
今日总结12.13
实验5
MapReduce初级编程实践
1.实验目的
(1)通过实验掌握基本的MapReduce编程方法;
(2)掌握用MapReduce解决一些常见的数据处理问题,包括数据去重、数据排序和数据挖掘等。
2.实验平台
(1)操作系统:Linux(建议Ubuntu16.04或Ubuntu18.04)
(2)Hadoop版本:3.1.3
3.实验步骤
(一)编程实现文件合并和去重操作
对于两个输入文件,即文件A和文件B,请编写MapReduce程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新的输出文件C。下面是输入文件和输出文件的一个样例供参考。
输入文件A的样例如下:
|
20170101 x 20170102 y 20170103 x 20170104 y 20170105 z 20170106 x |
输入文件B的样例如下:
|
20170101 y 20170102 y 20170103 x 20170104 z 20170105 y |
根据输入文件A和B合并得到的输出文件C的样例如下:
|
20170101 x 20170101 y 20170102 y 20170103 x 20170104 y 20170104 z 20170105 y 20170105 z 20170106 x |
(一)编程实现文件合并和去重操作
1.启动 hadoop:
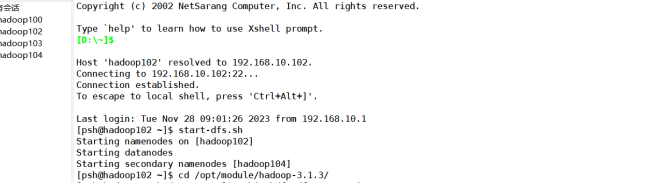
2. 需要首先删除HDFS中与当前Linux用户hadoop对应的input和output目录(即HDFS中的“/opt/module/hadoop-3.1.3/input”和“/opt/module/hadoop-3.1.3/output”目录),这样确保后面程序运行不会出现问题

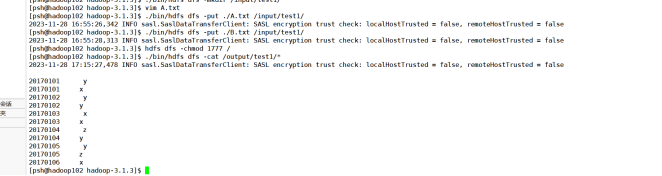
- 再在HDFS中新建与当前Linux用户hadoop对应的input目录,即“/opt/module/hadoop-3.1.3/input”目录,创建A.txt B.txt,输入上述内容

- 将A,B上传到HDFS中和运行结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号