PB 12+13
艰苦卓绝的调参之路
没有一个是对的,省流:做了一天无用功。
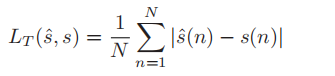
对!今天就是在研究作者大大是如何用MAE得到能看(听)的结果的。
mae abs_in,先绝对值再平均
LOSS = tf.reduce_mean(tf.abs(p_ola-y_ola))
模型有batchnorm
模型无batchnorm
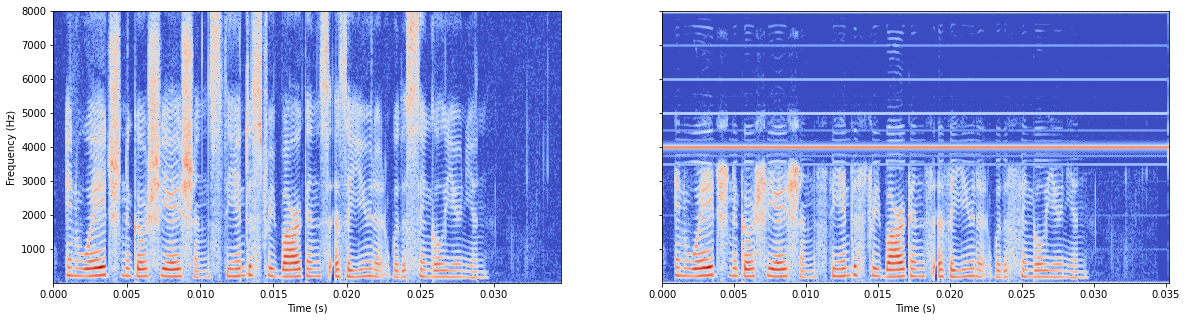
mae abs_in,先平均再绝对值
LOSS = tf.abs(tf.reduce_mean(p_ola-y_ola))
虽然但是,损失函数很小,基本没学的样子,且最高频有细线和公式描述也不符,pass。
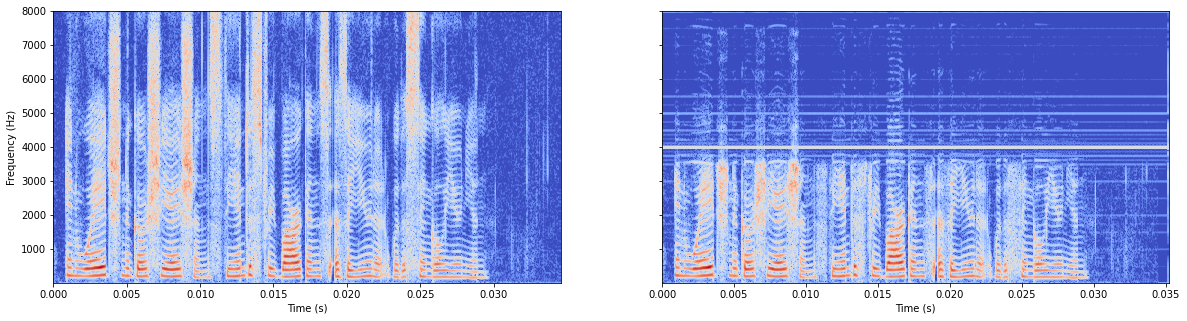
参考github L2
很糟糕
模型有batchnorm
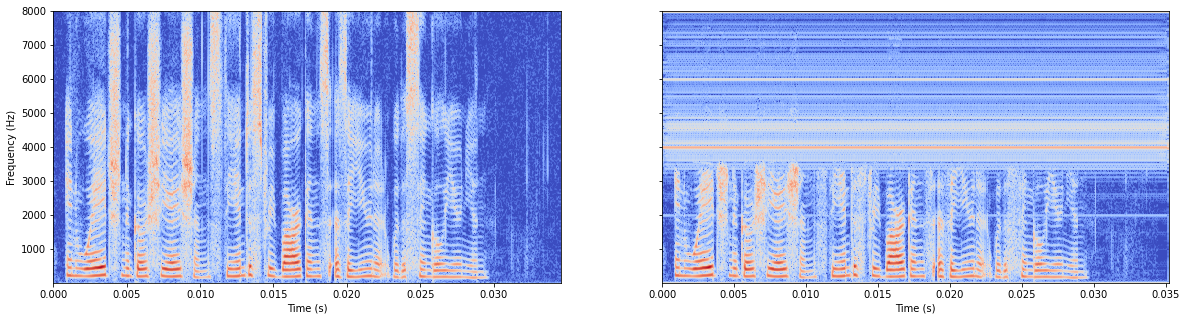
模型无batchnorm
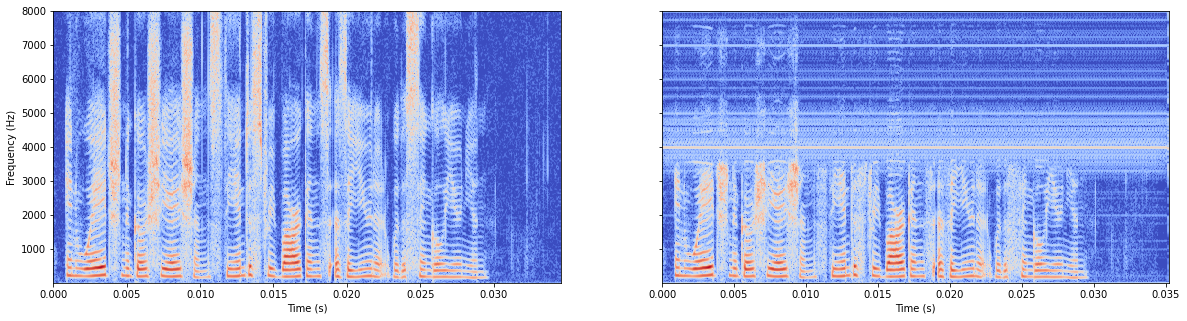
总体感觉无batchnorm更好,所以原作者把这行注释掉了。
以上没有用ola算,按照论文,把P Y换成了p_ola, y_ola
如果求两次平均
sqrt_l2_loss = tf.sqrt(tf.reduce_mean(input_tensor=(p_ola-y_ola)**2, axis=1))
avg_sqrt_l2_loss = tf.reduce_mean(input_tensor=sqrt_l2_loss, axis=0)
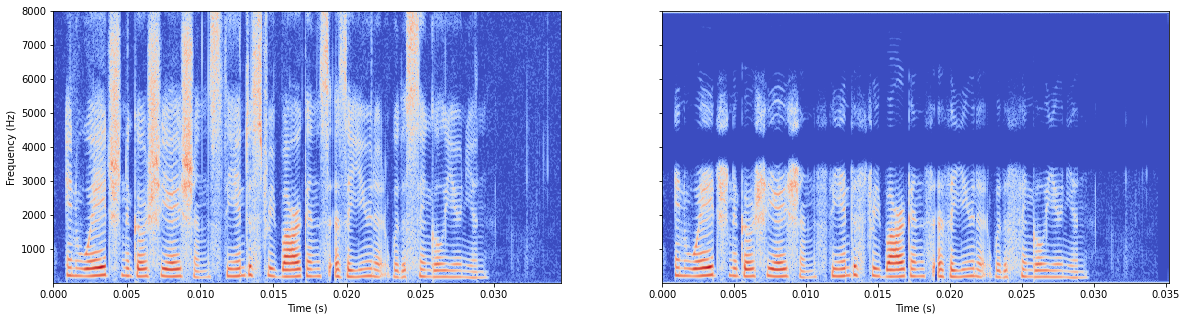
模型有batchnorm
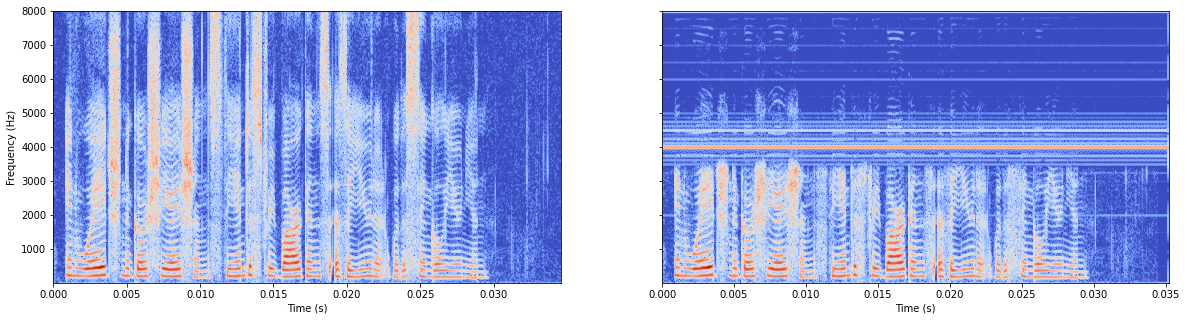
模型无batchnorm
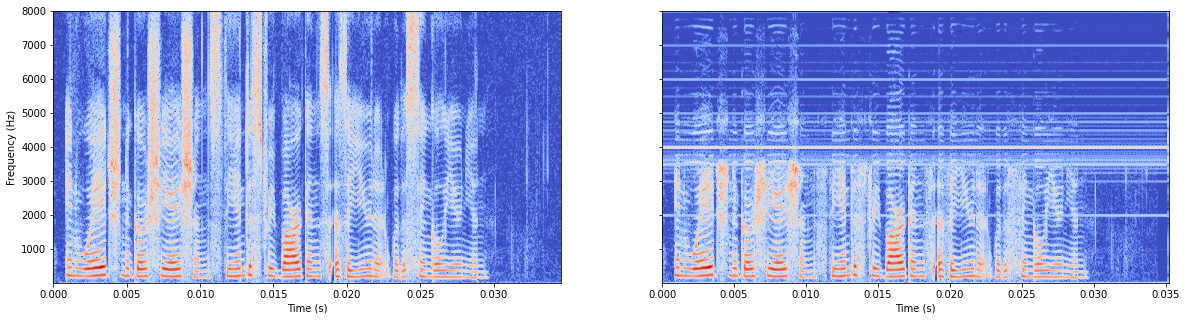
如果求一次平均
sqrt_l2_loss = tf.sqrt(tf.reduce_mean(input_tensor=(p_ola-y_ola)**2))
模型有batchnorm
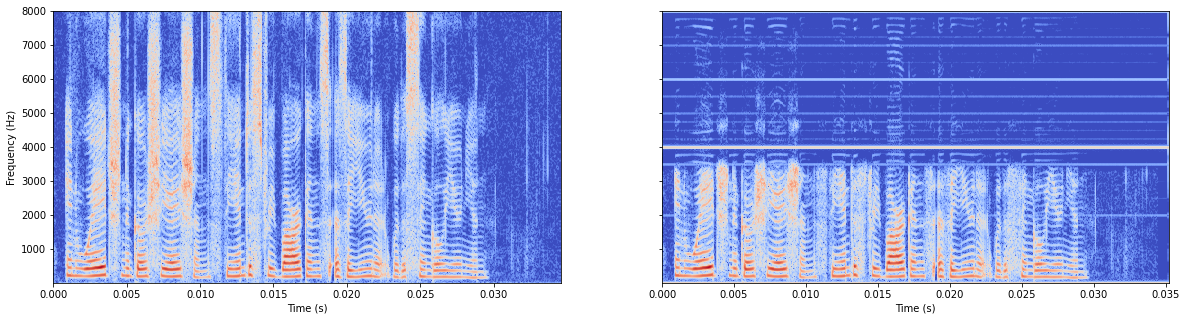
模型无batchnorm
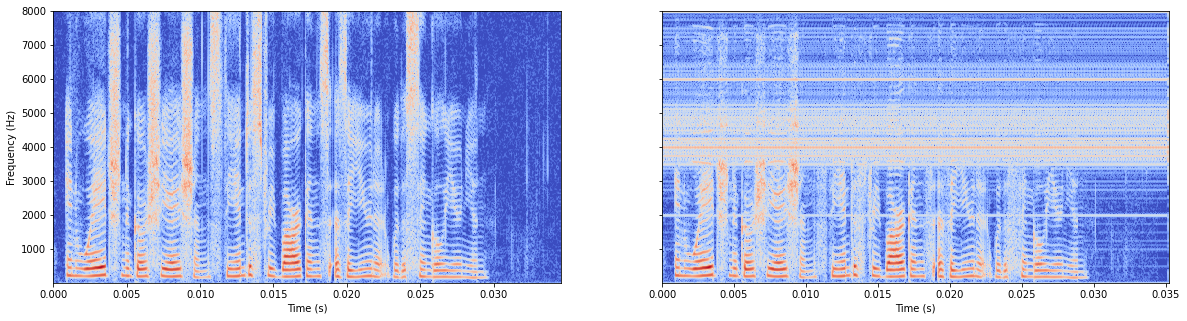
还不放弃,用abs求两次平均
sqrt_l2_loss = tf.reduce_mean(input_tensor=tf.abs(p_ola-y_ola), axis=1)
avg_sqrt_l2_loss = tf.reduce_mean(input_tensor=sqrt_l2_loss, axis=0)
LOSS = avg_sqrt_l2_loss
模型有batchnorm
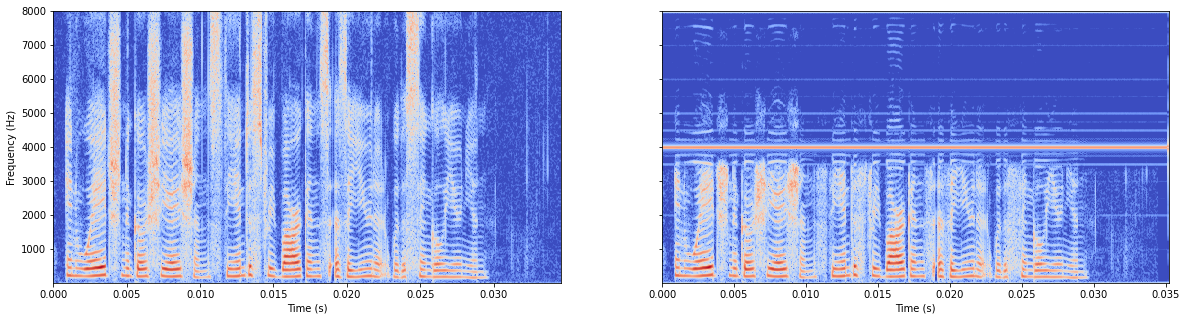
啥也没学到,还有极强的中线,也许是平均求多的缘故。
模型无batchnorm
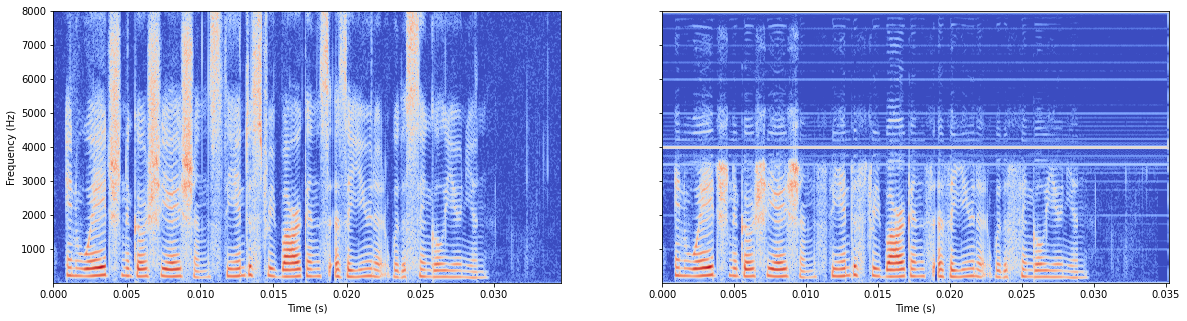
总算是学到点东西了,不过还是有线。
我感觉还是无batchnorm比较好,大意就是少求几次平均。
总体来看我觉得
LOSS = tf.reduce_mean(tf.abs(p_ola-y_ola)),无batchnorm。还挺好的。
现在有两方面的考虑:
1.模型问题?——用audiounet试试。
首先使用官方的参数。
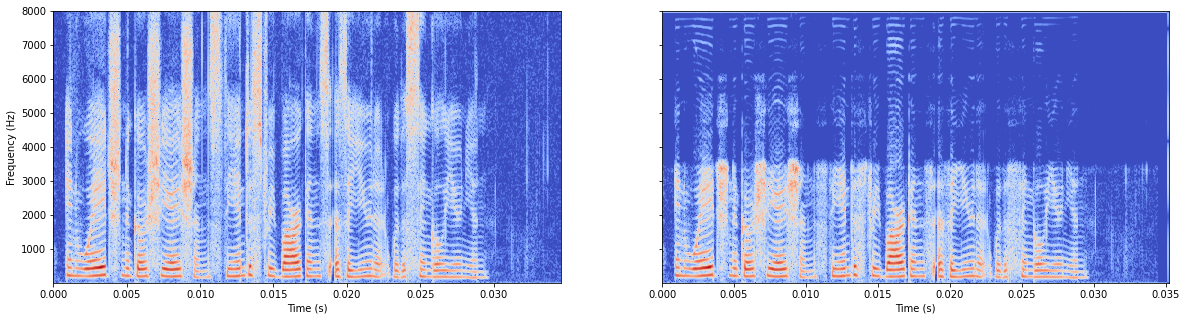
再用我认为最好的
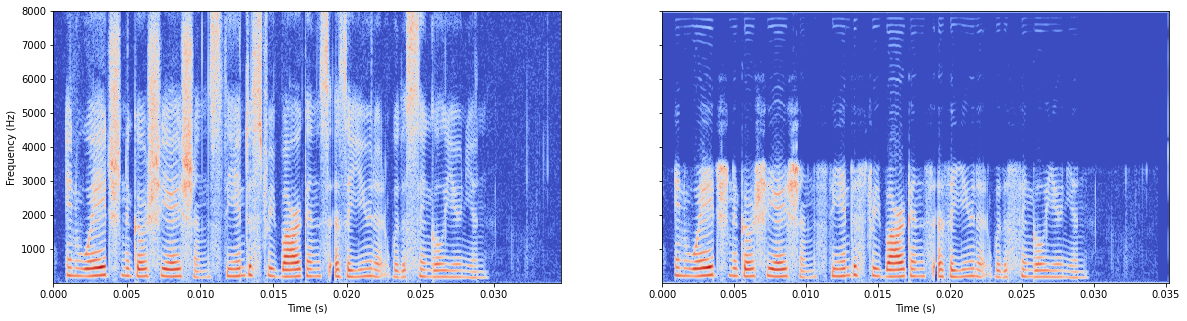
也没问题,甚至学得更清晰了,苦笑
现在在audiounet的基础上只修改
n_filters = [64, 64, 64, 128, 128, 128, 256, 256, 256]
n_filtersizes = [11, 11, 11, 11, 11, 11, 11, 11, 11, 11]
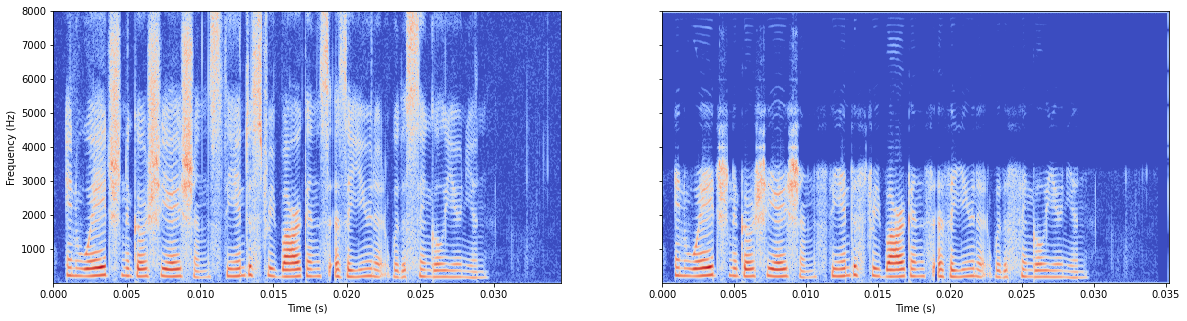
问题也不大。
接着把relu改成prelu
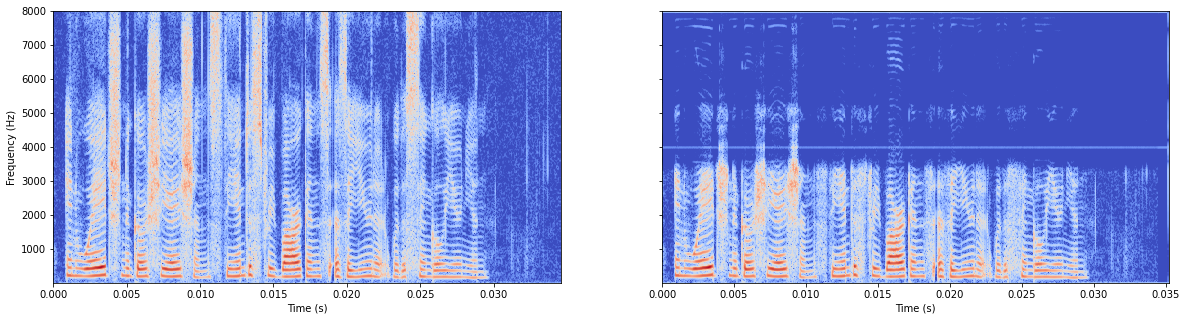
有了。
这正是我问作者的问题。可是他不回复我呀哭。
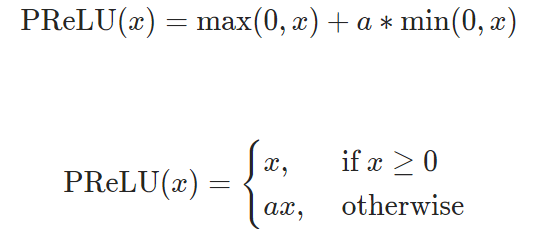
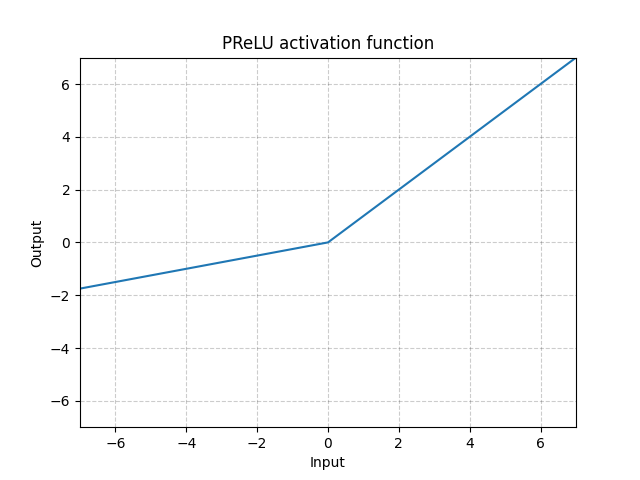

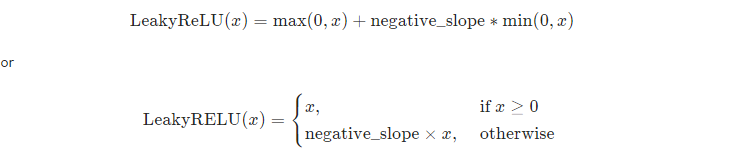
一个网站,值得收藏
https://martin-thoma.com/neuronale-netze-vorlesung/#aktivierungsfunktionen


 浙公网安备 33010602011771号
浙公网安备 33010602011771号