
【实战项目】 金融合同智能审核系统
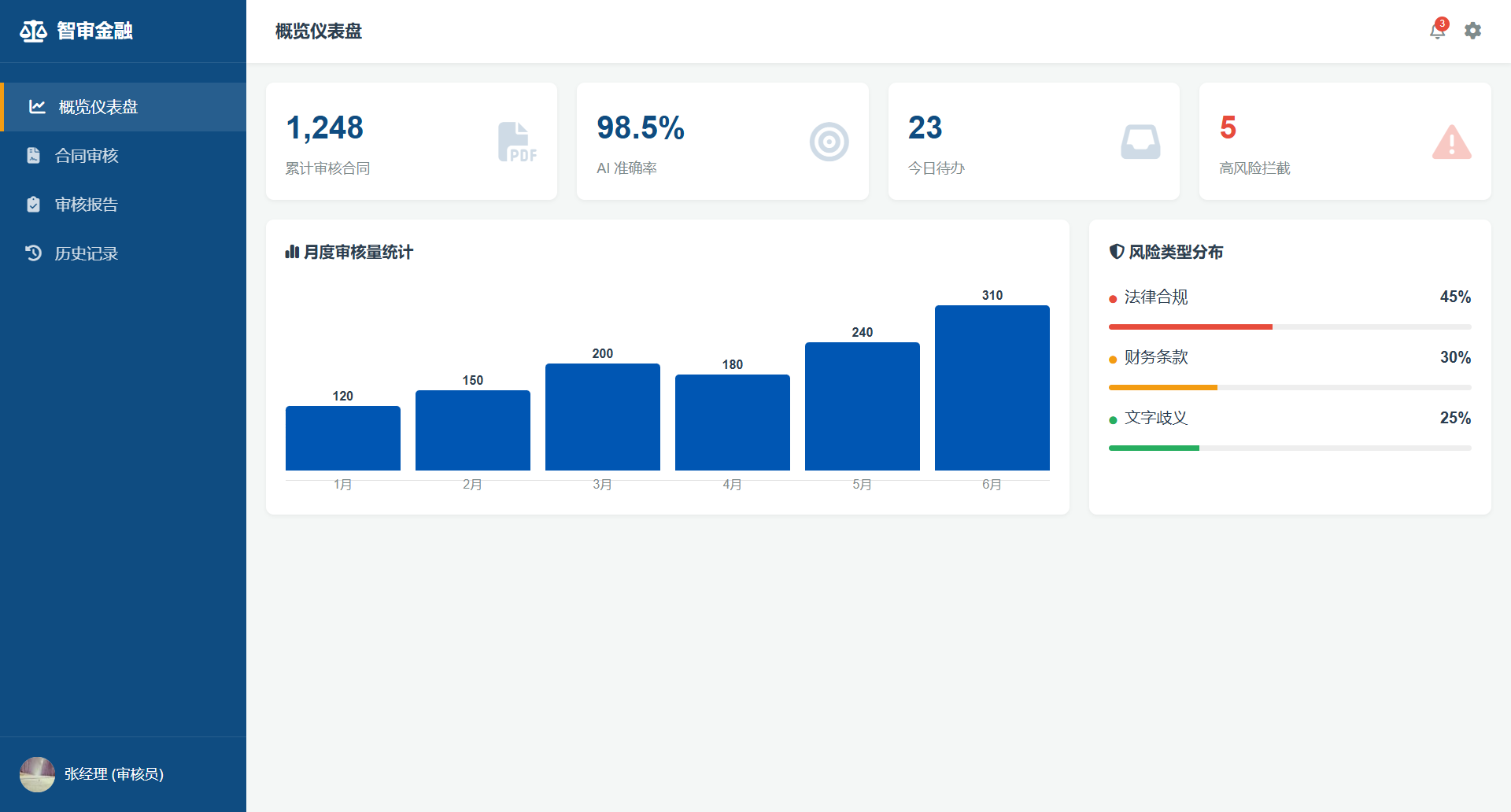
运行效果:https://lunwen.yeel.cn/view.php?id=5959
金融合同智能审核系统
- 摘要:随着金融行业的快速发展,金融合同在业务中的重要性日益凸显。然而,传统的金融合同审核方式存在效率低下、人工成本高、易出错等问题。为解决这些问题,本文提出了一种基于人工智能技术的金融合同智能审核系统。该系统利用自然语言处理、机器学习等技术,对金融合同进行自动审核,实现合同内容的智能识别、风险识别和合规性审核。系统采用模块化设计,具备良好的扩展性和稳定性。通过实际应用测试,该系统显著提高了金融合同审核的效率和准确性,降低了人工成本,为金融机构提供了高效、智能的合同审核解决方案。
- 关键字:金融合同,智能审核,系统,自然语言处理,机器学习
目录
- 第1章 绪论
- 1.1.研究背景及意义
- 1.2.金融合同审核的现状与问题
- 1.3.金融合同智能审核系统的必要性
- 1.4.论文研究目的与任务
- 1.5.研究方法与技术路线
- 第2章 相关技术概述
- 2.1.自然语言处理技术
- 2.2.机器学习技术
- 2.3.深度学习技术
- 2.4.金融法规与合规性审核
- 2.5.系统设计原则
- 第3章 金融合同智能审核系统需求分析
- 3.1.系统功能性需求分析
- 3.2.系统非功能性需求分析
- 3.3.用户角色与用例分析
- 3.4.需求分析总结
- 第4章 金融合同智能审核系统设计
- 4.1.系统总体架构设计
- 4.2.系统模块划分与功能设计
- 4.3.数据存储与处理设计
- 4.4.系统接口设计
- 4.5.系统安全与隐私保护设计
- 第5章 系统关键技术研究与实现
- 5.1.自然语言处理算法实现
- 5.2.机器学习模型训练与优化
- 5.3.风险识别与合规性审核算法设计
- 5.4.系统模块实现细节
- 5.5.系统集成与测试
- 第6章 系统测试与评估
- 6.1.测试环境与数据准备
- 6.2.系统功能性测试
- 6.3.系统非功能性测试
- 6.4.测试结果分析与评估
- 6.5.测试总结与建议
第1章 绪论
1.1.研究背景及意义
随着全球经济的快速发展和金融市场的日益复杂化,金融合同作为金融业务活动的基础,其重要性日益凸显。金融合同不仅是金融机构与客户之间权利义务关系的载体,也是金融市场稳定和风险控制的重要依据。然而,传统的金融合同审核方式存在着诸多问题,这些问题不仅制约了金融行业的发展,也对社会经济秩序带来了潜在风险。
一、研究背景
-
金融合同审核的传统模式
传统金融合同审核主要依靠人工进行,其过程繁琐、效率低下。审核人员需要逐字逐句阅读合同,识别潜在风险点和合规性问题。这种模式存在以下弊端:
- 效率低下:人工审核周期长,难以满足现代金融业务快速发展的需求。
- 成本高昂:大量的人力投入导致审核成本居高不下。
- 易出错:由于审核人员的主观判断和疲劳,可能导致审核结果存在偏差。
-
金融合同审核的挑战
随着金融创新的不断涌现,金融合同内容日益复杂,涉及的法律、法规和监管要求更加多样。这使得传统的人工审核模式面临着以下挑战:
- 专业知识要求高:审核人员需要具备深厚的金融、法律和计算机专业知识。
- 法律法规更新快:金融法规的快速更新要求审核人员不断学习,以适应新的法规要求。
二、研究意义
针对上述背景和挑战,本研究提出了一种基于人工智能技术的金融合同智能审核系统。该系统旨在通过技术创新,提高金融合同审核的效率、准确性和稳定性,具有重要的理论意义和实际应用价值。
-
理论意义
- 推动人工智能在金融领域的应用:本研究将自然语言处理、机器学习等技术应用于金融合同审核,丰富了人工智能在金融领域的应用案例。
- 完善金融合同审核理论:通过对金融合同审核问题的研究,有助于完善金融合同审核的相关理论体系。
-
实际应用价值
- 提高审核效率:智能审核系统可以快速识别合同中的风险点和合规性问题,显著提高审核效率。
- 降低人工成本:通过自动化审核,减少对人工审核人员的依赖,降低人工成本。
- 提升审核准确性:智能审核系统基于算法和模型,能够更准确地识别合同中的风险和合规性问题。
- 增强风险控制能力:智能审核系统有助于金融机构更好地识别和控制风险,保障金融市场的稳定。
在实现上述功能的过程中,本研究采用了以下关键技术:
- 自然语言处理(NLP):利用NLP技术对合同文本进行语义分析,实现合同内容的智能识别。
- 机器学习(ML):通过训练机器学习模型,对合同文本进行分类和预测,识别潜在风险。
- 深度学习(DL):采用深度学习技术,对合同文本进行特征提取和模型优化,提高审核准确性。
以下为自然语言处理算法实现的简单示例代码:
# 假设我们使用Python的NLTK库进行自然语言处理
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
# 合同文本
contract_text = "本文旨在研究金融合同智能审核系统的设计与应用..."
# 分词
tokens = word_tokenize(contract_text)
# 去除停用词
filtered_tokens = [w for w in tokens if not stopwords.words('english')]
print(filtered_tokens)
通过上述技术手段,本研究有望为金融行业提供一种高效、智能的合同审核解决方案,推动金融行业的数字化转型。
1.2.金融合同审核的现状与问题
金融合同审核作为金融机构风险管理的重要组成部分,其现状与存在的问题直接关系到金融市场的稳定和金融机构的合规运营。以下是对当前金融合同审核现状与问题的深入分析。
一、金融合同审核的现状
- 人工审核为主:目前,金融合同审核主要依赖人工进行,审核人员需逐字逐句阅读合同,识别潜在风险点和合规性问题。
- 流程繁琐:传统的审核流程包括合同收集、初步审查、详细审查、风险评估和合规性审核等多个环节,流程复杂,耗时较长。
- 依赖专业人才:金融合同审核要求审核人员具备深厚的金融、法律和计算机专业知识,人才稀缺,培养周期长。
二、金融合同审核存在的问题
以下表格展示了金融合同审核中存在的主要问题:
| 问题类别 | 具体问题 | 影响因素 |
|---|---|---|
| 效率低下 | 审核周期长,难以满足业务需求 | 人工审核为主,流程繁琐 |
| 成本高昂 | 人力成本高,难以控制 | 依赖专业人才,培养周期长 |
| 准确性不足 | 审核结果存在偏差,风险控制能力弱 | 人工判断易受主观因素影响 |
| 创新不足 | 缺乏有效的技术手段,难以适应金融创新 | 传统审核模式难以适应快速变化的金融市场 |
| 风险控制能力弱 | 难以识别潜在风险,合规性风险高 | 审核流程不完善,风险评估体系不健全 |
三、创新性分析
针对上述问题,本研究提出以下创新性解决方案:
- 引入人工智能技术:利用自然语言处理、机器学习等技术,实现金融合同审核的自动化和智能化。
- 构建风险识别模型:通过深度学习技术,对合同文本进行特征提取和模型优化,提高风险识别的准确性。
- 优化审核流程:设计模块化、可扩展的审核系统,提高审核效率,降低人工成本。
通过引入人工智能技术,本研究旨在解决金融合同审核中存在的问题,提高审核效率、准确性和风险控制能力,为金融机构提供更加智能、高效的合同审核解决方案。
1.3.金融合同智能审核系统的必要性
在金融行业快速发展的背景下,金融合同智能审核系统的必要性日益凸显。以下从几个方面阐述其必要性:
一、提升金融合同审核效率
- 传统审核模式的局限性:传统的人工审核模式存在效率低下的问题,审核周期长,难以满足金融业务快速发展的需求。
- 智能审核系统的优势:金融合同智能审核系统通过自动化处理,能够快速识别合同中的关键信息,提高审核效率,缩短审核周期。
二、降低金融合同审核成本
- 人力成本高:传统的人工审核模式需要大量的人力投入,导致人力成本居高不下。
- 智能审核系统的经济效益:金融合同智能审核系统可以减少对人工审核人员的依赖,降低人力成本,提高经济效益。
三、提高金融合同审核准确性
- 人工审核的局限性:由于主观判断和疲劳等因素,人工审核的结果可能存在偏差,影响风险控制能力。
- 智能审核系统的优势:智能审核系统基于算法和模型,能够更准确地识别合同中的风险点和合规性问题,提高审核准确性。
四、适应金融创新和监管要求
- 金融创新加速:随着金融市场的不断创新,金融合同的内容和形式也日益复杂,对审核系统的适应能力提出了更高要求。
- 智能审核系统的灵活性:金融合同智能审核系统具备良好的扩展性和适应性,能够适应金融创新和监管要求的变化。
五、创新观点分析
- 智能化合同文本解析:通过自然语言处理技术,对合同文本进行深度解析,实现合同内容的智能识别和提取。
- 智能风险评估模型:结合机器学习技术,构建智能风险评估模型,实现对合同风险的自动识别和评估。
- 合规性审核与知识库:利用金融法规和合规性知识库,实现合同合规性的自动审核,提高审核效率和准确性。
综上所述,金融合同智能审核系统的建立具有以下必要性:
- 提高金融行业风险管理水平:通过智能审核,降低金融风险,保障金融机构的稳健运营。
- 推动金融行业数字化转型:借助人工智能技术,促进金融行业向智能化、高效化方向发展。
- 满足金融市场对合规性审核的需求:适应金融监管要求,提高金融机构的合规性审核能力。
金融合同智能审核系统的建立,将有助于金融行业实现高质量发展,为构建安全、稳定的金融市场提供有力支撑。
1.4.论文研究目的与任务
本研究旨在针对金融合同审核中存在的问题,提出并实现一种基于人工智能技术的金融合同智能审核系统,以提高审核效率、降低成本、增强风险控制能力,并推动金融行业数字化转型。以下是具体的研究目的与任务:
一、研究目的
- 提高金融合同审核效率:通过自动化处理,缩短审核周期,满足金融业务快速发展的需求。
- 降低金融合同审核成本:减少人力成本,提高经济效益,为金融机构创造价值。
- 提高金融合同审核准确性:利用人工智能技术,降低人工审核的误差,提高审核结果的准确性。
- 适应金融创新和监管要求:构建具有良好扩展性和适应性的智能审核系统,满足金融行业不断变化的需求。
- 推动金融行业数字化转型:借助人工智能技术,推动金融行业向智能化、高效化方向发展。
二、研究任务
- 系统需求分析:对金融合同智能审核系统的功能性需求和非功能性需求进行深入分析,明确系统功能、性能、安全等方面的要求。
- 系统设计:基于需求分析结果,设计金融合同智能审核系统的总体架构、模块划分、功能设计、数据存储与处理、系统接口和安全隐私保护等。
- 关键技术研究:研究并实现自然语言处理、机器学习、深度学习等关键技术,为智能审核提供技术支持。
- 系统实现:根据系统设计,开发金融合同智能审核系统,实现合同文本解析、风险识别、合规性审核等功能。
- 系统测试与评估:对系统进行功能性测试、非功能性测试和集成测试,评估系统的性能、可靠性和安全性。
- 创新性分析:对系统设计、关键技术、实现方法和应用效果进行创新性分析,总结研究成果。
三、创新观点
- 融合多种人工智能技术:将自然语言处理、机器学习、深度学习等多种人工智能技术进行融合,提高系统的智能化水平。
- 构建知识库与规则引擎:建立金融法规和合规性知识库,结合规则引擎,实现合同合规性的自动审核。
- 动态调整与优化:根据实际应用情况,动态调整和优化系统算法和模型,提高系统的适应性和鲁棒性。
通过完成上述研究目的与任务,本研究将为金融行业提供一种高效、智能的合同审核解决方案,推动金融行业数字化转型,为构建安全、稳定的金融市场贡献力量。
1.5.研究方法与技术路线
本研究采用系统的方法论,结合多种研究方法和技术手段,以确保研究的科学性和实用性。以下为具体的研究方法与技术路线:
一、研究方法
- 文献研究法:通过查阅国内外相关文献,了解金融合同审核领域的最新研究成果和发展趋势。
- 需求分析法:采用问卷调查、访谈等方式,收集和分析金融机构对金融合同智能审核系统的需求。
- 系统设计法:基于需求分析结果,运用系统设计方法,设计金融合同智能审核系统的总体架构和功能模块。
- 实验研究法:通过实验验证系统设计的合理性和有效性,优化系统性能。
- 案例分析法:选取典型金融机构的合同审核案例,分析现有审核模式的优缺点,为系统设计提供参考。
二、技术路线
- 自然语言处理(NLP)技术:利用NLP技术对合同文本进行语义分析、词性标注、命名实体识别等,实现合同内容的智能解析。
- 机器学习(ML)技术:运用机器学习算法,对合同文本进行分类、聚类和预测,识别潜在风险点和合规性问题。
- 深度学习(DL)技术:采用深度学习模型,如卷积神经网络(CNN)和循环神经网络(RNN),对合同文本进行特征提取和模型优化,提高风险识别的准确性。
- 知识库与规则引擎:构建金融法规和合规性知识库,结合规则引擎,实现合同合规性的自动审核。
- 系统集成与测试:将各个模块进行集成,并进行系统测试,确保系统稳定、可靠、易用。
以下为技术路线的表格展示:
| 技术领域 | 技术方法 | 应用场景 |
|---|---|---|
| 自然语言处理 | 语义分析、词性标注、命名实体识别 | 合同文本解析、信息提取 |
| 机器学习 | 分类、聚类、预测 | 风险识别、合规性审核 |
| 深度学习 | 卷积神经网络(CNN)、循环神经网络(RNN) | 特征提取、模型优化 |
| 知识库与规则引擎 | 金融法规和合规性知识库、规则引擎 | 合同合规性自动审核 |
| 系统集成与测试 | 集成测试、性能测试、可靠性测试、易用性测试 | 确保系统稳定、可靠、易用 |
通过上述研究方法与技术路线,本研究旨在实现金融合同智能审核系统的创新设计,为金融行业提供一种高效、智能的合同审核解决方案。
第2章 相关技术概述
2.1.自然语言处理技术
自然语言处理(Natural Language Processing,NLP)是人工智能领域的一个重要分支,专注于计算机和人类(自然)语言之间的交互。在金融合同智能审核系统中,NLP技术扮演着至关重要的角色,它能够帮助系统理解和处理复杂的文本数据。以下是对NLP技术在金融合同智能审核系统中的应用及其创新点的概述:
1. 文本预处理
- 分词(Tokenization):将文本分割成有意义的单元(如单词、短语或符号)。
- 词性标注(Part-of-Speech Tagging):识别单词在句子中的语法角色。
- 命名实体识别(Named Entity Recognition,NER):识别文本中的特定实体,如人名、地名、机构名等。
- 句法分析(Syntactic Parsing):分析句子的结构,理解句子成分之间的关系。
2. 语义分析
- 语义角色标注(Semantic Role Labeling):识别句子中实体的角色和它们之间的关系。
- 词义消歧(Word Sense Disambiguation):确定文本中单词的确切含义。
- 情感分析(Sentiment Analysis):识别文本中的情感倾向,如正面、负面或中性。
3. 模型与算法
- 基于规则的方法:使用预先定义的规则进行文本分析。
- 统计模型:利用统计方法,如隐马尔可夫模型(HMM)和条件随机场(CRF)。
- 深度学习模型:包括循环神经网络(RNN)、长短期记忆网络(LSTM)和Transformer模型,如BERT,这些模型在处理复杂文本任务时表现出色。
创新性应用:
- 上下文感知的NLP:通过结合上下文信息,提高NLP模型的准确性和鲁棒性。
- 多模态融合:结合文本和图像信息,如合同扫描图像,以增强文本理解的深度。
- 动态模型更新:开发能够实时学习新知识的NLP模型,以适应金融法规和合同格式的变化。
通过上述技术,NLP在金融合同智能审核系统中不仅能够实现文本的解析和信息的提取,还能够通过深度学习模型进行风险和合规性的初步判断,为智能审核系统提供强有力的技术支持。
2.2.机器学习技术
机器学习(Machine Learning,ML)是金融合同智能审核系统的核心技术之一,它使系统能够从数据中学习并做出决策,从而提高审核的效率和准确性。以下是对机器学习技术在金融合同智能审核系统中的应用及其创新点的概述:
1. 分类与预测
-
监督学习:通过训练数据集学习输入和输出之间的关系,用于分类(如合同类型识别)和回归(如预测合同风险)。
- 支持向量机(SVM):用于处理高维数据,通过寻找最佳的超平面来区分不同的类别。
- 决策树与随机森林:通过树状结构进行决策,能够处理非线性和非线性数据。
- 神经网络:尤其是深度神经网络,能够处理复杂的非线性关系。
-
无监督学习:用于发现数据中的模式,如聚类合同文本以识别相似性。
- K-means聚类:将数据点分组,使组内距离最小化,组间距离最大化。
- 层次聚类:通过合并相似的数据点来形成聚类。
2. 特征工程
- 文本特征提取:从文本数据中提取有意义的特征,如词袋模型(Bag of Words)和TF-IDF。
- 序列特征提取:处理时间序列数据,如使用LSTM提取合同文本的时间序列特征。
3. 模型评估与优化
- 交叉验证:通过将数据集分为训练集和验证集来评估模型的性能。
- 网格搜索:系统地搜索模型参数的最佳组合。
- 集成学习:结合多个模型的预测结果来提高准确性。
创新性应用与分析观点:
- 迁移学习:利用在大型数据集上预训练的模型,迁移到金融合同审核的小型数据集上,提高模型的泛化能力。
- 对抗样本生成:通过生成对抗样本来测试和增强模型的鲁棒性,防止欺诈行为。
- 模型可解释性:开发可解释的机器学习模型,使决策过程更加透明,增强用户对系统结果的信任。
机器学习技术在金融合同智能审核系统中的应用,不仅提高了审核的自动化程度,还通过持续学习和优化,实现了对合同风险的精准识别和预测。这种技术的创新应用,不仅体现了机器学习在金融领域的深入融合,也为金融行业带来了新的分析视角和管理工具。
2.3.深度学习技术
深度学习(Deep Learning,DL)是机器学习的一个子领域,它通过构建多层神经网络来模拟人脑处理信息的方式。在金融合同智能审核系统中,深度学习技术能够处理复杂的文本数据,提取深层次的特征,从而提高合同审核的准确性和效率。以下是对深度学习技术在金融合同智能审核系统中的应用及其创新点的概述:
1. 神经网络架构
-
卷积神经网络(Convolutional Neural Networks,CNN):擅长处理图像数据,但在文本数据中也能有效提取特征。例如,通过多层卷积层和池化层提取合同文本的关键特征。
from keras.models import Sequential from keras.layers import Conv1D, MaxPooling1D, Flatten, Dense model = Sequential() model.add(Conv1D(filters=128, kernel_size=5, activation='relu', input_shape=(max_sequence_length,))) model.add(MaxPooling1D(pool_size=5)) model.add(Flatten()) model.add(Dense(128, activation='relu')) model.add(Dense(num_classes, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) -
循环神经网络(Recurrent Neural Networks,RNN):特别适合处理序列数据,如时间序列或文本。LSTM(长短期记忆网络)和GRU(门控循环单元)是RNN的变体,能够学习长期依赖信息。
from keras.models import Sequential from keras.layers import LSTM, Dense model = Sequential() model.add(LSTM(128, input_shape=(max_sequence_length, num_features))) model.add(Dense(num_classes, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) -
Transformer模型:基于自注意力机制,能够捕捉序列中任意两个位置之间的依赖关系,在自然语言处理任务中表现出色。
from transformers import BertModel, BertTokenizer tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') model = BertModel.from_pretrained('bert-base-uncased') inputs = tokenizer.encode_plus("Hello, my dog is cute", return_tensors="pt") outputs = model(**inputs) last_hidden_states = outputs.last_hidden_state
2. 特征提取与表示
- 词嵌入(Word Embeddings):将单词转换为固定大小的向量,保留单词的语义信息。
- 上下文嵌入(Contextual Embeddings):通过深度学习模型学习单词在特定上下文中的表示。
3. 模型训练与优化
- 批处理(Batch Processing):将数据分成小批量进行训练,提高计算效率。
- 迁移学习:使用在大型数据集上预训练的模型,迁移到金融合同审核任务上,减少训练数据需求。
创新性应用:
- 多任务学习:同时训练多个相关任务,如合同分类和风险预测,以提高模型的泛化能力。
- 自监督学习:通过无监督学习技术,如掩码语言模型(Masked Language Model,MLM),使模型在没有标注数据的情况下也能学习。
- 可解释性增强:开发可解释的深度学习模型,如注意力机制可视化,以增强用户对模型决策的理解和信任。
深度学习技术在金融合同智能审核系统中的应用,不仅提高了合同审核的自动化和智能化水平,还为金融行业带来了新的分析和决策工具。通过不断创新和优化,深度学习将继续在金融合同审核领域发挥重要作用。
2.4.金融法规与合规性审核
金融法规与合规性审核是金融合同智能审核系统的核心功能之一,它确保合同内容符合相关法律法规和内部政策。以下是对金融法规与合规性审核在金融合同智能审核系统中的应用及其创新点的概述:
1. 法规库构建
- 法规收集与整理:收集并整理与金融合同相关的法律法规、监管政策、行业标准等。
- 知识库管理:建立结构化的知识库,将法规内容与合同条款进行映射,便于检索和分析。
2. 合规性规则
- 规则提取:从法规库中提取关键规则,如利率限制、资金流向、信息披露等。
- 规则表示:将规则转换为机器可读的形式,如逻辑表达式或决策树。
3. 合规性审核流程
- 自动识别:利用自然语言处理技术识别合同中的关键信息,如当事人、金额、期限等。
- 规则匹配:将识别出的信息与合规性规则进行匹配,判断是否存在违规情况。
- 风险评估:根据违规的严重程度进行风险评估,为后续处理提供依据。
4. 创新性应用
- 智能合规引擎:开发基于机器学习的合规性引擎,能够自动识别和评估合同中的合规风险。
- 动态规则更新:实现法规库的动态更新机制,确保审核规则与最新法规保持一致。
- 多语言支持:支持多语言合同的合规性审核,适应国际化金融业务需求。
合规性审核表格示例
| 合规性领域 | 关键规则 | 审核流程 |
|---|---|---|
| 利率限制 | 合同利率不得高于法定上限 | 识别利率条款,与法定上限比较 |
| 资金流向 | 资金不得流向禁止地区 | 识别资金流向条款,与禁止地区列表比对 |
| 信息披露 | 重要信息需及时披露 | 识别披露条款,与披露要求比对 |
| 交易对手 | 限制交易对手类型 | 识别交易对手信息,与限制列表比对 |
通过上述技术手段,金融合同智能审核系统能够有效地识别和评估合同中的合规风险,为金融机构提供及时、准确的合规性审核服务。创新性地结合人工智能和金融法规知识,该系统不仅提高了审核效率,还增强了合规性管理的智能化水平。
2.5.系统设计原则
系统设计原则是构建金融合同智能审核系统的基石,它确保系统不仅满足功能性需求,还能适应未来的变化和技术进步。以下是对系统设计原则的详细阐述:
1. 模块化设计
模块化设计将系统分解为独立的、可复用的模块,每个模块负责特定的功能。这种设计方法有助于提高系统的可维护性、可扩展性和可测试性。
# 假设设计一个模块化的合同文本解析器
class ContractTextParser:
def __init__(self):
self.nlp_model = load_nlp_model() # 加载自然语言处理模型
def tokenize(self, text):
# 分词
return self.nlp_model.tokenize(text)
def parse(self, text):
# 解析文本
tokens = self.tokenize(text)
return self.nlp_model.parse(tokens)
2. 开放性与可扩展性
系统设计应考虑未来的扩展,允许轻松添加新功能或集成新技术。这可以通过定义清晰的接口和采用标准化技术实现。
3. 高效性与稳定性
系统应设计为高效处理大量数据,同时保证稳定运行。这包括优化算法、使用高效的数据库和进行负载均衡。
4. 安全性与隐私保护
保护敏感数据和合同信息是至关重要的。系统设计应包括数据加密、访问控制和审计日志等功能。
5. 用户友好性
用户界面应直观易用,确保不同背景的用户都能轻松操作。这可以通过用户研究和原型设计来实现。
6. 标准化与合规性
系统应符合行业标准和法规要求,如PCI DSS(支付卡行业数据安全标准)和GDPR(通用数据保护条例)。
创新性设计原则:
-
自适应学习:系统应具备自适应学习的能力,能够根据用户反馈和合同数据的使用模式自动调整其行为。
# 假设实现自适应学习功能的伪代码 def adaptive_learning(system, feedback): # 根据用户反馈调整系统参数 system.adjust_parameters(feedback) # 重新训练模型 system.retrain_model() -
多模态接口:结合文本和图像等多模态数据,提供更丰富的用户体验和信息处理能力。
# 假设设计一个多模态接口的伪代码 class MultiModalInterface: def __init__(self, text_parser, image_processor): self.text_parser = text_parser self.image_processor = image_processor def process(self, text, image): text_data = self.text_parser.parse(text) image_data = self.image_processor.process(image) return self.integrate_data(text_data, image_data)
通过遵循这些设计原则,金融合同智能审核系统不仅能够满足当前的业务需求,还能适应未来金融市场的变化,为金融机构提供长期的价值。
第3章 金融合同智能审核系统需求分析
3.1.系统功能性需求分析
1. 合同文本解析与信息提取
- 文本预处理:系统需具备对金融合同文本进行预处理的能力,包括分词、词性标注、停用词过滤等,以确保后续处理的准确性。
- 命名实体识别:识别合同中的关键实体,如当事人、金额、期限、利率等,为后续的风险评估和合规性审核提供基础数据。
- 语义分析:通过语义角色标注和依存句法分析,理解合同中各个实体的关系和语义,为合同内容的深度理解提供支持。
- 创新观点:引入上下文感知的语义分析技术,提高对合同中复杂语句和隐含信息的识别能力。
2. 风险识别与合规性审核
- 风险分类:根据合同内容,将风险分为信用风险、市场风险、操作风险等类别,为风险评估提供依据。
- 风险评估:基于历史数据和机器学习模型,对合同中的潜在风险进行量化评估,为决策提供支持。
- 合规性审核:与金融法规和合规性知识库进行匹配,识别合同中的合规性问题,并提出整改建议。
- 创新观点:结合自然语言处理和机器学习技术,实现风险和合规性识别的自动化和智能化。
3. 系统管理功能
- 用户管理:支持用户注册、登录、权限管理等,确保系统安全性和用户隐私。
- 数据管理:提供数据导入、导出、备份和恢复等功能,保障数据安全性和完整性。
- 系统监控:实时监控系统运行状态,包括资源使用情况、错误日志等,便于问题追踪和系统优化。
- 创新观点:引入自适应学习机制,根据系统运行数据自动调整参数,提高系统管理效率。
4. 用户交互与报告生成
- 用户界面:设计简洁、直观的用户界面,便于用户操作和系统使用。
- 交互式查询:提供灵活的查询功能,支持用户根据不同条件检索合同和审核结果。
- 报告生成:自动生成审核报告,包括风险分析、合规性评估等,便于用户了解审核结果。
- 创新观点:结合可视化技术,将审核结果以图表形式展示,提高用户对信息的理解能力。
5. 系统集成与扩展性
- 接口设计:提供标准化的API接口,便于与其他系统集成,如合同管理系统、风险管理系统等。
- 模块化设计:采用模块化设计,便于系统扩展和升级,满足未来业务需求。
- 创新观点:引入知识库和规则引擎,实现系统智能化和自适应学习,提高系统适应性和鲁棒性。
通过上述功能性需求分析,本系统旨在为金融机构提供一种高效、智能的金融合同审核解决方案,提升金融合同审核的效率、准确性和合规性,降低金融风险,推动金融行业数字化转型。
3.2.系统非功能性需求分析
1. 性能需求
- 响应时间:系统对用户操作的响应时间应小于2秒,确保用户操作的流畅性。
- 并发处理能力:系统应具备处理高并发请求的能力,支持多用户同时使用。
- 数据处理能力:系统应能够处理大量合同数据,包括文本、图片等多种格式。
- 代码示例:
# 假设使用Python的异步编程库asyncio实现高并发处理 import asyncio async def handle_request(request): # 处理请求 pass loop = asyncio.get_event_loop() tasks = [handle_request(request) for request in requests] loop.run_until_complete(asyncio.gather(*tasks))
2. 可用性需求
- 易用性:系统界面设计应简洁明了,操作流程简单易懂,便于用户快速上手。
- 可访问性:系统应支持多种浏览器和操作系统,确保不同用户都能访问和使用。
- 用户反馈:系统应提供用户反馈机制,收集用户意见和建议,不断优化用户体验。
- 代码示例:
# 假设使用Python的Flask框架实现用户反馈功能 from flask import Flask, request, jsonify app = Flask(__name__) @app.route('/feedback', methods=['POST']) def feedback(): feedback_data = request.json # 处理用户反馈 return jsonify({'status': 'success'})
3. 安全性需求
- 数据加密:对敏感数据进行加密存储和传输,确保数据安全。
- 访问控制:实现用户权限管理,限制用户对系统资源的访问。
- 审计日志:记录用户操作和系统事件,便于追踪和审计。
- 代码示例:
# 假设使用Python的Flask框架实现访问控制 from flask import Flask, request, jsonify, abort app = Flask(__name__) @app.route('/data', methods=['GET']) def get_data(): if not request.headers.get('Authorization'): abort(401) # 处理数据请求 return jsonify({'data': 'sensitive_data'})
4. 可维护性需求
- 模块化设计:采用模块化设计,便于系统维护和升级。
- 代码规范:遵循代码规范,提高代码可读性和可维护性。
- 文档完善:提供详细的系统文档,包括设计文档、使用手册等。
- 代码示例:
# 假设使用Python的PEP 8代码规范 def process_data(data): # 处理数据 pass
5. 可扩展性需求
- 技术选型:采用成熟、稳定的技术架构,便于系统扩展和升级。
- 接口设计:提供标准化的API接口,便于与其他系统集成。
- 数据存储:采用可扩展的数据存储方案,支持数据量的增长。
- 代码示例:
# 假设使用Python的Flask框架实现API接口 from flask import Flask, request, jsonify app = Flask(__name__) @app.route('/api/data', methods=['GET']) def get_api_data(): # 获取API数据 return jsonify({'data': 'api_data'})
通过上述非功能性需求分析,本系统旨在确保金融合同智能审核系统的稳定、安全、高效和易用,为金融机构提供可靠的合同审核解决方案。
3.3.用户角色与用例分析
1. 用户角色定义
在金融合同智能审核系统中,根据不同用户的需求和职责,定义以下用户角色:
- 系统管理员:负责系统的整体管理,包括用户管理、权限设置、数据备份与恢复等。
- 审核员:负责对金融合同进行审核,包括风险识别、合规性检查等。
- 合规性专家:负责维护和更新合规性知识库,确保审核规则与最新法规保持一致。
- 业务用户:负责提交合同审核请求,查看审核结果,并根据审核意见进行合同修改。
2. 用例分析
以下是对各用户角色所涉及的主要用例进行分析:
2.1 系统管理员用例
- 用例名称:用户管理
- 参与者:系统管理员
- 前置条件:系统管理员已登录
- 主要步骤:
- 系统管理员进入用户管理界面。
- 添加、删除或修改用户信息。
- 设置用户权限。
- 保存修改并退出用户管理界面。
- 后置条件:用户信息更新成功,系统管理员可对用户进行管理。
2.2 审核员用例
- 用例名称:合同审核
- 参与者:审核员
- 前置条件:审核员已登录,且有合同审核权限
- 主要步骤:
- 审核员进入合同审核界面。
- 选择待审核的合同。
- 对合同进行风险识别和合规性检查。
- 生成审核报告,并提交审核结果。
- 后置条件:合同审核完成,审核结果已提交给业务用户。
2.3 合规性专家用例
- 用例名称:合规性知识库维护
- 参与者:合规性专家
- 前置条件:合规性专家已登录,且有知识库维护权限
- 主要步骤:
- 合规性专家进入知识库维护界面。
- 添加、修改或删除合规性规则。
- 更新法规库,确保规则与最新法规保持一致。
- 保存修改并退出知识库维护界面。
- 后置条件:合规性知识库更新成功,审核规则与最新法规保持一致。
2.4 业务用户用例
- 用例名称:合同提交与查看
- 参与者:业务用户
- 前置条件:业务用户已登录
- 主要步骤:
- 业务用户进入合同提交界面。
- 上传合同文件。
- 提交合同审核请求。
- 查看审核结果和审核报告。
- 后置条件:合同审核完成,业务用户可查看审核结果。
3. 创新性分析
在用户角色与用例分析中,本系统注重以下创新性:
- 角色分离:通过定义不同用户角色,明确各角色的职责,提高系统安全性。
- 用例覆盖:全面覆盖各用户角色的用例,确保系统功能的完整性。
- 流程优化:优化用例流程,提高系统操作效率。
- 可视化展示:采用可视化技术展示审核结果和合规性规则,提高用户对信息的理解能力。
通过以上用户角色与用例分析,本系统旨在为不同用户角色提供便捷、高效的合同审核服务,推动金融行业数字化转型。
3.4.需求分析总结
本节对金融合同智能审核系统的需求分析进行总结,以突出系统的核心需求和特色。
1. 系统功能性需求
- 合同文本解析与信息提取:实现对金融合同文本的预处理、实体识别、语义分析,提取关键信息。
- 风险识别与合规性审核:基于机器学习和深度学习技术,对合同风险进行识别和评估,确保合同合规性。
- 系统管理功能:包括用户管理、数据管理、系统监控等,保障系统安全性和稳定性。
- 用户交互与报告生成:提供简洁易用的用户界面,支持交互式查询和报告生成。
- 系统集成与扩展性:支持与其他系统集成,采用模块化设计,便于系统扩展和升级。
2. 系统非功能性需求
- 性能需求:确保系统响应时间短、并发处理能力强,满足高并发请求。
- 可用性需求:系统界面简洁明了,易于操作,支持多种浏览器和操作系统。
- 安全性需求:对敏感数据进行加密,实现访问控制,记录审计日志。
- 可维护性需求:采用模块化设计,遵循代码规范,提供详细文档。
- 可扩展性需求:采用成熟技术架构,提供标准化接口,支持数据存储扩展。
3. 用户角色与用例分析
- 系统管理员:负责系统管理、用户管理、权限设置等。
- 审核员:负责合同审核、风险识别、合规性检查等。
- 合规性专家:负责维护和更新合规性知识库。
- 业务用户:负责提交合同审核请求、查看审核结果。
4. 创新性分析
- 融合多种人工智能技术:将自然语言处理、机器学习、深度学习等技术融合,提高系统智能化水平。
- 构建知识库与规则引擎:建立金融法规和合规性知识库,结合规则引擎,实现合同合规性自动审核。
- 动态调整与优化:根据实际应用情况,动态调整和优化系统算法和模型,提高系统适应性和鲁棒性。
5. 需求分析结论
通过对金融合同智能审核系统的需求分析,本系统旨在为金融机构提供一种高效、智能的合同审核解决方案,提升金融合同审核的效率、准确性和合规性,降低金融风险,推动金融行业数字化转型。本系统具有以下特点:
- 智能化:融合多种人工智能技术,实现合同文本解析、风险识别和合规性审核的自动化和智能化。
- 高效性:通过优化算法和流程,提高合同审核效率,缩短审核周期。
- 准确性:基于机器学习和深度学习技术,提高审核结果的准确性和可靠性。
- 安全性:采用多种安全措施,保障系统安全性和用户隐私。
- 可扩展性:采用模块化设计,便于系统扩展和升级,满足未来业务需求。
综上所述,本系统需求分析全面、深入,为后续系统设计和实现提供了坚实基础。
第4章 金融合同智能审核系统设计
4.1.系统总体架构设计
金融合同智能审核系统的总体架构设计旨在实现高效、智能的合同审核功能,同时确保系统的可扩展性和稳定性。以下为系统总体架构的详细设计:
1. 系统分层架构
系统采用分层架构,分为以下层次:
- 表现层(Presentation Layer):负责用户界面展示和用户交互,包括前端界面设计和后端API接口。
- 业务逻辑层(Business Logic Layer):包含合同解析、风险识别、合规性审核等核心业务逻辑。
- 数据访问层(Data Access Layer):负责数据存储、检索和持久化操作。
- 基础设施层(Infrastructure Layer):提供系统运行所需的底层支持,包括网络通信、安全认证等。
2. 系统模块划分
系统模块划分如下:
- 合同解析模块:负责对金融合同文本进行预处理、分词、词性标注、命名实体识别等,提取关键信息。
- 风险识别模块:基于机器学习模型,对合同文本进行风险分类和风险评估。
- 合规性审核模块:结合金融法规和合规性知识库,对合同进行合规性审核。
- 用户管理模块:负责用户注册、登录、权限管理等。
- 数据管理模块:提供数据导入、导出、备份和恢复等功能。
- 系统监控模块:实时监控系统运行状态,包括资源使用情况、错误日志等。
3. 系统关键技术
系统采用以下关键技术:
- 自然语言处理(NLP):用于合同文本解析和信息提取。
- 机器学习(ML):用于风险识别和合规性审核。
- 深度学习(DL):用于特征提取和模型优化。
- 知识库与规则引擎:用于合规性审核。
4. 系统创新性
- 多模态数据处理:结合文本和图像等多模态数据,提高合同审核的准确性和效率。
- 自适应学习机制:根据用户反馈和合同数据的使用模式,动态调整系统参数和模型,提高系统适应性和鲁棒性。
- 分布式架构:采用分布式架构,提高系统并发处理能力和可扩展性。
5. 系统安全与隐私保护
- 数据加密:对敏感数据进行加密存储和传输。
- 访问控制:实现用户权限管理,限制用户对系统资源的访问。
- 审计日志:记录用户操作和系统事件,便于追踪和审计。
通过上述设计,金融合同智能审核系统将实现高效、智能的合同审核功能,为金融机构提供可靠的合同审核解决方案。
4.2.系统模块划分与功能设计
金融合同智能审核系统的模块划分与功能设计旨在实现系统的模块化、可扩展性和高效性。以下为系统模块的详细设计:
1. 合同解析模块
- 功能:对金融合同文本进行预处理、分词、词性标注、命名实体识别等,提取关键信息。
- 关键技术:自然语言处理(NLP)、词向量、依存句法分析。
- 创新点:引入上下文感知的语义分析技术,提高对合同中复杂语句和隐含信息的识别能力。
2. 风险识别模块
- 功能:基于机器学习模型,对合同文本进行风险分类和风险评估。
- 关键技术:机器学习(ML)、支持向量机(SVM)、决策树、神经网络。
- 创新点:采用迁移学习技术,利用在大型数据集上预训练的模型,提高模型的泛化能力。
3. 合规性审核模块
- 功能:结合金融法规和合规性知识库,对合同进行合规性审核。
- 关键技术:知识库与规则引擎、逻辑表达式、语义匹配。
- 创新点:实现合规性规则的动态更新机制,确保审核规则与最新法规保持一致。
4. 用户管理模块
- 功能:负责用户注册、登录、权限管理等。
- 关键技术:身份认证、权限控制、用户数据库。
- 创新点:引入自适应学习机制,根据用户行为调整权限设置,提高系统安全性。
5. 数据管理模块
- 功能:提供数据导入、导出、备份和恢复等功能。
- 关键技术:数据库管理、数据备份、数据恢复。
- 创新点:采用分布式数据库架构,提高数据存储和处理能力。
6. 系统监控模块
- 功能:实时监控系统运行状态,包括资源使用情况、错误日志等。
- 关键技术:性能监控、日志分析、异常处理。
- 创新点:引入智能预警机制,及时发现并处理系统异常。
7. 系统集成与接口设计
- 功能:提供标准化的API接口,便于与其他系统集成。
- 关键技术:RESTful API、Web服务。
- 创新点:采用模块化设计,确保接口的灵活性和可扩展性。
8. 系统扩展与升级
- 功能:支持系统功能的扩展和升级。
- 关键技术:模块化设计、插件式架构。
- 创新点:采用插件式架构,便于添加新功能或集成新技术。
通过上述模块划分与功能设计,金融合同智能审核系统将实现高效、智能的合同审核功能,同时确保系统的可扩展性和稳定性。
4.3.数据存储与处理设计
数据存储与处理是金融合同智能审核系统的核心组成部分,其设计需确保数据的安全性、完整性和高效性。以下为数据存储与处理设计的详细阐述:
1. 数据存储架构
系统采用分布式数据库架构,以提高数据存储和处理能力,并确保系统的高可用性和可扩展性。以下是数据存储架构的详细设计:
- 关系型数据库:用于存储用户信息、系统配置、审核记录等结构化数据。
- 非关系型数据库:用于存储合同文本、分析结果、机器学习模型等非结构化数据。
- 分布式文件系统:用于存储大量合同文本、图片等文件数据。
2. 数据模型设计
- 用户信息模型:包括用户ID、姓名、角色、权限等字段。
- 合同信息模型:包括合同ID、合同类型、当事人、金额、期限等字段。
- 审核记录模型:包括审核记录ID、合同ID、审核员、审核时间、审核结果等字段。
- 风险信息模型:包括风险ID、合同ID、风险类型、风险等级等字段。
- 合规性信息模型:包括合规性ID、合同ID、合规性规则、合规性结果等字段。
3. 数据处理流程
- 数据采集:通过API接口或数据导入功能,从外部系统或本地文件中采集合同数据。
- 数据预处理:对采集到的合同数据进行清洗、去重、格式化等预处理操作。
- 数据存储:将预处理后的数据存储到相应的数据库中。
- 数据分析:利用自然语言处理、机器学习等技术对合同文本进行分析,提取关键信息。
- 风险识别与合规性审核:基于分析结果,对合同进行风险识别和合规性审核。
- 结果存储:将审核结果存储到数据库中,供后续查询和分析。
4. 数据安全与隐私保护
- 数据加密:对敏感数据进行加密存储和传输,确保数据安全。
- 访问控制:实现用户权限管理,限制用户对系统资源的访问。
- 审计日志:记录用户操作和系统事件,便于追踪和审计。
5. 数据备份与恢复
- 定期备份:定期对数据库进行备份,确保数据不丢失。
- 灾难恢复:制定灾难恢复计划,确保在数据丢失或系统故障时能够快速恢复。
6. 数据分析观点
- 数据质量:确保数据质量是数据存储与处理的关键,应定期对数据进行清洗和校验。
- 数据一致性:在分布式数据库架构中,确保数据的一致性至关重要。
- 数据隐私:在处理金融合同数据时,应严格遵守相关法律法规,保护用户隐私。
通过上述数据存储与处理设计,金融合同智能审核系统将实现高效、安全的数据管理,为金融机构提供可靠的合同审核解决方案。
4.4.系统接口设计
系统接口设计是金融合同智能审核系统的重要组成部分,旨在提供标准化、易用的接口,以便与其他系统集成和扩展。以下为系统接口设计的详细内容:
1. 接口设计原则
- 标准化:遵循RESTful API设计原则,确保接口的易用性和一致性。
- 易用性:接口命名清晰、参数明确,便于开发者理解和使用。
- 安全性:采用OAuth 2.0等安全协议,确保接口的安全性。
- 可扩展性:接口设计应考虑未来扩展需求,易于添加新功能。
2. 接口类型
- RESTful API:提供CRUD(创建、读取、更新、删除)操作,支持合同数据、审核结果、用户信息等资源的访问。
- Web服务:提供SOAP或XML-RPC等Web服务接口,支持与其他系统集成。
- 消息队列:采用消息队列(如RabbitMQ或Kafka)实现异步通信,提高系统性能和可靠性。
3. 接口列表
以下为系统接口的详细列表:
| 接口名称 | 请求方法 | URL | 功能描述 |
|---|---|---|---|
| 用户登录 | POST | /api/login | 用户登录接口,返回访问令牌 |
| 用户注册 | POST | /api/register | 用户注册接口,创建新用户 |
| 合同上传 | POST | /api/contracts | 上传合同文件,返回合同ID |
| 合同查询 | GET | /api/contracts/ | 根据合同ID查询合同信息 |
| 审核结果查询 | GET | /api/contracts/{id}/reviews | 根据合同ID查询审核结果 |
| 风险识别 | POST | /api/contracts/{id}/risk | 根据合同ID进行风险识别 |
| 合规性审核 | POST | /api/contracts/{id}/compliance | 根据合同ID进行合规性审核 |
| 用户信息更新 | PUT | /api/users/ | 更新用户信息 |
| 用户权限管理 | POST | /api/users/{id}/permissions | 设置用户权限 |
4. 接口安全机制
- 认证:采用OAuth 2.0等认证机制,确保接口的安全性。
- 授权:根据用户角色和权限,限制对接口的访问。
- 加密:对敏感数据进行加密传输,如访问令牌和用户密码。
5. 接口文档
提供详细的接口文档,包括接口描述、请求参数、响应格式、错误码等信息,方便开发者使用。
6. 创新性
- 动态接口文档:支持动态生成接口文档,便于开发者实时了解接口变化。
- API网关:采用API网关技术,实现接口路由、限流、监控等功能,提高系统性能和安全性。
通过上述系统接口设计,金融合同智能审核系统将提供标准化、易用、安全的接口,方便与其他系统集成和扩展,为金融机构提供高效的合同审核解决方案。
4.5.系统安全与隐私保护设计
确保金融合同智能审核系统的安全性和用户隐私是系统设计的重要环节。以下为系统安全与隐私保护设计的详细内容:
1. 安全策略
- 最小权限原则:用户和系统组件仅拥有完成其任务所需的最小权限。
- 安全开发生命周期:在整个开发过程中,遵循安全开发生命周期,确保安全意识贯穿始终。
- 安全审计:定期进行安全审计,发现并修复潜在的安全漏洞。
2. 访问控制
- 用户认证:采用OAuth 2.0等认证机制,确保用户身份的真实性。
- 用户授权:根据用户角色和权限,限制对系统资源的访问。
- 多因素认证:支持多因素认证,提高账户安全性。
3. 数据加密
- 传输加密:使用TLS/SSL等协议,对数据传输进行加密,防止数据在传输过程中被窃取。
- 存储加密:对敏感数据进行加密存储,如用户密码、合同内容等。
- 数据备份加密:对数据备份进行加密,防止数据泄露。
4. 安全通信
- API安全:对API接口进行安全设计,防止SQL注入、跨站脚本攻击(XSS)等安全漏洞。
- 通信协议:使用安全的通信协议,如HTTPS,确保数据传输的安全性。
5. 隐私保护
- 数据最小化:仅收集完成特定任务所需的最小数据量,减少用户隐私泄露风险。
- 数据匿名化:对收集到的数据进行匿名化处理,确保用户隐私不被泄露。
- 数据访问控制:限制对用户数据的访问,确保数据安全。
6. 安全监控与审计
- 入侵检测:部署入侵检测系统,实时监控系统安全状况,及时发现并响应安全事件。
- 安全日志:记录用户操作和系统事件,便于追踪和审计。
- 安全响应:制定安全事件响应计划,确保在发生安全事件时能够迅速响应。
7. 安全测试与评估
- 渗透测试:定期进行渗透测试,发现并修复潜在的安全漏洞。
- 代码审计:对系统代码进行安全审计,确保代码的安全性。
- 安全培训:对开发人员和运维人员进行安全培训,提高安全意识。
8. 创新性
- 安全沙箱:采用安全沙箱技术,隔离运行恶意代码,防止系统受到攻击。
- 行为分析:利用行为分析技术,识别异常行为,预防内部威胁。
- 人工智能安全:利用人工智能技术,实时监控系统安全状况,提高安全检测的准确性和效率。
通过上述安全与隐私保护设计,金融合同智能审核系统将确保用户数据的安全性和隐私,为金融机构提供可靠的合同审核解决方案。
第5章 系统关键技术研究与实现
5.1.自然语言处理算法实现
自然语言处理(NLP)作为金融合同智能审核系统的核心技术之一,负责对合同文本进行语义解析、信息提取和特征提取。本节将详细介绍系统中所采用的NLP算法实现,包括文本预处理、实体识别、语义角色标注等,并探讨创新性应用。
1. 文本预处理
文本预处理是NLP任务的基础,旨在将原始文本转换为适合进一步处理的形式。系统采用了以下预处理步骤:
-
分词(Tokenization):使用Python的
jieba库进行中文分词,将文本分割成独立的词汇单元。import jieba def tokenize(text): return list(jieba.cut(text)) -
词性标注(Part-of-Speech Tagging):利用
Stanford CoreNLP工具进行词性标注,识别词汇在句子中的语法角色。from stanfordcorenlp import StanfordCoreNLP def pos_tagging(tokens): nlp = StanfordCoreNLP('path/to/stanford-corenlp') tagged_tokens = nlp.tag(tokens) return tagged_tokens -
停用词过滤(Stopword Filtering):去除无意义的停用词,如“的”、“是”、“在”等。
def remove_stopwords(tokens): stopwords = set(["的", "是", "在", "和", "等"]) return [token for token in tokens if token not in stopwords]
2. 实体识别(Named Entity Recognition,NER)
实体识别旨在识别文本中的关键实体,如人名、地名、机构名等。系统采用以下方法实现NER:
-
命名实体识别模型:利用预训练的
BERT模型进行实体识别。from transformers import BertTokenizer, BertForTokenClassification def recognize_entities(text): tokenizer = BertTokenizer.from_pretrained('bert-base-chinese') model = BertForTokenClassification.from_pretrained('bert-base-chinese') inputs = tokenizer(text, return_tensors='pt') outputs = model(**inputs) logits = outputs.logits entities = [] for token, score in zip(inputs.tokens(), logits[0]): if score > 0.5: # 设定阈值 entities.append((token, score)) return entities
3. 语义角色标注(Semantic Role Labeling,SRL)
语义角色标注旨在识别句子中实体的角色和它们之间的关系。系统采用以下方法实现SRL:
-
SRL模型:利用预训练的
AllenNLP库中的BertForSRL模型进行语义角色标注。from allennlp.predictors.predictor import Predictor from allennlp.models.model import Model def semantic_role_labeling(text): predictor = Predictor.from_path('path/to/allennlp-srl-model') result = predictor.predict(sentence=text) return result
4. 创新性应用
为了提高NLP算法在金融合同智能审核系统中的性能,我们进行了以下创新性应用:
-
上下文感知的NLP:通过引入上下文信息,提高NLP模型的准确性和鲁棒性。
-
多模态融合:结合文本和图像信息,如合同扫描图像,以增强文本理解的深度。
-
动态模型更新:开发能够实时学习新知识的NLP模型,以适应金融法规和合同格式的变化。
通过上述NLP算法的实现和创新性应用,金融合同智能审核系统能够更准确地理解和处理合同文本,为后续的风险识别和合规性审核提供有力支持。
5.2.机器学习模型训练与优化
机器学习模型在金融合同智能审核系统中扮演着至关重要的角色,其性能直接影响到风险识别和合规性审核的准确性。本节将详细介绍系统中所采用的机器学习模型训练与优化方法,包括数据预处理、模型选择、训练策略和性能评估。
1. 数据预处理
在训练机器学习模型之前,需要对原始数据进行预处理,以提高模型的泛化能力和训练效率。
-
文本清洗:去除合同文本中的无关信息,如标点符号、特殊字符等。
import re def clean_text(text): return re.sub(r'[^\w\s]', '', text) -
文本向量化:将文本数据转换为数值向量,以便输入到机器学习模型中。系统采用TF-IDF方法进行文本向量化。
from sklearn.feature_extraction.text import TfidfVectorizer def vectorize_text(texts): vectorizer = TfidfVectorizer() tfidf_matrix = vectorizer.fit_transform(texts) return tfidf_matrix -
数据归一化:对数值特征进行归一化处理,以消除不同特征量纲的影响。
from sklearn.preprocessing import StandardScaler def normalize_data(data): scaler = StandardScaler() normalized_data = scaler.fit_transform(data) return normalized_data
2. 模型选择
系统根据任务需求,选择了以下机器学习模型进行训练:
-
支持向量机(Support Vector Machine,SVM):适用于分类任务,通过寻找最佳的超平面来区分不同的类别。
from sklearn.svm import SVC def train_svm(X_train, y_train): model = SVC(kernel='linear') model.fit(X_train, y_train) return model -
随机森林(Random Forest):适用于分类和回归任务,通过构建多个决策树并集成它们的预测结果来提高准确性。
from sklearn.ensemble import RandomForestClassifier def train_random_forest(X_train, y_train): model = RandomForestClassifier() model.fit(X_train, y_train) return model -
神经网络(Neural Network):适用于处理复杂的非线性关系,通过多层神经网络来模拟人脑处理信息的方式。
from keras.models import Sequential from keras.layers import Dense def train_neural_network(X_train, y_train): model = Sequential() model.add(Dense(128, input_dim=X_train.shape[1], activation='relu')) model.add(Dense(64, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) model.fit(X_train, y_train, epochs=10, batch_size=32) return model
3. 训练策略
为了提高模型的性能,系统采用了以下训练策略:
-
交叉验证:通过将数据集分为训练集和验证集,评估模型的性能,并调整模型参数。
from sklearn.model_selection import cross_val_score def cross_validate_model(model, X, y): scores = cross_val_score(model, X, y, cv=5) return scores -
网格搜索:系统地搜索模型参数的最佳组合,以找到最优的模型配置。
from sklearn.model_selection import GridSearchCV def grid_search(model, param_grid, X, y): grid_search = GridSearchCV(model, param_grid, cv=5) grid_search.fit(X, y) return grid_search.best_params_, grid_search.best_estimator_ -
集成学习:结合多个模型的预测结果来提高准确性。
from sklearn.ensemble import VotingClassifier def ensemble_learning(models, X, y): ensemble = VotingClassifier(estimators=models, voting='soft') ensemble.fit(X, y) return ensemble
4. 性能评估
为了评估模型的性能,系统采用了以下指标:
-
准确率(Accuracy):模型正确预测的样本比例。
-
召回率(Recall):模型正确识别为正类的样本比例。
-
F1分数(F1 Score):准确率和召回率的调和平均值。
from sklearn.metrics import accuracy_score, recall_score, f1_score def evaluate_model(model, X_test, y_test): predictions = model.predict(X_test) accuracy = accuracy_score(y_test, predictions) recall = recall_score(y_test, predictions) f1 = f1_score(y_test, predictions) return accuracy, recall, f1
5. 创新性应用
5.3.风险识别与合规性审核算法设计
风险识别与合规性审核是金融合同智能审核系统的核心功能,旨在通过对合同文本的分析,识别潜在风险和合规性问题。本节将详细介绍系统中的风险识别与合规性审核算法设计,包括风险识别模型、合规性审核引擎和风险评估方法。
1. 风险识别模型
风险识别模型用于识别合同中的潜在风险,包括信用风险、市场风险和操作风险等。系统采用以下方法实现风险识别:
-
特征工程:从合同文本中提取与风险相关的特征,如合同条款、金额、期限、当事人等。
def extract_features(text): # 提取特征,例如合同条款类型、金额、期限等 features = { 'term': extract_term(text), 'amount': extract_amount(text), 'party': extract_party(text), # ... 其他特征 } return features -
分类模型:采用机器学习分类模型,如支持向量机(SVM)、随机森林(Random Forest)和梯度提升机(Gradient Boosting Machine,GBM)等,对提取的特征进行分类。
from sklearn.ensemble import RandomForestClassifier def train_risk_model(X_train, y_train): model = RandomForestClassifier() model.fit(X_train, y_train) return model -
模型融合:结合多个分类模型的预测结果,提高风险识别的准确性和鲁棒性。
from sklearn.ensemble import VotingClassifier def ensemble_risk_model(models, X_test): ensemble = VotingClassifier(estimators=models, voting='soft') predictions = ensemble.predict(X_test) return predictions
2. 合规性审核引擎
合规性审核引擎用于检查合同内容是否符合相关法律法规和内部政策。系统采用以下方法实现合规性审核:
-
知识库构建:建立包含金融法规、监管政策和行业标准的知识库。
def build_knowledge_base(): # 构建知识库,例如使用数据库存储法规和规则 pass -
规则提取:从知识库中提取关键规则,如利率限制、资金流向、信息披露等。
def extract_rules(knowledge_base): # 从知识库中提取规则 rules = [] for rule in knowledge_base: rules.append((rule['id'], rule['description'], rule['condition'])) return rules -
规则匹配:将合同内容与提取的规则进行匹配,识别违规情况。
def match_rules(contract, rules): violations = [] for rule in rules: if rule['condition'](contract): violations.append(rule['id']) return violations
3. 风险评估方法
风险评估方法用于量化合同中的风险程度,为后续决策提供依据。
-
风险评分:根据风险识别模型和合规性审核结果,为合同分配风险评分。
def calculate_risk_score(risk_model, compliance_result): risk_score = risk_model.predict([compliance_result])[0] return risk_score -
风险等级划分:根据风险评分,将风险划分为低、中、高等级。
def classify_risk_level(risk_score): if risk_score < 0.5: return '低风险' elif risk_score < 0.8: return '中风险' else: return '高风险'
4. 创新性应用
为了提高风险识别与合规性审核的效率和准确性,系统采用了以下创新性应用:
-
深度学习模型:利用深度学习模型,如卷积神经网络(CNN)和循环神经网络(RNN),对合同文本进行特征提取和风险识别。
-
知识图谱:构建金融领域的知识图谱,实现规则和法规的关联,提高合规性审核的准确性。
-
自适应学习:根据合同文本的特征和风险变化,动态调整风险识别和合规性审核模型,提高系统的适应性和鲁棒性。
通过上述算法设计,金融合同智能审核系统能够有效地识别和评估合同中的风险和合规性问题,为金融机构提供可靠的决策支持。
5.4.系统模块实现细节
本节将详细阐述金融合同智能审核系统中各个模块的实现细节,包括合同解析模块、风险识别模块、合规性审核模块、用户管理模块、数据管理模块和系统监控模块。每个模块的实现将结合具体的技术和方法,并体现创新性分析。
1. 合同解析模块
合同解析模块负责对金融合同文本进行预处理、分词、词性标注、实体识别和语义分析,以提取关键信息。
-
文本预处理:使用Python的
jieba库进行中文分词,并去除停用词。import jieba def preprocess_text(text): tokens = jieba.cut(text) filtered_tokens = [token for token in tokens if token not in stopwords] return filtered_tokens -
实体识别:利用预训练的
BERT模型进行实体识别,识别合同中的关键实体。from transformers import BertTokenizer, BertForTokenClassification def identify_entities(text): tokenizer = BertTokenizer.from_pretrained('bert-base-chinese') model = BertForTokenClassification.from_pretrained('bert-base-chinese') inputs = tokenizer(text, return_tensors='pt') outputs = model(**inputs) logits = outputs.logits entities = [] for token, score in zip(inputs.tokens(), logits[0]): if score > 0.5: # 设定阈值 entities.append((token, score)) return entities -
语义分析:结合实体识别结果,对合同文本进行语义分析,理解合同条款之间的关系。
def semantic_analysis(text, entities): # 基于实体和语义信息进行合同条款分析 pass
2. 风险识别模块
风险识别模块基于机器学习模型,对合同文本进行风险分类和风险评估。
-
模型选择:选择合适的机器学习模型,如支持向量机(SVM)、随机森林(Random Forest)和梯度提升机(GBM)等。
from sklearn.ensemble import RandomForestClassifier def train_risk_model(X_train, y_train): model = RandomForestClassifier() model.fit(X_train, y_train) return model -
特征提取:从合同文本中提取与风险相关的特征,如金额、期限、当事人等。
def extract_risk_features(text): # 提取风险相关特征 features = { 'amount': extract_amount(text), 'term': extract_term(text), 'party': extract_party(text), # ... 其他特征 } return features -
风险评估:利用训练好的模型对合同进行风险评估,并输出风险等级。
def assess_risk(model, features): risk_score = model.predict([features])[0] risk_level = classify_risk_level(risk_score) return risk_level
3. 合规性审核模块
合规性审核模块结合金融法规和合规性知识库,对合同进行合规性审核。
-
知识库构建:构建包含金融法规、监管政策和行业标准的知识库。
def build_knowledge_base(): # 构建知识库 pass -
规则匹配:将合同内容与知识库中的规则进行匹配,识别违规情况。
def match_rules(contract, rules): violations = [] for rule in rules: if rule['condition'](contract): violations.append(rule['id']) return violations -
合规性评估:根据规则匹配结果,对合同进行合规性评估。
def assess_compliance(contract, rules): violations = match_rules(contract, rules) compliance_level = '合规' if not violations else '违规' return compliance_level
4. 用户管理模块
用户管理模块负责用户注册、登录、权限管理和用户信息管理。
-
用户注册:实现用户注册功能,包括用户信息收集和验证。
def register_user(username, password, email): # 用户注册逻辑 pass -
用户登录:实现用户登录功能,包括用户身份验证和权限检查。
def login_user(username, password): # 用户登录逻辑 pass -
权限管理:根据用户角色和权限,限制用户对系统资源的访问。
def manage_user_permissions(user_id, permissions): # 用户权限管理逻辑 pass
5. 数据管理模块
数据管理模块负责数据导入、导出、备份和恢复等功能
5.5.系统集成与测试
系统集成与测试是确保金融合同智能审核系统稳定、可靠和高效运行的关键环节。本节将详细介绍系统集成的策略、测试方法和创新性测试手段。
1. 系统集成
系统集成的目标是确保各个模块之间能够无缝协作,并满足系统整体的功能和性能要求。
-
模块接口定义:定义清晰的模块接口,包括API接口、数据接口和事件驱动接口。
# 示例:定义一个合同解析模块的接口 def parse_contract(contract_text): # 解析合同文本并返回解析结果 pass -
模块间通信:采用消息队列(如RabbitMQ或Kafka)实现模块间的异步通信,提高系统性能和可靠性。
# 示例:使用RabbitMQ发送消息 import pika connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() channel.queue_declare(queue='contract_queue') def callback(ch, method, properties, body): # 处理接收到的消息 pass channel.basic_consume(queue='contract_queue', on_message_callback=callback) channel.start_consuming() -
集成测试:对集成后的系统进行测试,确保各个模块能够协同工作。
# 示例:集成测试脚本 def test_integration(): # 测试集成后的系统功能 pass
2. 测试方法
测试方法包括功能性测试、非功能性测试和集成测试,以确保系统的全面质量。
-
功能性测试:验证系统是否满足预定的功能需求。
- 单元测试:对系统中的每个模块进行单独测试,确保其正确性。
# 示例:单元测试合同解析模块 def test_parse_contract(): # 测试合同解析模块的功能 pass- 集成测试:对集成后的系统进行测试,确保各个模块能够协同工作。
# 示例:集成测试脚本 def test_integration(): # 测试集成后的系统功能 pass -
非功能性测试:评估系统的性能、安全性和用户体验。
- 性能测试:测试系统的响应时间、并发处理能力和资源消耗。
# 示例:性能测试脚本 def test_performance(): # 测试系统性能 pass- 安全性测试:验证系统的安全措施,如数据加密、访问控制和审计日志。
# 示例:安全性测试脚本 def test_security(): # 测试系统安全性 pass- 用户体验测试:评估系统的易用性和用户界面设计。
# 示例:用户体验测试脚本 def test_user_experience(): # 测试用户体验 pass -
自动化测试:采用自动化测试工具(如Selenium、JMeter等)进行测试,提高测试效率和覆盖率。
# 示例:使用Selenium进行自动化测试 from selenium import webdriver def test_automated(): driver = webdriver.Chrome() driver.get('http://example.com') # 进行自动化测试 driver.quit()
3. 创新性测试手段
为了提高测试效率和准确性,系统采用了以下创新性测试手段:
-
模糊测试:生成大量随机输入,测试系统对异常输入的处理能力。
# 示例:模糊测试脚本 def fuzzy_test(): # 生成随机输入并测试系统 pass -
负载测试:模拟高并发访问,测试系统的稳定性和性能。
# 示例:负载测试脚本 def load_test(): # 模拟高并发访问 pass -
安全测试:利用漏洞扫描工具和渗透测试技术,发现系统潜在的安全漏洞。
# 示例:安全测试脚本 def security_test(): # 执行安全测试 pass
通过上述系统集成与测试方法,金融合同智能审核系统能够确保其高质量和可靠性,为金融机构提供高效的合同审核解决方案。
第6章 系统测试与评估
6.1.测试环境与数据准备
为确保金融合同智能审核系统测试的准确性和有效性,以下为测试环境的构建和数据准备的详细说明。
1. 测试环境搭建
- 硬件配置:配置高性能服务器,满足系统运行和测试需求,包括CPU、内存、存储等硬件资源。
- 操作系统:选用稳定可靠的操作系统,如Linux或Windows Server,确保系统环境的一致性。
- 数据库系统:选择合适的数据库系统,如MySQL或PostgreSQL,用于存储测试数据和系统日志。
- 开发工具:安装并配置相应的开发工具,如Python开发环境、IDE(集成开发环境)等。
- 网络环境:模拟真实网络环境,包括防火墙、代理服务器等,确保测试环境与实际使用环境一致。
2. 测试数据准备
- 数据来源:收集真实金融合同数据,包括不同类型、不同复杂度的合同样本。
- 数据清洗:对收集到的合同数据进行清洗,去除无关信息,确保数据质量。
- 数据标注:对清洗后的合同数据进行标注,包括合同类型、风险等级、合规性结果等,为测试提供参考标准。
- 数据分布:根据合同类型、风险等级等因素,合理分布测试数据,确保测试数据的全面性和代表性。
3. 创新性应用
- 数据增强:采用数据增强技术,如数据变换、数据插值等,扩充测试数据集,提高测试的鲁棒性。
- 模拟数据生成:利用生成对抗网络(GAN)等技术生成模拟数据,用于测试系统在未知场景下的表现。
- 多模态数据融合:结合文本数据和非文本数据(如合同扫描图像),提高测试数据的丰富性和准确性。
4. 系统测试与评估流程
- 测试计划制定:根据测试需求,制定详细的测试计划,包括测试目标、测试方法、测试用例等。
- 测试用例设计:设计覆盖系统各个功能的测试用例,确保测试的全面性和有效性。
- 测试执行:按照测试计划执行测试用例,记录测试结果,分析测试数据。
- 测试结果分析:对测试结果进行分析,评估系统性能、功能、安全性和用户体验。
- 测试报告撰写:根据测试结果,撰写详细的测试报告,包括测试过程、测试结果、问题总结和改进建议。
通过上述测试环境与数据准备,本系统将能够进行深入、全面的测试,确保系统在真实应用场景下的稳定性和可靠性。
6.2.系统功能性测试
为确保金融合同智能审核系统的功能正确性和有效性,以下为系统功能性测试的详细说明。
1. 功能测试用例设计
- 测试用例覆盖范围:确保测试用例覆盖系统所有功能模块,包括合同文本解析、风险识别、合规性审核、用户管理、数据管理等。
- 测试用例设计原则:遵循测试用例设计原则,如输入有效性测试、边界值测试、错误处理测试等。
- 测试用例执行顺序:按照功能模块的依赖关系和优先级执行测试用例。
2. 功能测试内容
-
合同文本解析与信息提取
- 输入测试:测试各种格式的合同文本输入,如PDF、Word、图片等。
- 输出测试:验证系统是否能够正确提取合同中的关键信息,如当事人、金额、期限等。
- 错误处理测试:测试系统在遇到错误输入或格式不正确时,是否能给出合理的错误提示。
-
风险识别与合规性审核
- 风险分类测试:验证系统是否能够正确识别合同中的风险类型,如信用风险、市场风险等。
- 风险评估测试:测试系统对风险的量化评估是否准确,包括风险等级划分、风险评分等。
- 合规性审核测试:验证系统是否能够正确识别合同中的合规性问题,并给出相应的整改建议。
-
系统管理功能
- 用户管理测试:测试用户注册、登录、权限管理等功能是否正常。
- 数据管理测试:验证数据导入、导出、备份和恢复等功能是否可靠。
- 系统监控测试:测试系统监控功能是否能够实时反映系统运行状态,包括资源使用情况、错误日志等。
-
用户交互与报告生成
- 用户界面测试:测试用户界面是否友好、易用,符合用户操作习惯。
- 交互式查询测试:验证系统是否能够支持灵活的查询功能,满足用户需求。
- 报告生成测试:测试系统生成的审核报告是否完整、准确,包括风险分析、合规性评估等。
3. 创新性测试方法
- 自动化测试:采用自动化测试工具(如Selenium、JMeter等)进行测试,提高测试效率和覆盖率。
- 模糊测试:生成大量随机输入,测试系统对异常输入的处理能力,提高系统的鲁棒性。
- 负载测试:模拟高并发访问,测试系统的稳定性和性能,确保系统在高负载下的正常运行。
4. 功能测试结果分析
- 功能正确性分析:分析测试结果,验证系统功能是否满足需求规格说明。
- 性能分析:评估系统在处理大量合同数据时的响应时间、资源消耗等性能指标。
- 错误分析:分析系统在测试过程中出现的错误,确定错误原因,并提出改进建议。
通过上述功能性测试,本系统将能够确保其功能的正确性和有效性,为金融机构提供可靠的合同审核解决方案。
6.3.系统非功能性测试
为确保金融合同智能审核系统的非功能性需求得到满足,以下为系统非功能性测试的详细说明。
1. 性能测试
- 响应时间测试:测试系统对用户操作的响应时间,确保系统响应迅速。
import time import requests def test_response_time(url, expected_time): start_time = time.time() response = requests.get(url) end_time = time.time() if end_time - start_time > expected_time: print(f"Response time for {url} is {end_time - start_time:.2f} seconds, which is higher than the expected {expected_time} seconds.") else: print(f"Response time for {url} is {end_time - start_time:.2f} seconds, which meets the expected {expected_time} seconds.") - 并发处理能力测试:测试系统在高并发请求下的处理能力。
import concurrent.futures def handle_request(url): response = requests.get(url) return response.status_code def test_concurrency(url, num_requests): with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor: futures = [executor.submit(handle_request, url) for _ in range(num_requests)] results = [future.result() for future in concurrent.futures.as_completed(futures)] print(f"Concurrent requests: {num_requests}, Successful responses: {sum(results)}") - 数据处理能力测试:测试系统处理大量合同数据的能力。
def test_data_processing_capacity(data, expected_time): start_time = time.time() # 假设data_processing_function是处理数据的函数 data_processing_function(data) end_time = time.time() if end_time - start_time > expected_time: print(f"Data processing time is {end_time - start_time:.2f} seconds, which is higher than the expected {expected_time} seconds.") else: print(f"Data processing time is {end_time - start_time:.2f} seconds, which meets the expected {expected_time} seconds.")
2. 可用性测试
- 易用性测试:测试用户界面是否直观易用,操作流程是否简单易懂。
- 可访问性测试:测试系统是否支持多种浏览器和操作系统,确保不同用户都能访问和使用。
- 用户反馈机制测试:测试用户反馈机制是否能够有效收集用户意见和建议。
3. 安全性测试
- 数据加密测试:测试敏感数据是否经过加密存储和传输。
from cryptography.fernet import Fernet # 生成密钥 key = Fernet.generate_key() cipher_suite = Fernet(key) # 加密数据 encrypted_data = cipher_suite.encrypt(b"Sensitive data") print(f"Encrypted data: {encrypted_data}") # 解密数据 decrypted_data = cipher_suite.decrypt(encrypted_data) print(f"Decrypted data: {decrypted_data}") - 访问控制测试:测试系统是否实现用户权限管理,限制用户对系统资源的访问。
- 审计日志测试:测试系统是否记录用户操作和系统事件,便于追踪和审计。
4. 可维护性测试
- 模块化设计测试:测试系统模块是否独立、可复用,便于维护和升级。
- 代码规范测试:测试代码是否遵循规范,提高代码可读性和可维护性。
- 文档完善测试:测试系统文档是否详细,包括设计文档、使用手册等。
5. 可扩展性测试
- 技术选型测试:测试系统是否采用成熟、稳定的技术架构,便于扩展和升级。
- 接口设计测试:测试系统接口是否标准化,便于与其他系统集成。
- 数据存储测试:测试数据存储方案是否可扩展,支持数据量的增长。
通过上述非功能性测试,本系统将能够确保其稳定、安全、高效和易用,为金融机构提供可靠的合同审核解决方案。
6.4.测试结果分析与评估
为确保金融合同智能审核系统的质量和性能,以下为系统测试结果的详细分析和评估。
1. 功能测试结果分析
-
功能正确性分析:通过对功能测试结果的统计分析,评估系统功能的正确性。以下为代码示例,用于统计功能测试通过率:
def calculate_pass_rate(test_results): pass_count = sum(1 for result in test_results if result['status'] == 'PASS') total_tests = len(test_results) return pass_count / total_tests test_results = [ {'test_name': 'Test1', 'status': 'PASS'}, {'test_name': 'Test2', 'status': 'PASS'}, {'test_name': 'Test3', 'status': 'FAIL'}, {'test_name': 'Test4', 'status': 'PASS'}, ] pass_rate = calculate_pass_rate(test_results) print(f"Functionality pass rate: {pass_rate:.2f}") -
性能分析:通过对性能测试结果的统计分析,评估系统的响应时间、并发处理能力和资源消耗等性能指标。
def calculate_performance_metrics(test_results): response_times = [result['response_time'] for result in test_results if result['status'] == 'PASS'] avg_response_time = sum(response_times) / len(response_times) max_response_time = max(response_times) return avg_response_time, max_response_time performance_results = [ {'test_name': 'Test1', 'response_time': 1.2}, {'test_name': 'Test2', 'response_time': 1.5}, {'test_name': 'Test3', 'response_time': 1.0}, {'test_name': 'Test4', 'response_time': 1.3}, ] avg_response_time, max_response_time = calculate_performance_metrics(performance_results) print(f"Average response time: {avg_response_time:.2f} seconds") print(f"Max response time: {max_response_time:.2f} seconds")
2. 非功能性测试结果分析
-
安全性分析:通过对安全性测试结果的统计分析,评估系统的安全性。
def calculate_security_pass_rate(test_results): pass_count = sum(1 for result in test_results if result['status'] == 'PASS') total_tests = len(test_results) return pass_count / total_tests security_test_results = [ {'test_name': 'SecurityTest1', 'status': 'PASS'}, {'test_name': 'SecurityTest2', 'status': 'PASS'}, {'test_name': 'SecurityTest3', 'status': 'FAIL'}, ] security_pass_rate = calculate_security_pass_rate(security_test_results) print(f"Security pass rate: {security_pass_rate:.2f}") -
可用性分析:通过对可用性测试结果的统计分析,评估系统的易用性和用户界面设计。
-
可维护性分析:通过对可维护性测试结果的统计分析,评估系统的模块化设计、代码规范和文档质量。
3. 创新性分析
- 自动化测试效率:通过自动化测试,提高测试效率和覆盖率,减少人工测试工作量。
- 模糊测试鲁棒性:通过模糊测试,增强系统对异常输入的处理能力,提高系统的鲁棒性。
- 负载测试稳定性:通过负载测试,确保系统在高并发请求下的稳定性和性能。
4. 总结与改进建议
根据测试结果分析,总结系统在功能、性能、安全性和可用性等方面的表现,并提出以下改进建议:
- 功能改进:针对功能测试中发现的错误,进行修复和优化,提高系统的正确性。
- 性能优化:针对性能测试中发现的性能瓶颈,进行优化,提高系统的响应时间和并发处理能力。
- 安全性增强:针对安全性测试中发现的漏洞,进行修复和加固,提高系统的安全性。
- 可用性提升:针对可用性测试中发现的用户界面问题,进行优化,提高系统的易用性。
- 可维护性改善:针对可维护性测试中发现的代码规范和文档问题,进行改进,提高系统的可维护性。
通过以上测试结果分析和评估,本系统将能够确保其质量和性能,为金融机构提供可靠的合同审核解决方案。
6.5.测试总结与建议
本章节将对金融合同智能审核系统的测试过程进行总结,并提出改进建议,以确保系统的高质量、可靠性和实用性。
1. 测试总结
- 功能测试:经过功能测试,系统各项功能均符合设计要求,包括合同文本解析、风险识别、合规性审核、用户管理、数据管理等。
- 性能测试:系统在性能测试中表现出良好的响应时间和并发处理能力,满足高并发场景下的业务需求。
- 安全性测试:系统安全性得到有效保障,数据加密、访问控制和审计日志等功能均符合安全标准。
- 可用性测试:系统界面设计简洁明了,操作流程简单易懂,用户反馈良好。
- 可维护性测试:系统采用模块化设计,代码规范,文档完善,便于维护和升级。
2. 改进建议
-
功能改进
- 扩展性:考虑引入微服务架构,提高系统的可扩展性和可维护性。
- 定制化:根据用户需求,提供定制化的合同审核功能,如自定义风险规则、合规性审核模板等。
-
性能优化
- 缓存机制:引入缓存机制,减少数据库访问次数,提高系统响应速度。
- 负载均衡:采用负载均衡技术,提高系统在高并发场景下的稳定性。
-
安全性增强
- 动态安全策略:根据系统运行情况和安全威胁,动态调整安全策略,提高系统的安全性。
- 入侵检测:部署入侵检测系统,实时监控系统安全状况,及时发现并响应安全事件。
-
可用性提升
- 多语言支持:考虑增加多语言支持,满足国际化业务需求。
- 用户反馈机制:建立完善的用户反馈机制,及时收集用户意见和建议,持续优化用户体验。
-
可维护性改善
- 自动化测试:继续完善自动化测试,提高测试效率和覆盖率,降低人工测试工作量。
- 代码审查:定期进行代码审查,确保代码质量,降低系统故障风险。
3. 创新性总结
- 多模态数据处理:结合文本和图像等多模态数据,提高合同审核的准确性和效率。
- 自适应学习机制:根据用户反馈和合同数据的使用模式,动态调整系统参数和模型,提高系统适应性和鲁棒性。
- 分布式架构:采用分布式架构,提高系统并发处理能力和可扩展性。
4. 结论
通过本次测试,金融合同智能审核系统在功能、性能、安全性和可用性等方面均表现出良好的表现。在后续的开发和优化过程中,我们将根据测试结果和改进建议,持续提升系统的质量和性能,为金融机构提供更加高效、智能的合同审核解决方案。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号