Architecture
To fully understand the STATSPACK architecture, we have to look at the basic nature of the STATSPACK utility. The STATSPACK utility is an outgrowth of the Oracle UTLBSTAT and UTLESTAT utilities, which have been used with Oracle since the very earliest versions.
The BSTAT-ESTAT utilities capture information directly from the Oracle's in-memory structures and then compare the information from two snapshots in order to produce an elapsed-time report showing the activity of the database. If we look inside utlbstat.sql and utlestat.sql, we see the SQL that samples directly from the view: V$SYSSTAT;
insert into stats$begin_stats select * from v$sysstat;
insert into stats$end_stats select * from v$sysstat;
![]()
When a snapshot is executed, the STATSPACK software will
sample from the RAM in-memory structures inside the SGA and transfer the values
into the corresponding STATSPACK tables. These values are then available for
comparing with other snapshots.
![]()
Note that in most cases, there is a direct correspondence
between the v$ view in the SGA and the corresponding STATSPACK table. For
example, we see that the stats$sysstat table is similar to the
v$sysstat view.
SQL> desc v$sysstat;
Name Null?
Type
----------------------------------------- --------
-----------------------
STATISTIC#
NUMBER
NAME
VARCHAR2(64)
CLASS
NUMBER
VALUE
NUMBER
STAT_ID
NUMBER
SQL> desc stats$sysstat;
Name Null?
Type
----------------------------------------- --------
-----------------------
SNAP_ID NOT NULL
NUMBER
DBID NOT NULL
NUMBER
INSTANCE_NUMBER NOT NULL
NUMBER
STATISTIC# NOT NULL
NUMBER
NAME NOT NULL
VARCHAR2(64)
VALUE
NUMBER
It is critical to your understanding of the
STATSPACK utility that you realize the information captured by a STATSPACK
snapshot is accumulated values. The information from the V$VIEWS collects
database information at startup time and continues to add the values until the
instance is shutdown. In order to get a meaningful elapsed-time report, you must
run a STATSPACK report that compares two snapshots as shown above. It is
critical to understand that a report will be invalid if the database is shut
down between snapshots. This is because all of the accumulated values will be
reset, causing the second snapshot to have smaller values than the first
snapshot.
Installing and Configuring STATSPACK
Create PERFSTAT Tablespace
The STATSPACK utility requires an isolated
tablespace to obtain all of the objects and data. For uniformity, it is
suggested that the tablespace be called PERFSTAT, the same name as the schema
owner for the STATSPACK tables. It is important to closely watch the STATSPACK
data to ensure that the stats$sql_summary table is not taking an inordinate
amount of space.
SQL> CREATE TABLESPACE
perfstat
DATAFILE
'/u01/oracle/db/AKI1_perfstat.dbf' SIZE
1000M REUSE
EXTENT MANAGEMENT LOCAL UNIFORM SIZE
512K
SEGMENT SPACE MANAGEMENT AUTO
PERMANENT
ONLINE;
Run the Create Scripts
Now that the tablespace exists, we can begin
the installation process of the STATSPACK software. Note that you must have
performed the following before attempting to install STATSPACK.
-
Run catdbsyn.sql as
SYS
-
Run dbmspool.sql as
SYS
$ cd $ORACLE_HOME/rdbms/admin
$ sqlplus "/ as sysdba"
SQL>
start spcreate.sql
Choose the PERFSTAT user's
password
-----------------------------------
Not specifying a password
will result in the installation FAILING
Enter value for
perfstat_password: perfstat
Choose the Default tablespace for the
PERFSTAT user
---------------------------------------------------
Below is
the list of online tablespaces in this database which can
store user data.
Specifying the SYSTEM tablespace for the user's
default tablespace will
result in the installation FAILING, as
using SYSTEM for performance data is
not supported.
Choose the PERFSTAT users's default tablespace. This is
the tablespace
in which the STATSPACK tables and indexes will be
created.
TABLESPACE_NAME CONTENTS STATSPACK DEFAULT
TABLESPACE
------------------------------ ---------
----------------------------
PERFSTAT PERMANENT
SYSAUX PERMANENT
*
USERS PERMANENT
Pressing <return> will result in STATSPACK's
recommended default
tablespace (identified by *) being used.
Enter
value for default_tablespace: PERFSTAT
Choose the Temporary tablespace for the
PERFSTAT user
-----------------------------------------------------
Below
is the list of online tablespaces in this database which can
store temporary
data (e.g. for sort workareas). Specifying the SYSTEM
tablespace for the
user's temporary tablespace will result in the
installation FAILING, as using
SYSTEM for workareas is not supported.
Choose the PERFSTAT user's
Temporary tablespace.
TABLESPACE_NAME CONTENTS DB DEFAULT TEMP
TABLESPACE
------------------------------ ---------
--------------------------
TEMP TEMPORARY *
Pressing <return>
will result in the database's default Temporary
tablespace (identified by *)
being used.
Enter value for temporary_tablespace: TEMP
.....
.....
Creating Package
STATSPACK...
Package created.
No errors.
Creating Package Body
STATSPACK...
Package body created.
No
errors.
NOTE:
SPCPKG complete. Please check spcpkg.lis for any
errors.
Check the Logfiles: spcpkg.lis, spctab.lis,
spcusr.lis
Adjusting the STATSPACK Collection
Level
STATSPACK has two types of collection options,
level and threshold. The level parameter controls the type of data
collected from Oracle, while the threshold parameter acts as a filter for
the collection of SQL statements into the stats$sql_summary
table.
SQL> SELECT * FROM
stats$level_description ORDER BY snap_level;
| Level 0 |
This level captures general
statistics, including rollback segment, row cache, SGA, system events,
background events, session events, system statistics, wait statistics, lock
statistics, and Latch information. |
| Level 5 |
This level includes capturing high
resource usage SQL Statements, along with all data captured by lower
levels. |
| Level 6 |
This level includes capturing SQL
plan and SQL plan usage information for high resource usage SQL Statements,
along with all data captured by lower levels. |
| Level 7 |
This level captures segment level
statistics, including logical and physical reads, row lock, itl and buffer busy
waits, along with all data captured by lower levels. |
| Level 10 |
This level includes capturing Child
Latch statistics, along with all data captured by lower
levels. |
You can change the default level of a snapshot
with the statspack.snap function. The
i_modify_parameter =>
'true' changes the level permanent for all
snapshots in the future.
SQL> exec
statspack.snap(i_snap_level => 6, i_modify_parameter
=> 'true');
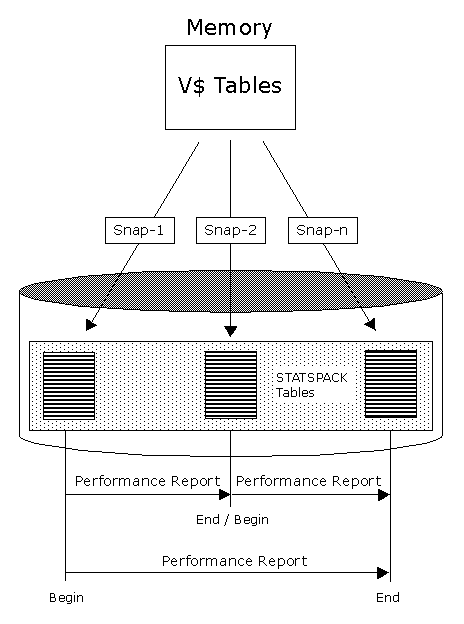
Create, View and Delete
Snapshots
sqlplus perfstat/perfstat
SQL> exec
statspack.snap;
SQL> select
name,snap_id,to_char(snap_time,'DD.MM.YYYY:HH24:MI:SS')
"Date/Time" from
stats$snapshot,v$database;
NAME SNAP_ID
Date/Time
--------- ---------- -------------------
AKI1 4
14.11.2004:10:56:01
AKI1 1
13.11.2004:08:48:47
AKI1 2
13.11.2004:09:00:01
AKI1 3
13.11.2004:09:01:48
SQL>
@?/rdbms/admin/sppurge;
Enter the Lower and Upper
Snapshot ID
Create the Report
sqlplus perfstat/perfstat
SQL>
@?/rdbms/admin/spreport.sql
Statspack at a Glance
What if you have this long STATSPACK report and you want to
figure out if everything is running smoothly? Here, we will review what we look
for in the report, section by section. We will use an actual STATSPACK report
from our own Oracle 10g system.
STATSPACK report
for
DB Name DB Id Instance Inst Num Release RAC
Host
------------ ----------- ------------ -------- ----------- ---
----------------
AKI1 2006521736 AKI1 1 10.1.0.2.0
NO akira
Snap Id Snap Time Sessions Curs/Sess
Comment
--------- ------------------ -------- ---------
-------------------
Begin Snap: 5 14-Nov-04 11:18:00 15
14.3
End Snap: 6 14-Nov-04 11:33:00 15 10.2
Elapsed: 15.00
(mins)
Cache Sizes
(end)
~~~~~~~~~~~~~~~~~
Buffer Cache: 24M Std
Block Size: 4K
Shared Pool Size: 764M Log
Buffer: 1,000K
Note that this section may appear slightly different
depending on your version of Oracle. For example, the Curs/Sess column, which
shows the number of open cursors per session, is new with Oracle9i (an 8i
Statspack report would not show this data).
Here, the item we are most interested in is the elapsed
time. We want that to be large enough to be meaningful, but small enough to
be relevant (15 to 30 minutes is OK). If we use longer times, we begin to
lose the needle in the haystack.
Load
Profile
~~~~~~~~~~~~ Per Second Per
Transaction
---------------
---------------
Redo size: 425,649.84
16,600,343.64
Logical reads: 1,679.69
65,508.00
Block changes: 2,546.17
99,300.45
Physical reads: 77.81
3,034.55
Physical writes: 78.35
3,055.64
User calls: 0.24
9.55
Parses: 2.90
113.00
Hard
parses: 0.16 6.27
Sorts:
0.76 29.82
Logons:
0.01 0.36
Executes: 4.55
177.64
Transactions:
0.03
% Blocks changed per Read:
151.59 Recursive Call %: 99.56
Rollback per transaction %:
0.00 Rows per Sort: 65.61
Here, we are interested in a variety of things, but if we
are looking at a "health check", three items are important:
- The Hard parses (we want very few of them)
- Executes (how many statements we are executing per
second / transaction)
- Transactions (how many transactions per second we
process).
This gives an overall view of the load on the server.
In this case, we are looking at a very good hard parse number and a fairly light
system load (1 - 4 transactions per second is low).
Next, we move onto the Instance Efficiency Percentages
section, which includes perhaps the only ratios we look at in any
detail:
Instance Efficiency
Percentages (Target
100%)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Buffer
Nowait %: 100.00 Redo NoWait %: 99.99
Buffer Hit %:
95.39 In-memory Sort %: 100.00
Library Hit %: 99.42 Soft Parse %:
94.45
Execute to Parse %: 36.39 Latch Hit %: 100.00
Parse CPU to Parse Elapsd %:
59.15 % Non-Parse CPU: 99.31
Shared Pool Statistics Begin
End
------ ------
Memory
Usage %: 10.28 10.45
% SQL with executions>1: 70.10 71.08
% Memory for SQL w/exec>1: 44.52 44.70
The three in bold are the most important: Library Hit, Soft
Parse % and Execute to Parse. All of these have to do with how well the shared
pool is being utilized. Time after time, we find this to be the area of greatest
payback, where we can achieve some real gains in performance.
Here, in this report, we are quite pleased with the Library
Hit and the Soft Parse % values. If the library Hit ratio was low, it
could be indicative of a shared pool that is too small, or just as
likely, that the system did not make correct use of bind variables in the
application. It would be an indicator to look at issues such as
those.
OLTP System
The Soft Parse % value is one of the most important
(if not the only important) ratio in the database. For a typical OLTP system,
it should be as near to 100% as possible. You quite simply do not hard
parse after the database has been up for a while in your typical transactional /
general-purpose database. The way you achieve that is with bind
variables. In a regular system like this, we are doing many executions per
second, and hard parsing is something to be avoided.
Data Warehouse
In a data warehouse, we would like to generally see the
Soft Parse ratio lower. We don't necessarily want to use bind variables in a
data warehouse. This is because they typically use materialized views,
histograms, and other things that are easily thwarted by bind variables. In a
data warehouse, we may have many seconds between executions, so hard parsing is
not evil; in fact, it is good in those environments.
The moral of this is ...
... to look at these ratios and look at how the system
operates. Then, using that knowledge, determine if the ratio is okay given the
conditions. If we just said that the execute-to-parse ratio for your system
should be 95% or better, that would be unachievable in many web-based systems.
If you have a routine that will be executed many times to generate a page, you
should definitely parse once per page and execute it over and over, closing the
cursor if necessary before your connection is returned to the connection
pool.
Moving on, we get to the Top 5 Timed Events section (in
Oracle9i Release 2 and later) or Top 5 Wait Events (in Oracle9i Release 1 and
earlier).
Top 5 Timed
Events
~~~~~~~~~~~~~~~~~~
% Total
Event Waits Time (s)
Call Time
-------------------------------------------- ------------
----------- ---------
CPU
time 122
91.65
db file sequential read 1,571
2 1.61
db file scattered read
1,174 2 1.59
log file
sequential read 342 2
1.39
control file parallel write 450
2 1.39
-------------------------------------------------------------
Wait Events
DB/Inst: AKI1/AKI1 Snaps: 5-6
-> s - second
-> cs -
centisecond - 100th of a second
-> ms - millisecond - 1000th of a
second
-> us - microsecond - 1000000th of a second
-> ordered by
wait time desc, waits desc (idle events last)
This section is among the most important and relevant
sections in the Statspack report. Here is where you find out what events
(typically wait events) are consuming the most time. In Oracle9i Release 2, this
section is renamed and includes a new event: CPU time.
- CPU time is not really a wait event (hence, the new
name), but rather the sum of the CPU used by this session, or the amount of CPU
time used during the snapshot window. In a heavily loaded system, if the CPU
time event is the biggest event, that could point to some CPU-intensive
processing (for example, forcing the use of an index when a full scan should
have been used), which could be the cause of the bottleneck.
- Db file sequential read - This wait event will be
generated while waiting for writes to TEMP space generally (direct loads,
Parallel DML (PDML) such as parallel updates. You may tune the PGA AGGREGATE
TARGET parameter to reduce waits on sequential reads.
- Db file scattered read - Next is the db file
scattered read wait value. That generally happens during a full scan of a
table. You can use the Statspack report to help identify the query in
question and fix it.
Here you will find the most CPU-Time consuming
SQL statements
SQL ordered by Gets
DB/Inst: AKI1/AKI1 Snaps: 5-6
-> Resources reported for PL/SQL code
includes the resources used by all SQL
statements called by the
code.
-> End Buffer Gets Threshold: 10000 Total Buffer Gets:
720,588
-> Captured SQL accounts for 3.1% of Total Buffer Gets
->
SQL reported below exceeded 1.0% of Total Buffer
Gets
CPU
Elapsd Old
Buffer Gets Executions Gets per Exec %Total Time (s)
Time (s) Hash Value
--------------- ------------ -------------- ------
-------- --------- ----------
16,926 1 16,926.0
2.3 2.36 3.46 1279400914
Module: SQL*Plus
create table test as select * from
all_objects
Tablespace
------------------------------
Av Av Av Av Buffer Av Buf
Reads
Reads/s Rd(ms) Blks/Rd Writes Writes/s Waits Wt(ms)
--------------
------- ------ ------- ------------ -------- ---------- ------
TAB
1,643 4 1.0 19.2 16,811 39 0
0.0
UNDO 166 0 0.5 1.0 5,948 14 0
0.0
SYSTEM 813 2 2.5 1.6 167 0 0
0.0
STATSPACK 146 0 0.3 1.1 277 1 0
0.0
SYSAUX 18 0 0.0 1.0 29 0 0
0.0
IDX 18 0 0.0 1.0 18 0 0
0.0
USER 18 0 0.0 1.0 18 0 0
0.0
-------------------------------------------------------------
->A high value for "Pct
Waits" suggests more rollback segments may be required
->RBS stats may not
be accurate between begin and end snaps when using Auto Undo
managment, as
RBS may be dynamically created and dropped as needed
Trans
Table Pct Undo Bytes
RBS No Gets Waits Written
Wraps Shrinks Extends
------ -------------- ------- ---------------
-------- -------- --------
0 8.0 0.00
0 0 0 0
1 3,923.0 0.00
14,812,586 15 0 14
2 5,092.0 0.00
19,408,996 19 0 19
3 295.0 0.00
586,760 1 0 0
4 1,312.0 0.00
4,986,920 5 0 5
5 9.0
0.00 0 0 0 0
6 9.0
0.00 0 0 0 0
7 9.0
0.00 0 0 0 0
8 9.0
0.00 0 0 0 0
9 9.0
0.00 0 0 0 0
10 9.0
0.00 0 0 0 0
-------------------------------------------------------------
->Optimal Size should
be larger than Avg Active
RBS No Segment Size Avg Active
Optimal Size Maximum Size
------ --------------- ---------------
--------------- ---------------
0 364,544
0 364,544
1 17,952,768
8,343,482 17,952,768
2 25,292,800
11,854,857 25,292,800
3 4,321,280
617,292 6,418,432
4 8,515,584
1,566,623 8,515,584
5
126,976 0 126,976
6
126,976 0 126,976
7
126,976 0 126,976
8
126,976 0 126,976
9
126,976 0 126,976
10
126,976 0 126,976
-------------------------------------------------------------
Generate Execution Plan for given SQL
statement
If you have identified one or more problematic
SQL statement, you may want to check the execution plan. Remember the "Old Hash
Value" from the report above (1279400914), then execute the scrip to generate
the execution plan.
sqlplus perfstat/perfstat
SQL>
@?/rdbms/admin/sprepsql.sql
Enter the Hash Value,
in this example: 1279400914
SQL
Text
~~~~~~~~
create table test as select * from all_objects
Known
Optimizer Plan(s) for this Old Hash
Value
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Shows all known
Optimizer Plans for this database instance, and the Snap Id's
they were first
found in the shared pool. A Plan Hash Value will appear
multiple times if
the cost has changed
-> ordered by Snap Id
First
First Plan
Snap Id Snap Time Hash Value
Cost
--------- --------------- ------------ ----------
6 14 Nov 04
11:26 1386862634 52
Plans in shared pool between Begin and End
Snap Ids
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Shows the
Execution Plans found in the shared pool between the begin and end
snapshots
specified. The values for Rows, Bytes and Cost shown below are those
which
existed at the time the first-ever snapshot captured this plan - these
values
often change over time, and so may not be indicative of current values
->
Rows indicates Cardinality, PHV is Plan Hash Value
-> ordered by Plan Hash
Value
--------------------------------------------------------------------------------
|
Operation | PHV/Object Name | Rows | Bytes| Cost
|
--------------------------------------------------------------------------------
|CREATE
TABLE STATEMENT |----- 1386862634 ----| | | 52
|
|LOAD AS SELECT | | |
| |
| VIEW | | 1K|
216K| 44 |
| FILTER | |
| | |
| HASH JOIN |
| 1K| 151K| 38 |
| TABLE ACCESS FULL
|USER$ | 29 | 464 | 2 |
| TABLE ACCESS
FULL |OBJ$ | 3K| 249K| 35 |
| TABLE
ACCESS BY INDEX ROWID |IND$ | 1 | 7 | 2 |
|
INDEX UNIQUE SCAN |I_IND1 | 1 | | 1
|
| NESTED LOOPS | | 5 | 115 |
16 |
| INDEX RANGE SCAN |I_OBJAUTH1 | 1 | 10
| 2 |
| FIXED TABLE FULL |X$KZSRO | 5 |
65 | 14 |
| FIXED TABLE FULL |X$KZSPR | 1
| 26 | 14 |
| FIXED TABLE FULL |X$KZSPR
| 1 | 26 | 14 |
| FIXED TABLE FULL
|X$KZSPR | 1 | 26 | 14 |
| FIXED TABLE
FULL |X$KZSPR | 1 | 26 | 14 |
| FIXED
TABLE FULL |X$KZSPR | 1 | 26 | 14 |
|
FIXED TABLE FULL |X$KZSPR | 1 | 26 | 14
|
| FIXED TABLE FULL |X$KZSPR | 1 | 26 |
14 |
| FIXED TABLE FULL |X$KZSPR | 1 | 26
| 14 |
| FIXED TABLE FULL |X$KZSPR | 1 |
26 | 14 |
| FIXED TABLE FULL |X$KZSPR | 1
| 26 | 14 |
| FIXED TABLE FULL |X$KZSPR
| 1 | 26 | 14 |
| FIXED TABLE FULL
|X$KZSPR | 1 | 26 | 14 |
| FIXED TABLE
FULL |X$KZSPR | 1 | 26 | 14 |
| FIXED
TABLE FULL |X$KZSPR | 1 | 26 | 14 |
|
FIXED TABLE FULL |X$KZSPR | 1 | 26 | 14
|
| FIXED TABLE FULL |X$KZSPR | 1 | 26 |
14 |
| FIXED TABLE FULL |X$KZSPR | 1 | 26
| 14 |
| FIXED TABLE FULL |X$KZSPR | 1 |
26 | 14 |
| FIXED TABLE FULL |X$KZSPR | 1
| 26 | 14 |
| FIXED TABLE FULL |X$KZSPR
| 1 | 26 | 14 |
| VIEW
| | 1 | 13 | 2 |
| FAST
DUAL | | 1 | | 2
|
--------------------------------------------------------------------------------
Resolving Your Wait Events
The following are 10 of the most common causes
for wait events, along with explanations and potential
solutions:
This generally indicates waits related to
full table scans. As full table scans are pulled into memory, they rarely
fall into contiguous buffers but instead are scattered throughout the buffer
cache. A large number here indicates that your table may have missing or
suppressed indexes. Although it may be more efficient in your situation to
perform a full table scan than an index scan, check to ensure that full table
scans are necessary when you see these waits. Try to cache small tables to avoid
reading them in over and over again, since a full table scan is put at the cold
end of the LRU (Least Recently Used) list.
This event generally indicates a single block
read (an index read, for example). A large number of waits here could indicate
poor joining orders of tables, or unselective indexing. It is normal for
this number to be large for a high-transaction, well-tuned system, but it can
indicate problems in some circumstances. You should correlate this wait
statistic with other known issues within the Statspack report, such as
inefficient SQL. Check to ensure that index scans are necessary, and check join
orders for multiple table joins. The DB_CACHE_SIZE will also be a determining
factor in how often these waits show up. Problematic hash-area joins should show
up in the PGA memory, but they're also memory hogs that could cause high wait
numbers for sequential reads. They can also show up as direct path read/write
waits.
This indicates your system is waiting for a
buffer in memory, because none is currently available. Waits in this category
may indicate that you need to increase the DB_BUFFER_CACHE, if all your
SQL is tuned. Free buffer waits could also indicate that unselective SQL is
causing data to flood the buffer cache with index blocks, leaving none for this
particular statement that is waiting for the system to process. This normally
indicates that there is a substantial amount of DML (insert/update/delete) being
done and that the Database Writer (DBWR) is not writing quickly enough; the
buffer cache could be full of multiple versions of the same buffer, causing
great inefficiency. To address this, you may want to consider accelerating
incremental checkpointing, using more DBWR processes, or increasing the
number of physical disks.
This is a wait for a buffer that is being used
in an unshareable way or is being read into the buffer cache. Buffer busy
waits should not be greater than 1 percent. Check the Buffer Wait Statistics
section (or V$WAITSTAT) to find out if the wait is on a segment header. If this
is the case, increase the freelist groups or increase the pctused to
pctfree gap. If the wait is on an undo header, you can address this by
adding rollback segments; if it's on an undo block, you need to reduce the data
density on the table driving this consistent read or increase the DB_CACHE_SIZE.
If the wait is on a data block, you can move data to another block to avoid this
hot block, increase the freelists on the table, or use Locally Managed
Tablespaces (LMTs). If it's on an index block, you should rebuild the index,
partition the index, or use a reverse key index. To prevent buffer busy waits
related to data blocks, you can also use a smaller block size: fewer records
fall within a single block in this case, so it's not as "hot." When a DML
(insert/update/ delete) occurs, Oracle Database writes information into the
block, including all users who are "interested" in the state of the block
(Interested Transaction List, ITL). To decrease waits in this area, you can
increase the initrans, which will create the space in the block to allow
multiple ITL slots. You can also increase the pctfree on the table where
this block exists (this writes the ITL information up to the number specified by
maxtrans, when there are not enough slots built with the initrans
that is specified).
Latches are low-level queuing mechanisms
(they're accurately referred to as mutual exclusion mechanisms) used to protect
shared memory structures in the system global area (SGA). Latches are like locks
on memory that are very quickly obtained and released. Latches are used to
prevent concurrent access to a shared memory structure. If the latch is
not available, a latch free miss is recorded. Most latch problems are related to
the failure to use bind variables (library cache latch), redo generation
issues (redo allocation latch), buffer cache contention issues (cache buffers
LRU chain), and hot blocks in the buffer cache (cache buffers chain). There are
also latch waits related to bugs; check MetaLink for bug reports if you suspect
this is the case. When latch miss ratios are greater
than 0.5 percent, you should investigate the issue.
An enqueue is a lock that protects a shared
resource. Locks protect shared resources, such as data in a record, to prevent
two people from updating the same data at the same time. An enqueue includes a
queuing mechanism, which is FIFO (first in, first out). Note that Oracle's
latching mechanism is not FIFO. Enqueue waits usually point to the ST enqueue,
the HW enqueue, the TX4 enqueue, and the TM enqueue. The ST enqueue is used for
space management and allocation for dictionary-managed tablespaces. Use LMTs, or
try to preallocate extents or at least make the next extent larger for
problematic dictionary-managed tablespaces. HW enqueues are used with the
high-water mark of a segment; manually allocating the extents can circumvent
this wait. TX4s are the most common enqueue waits. TX4 enqueue waits are usually
the result of one of three issues. The first issue is duplicates in a unique
index; you need to commit/rollback to free the enqueue. The second is multiple
updates to the same bitmap index fragment. Since a single bitmap fragment may
contain multiple rowids, you need to issue a commit or rollback to free the
enqueue when multiple users are trying to update the same fragment. The third
and most likely issue is when multiple users are updating the same block.
If there are no free ITL slots, a block-level lock could occur. You can easily
avoid this scenario by increasing the initrans and/or maxtrans to
allow multiple ITL slots and/or by increasing the pctfree on the table.
Finally, TM enqueues occur during DML to prevent DDL to the affected object. If
you have foreign keys, be sure to index them to avoid this general
locking issue.
This wait occurs because you are writing the
log buffer faster than LGWR can write it to the redo logs, or because log
switches are too slow. To address this problem, increase the size of the log
files, or increase the size of the log buffer, or get faster disks to write to.
You might even consider using solid-state disks, for their high
speed.
All commit requests are waiting for "logfile
switch (archiving needed)" or "logfile switch (Checkpoint. Incomplete)." Ensure that the archive disk is not full or slow.
DBWR may be too slow because of I/O. You may need to add more or larger redo
logs, and you may potentially need to add database writers if the DBWR is the
problem.
When a user commits or rolls back data, the
LGWR flushes the session's redo from the log buffer to the redo logs. The log
file sync process must wait for this to successfully complete. To reduce wait
events here, try to commit more records (try to commit a batch of 50 instead
of one at a time, for example). Put redo logs on a faster disk, or alternate
redo logs on different physical disks, to reduce the archiving effect on LGWR.
Don't use RAID 5, since it is very slow for applications that write a lot;
potentially consider using file system direct I/O or raw devices, which are very
fast at writing information.
There are several idle wait events listed after
the output; you can ignore them. Idle events are generally listed at the bottom
of each section and include such things as SQL*Net message to/from client and
other background-related timings. Idle events are listed in the stats$idle_event
table.
Remove STATSPACK from the Database
After a STATSPACK session you want to remove
the STATSPACK tables.
sqlplus "/ as sysdba"
SQL>
@?/rdbms/admin/spdrop.sql
SQL> DROP TABLESPACE perfstat
INCLUDING CONTENTS AND DATAFILES;
|
 by providing data which identifies high-load SQL statements. STATSPACK can be used both proactively to monitor the changing load on a system, and also reactively to investigate a performance problem.
by providing data which identifies high-load SQL statements. STATSPACK can be used both proactively to monitor the changing load on a system, and also reactively to investigate a performance problem.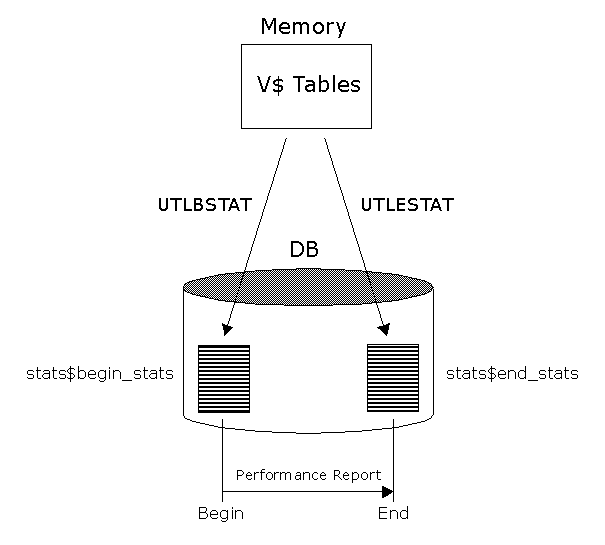

 浙公网安备 33010602011771号
浙公网安备 33010602011771号