R 语言在数据处理上的禀赋之——独特的数据类型
R 语言天生就有数据处理的禀赋,有很重要的一个原因是R有他自己独特的数据类型。
为啥这样说呢?
Java中的数据类型
先来看看其他传统编程语言中的数据类型是啥样子。拿java来说,java语言中有基本的数据类型,如byte,short,int,long,float,double,boolean等,这几种基本的数据类型有啥特点呢?拿int来说,我们这样定义一个int:
int i = 0;
一个int本身是一个单独的个体,不是【复合】的。什么是【复合】呢?可以看一下java中的数组,比如:
double d [] = new double[3];
d[0]=1;
d[1]=2;
d[2]=3;
这里的一个d里面有三个元素,d[0],d[1],d[2],是复合的,i里面只有一个元素,是单独的。
但是对于数据处理来说,哪一个更好呢?如果说到处理数据的话,二者都是不可或缺的;但是像数学中经常处理如数组,矩阵,向量来说的话,单一的数据类型可搞不定。
R中的数据类型
R语言中,为了处理数组,矩阵,向量以及其他更加复杂的数据,天生就准备好了这样的数据类型:
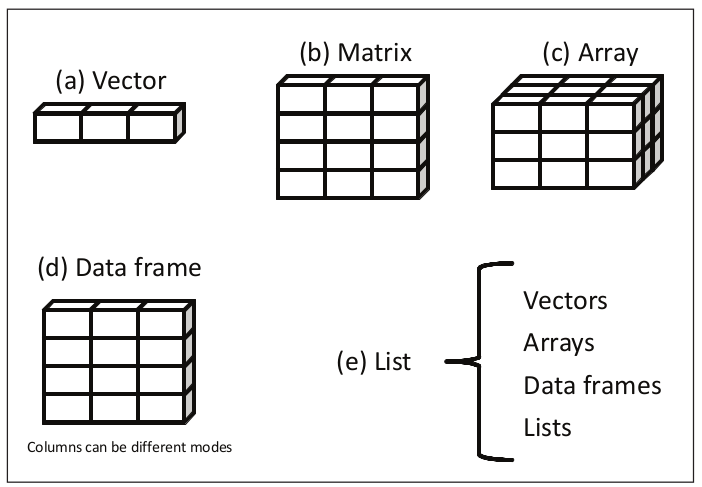
R语言中的数据类型 --摘自《R In Action》
不考虑让人难以理解的数据类型,在R语言中,有5种数据类型,分别为Vector、Matrix、Array、Data frame、和List。
Vector:数组。
你可以想象数学中的一维向量,说白了,就是一串数据排成一排而已。比如:
1,2,3,4,5,6,7,8
就可以是一个数组。
"a","b","c","d","e","f","g"
也可以是一个数组。
1.2,1.4,1.5,1.6,1.7
也可以是一个数组。
在R语言中,用c创建一个数组。比如:
a <- c(1, 2, 5, 3, 6, -2, 4)
b <- c("one", "two", "three")
c <- c(TRUE, TRUE, TRUE, FALSE, TRUE, FALSE)
也可以直接创建单独的元素:
f <- 3 # Scalars are one-element vectors.
g <- "US"
特别说明一下,在R中,没有专门的单读的元素,最小的就是数组了,那么想一个单独的元素怎么表示呢?你可以想想,一个单独的元素,就是一个只有一个元素的数组。
Matrix:矩阵。
你可以想像数学中的矩阵,说白了就是“行列式”。比如:
1 3 5 7
2 4 6 8
是一个“2行4列”的矩阵,因为他有两行,有四列。
"a" "c" "f" "h"
"b" "e" "g" "i"
也是一个有“2行4列”的矩阵,因为他有两行,有四列。
1.2 1.4 1.5 1.6
1.7 1.8 1.9 2.0
也是一个有“2行4列”的矩阵,因为他有两行,有四列。
矩阵可以这样来创建:
cells <- c(1,26,24,68)
m <- matrix(cells,nrow=2,ncol=2)
其中,nrow=2和ncol=2分别代表2行2列的意思。
Array:向量
向量实际上就是矩阵的扩充。你可以把矩阵看成一张饼,比如这里有三个个矩阵,三张饼:
1 3 5
2 4 6
和
7 9 11
8 10 12
和
13 15 17
14 16 18
我们把这三张饼像吃三明治的那样,压在一起,就是一个向量了。
我们可以这样创建一个向量:
z <- array(1:18,c(2,3,3))
1:18代表产生
1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,15,17,18
18个数字,c(2,3,3)代表,向量的格式是3张2行3列的矩阵。
Data frame:数据框
数据框的概念就更容易理解了,考虑下面这一张表,
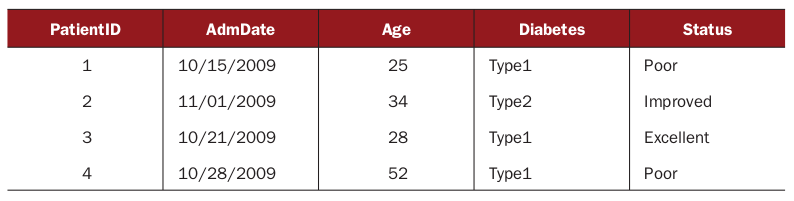
数据框就像一张普通的表--摘自《R In Action》
这张数据框有5列,我们可以简单的看成这个数据框是有5个数组(Vector)合并成的,这5个数组分别为:
patientID <- c(1, 2, 3, 4)
AdmDate <- c("10/15/2009","11/01/2009","10/21/2009","10/28/2009")
age <- c(25, 34, 28, 52)
diabetes <- c("Type1", "Type2", "Type1", "Type1")
status <- c("Poor", "Improved", "Excellent", "Poor")
我们这样创建一张数据框:
patientdata <- data.frame(patientID,AdmDate,age,diabetes,status)
List:链表
链表是一个可以放任何数据类型的一条链。我们可以这样创建一个链表:
g <- "My First List"
h <- c(25, 26, 18, 39)
j <- matrix(1:10, nrow=5)
k <- c("one", "two", "three")
mylist <- list(title=g, ages=h, j, k)
其中title=g 和 ages=h代表的是数据g和h的名字而已,可以不要。
R在语言上的优势
但是,问题来了,java中不是也有数组这样复合的数据类型吗?即使没有,不也可以通过class构造吗?那么R语言中的数据类型有和中高明之处呢?有高明之处,就是R语言中,数据操作起来可不是java中一个元素一个元素的操作。
比如要填满一个1到10的数组:
java中:
int [] v = new int[10];
for (int i=1;i<=10;i++)
v[i] = i;
然而在R语言中:
v <- 1:10
简便很多。你可能会说,R语言这样的写法,python中也有,这算什么?
但这不仅仅是R语言中的语法糖,R语言天生就支持批量操作。再举一个例子,显示一下R语言数据类型操作上的优势。比如,我们要造出一个y=1/x^2的曲线的数组,
用R可以容易的实现这样一张图
y的数据分别为:
1.00000000 0.25000000 0.11111111 0.06250000 0.04000000
0.02777778 0.02040816 0.01562500 0.01234568 0.01000000
如果用java生成的话,恐怕要这样写了:
double y [] = new double[10];
for(int i=0 ;i<y.length;i++)
y[i] = 1/(double)(i+1)^2;
但是在R中,这样写就可以了:
x=1:10
y=1/x^2
后者看起来更加像普通的数学公式呢!
不但如此,仔细观察可以发现,x本来是一列数据,但是在R中就轻易的被当成了一个整体对待。
这个正是我要表达的R语言在数据处理方面的禀赋所在。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号