爬虫之某网站的js逆向分析
某翻译的js逆向分析
今天学习了爬虫的高阶内容:js逆向分析。
选择难度较低的某翻译网站,首先进行抓包分析。

点击翻译,选择xhr文件就可以找到了我们点击发送的请求,

网页是一个post请求,网址如图所示,接着往下看,

这里有很多我们看不懂的参数,我们再发送一次请求看看这些参数是否发生变化,

我们可以发现i:是我们翻译的单词,其他发生变化的有图中三项:
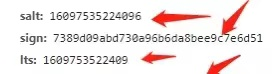
有经验的同学应该可以看出lts和时间戳很相似,而salt比lts多了一位数。sign是一个32位的字符,应该是md5加密。我们来验证一下;

在search中搜索sign,发现一个js文件,选择他。

这里的格式并不规范,我们点击左下角的{},就可以格式化了。
然后点击快捷键Ctrl+F,搜索sign,我们发现sign在第六次出现是被赋值,并且salt和ts的取值也是发生在此处。

r = “” + (new Date).getTime()
i = r + parseInt(10 * Math.random(), 10);
sign: n.md5(“fanyideskweb” + e + i + “Tbh5E8=q6U3EXe+&L[4c@”)
果然,ts是一个时间戳,由i的赋值可知,i的值是等于ts加上一个0-9的随机整数。对于sign的赋值,我们仍不清楚e的来源。此时我们可以对它进行断点分析,如图:
可以知道e的值是我们要翻译的内容,至此,我们已经分析完了。
这时我们就可以通过python来构造这些js逻辑。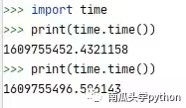
构造ts时,可以发现这里的时间戳是整数部分是10位,而ts是13位的,所以我们要对time.time()1000并取整,因为salt是在ts的基础上加上一位随机整数的,我们不妨对salt10000,再取整即可完成对salt的构造。
对于sign,在获取了e和i的值后,我们就可以通过python构造了,代码如下:
from hashlib import md5
import time
e = 'dog'
i = int(time.time()*1000)
print(i)
str = 'fanyideskweb' + e + str(i) + 'Tbh5E8=q6U3EXe+&L[4c@'
md = md5()
md.update(str.encode())
res = md.hexdigest()
print(res)
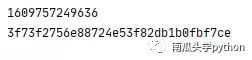
至此,所有的参数我们也构造完了。接下来就可以像网页发送post请求了。
def spider_youdaofanyi():
headers = {
'Host': 'fanyi.youdao.com',
'Origin': 'http: // fanyi.youdao.com',
'Referer': 'http: // fanyi.youdao.com /',
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11'
}
e = input("请输要翻译的词语:")
t = time.time()
ts = str(int(t * 1000))
salt = ts + str(int(t * 10000))
str_1 = 'fanyideskweb' + e + salt + 'Tbh5E8=q6U3EXe+&L[4c@'
md = md5()
md.update(str_1.encode())
sign = md.hexdigest()
# post请求的参数
data = {
'i': e,
'from':' AUTO',
'to': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'salt': salt,
'sign': sign,
'lts': ts,
'bv':'d17d9dd026a611df0315b4863363408c',
'doctype':'json',
'version':'2.1',
'keyfrom':'fanyi.web',
'action':'FY_BY_REALTlME'
}
# print(e, ts, salt, sign, data)
url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
response = session.post(url, headers=headers, data=data)
html = response.text
#print(html)
return html
结果如图所示:
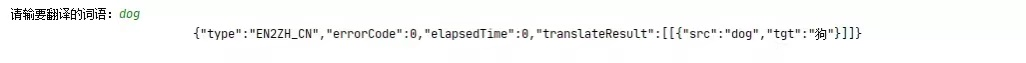
发现结果是json格式的,所以接下来就可以解析json了。
代码如下:
def fanyi():
html = spider_youdaofanyi()
jsondict = json.loads(html)
return jsondict['translateResult'][0][0]['tgt']
再次执行,结果如下:
关注公众号回复“翻译”获取完整代码!!!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号