〈四〉ElasticSearch的认识:基础原理的补充
想想我们漏了什么
这篇文章已经是第四篇了,前面很多都只是讲了基础的使用,没有讲到内层的原理,所以这里就要补一下原理知识了。
回顾
先回顾一下我们前面学过了什么,再想想我们漏了什么。
第一篇我们认识了ElasticSearch,大概知道了ElasticSearch的作用--搜索,也了解了一些倒排索引和分词器的知识(需要补充),然后学习了如何搭建环境(需要补充一下关于基础的集群知识),然后讲了一些基础的ElasticSearch概念(重新讲述,加深了解)。
第二篇讲了索引和文档的CRUD,讲创建索引的时候,没有讲mapping,讲文档的时候没有讲文档的数据类型和元数据,这些都需要补充。
第三篇讲了文档的搜索,主要是语法方面的问题,但相关度分数是怎么计算出来的,我们并没有讲。
补回
所以下面将对前面漏了的基础知识进行补充:
- Json文档的数据格式?【我们之前只会弄一个简单的json,而不知道里面有什么区别】
- 集群的基础认识?【我们之前说了ElasticSearch是一个分布式的系统,但我们之前只讲了如何启动,如何使用kibana操作ElasticSearch,并没有讲ElasticSearch的集群式怎么建立的】
- 节点是怎么提供服务的?【我们之前只知道直接发请求,这个请求ElasticSearch是怎么处理的,我们并不知道】
- 索引的mapping?【之前创建索引的时候,没有说清楚mapping,mapping受文档的数据类型影响,mapping影响查询方式和分词方式】
- 相关度分数score是怎么算出来的?【我们知道score是相关度分数,但我们并不知道这个是怎么算出来的】
- 分词器的原理【第一篇讲了一点,现在加深】
集群的建立
我们说了,ElasticSearch是分布式的,但我们之前只说了如何启动ElasticSearch,然后使用Kibana操作ElasticSearch,并没有讲ElasticSearch的集群式如何建立的,所以下面将会讲一下集群的知识。但如何管理集群会单独做成一篇来讲。
集群发现机制
首先,每一个ElasticSearch服务端就是一个集群节点,当我们启动一个elasticsearch时,就相当于启动了一个集群节点。
那么,多个节点之间如何建立联系呢?当我们启动一个节点的时候,这个节点会自动创建一个集群,集群的名称默认为elasticsearch,当我们再次启动一个节点的时候,它首先会尝试寻找名称为elasticsearch的集群,然后加入其中,(所有的都是先尝试寻找,没有再自己创建)。【集群名称可以自行配置,下面讲】
当节点加入到集群中后,这个集群就算是建立起来了。
配置文件
上面讲了集群名称可以自行配置,下面讲一下怎么配置。
ElasticSearch的配置文件是config/elasticsearch.yml,里面有以下几个配置项:
【左边是配置项,右边是值,修改配置也就是修改右边的值】
- 集群名称:
cluster.name: my-application - 索引存储位置:
path.data: /path/to/data - 日志存储位置:
path.logs: /path/to/logs - 绑定的IP地址:
network.host: 192.168.0.1 - 绑定的http端口:
http.port: 9200 - 是否允许使用通配符来标识索引:
action.destructive_requires_name,true为禁止。
健康状态
当集群建立后,我们可以使用命令来查看集群状态:
GET /_cluster/health:以json方式显示集群状态

GET /_cat/health?v:行列式显示集群状态

返回结果解析:- epoch:时间戳
- timestamp:时间
- cluster:集群名
- status:状态
- 集群状态解析看下面。
- node.total:集群中的节点数
- node.data:集群中的数据节点数
- shards:集群中总的分片数量
- pri:主分片数量
- relo:副本分片数量
- init:初始化中的分片数?【不确定,英文是这样的:number of initializing nodes 】
- unassign:没有被分配的分片的数量
- pending_tasks:待处理的任务数
- max_task_wait_time:最大任务等待时间
- activeds_percent:active的分片数量
集群状态解析:
集群状态受当前的primary shared和replica shared的数量影响。
当每个索引的primary shared和replica shared都是active的时候,状态为green;【什么是active?shard是位于节点上的,一个shard被分配到了运行的节点上,那么此时就是active的,如果shard没有分配到节点上,那么就是inactive】
当每个索引的primary shared都是active的,但replica shared不完全是active的时候,状态为yellow;
当每个索引的primary shared不完全是active的时候,此时发生了数据丢失,状态为red。
为什么现在是yellow?
当我们第一次启动的时候,kibana会默认为我们创建一个名为kibana的索引,这个索引的primary shard和replica shard都为1,由于此时只有一个节点,所以会优先分配primary shard,而忽略replica shard(不要忘了基于备份的安全性的shard排斥考虑:主分片和副本分片不能位于同一个节点上),所以此时就符合了“每个索引的primary shared都是active的,但replica shared不全是active的”,所以此时是yellow.
你可以尝试启动多一个elasticsearch节点来调整状态。【当然,我觉得你学到这里了,此时replica shard的数量可能已经变了,所以这里只启动多一个可能已经不够了,具体的下面“分片的管理”讲】
补充:
- 集群的知识还有很多,这里讲集群只是讲了个开头,对于深层的集群管理并没有涉及,将留到后面集群管理篇讲。
小节总结
上面讲了当启动了一个elasticsearch之后,这个节点先寻找集群,没有的话就自己创建一个,然后后续的其他节点也会加入这个节点,从而自动实现了自动集群化部署。
分片的管理
之前讲了一些分片的知识,但并没有具体用到,可能有些人已经忘了这个概念。这里重新讲一下。
梳理
文档的数据是存储到索引中的,而索引的数据是存储在分片上的,而分片是位于节点上的。
分片shard有主分片primary shard和复制分片replica shard两种,其中主分片是主要存储的分片,可以进行读写操作;副本分片是主分片的备份,可以进行读操作(不支持写操作)。
查询可以在主分片或副本分片上进行查询,这样可以提供查询效率。【但数据的修改只发生在主分片上。】
分片是面向索引的,分片上的数据属于同一个索引,在我们创建索引的时候,可以指定主分片和副本分片的数量,默认是5个主分片,5个副本分片。
索引的replica shard的数量可以修改,但primary shard的数量不可以修改。【一个Primary Shard可以有多个Replica Shard,默认创建是1个。】
修改replica shard数量:
PUT /douban/_settings
{
"number_of_replicas":1
}
为了保证数据的不丢失,通常来说Replica Shard不能与其对应的Primary Shard处于同一个节点中。【因为万一这个节点损坏了,那么存储在这个节点上的原数据(primary shard)和备份数据(replica shard)就全部丢失了】,但是可以和其他primary shard的replica shard放在一起
replica shard是primary shard的副本分片,负责承载一定的读请求,当primary shard都挂掉后,其中一个replica shard会变成primary shard来维持写功能。
分片的均衡分配
分片是分配到节点上的,但它会默认地均衡分配。
所谓均衡分配,以情况举例:【priX代表主分片XX,repX代表副本分片XX】
1.索引有1个priA,1个repA,但当前只有一个节点A,那么priA分配到A节点;repA没有分配。优先分配主分片。
2.索引有1个priA,1个repA,当前有两个节点A和B,那么priA分配到A节点;repA分配到B节点(priA分配到B节点也有可能)。
3.索引当前有2个priA,4个repA,有3个节点,那么现在每台节点上有两个分片(但要考虑主分片不能与自己的副本分片同在一个节点上,在下面的“ 主副分片的排斥”中由一个例子)。
【当后续新增节点的时候,会自动再次重新均衡分配。】
主副分片的排斥
考虑到备份的安全性,不应该让主分片和副本分片位于一个节点上,不然可能完全丢失数据。(比如你为了避免丢失钥匙,你给你家的门准备两条钥匙,你有一个钱包和一个背包,结果你把两条钥匙都放到钱包中,某天你钱包丢了,于是你回不了家了。。。所以你应该把钥匙分开放。)
对应的排斥情况就是:
1.索引有1个priA,1个repA,但当前只有一个节点A,那么priA分配到A节点;repA没有分配。
2.索引有1个priA,1个repA,当前有两个节点A和B,那么priA分配到A节点;repA分配到B节点(priA分配到B节点也有可能)。
【请注意,主分片与副本分片不能在一起,但副本分片和副本分片能存放在一起】
在上面的“分片的均衡分配”没有提到主副分片的排斥的问题,下面再举一个例子【下述的分配结果还有可能是其他的】:
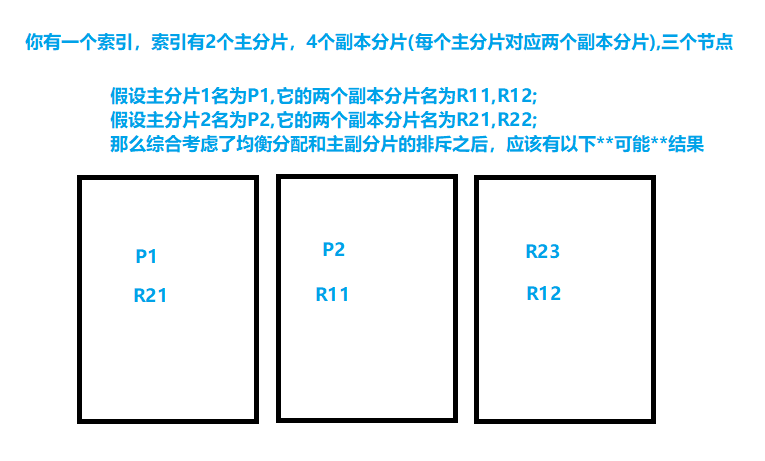
容错性:
既然提到了备份的安全性,那么就不得不提一下容错性了。节点是有可能宕机的,宕机后,那么这个节点的数据起码会暂时性的丢失,那么对于不同情况下,最多可以宕机多少个节点呢?下面举例:【pri = x代表主分片数量为X,rep是副本分片】
1.如果你只有一个节点,那么容错性为0,你不能宕机,宕机不完全意味着数据完全丢失,但暂停服务还是有的。
2.如果你有两个节点,pri = 2,rep = 2,那么此时分片分配应该是[P1R2, P2R1],此时容错性为一个,因为某个节点上有完整的两个分片的数据【此处一提,假设丢失了P2R1,那么R1R2中的R2会升级成primary shard来保持写功能】
3.后面的自己尝试算一下吧!要综合均衡分片和排斥性来考虑。
数据路由
每一个document会存储到唯一的一个primary shared和其副本分片replica shard 中,我们是怎么根据ID来知道这个document存储在哪个分片的呢?
ElasticSearch会自动根据document的id值来进行计算,最终得出一个小于分片数量的数值,这个数值就是分片在ElasticSearch中的序号,最终得出应该存储到哪个分片上。
类似原理举例,假设我现在有4个主分片,那么我给它们标序号0,1,2,3。现在进来一个ID为15的数据,我经过一系列计算之后,15入参之后假设得到243这个数值,然后我们使用243来对4求余,余数是3,所以就把这个数据放在序号为3的分片上。
依据这个原理,存储数据的时候就知道把数据放在哪个分片上;读取数据的时候也知道从哪个分片上读取数据。
【稍微提一下,在ElasticSearch全文搜索完成之后,此时内部得到的是ID组成的数组,内部再会根据ID来查找数据】
对于集群健康状态的影响
上面说了,集群状态受当前的primary shared和replica shared的数量影响。
- 当每个索引的primary shared和replica shared都是active的时候,状态为green;
- 当每个索引的primary shared都是active的,但replica shared不完全是active的时候,状态为yellow;
- 当每个索引的primary shared不完全是active的时候,此时发生了数据丢失,状态为red。
现在学会了“分片的均衡分配”和“主副分片的排斥”后,你应该能分析出要启动多少个节点才能改变集群的健康状态。
下面举个例子,以变green为例:
当前节点中只有一个索引A,索引A当前有2个priA,4个repA,那么此时需要两个节点才可以变green,
一个的时候就不说了,此时所有副本分片都inactive;两个节点的时候,由于每个主分片有两个副本分片,此时的分配是[P1-R11-R12,P2-R21-R22]
小节总结:
本节重新讲了主分片和副本分片的功能,主分片和副本分片都有存储数据的功能,一个索引的数据平分到多个主分片上,副本分片拷贝对应主分片的数据;然后讲了ElasticSearch对于分片的自动均衡分配,和主分片和副本分片不能存储在一起的问题。然后讲了ElasticSearch如何根据ID来判断数据存储在哪个分片上。最后讲了节点上分片的分配对于集群健康状态的影响。
请求的处理
提供服务
- 节点是提供服务的单位,请求是发到节点上的。
- 节点接收到请求后,会对请求进行处理:
- 读请求:
- 当接受读请求,如果是根据ID来获取数据的读请求,那么它会选择有这个ID的数据的分片来获取数据(可以根据ID来判断该分片上是否有这份数据);如果是搜索类的请求,首先会根据索引表来搜索,得出相关文档的ID,然后根据ID从这个索引的相关分片来获取数据(如果有2个pri,2个rep,那么搜索的分片可能是p1r2、p2r1、p1p2,r1r2,只要能完整地获取索引的所有数据即可)。
- 写请求:
- 当接收写请求,节点会选择根据ID来计算应该把这个数据存储到哪个主分片上,然后通过主分片来修改数据,主分片修改完成后,会将数据同步到副本分片上。【由于存在一个同步过程,同步完成之前,某个分片上可能不存在刚刚插入的数据,但概率较小,因为同步是极快的(NRT)】
- 读请求:
- 【再次提醒,主分片有读和写的能力,副本分片只可以读,所以数据的更新都发生在主分片上】
协调节点cordination node
索引的数据是存储在节点上的,当一个请求发到节点上的时候,可能这个节点上并没有这个索引的数据,那么这个时候就需要把请求转发给另一个节点了,这时候原本的节点就是一个“协调节点”。
请求分发的负载均衡
一个索引存储在多个主分片和副本分片上,索引的数据会平均分配到每一个主分片中,然后每一个副本分片拷贝对应主分片的数据。
对于数据存储,数据是存储在分片上的,而分片位于节点上,在上面说了分片会均衡分配到每一个节点上,这样也保证了节点上的数据量是平均的。除此之外,对于读取某一个主分片及其副本分片上的数据的时候,会使用轮询算法来将读请求平均分配(大概意思就是,假设现在对于主分片1有三个副本分片,那么总数为4,假设分别编号1、2、3、4,那么可能地,第一次请求交给了1,那么第二次请求要交给2,第三次要交给3。。。以此类推,超过4则从头开始)。
补充:
- 除了上面的内容,还有一些与集群比较相关的内容,比如某节点宕机后会发生什么。这些会留到集群管理篇再讲。
小节总结
本节简单说了一下读写操作的流程,ID类的读请求直接根据ID来查找文档,搜索类的读请求先搜索索引表,再根据ID来查找文档;写数据请求会根据ID来计算应该把这个数据存储到哪个主分片上,然后通过主分片来修改数据;最后讲了一下对于请求分发的负载均衡,一方面通过数据量的平均分配来均衡,一方面使用轮询算法来降低单个分片的处理压力。
文档的元数据
你在查询文档的时候,你可能看到返回结果中有如下的内容:
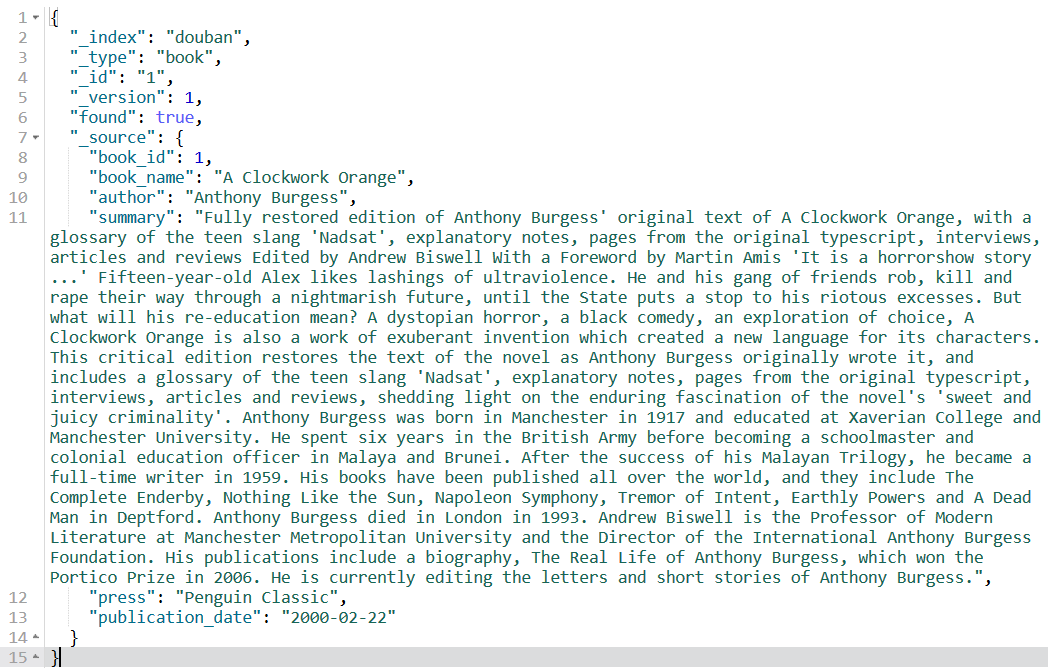
上面的几个前缀有_的就是元数据。
_index:代表当前document存放到哪个index中。_type:代表当前document存放在index的哪个type中。_id:代表document的唯一标识,与index和type一起,可以唯一标识和定位一个document。【在前面我们都是手动指定的,其实可以不手动指定,那样会随机产生要给唯一的字符串作为ID】_version:是当前document的版本,这个版本用于标识这个document的“更新次数”(新建、删除、修改都会增加版本)_source:返回的结果是查询出来的当前存储在索引中的完整的document数据。之前在搜索篇中讲到了,我们可以使用_source来指定返回docuemnt的哪些字段。
元数据与具体的文档数据无关,每一个文档都有这些数据。
文档的数据类型
对于web中的json,数据格式主要有字符串、数值、数组和{}这几种。
比如:
{
"name": "neo",
"age": 18,
"tool": ["clothes", "computer", "gun"],
"gf": {
"feature": "beauty"
}
}
ElasticSearch并不是这样的,因为它要考虑分词,就算是字符串,它也要考虑里面的数据是不是日期类型的,日期类型通常不会分词。
数据类型
ElasticSearch主要有以下这几种数据类型:
- 字符类:
- text:是存储字符串的类型,在elasticsearch中存储会分词的字符串数据一般用text
- keyword:也是存储字符串的类型,在elasticsearch中用于存储不会分词的、结构化的字符串数据
string:string在5.x之前可以使用,现在已被text和keyword取代。
- 整数类型:
- integer
- long
- short
- byte
- 浮点数类型:
- double
- float
- 日期类型:date
- 布尔类型:boolean
- 数组类型:array
- 对象类型:object
【除了上述的类型之外,还有一些例如half_float、scaled_float、binary、ip等等类型,由于不是非常基础的内容,所以这里不讲,有兴趣的可以自查。】
补充:
- 数据类型本身是没有多少重要的知识点,重要的是与数据类型紧密相关的mapping。因为mapping存储的就是索引的结构信息,下面小节将讲述mapping。
mapping
mapping负责维护index中文档的结构,包括文档的字段名、字段数据类型、分词器、字段是否进行分词等。这些属性会对我们的搜索造成影响。
dynamic mapping
在前面,其实我们都没有定义过mapping,直接就是插入数据了。其实这时候ElasticSearch会帮我们自动定义mapping,这个mapping会依据文档的数据来自动生成。
此时,如果数据是字符串的,会认为是text类型,并且默认进行分词;如果数据是日期类型类(字符串里面的数据是日期格式的),那么这个字段会认为是date类型的,是不分词的;如果数据是整数,那么这个字段会认为是long类型的数据;如果数据是小数,那么这个字段会认为是float类型的;如果是true或者false,会认为是boolean类型的。
举例:
我们插入以下数据【如果你用了这个索引,那么可以自定义一个索引,避免我随意创建的数据污染了你的测试数据】:
PUT /test/person/1
{
"name":"suke",
"age":18,
"tall":178.5,
"birthdate":"2018-01-01"
}
然后查看索引,其中mapping定义了我们刚刚定义的字段的信息:
GET /test

创建mapping
【之前在第二篇中有提到,可以通过查看索引来查看mapping】
语法:
【[]代表里面的内容是可选的,非必须的】
PUT /index/
{
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 1
}
},
"mappings": {
"type名": {
"properties": {
"字段名": {
"type": "数据类型",
// 是否索引,不索引则不将这个字段列入索引表,无法对这个字段进行搜索
["index": "是否索引,值为true或者fasle",]
// 是否新旧keyword保留原始数据
["fields": {
"keyword": {
"type": "keyword",【这个是保留原始数据采用的数据类型,也可以使用text,一般用keyword】
"ignore_above": 256【超过多少字符就忽略,不建立keyword】
}
},]
// (选择什么分词器来对这个字段进行分词)
["analyzer": "分词器名称"
,]
}
}
}
}
}
【内容补充:在旧版中,index的值有not_analyzed这样的值,现在只有true或false,它的原意是不分词,现在是不索引,在旧版中,不分词则会保留原始数据,在新版中使用keyword来保留原始数据】
举例:
1.创建一个mapping,只定义数据类型:【定义了每个字段的数据类型后,插入数据的时候并没有说要严格遵循,数据类型的作用是提前声明字段的数据类型,例如在之前第二篇说type的时候,就提到了多个type中的字段其实都会汇总到mapping中,如果不提前声明,那么可能导致因为使用dynamic mapping而使得数据类型定义出错。比如在type1中birthdate字段】
> 第二篇中这样说的:当我们直接插入document的时候,如果不指定document的数据结构,那么ElastciSearch会基于dynamic mapping来自动帮我们声明每一个字段的数据类型,比如"content":"hello world!"会被声明成字符串类型,"post_date":"2017-07-07"会被认为是date类型。如果我们首先在一个type中声明了content为字符串类型,再在另外一个type中声明成日期类型,这会报错,因为对于index来说,这个content已经被声明成字符串类型了。
PUT /test0101
{
"settings": {
"index":{
"number_of_shards":3,
"number_of_replicas":1
}
},
"mappings": {
"person":{
"properties": {
"name":{
"type": "text"
},
"age":{
"type": "long"
},
"birthdate":{
"type":"date"
}
}
}
}
}
2.设置某个字段不进行索引【设置后,你可以尝试对这个字段搜索,会报错!】
PUT /test0102
{
"settings": {
"index":{
"number_of_shards":3,
"number_of_replicas":1
}
},
"mappings": {
"person":{
"properties": {
"name":{
"type": "text",
"index": "false"
},
"age":{
"type": "long"
},
"birthdate":{
"type":"date"
}
}
}
}
}
测试:
PUT /test0102/person/1
{
"name":"Paul Smith",
"age":18,
"birthdate":"2018-01-01"
}
GET /test0102/person/_search
{
"query": {
"match": {
"name": "Paul"
}
}
}
3.给某个字段增加keyword
PUT /test0103
{
"settings": {
"index":{
"number_of_shards":3,
"number_of_replicas":1
}
},
"mappings": {
"person":{
"properties": {
"name":{
"type": "text",
"index": "false",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"age":{
"type": "long"
},
"birthdate":{
"type":"date"
}
}
}
}
}
测试:
PUT /test0103/person/1
{
"name":"Paul Smith",
"age":18,
"birthdate":"2018-01-01"
}
【注意这里是不能使用name来搜索的,要使用name.keyword来搜索,而且keyword是对原始数据进行**不分词**的搜索的,所以你搜单个词是找不到的。】
GET /test0103/person/_search
{
"query": {
"match": {
"name.keyword": "Paul Smith"
}
}
}
修改mapping
mapping只能新增字段,不能修改原有的字段。
// 给索引test0103的类型person新增一个字段height
PUT /test0103/_mapping/person
{
"properties": {
"height":{
"type": "float"
}
}
}
查看mapping
1.之前说过了,可以通过查看索引来查看mapping:GET /index,例如GET /test0103/_mapping
2.通过GET /index/_mapping,例子:GET /test0103/_mapping
3.你也可以附加type来查看指定type包裹的mapping。GET /test0103/_mapping/person
keyword
上面定义mapping的时候有定义一个keyword,这是什么?有什么用?
ElasticSearch对于一些类型的字段,例如text类型的字段,默认是会进行分词的。但如果我们并不想分词呢?一些数据我们想要非常精确地查找,并且只找到我们搜索的数据的时候,这个字段是不应该分词的。那么我们可以使用keyword来存储完整的原有的数据,keyword会作为一个索引词,然后我们针对字段.keyword来搜索。【例子上面已经举例了】理论上,这个不分词的字段的数据应该是比较简短的,太长的话可能就没有必要不分词了。所以在定义keyword的时候还可以提供
"ignore_above": 数值来限制超过多少个字符就不使用原有数据创建keyword.
现在版本中,对于默认分词的字段,现在会默认附加一个keyword。
mapping对分词的影响
1.数据类型的影响:
以date和text类型存储的“日期”类型的数据的分词差异化为例:
date和string这两者都是使用双引号包裹的,与其他数值型的不分词的数据类型不一样。所以以他们两个为例。
PUT /test0104
{
"settings": {
"index":{
"number_of_shards":3,
"number_of_replicas":1
}
},
"mappings": {
"test":{
"properties": {
"post_date":{
"type": "text"
},
"birthdate":{
"type":"date"
}
}
}
}
}
PUT /test0104/test/1
{
"post_date":"2019-09-30",
"birthdate":"2018-08-29"
}
PUT /test0104/test/2
{
"post_date":"2018-09-30",
"birthdate":"2017-08-29"
}
PUT /test0104/test/3
{
"post_date":"2017-09-30",
"birthdate":"2016-08-29"
}
//测试1:结果是ID:1
GET /test0104/test/_search
{
"query": {
"match": {
"post_date": "2019"
}
}
}
// 测试2:结果是ID=1,2,3的文档,理论上text存储的日期格式的没有分词区别
GET /test0104/test/_search
{
"query": {
"match": {
"post_date": "30"
}
}
}
//测试3:结果无,【单搜索08或2017,2018,2016也是无,】
GET /test0104/test/_search
{
"query": {
"match": {
"birthdate": "29"
}
}
}
//测试4, 结果是ID=2的文档
GET /test0104/test/_search
{
"query": {
"match": {
"birthdate": "2017-08-29"
}
}
}
2.不索引的影响:
不索引的时候不会进行分词,甚至不能用于搜索。【低版本对于properties中的index设置不一样,5.x以下是不分词,5.x以上是不索引,不索引就不可以用于搜索】
3.keyword的影响:
keyword适用于不分词的搜索的情况,在keyword中的数据不会分词。
4.其他:
mapping还可以设置分词器来使用不同的分词器来分词。
// 你可以使用格式类似如下的代码来测试mapping中某个字段的分词结果,如果是不允许分词的,则会报Analysis requests are only supported on tokenized fields错误。
GET /test0104/_analyze
{
"field": "post_date",
"text": "2017-09-30"
}
补充:
- dynamic mapping策略是关于自动创建mapping的策略,定义了遇上某某数据的时候把它当作什么类型,比如可以定义存入"2017-09-30"的时候认为是text而不是date,这些内容可能会留到后面再讲,也有可能后面再补充到这里。
- 复合数据类型比较特殊,可能会留到后面再讲,也有可能后面再补充到这里。
小节总结:
本节介绍了什么是mapping,mapping负责管理索引的数据结构和字段的分词等一些配置。在直接存储数据的时候,会dynamic mapping;然后介绍了如何创建mapping,如何修改mapping,如何查看mapping;然后介绍了keyword这个保留原数据的一个特殊的字段。
相关度分数
相关度分数的具体算法我们其实并不需要关心。但可能还是需要大概了解一下计算的方式。
为什么说不需要关心呢?因为实际上相关度是由索引词直接决定的,分析好哪些是用于搜索的词就可以大致分析出相关度排序了。
当然,这只是大概的,因为内部可能因为索引词的重复性问题会降低某个词的score,但差距一般不会太大。
- 在我们进行搜索的时候,你可以看到一个score,这个就是相关度分数,在默认排序中相关度分数最高的会被排在最前面,这个分数是ElasticSearch根据你搜索的内容,使用内部算法计算出的一个数值。
- 内部算法主要是指TF算法和IDF算法。
TF算法
TF算法,全称Term frequency,索引词频率算法。
意义就像它的名字,会根据索引词的频率来计算,索引词出现的次数越多,分数越高。
例子如下:
搜索
hello
有两份文档:A文档:hello world!,B文档:hello hello hello
结果是B文档的score大于A文档。搜索
hello world
有两份文档:A文档:hello world!,B文档:hello,are you ok?
结果是A文档的score大于B文档。要根据索引词来综合考虑。
IDF算法
IDF算法全称Inverse Document Frequency,逆文本频率。
搜索文本的词在整个索引的所有文档中出现的次数越多,这个词所占的score的比重就越低。
例子如下:
搜索
hello world,其中索引中hello出现次数1000次,world出现100次。
有三份文档:A文档hello,are you ok?,B文档The world is interesting!,C文档hello world!
结果是:C>B>A
由于hello出现频率高,所以单个hello得到的score比不上world。
Field-length norm算法。
- 这个算法elasticsearch并没有单独列出来,但也有生效。
- field越长,相关度就越低,数据长度会拉低相关度。
例子如下:
搜索
hello world!
有两份文档:A文档hello world!,B文档hello world,I'm xxx!
结果是:A>B
三种算法的综合:
(下面属于理论分析,并不真实这样计算)
TF算法针对在Field中,索引词出现的频率;
IDF算法针对在整个索引中的索引词出现的频率;
Field-length norm算法针对Field的长度。
那么可以这样分析,由于Field-length norm算法并不直接针对score,所以它是最后起作用的,它理论上类似于一个除数。而TF和IDF是平等的,IDF计算出每一个索引词的score量,TF来计算整个文档中索引词的score的加和。
也就是如下的计算:
1.IDF:计算索引词的单位score,比如hello=0.1,world=0.2,
2.TF:计算整个文档的sum(score),hello world!I'm xxx.得到0.1+0.2=0.3
3.Field-length norm:将sum(score)/对应Field的长度,得出的结果就是score。
score计算API
elasticsearch提供了测试计算score的API,语法类似如下:
GET /index/type/_search?explain=true
{
"query": {
"match": {
"搜索字段": "搜索值"
}
}
}
例子:
GET /douban/book/_search?explain=true
{
"query": {
"match": {
"book_name": "Story"
}
}
}
返回结果数据解析:
_explanation是score的原因,_explanation的格式是先列出分数,然后detail部分解释分数,内层也是。
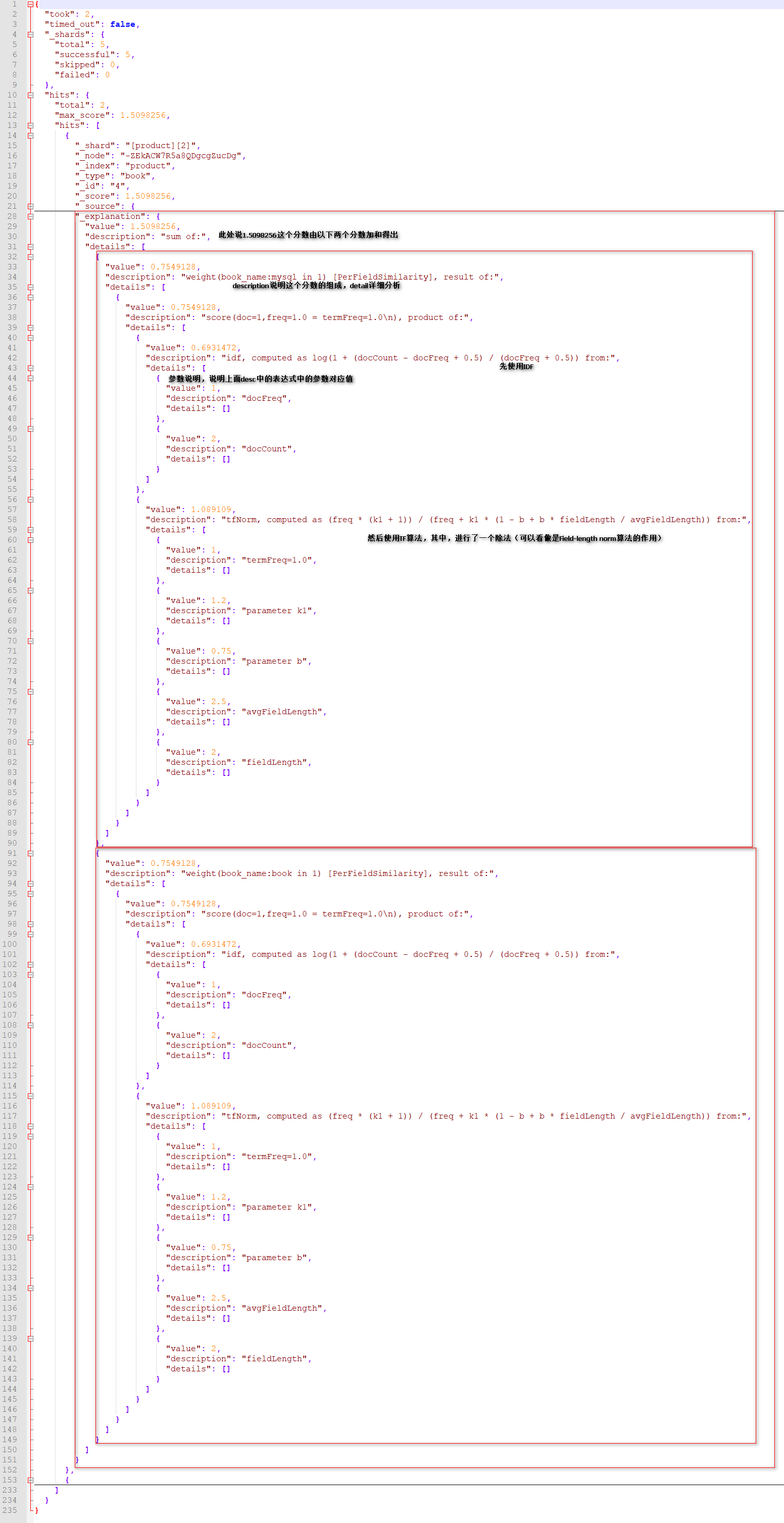
小节总结
这节介绍了相关度分数的计算方式,可以大致了解一下score是怎么得出来得,TF是索引词频率算法,是对索引词分数的加和;IDF是基于整个索引对每个索引词的计算分数;Field-length用于降低数据长的文档的相关度分数。
分词器
什么是分词器?
分词器负责对document进行处理,以提高搜索效率。
分词器通常由分解器tokenizer和词元过滤器token filter组成。分词器对数据的分词处理:为了提高索引的效率,ElasticSearch会数据进行处理,处理方式主要有字符过滤、词转换、词拆分
字符过滤:过滤一些特殊字符,例如&、||、html标签,因为这些词通常搜索意义不大。词转换:把一些意义相同的词统一转成一个词,(同词义转换)比如mom,mother统一转成mom;(大小写转换)he,He统一归为He;还处理一些词意义不大的词(停用词清除),比如英文的“the”,“to”,这些词使用频率很高,但没有具体意义。
词拆分:进行数据的拆分,拆分成词,比如把
good morning,mom拆分成good,morining,mom。另外,词拆分并不完全是按照数据的最小单位分解的,某一些分词器会把一些词进行组合,因为一些词的组合起来才有索引的意义,比如中文的一些词通常要组合起来才有意义,比如“大”和“家”要组成“大家”才有比较具体的意义,这是为了确保索引词的最小单位是有意义的(比如英文mom的最小单位是m,o,m,内部的分词器要能够区分出mom整个是有意义的才可以确保是采用mom作为索引,而不是采用m和o,也正是因为这个问题,所以英文分词器不能用于中文分词器)。【分词器有很多个,默认的分词器是不能适当对中文数据分词的,它只能把一个个数据按最小的单位拆分,因为英文分词器不能分清楚怎么把词拆分才有意义,由于配置分词器是一个较为靠后的知识点,所以前期将以英文数据为测试数据。】
常见的内置分词器:
每一个分词器的都有一些自己的规则,比如一些分词器会把a当成停用词,有些则不会;有些分词器会去掉标点符号,有些则不会;有些分词器能识别英文词,但识别不了中文词。要按需要来选择分词器。
- 标准分词器standard analyzer:最基础的分词器。可以把词进行拆分、
- 简单分词器simple analyzer:分词、做字符过滤、不做词转换。
- 空格分词器whitespace analyzer:仅仅根据空格来划分词,不会做字符过滤也不会做词转换。
- 英文分词器english:根据英文标准来分词,进行字符过滤,进行词转换(去除英文中的停用词(a,the),同义词转换等)
- 小写lowercase tokenizer:把英文全转成小写再分词
- 字母分词器letter tokenizer:根据字母来分词
分词示例
可以使用下面的格式的命令来测试不同分词器的分词效果:
GET /_analyze
{
"analyzer": "分词器",
"text": "要测试的文本"
}
// 举例:
GET /_analyze
{
"analyzer": "simple",
"text": "I am a little boy,I have 5$.dogs,long-distance,<html></html>"
}
示例:
原句:I am a little boy,I have 5$.dogs,long-distance,<html></html>
- 标准分词器standard analyzer:
i,am,a,little,boy,i,have,5,dogs,long,distance,html,html【对于拆分成同一个词的,会形成同一个索引词】【这个分词器,做了小写、去掉特殊字符等操作】 - 简单分词器simple analyzer:
i,am,a,little,boy,i,have,dogs,long,distance,html,html【这个分词器做了小写、去掉特殊字符和数字等操作】 - 空格分词器whitespace analyzer:
I,am,a,little,boy,I,have,5$.dogs,long-distance,<html></html>【根据空格分词】 - 英文分词器英文分词器english::
i,am,littl,boi,i,have,5,dog,long,distanc,html,html【语言分词器会比较特殊,会做一部分的形式转换,有些时候会盲目地切分单词,比如er和e这些常见后缀,会被切掉,所以little变成了littl。】
可能有人不是很懂分词器的作用,这里再次重谈一下:
如果使用的分词器是standard,那你输入的loves会认为是loves,loved会认为是loved;
而english会把loves认为是love,loved认为是love.
所以在english分词器中,loves和loved的搜索用的是love的索引词搜索,而standard中用的是loves和loved的索引词,从搜索效率来说,english的搜索才是我们想要的,它比较灵活。
而且有些分词器会帮你把词组合起来,比如“中国人”这个词不该被拆分成“中”“国”“人”】
修改分词器
修改分词器就是修改mapping中的analyzer,mapping中某个字段一但创建就不能针对这个字段修改,所以只能删除再修改或新增。
PUT /test0106
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
},
"mappings": {
"test":{
"properties": {
"content":{
"type": "text",
"analyzer": "standard"
},
"detail":{
"type": "text",
"analyzer": "english"
}
}
}
}
}
中文分词器
在前面,我们都是使用英文作为字段的数据,因为ElasticSearch默认情况下无法很好地对中文进行分词,它默认只能一个个字地分词,所以它会把“中国人”这个词拆分成“中”“国”“人”。
所以我们需要使用“插件”来对ElasticSearch来进行扩展。
我们常用的中文分词器就是IK分词器。
如何安装
1.去github上下载IK的zip文件,下载的插件版本要与当前使用的elasticsearch版本一致,比如你是elasticsearch6.2.3,就下载6.2.3的【对于没有自己版本的,这时候可能需要下载新的elasticsearch,有些人说可以通过修改pom.xml来强行适配,但还是存在一些问题的。】。github-IK
2.把zip文件中的elasticsearch文件夹解压到elasticsearch安装目录\plugins中,并且重命名文件夹为ik-analyzer
3.然后重启elasticsearch
使用
IK分词器提供了两种分词器ik_max_word和ik_smart
- ik_max_word: 会将文本做最细粒度的拆分,比如
北京天安门广场会被拆分为北京,京,天安门广场,天安门,天安,门,广场,会尝试各种在IK中可能的组合; - ik_smart: 会做最粗粒度的拆分,比如会将
北京天安门广场拆分为北京,天安门广场。 - 一般都会使用ik_max_word,只有在某些确实只需要最粗粒度的时候才使用ik_smart。
// 测试一:比较标准分词器和IK分词器的区别:
// 结果:标准分词器只会一个个字地拆分
GET /_analyze
{
"analyzer": "standard",
"text": "北京天安门广场"
}
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "北京天安门广场"
}
GET /_analyze
{
"analyzer": "ik_smart",
"text": "北京天安门广场"
}
// 测试二:给某个字段的mapping配置分词器为ik_max_word,插入测试数据,并进行搜索
PUT /test0107
{
"mappings": {
"test": {
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
}
PUT /test0107/test/1
{
"content":"北京天安门广场"
}
PUT /test0107/test/2
{
"content":"上海世博会"
}
PUT /test0107/test/3
{
"content":"北京鸟巢"
}
PUT /test0107/test/4
{
"content":"上海外滩"
}
// 开始搜索:
GET /test0107/test/_search
{
"query": {
"match": {
"content": "北京"
}
}
}
GET /test0107/test/_search
{
"query": {
"match": {
"content": "鸟巢"
}
}
}
GET /test0107/test/_search
{
"query": {
"match": {
"content": "世博会"
}
}
}
// 这条搜索是搜索不出结果的,因为分词的结果没有“京”字
GET /test0107/test/_search
{
"query": {
"match": {
"content": "北"
}
}
}
补充:
- 上面说了“分词器通常由分解器tokenizer和词元过滤器token filter组成。”,所以其实我们也可以自己通过组合分解器和过滤器来成形成一个分词器。这里有兴趣自查的。【有可能后面某天会补充】
- 上面提到了中文分词器,其实这已经涉及到了“插件”的内容了,这个内容会后面的篇章再讲。
小节总结:
本节重新解释了分词器的作用(字符过滤,词转换,词拆分),介绍了几种常见的内置的分词器(standard,english这些),并举了一些分词的例子,以及如何修改字段的分词器(mapping的analyzer),最后还介绍了怎么安装支持中文分词的ik分词器。
文档的ID
文档的ID其实是可以不指定的,不指定的时候会随机生成唯一的一串字符串,

手动指定和不指定的区别:
手动指定通常适用于一些将数据库的数据转存到ElasticSearch的场景,因为这时候ID有特殊意义,让数据库的数据与ElasticSearch的数据关联起来,(有时候可能需要同时查数据库和ElasticSearch,那么可以直接根据数据库中的ID来查ElasticSearch中的数据)。
不指定的时候(这时候通常ID是没有特殊意义的),ElasticSearch会自动地帮我们生成一个ID值,自动生成的ID长度为20个字符,这个ID它能确保是不会重复的,就算是在分布式并发情况下也不会发生冲突。【由于此时的ID是随机字符串,所以根据ID来查询数据会比较麻烦】
这里讲的还是比较偏应用方面的基础知识,后面可能还会补充偏底层的一些基础知识,比如底层写入流程和NRT这些。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号