数据结构和算法&刷题题记
First of all, small tricks on leetcode:
setup the variables on for loop expression will reduce the memory cost on leetcode slightly.
convert the collections expression to array expression will reduce the memory cost and increase performance.
数据结构和算法课程要点
+:plus, -: minus, *: mutipled by / times, /:divided by, =: equals / is equal to, >: greater than, <: lesser than. (: opening parenthesis, ): closing parenthesis.
&: and, ~: tilde, |: pipe, ^: caret.
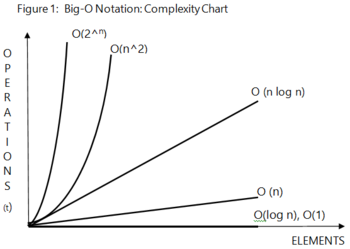
时间复杂度:O(1)=1次;
O(log n)=O(log2n)=2为底的n的对数次运算(23=8 ------> log28=log8=3);
O(n)=n次运算(n次for/while循环);
O(n log n)=O(n log2 n)=2为底的n的对数次运算乘以n(23=8 ----> log28=log8=3n);
O(nm)=n的m次方次运算(n/m次for/while嵌套循环)。
迭代:调用自身直到退出;遍历:循环查询;线性&二分&指数搜索;
哈希表:哈希冲突时,1将相同key装入同一个LinkedList;2)开放寻址,地址池受限时性能下降。
开放寻址:N=1,2,3,4...。Intitial Position=IP=Number%length;
罗宾逊法:若有相同key则自动移至下一位,直到占据空位;
线性探测:= (N + IP) % length;
二次探测:= (N^2+IP)%length;
二次哈希探测:= ((1+Number%7)+IP)%length;
二叉搜索树:left.val<parent.val<right.val;自平衡树二叉树:-1<=左右节点高度<=1;伸展树:parent.val>right.val>left.val,可旋转;
先序(preorder):根左右;中序(inorder):左根右;后序(postorder):左右根。
多路搜索树:父节点的子节点数超过2个;2-3-4树:自平衡多路搜索树,每个节点最多3个key,有2/3/4个子节点;红黑树:红节点下的子节点为黑节点;
冒泡排序:遍历时对比大小并交换元素,n^2;选择排序:选择元素并与目标位置交换,n^2;插入排序:将当前元素插入到之前的合适位置,n^2;
合并排序:二分数组并交换元素直到不可分,O(n log n);快速排序:以某个数字为中心点交换元素,O(n log n)~n^2;桶排序:将数字转换为索引位,O(n+m);
KMP算法:在遍历过程中利用额外空间存储字符串前后缀所在位置,O(m+n);
刷题:
原则:第一遍追求理解题意,写出代码,部分性能优化和总结;第二遍追求拓展题解,性能优化,快速解题,针对性做题;
算法的关键之处在于找出最小可重复运算单元,而性能优化的关键之处在于降低CPU内存开销或者跳过无关边角尽可能快速出值。这类似于经营公司时的商业模式:尽可能的找出最低成本的可重复盈利单元产品,然后融资利用资本优势迅速占领市场扩大生产放大收益。一个失败的产品就在于花费很多时间在无关盈利的产品上,从而消耗时间和资金,这与失败的算法是一样的道理。
中位数:取一组排序过的数组元素的中间位置的值。当数组长度为奇数:取中间位值>M(长度+1)/2;当数组长度为偶数时:取中间2位均值>(M长度/2+M(长度/2+1))/2。
分治:左右分割,分别以左右为小节点计算,然后合并。
二分查找:顺序数组中找特定值;错位前进:找指定位置。
迭代:无界搜索需要使用迭代,有界DFS/BFS可以用。
读题后应该尽可能造例子数据,尝试边界值,根据数据的规律观察解题步骤,进而归纳算法。
1-300题作为练手;5分钟读题,题目不懂看数据,5分钟找思路,没思路直接看题解思路;30分钟内写不出代码,直接看题解代码。
刷题时要考虑面试官把题目变形,改变条件,还能顺势推导。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号