【MyBatis笔记】关于MaBatis的一级缓存 | 二级缓存
在对一级缓存与二级缓存分别进行测试之前,先做一些对类和数据库的准备工作。
PoJo类:
Employee.java
package com.atguigu.mybatis.bean; /** * @author xiaoyi * @create 2021-11-21-21:06 */ public class Employee { private Integer id; private String lastName; private char gender; private String email; private Dept dept; public Employee() { } public Employee(Integer id, String lastName, char gender, String email) { this.id = id; this.lastName = lastName; this.gender = gender; this.email = email; } public Integer getId() { return id; } public void setId(Integer id) { this.id = id; } public String getLastName() { return lastName; } public void setLastName(String lastName) { this.lastName = lastName; } public char getGender() { return gender; } public void setGender(char gender) { this.gender = gender; } public String getEmail() { return email; } public void setEmail(String email) { this.email = email; } public Dept getDept() { return dept; } public void setDept(Dept dept) { this.dept = dept; } @Override public String toString() { return "Employee{" + "id=" + id + ", lastName='" + lastName + '\'' + ", gender=" + gender + ", email='" + email + '\'' + ", dept=" + dept + '}'; } }
Dept.java
package com.atguigu.mybatis.bean; import java.util.List; /** * @author xiaoyi * @create 2021-11-26-19:05 */ public class Dept { private Integer deptId; private String deptName; private List<Employee> employees; public Dept() { } public Dept(Integer deptId, String deptName, List<Employee> employees) { this.deptId = deptId; this.deptName = deptName; this.employees = employees; } public Integer getDeptId() { return deptId; } public void setDeptId(Integer deptId) { this.deptId = deptId; } public String getDeptName() { return deptName; } public void setDeptName(String deptName) { this.deptName = deptName; } public List<Employee> getEmployees() { return employees; } public void setEmployees(List<Employee> employees) { this.employees = employees; } @Override public String toString() { return "Dept{" + "deptId=" + deptId + ", deptName='" + deptName + '\'' + ", employees=" + employees + '}'; } }
Interface类:
EmployeeMapperPlus.java // EmployeeMapper的增强类:可以查询出员工所在的部门信息
package com.atguigu.mybatis.dao; import com.atguigu.mybatis.bean.Employee; /** * @author xiaoyi * @create 2021-11-25-21:04 */ public interface EmployeeMapperPlus { Employee getEmployeeByIdPlus(Integer id); Employee getEmployeeAndDeptByIdMethod1(Integer id); Employee getEmployeeAndDeptByIdMethod2(Integer id); Employee getEmployeeAndDeptByStep(Integer id); }
DeptMapper.java
package com.atguigu.mybatis.dao; import com.atguigu.mybatis.bean.Dept; /** * @author xiaoyi * @create 2021-11-27-0:05 */ public interface DeptMapper { Dept getDeptById(Integer id); Dept getDeptAndEmployeesById(Integer id); Dept getDeptAndEmployeesByStep(Integer id); }
Mapper类:
EmployeeMapperPlus.xml // 加强版的 EmployeeMapper 类:select 的属性使用了 resultMap
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.atguigu.mybatis.dao.EmployeeMapperPlus"> <!-- id:为 resultMap 设置唯一 id,方便引用 type:指定的 Java 类型 --> <resultMap id="myEmp1" type="com.atguigu.mybatis.bean.Employee"> <!-- <id />:指定主键列的封装规则 column: 数据库中指定的哪一列 property:指定对应的 JavaBean 属性 --> <id column="id" property="id"/> <!-- 定义普通列的封装规则 --> <result column="last_name" property="lastName"/> <!--其他不指定的列会自动封装--> </resultMap> <!-- 使用 resultMap 自定义封装规则--> <select id="getEmployeeByIdPlus" resultMap="myEmp1"> select * from tbl_employee where id = #{id} </select> <!-- 需求1:根据 id 查询出员工的信息及所在的部门信息 方式一:级联查询 --> <!-- 方法一: id:为resultMap标签指定唯一id属性,方便用来引用 type:指定查询结果返回的对象类型 --> <resultMap id="MyDifEmp1" type="com.atguigu.mybatis.bean.Employee"> <id column="id" property="id" /> <result column="last_name" property="lastName"/> <!-- 级联赋值 --> <result column="deptId" property="dept.deptId" /> <result column="deptName" property="dept.deptName"/> </resultMap> <select id="getEmployeeAndDeptByIdMethod1" resultMap="MyDifEmp1"> SELECT e.id id,last_name,gender,email,d_id deptId,dept_name deptName FROM tbl_employee e JOIN tbl_dept d ON e.d_id = d.id WHERE e.id = #{id} </select> <!-- 方式二:使用 association 标签指定关联关系 --> <resultMap id="MyDifEmp2" type="com.atguigu.mybatis.bean.Employee"> <id column="id" property="id" /> <result column="last_name" property="lastName"/> <!--association标签指定被关联对象的封装规则 property:被关联的对象属性 javaType:指定当前的属性类型 注意:这种方式javaType必须指定,表示supervisor的类型是Teacher,否则会报错 --> <association property="dept" javaType="com.atguigu.mybatis.bean.Dept"> <id column="deptId" property="deptId"/> <result column="deptName" property="deptName"/> </association> </resultMap> <select id="getEmployeeAndDeptByIdMethod2" resultMap="MyDifEmp2"> SELECT e.id id,last_name,gender,email,d_id deptId,dept_name deptName FROM tbl_employee e JOIN tbl_dept d ON e.d_id = d.id WHERE e.id = #{id} </select> <!-- 方法三:使用 association 标签分布查询 进阶:懒加载(延迟加载):编写好的sql语句,在需要调用对应的属性时才会加载对应的sql语句 在全局配置文件mybatis-config.xml中设置 <setting name="lazyLoadingEnabled" value="true"/> <setting name="aggressiveLazyLoading" value="false"/> --> <resultMap id="MyDifEmpByStep" type="com.atguigu.mybatis.bean.Employee"> <id column="id" property="id"/> <result column="last_name" property="lastName"/> <result column="gender" property="gender"/> <result column="email" property="email"/> <!-- association 定义关联对象的封装规则: select:表明当前属性是调用 select 指定的方法 根据 select 内的方法指定 property 内的被关联对象 流程:使用select指定的方法(传入column指定的这列参数的值)查询出指定的对象,并封装给property属性 --> <association property="dept" select="com.atguigu.mybatis.dao.DeptMapper.getDeptById" column="d_id"/> </resultMap> <select id="getEmployeeAndDeptByStep" resultMap="MyDifEmpByStep"> SELECT * FROM tbl_employee WHERE id = #{id} </select> </mapper>
DeptMapper.xml
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.atguigu.mybatis.dao.DeptMapper"> <select id="getDeptById" resultType="com.atguigu.mybatis.bean.Dept"> select id deptId,dept_name deptName from tbl_dept where id = #{id} </select> <!-- 需求2:根据部门id查询对应的部门信息以及该部门所有的员工信息 方法一:使用 collection 标签嵌套查询 --> <resultMap id="getDeptAndEmployeesById" type="com.atguigu.mybatis.bean.Dept"> <id column="id" property="deptId"/> <result column="dept_name" property="deptName"/> <!-- 使用 collection 标签嵌套查询 property:指定被集合的对象名(对应着JavaBean被封装的集合的对象名) ofType:指定集合元素里面的类型 --> <collection ofType="com.atguigu.mybatis.bean.Employee" property="employees"> <!-- 定义这个集合元素的封装规则 --> <id column="eid" property="id" /> <result column="last_name" property="lastName" /> <result column="gender" property="gender" /> <result column="email" property="email" /> </collection> </resultMap> <select id="getDeptAndEmployeesById" resultMap="getDeptAndEmployeesById"> SELECT d.id id,d.dept_name dept_name,e.id eid,e.last_name last_name,e.gender gender,e.email email FROM tbl_dept d LEFT JOIN tbl_employee e ON d.id = e.d_id WHERE d.id = #{id} </select> <!-- 方法二:使用collection标签分步查询 --> <resultMap id="getDeptAndEmployeesByStep" type="com.atguigu.mybatis.bean.Dept"> <id column="id" property="deptId"/> <result column="dept_name" property="deptName"/> <!-- 根据 column(下面查出来的某个列名)的值传入到 select 指定的方法中,并将查询结果返回给 property 属性中 --> <collection property="employees" select="com.atguigu.mybatis.dao.EmployeeMapperPlus.getEmployeeByIdPlus" column="id"/> </resultMap> <select id="getDeptAndEmployeesByStep" resultMap="getDeptAndEmployeesByStep"> select id,dept_name from tbl_dept where id = #{id} </select> </mapper>
数据库的准备工作:
tbl_dept 表
CREATE TABLE tbl_dept( id INT(11) PRIMARY KEY AUTO_INCREMENT, dept_name VARCHAR(255) );

tbl_employee 表
CREATE TABLE tbl_employee( id INT(11) PRIMARY KEY AUTO_INCREMENT, last_name VARCHAR(255), gender CHAR(1), email VARCHAR(255) ); ALTER TABLE tbl_employee ADD COLUMN d_id INT(11); ALTER TABLE tbl_employee ADD CONSTRAINT fk_emp_dept FOREIGN KEY(d_id) REFERENCES tbl_dept(id);

进行测试:
package com.atguigu.mybatis.test; import com.atguigu.mybatis.bean.Dept; import com.atguigu.mybatis.bean.Employee; import com.atguigu.mybatis.dao.DeptMapper; import com.atguigu.mybatis.dao.EmployeeMapper; import com.atguigu.mybatis.dao.EmployeeMapperPlus; import org.apache.ibatis.io.Resources; import org.apache.ibatis.session.SqlSession; import org.apache.ibatis.session.SqlSessionFactory; import org.apache.ibatis.session.SqlSessionFactoryBuilder; import org.junit.Test; import java.io.IOException; import java.io.InputStream; /** * @author xiaoyi * @create 2021-11-25-21:12 */ public class MyBatisPlusTest { public SqlSessionFactory getSqlSessionFactory() throws IOException { String resources = "mybatis-config.xml"; InputStream is = Resources.getResourceAsStream(resources); SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(is); return sqlSessionFactory; } /** * 一级缓存的使用 */ @Test public void testFirstLevelCache() { SqlSession openSession = null; try { SqlSessionFactory sqlSessionFactory = getSqlSessionFactory(); openSession = sqlSessionFactory.openSession(); EmployeeMapperPlus mapper = openSession.getMapper(EmployeeMapperPlus.class); Employee employee1 = mapper.getEmployeeAndDeptByIdMethod1(1); // 查询员工 id 为 1 的员工信息以及部门信息 System.out.println(employee1); } catch (IOException e) { e.printStackTrace(); } finally { openSession.close(); } } }
此时的运行结果为:
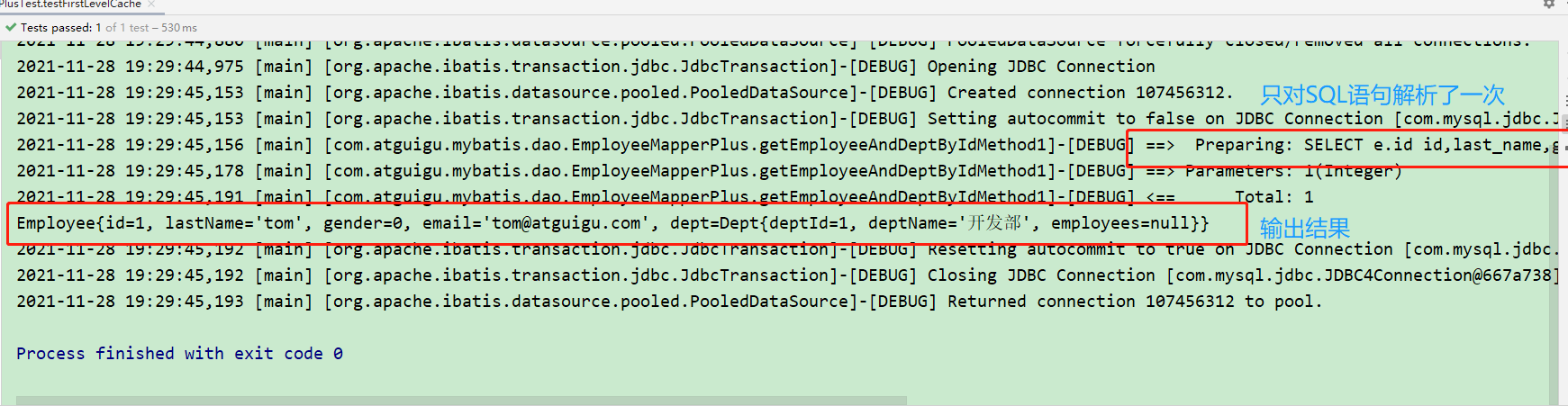
此时发现,一条调用查询语句会对 SQL 语句进行一次解析。
那么如果再查询一次员工 id 为 1 的员工信息以及部门信息的话会是怎样呢?如下:
输出结果如下:
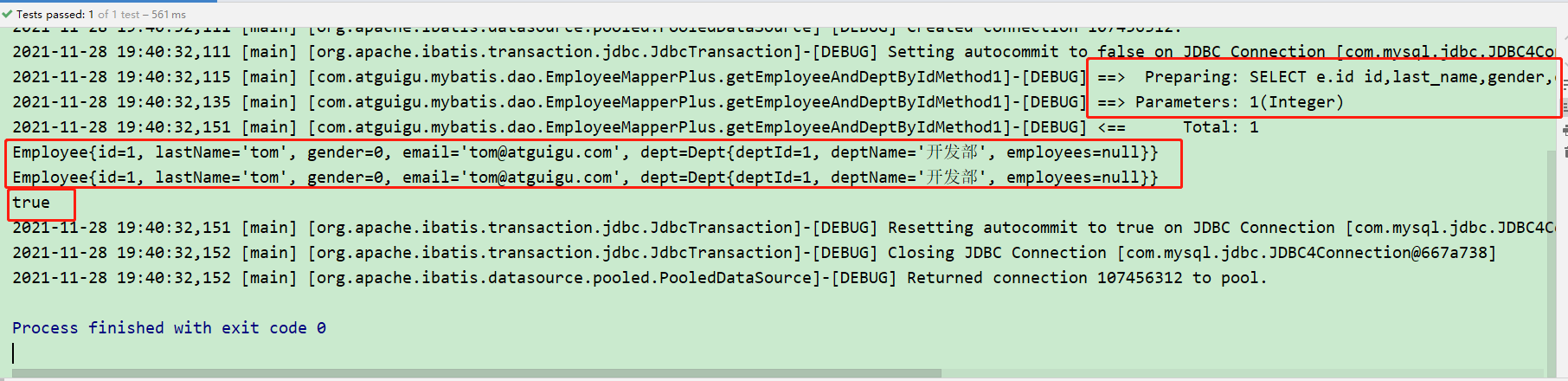
会惊奇的发现,尽管两条输出语句的员工信息一致,但对 SQL 语句的解析仍然只有一次,并且获取到的 employee1 和 employee2 对象的首地址值是一样的(获取到的两个对象是同一个对象)。
可以得出结论:employee2 是在缓存区获取到的,并不会对数据库再一次传入 SQL 语句进行查询。
一级缓存(本地缓存):它指的是Mybatis中sqlSession对象的缓存,当我们执行查询以后,查询的结果会同时存入到SqlSession为我们提供的一块区域中,该区域的结构是一个Map,当我们再次查询同样的数据,mybatis会先去sqlsession中查询是否有,的话直接拿出来用,当SqlSession对象消失时,mybatis的一级缓存也就消失了,同时一级缓存是SqlSession范围的缓存,当调用SqlSession的修改、添加、删除、commit(),close等方法时,就会清空一级缓存。
一级缓存失效情况(没有使用到当前一级缓存的情况,效果就是,还需要再向数据库发出查询):
1、sqlSession不同
2、sqlSession相同,查询条件不同.(当前一级缓存中还没有这个数据)
3、sqlSession相同,两次查询之间执行了增删改操作(这次增删改可能对当前数据有影响)
4、sqlSession相同,手动清除了一级缓存( 缓存清空:clearCache() )
那么有这么一个情况存在:如果是多个用户查询对数据库的进行同一条记录的查询,那么势必需要开启多个 sqlSession,对数据库进行多次查询交互。此时一级缓存将不再适用,此时我们需要引进二级缓存。
二级缓存(全局缓存):二级缓存是mapper级别的缓存,多个SqlSession去操作同一个Mapper的sql语句,多个SqlSession可以共用二级缓存,二级缓存是跨SqlSession的。EmployeeMapperPlus有一个二级缓存区域
(按namespace分),其它mapper也有自己的二级缓存区域(按namespace分)。每一个namespace的mapper都有一个二级缓存区域,两个mapper的namespace如果相同,这两个mapper执行sql查询到数据将存在相同的二级缓存区域中。
使用二级缓存同样需要做一些前提工作。如下:
- 开启全局二级缓存配置:<setting name="cacheEnabled" value="true"/>
- 去mapper.xml中配置使用二级缓存:
- 我们的POJO需要实现序列化接口
1.
<!-- 全局配置 --> <settings> <!-- 开启二级缓存 --> <setting name="cachedEnabled" value="true"/> </settings>
2.
<cache eviction="FIFO" flushInterval="60000" readOnly="false" size="1024"></cache> <!-- eviction:缓存的回收策略: LRU – 最近最少使用的:移除最长时间不被使用的对象。 FIFO – 先进先出:按对象进入缓存的顺序来移除它们。 SOFT – 软引用:移除基于垃圾回收器状态和软引用规则的对象。 WEAK – 弱引用:更积极地移除基于垃圾收集器状态和弱引用规则的对象。 默认的是 LRU。 flushInterval:缓存刷新间隔 缓存多长时间清空一次,默认不清空,设置一个毫秒值 readOnly:是否只读: true:只读;mybatis认为所有从缓存中获取数据的操作都是只读操作,不会修改数据。mybatis为了加快获取速度,直接就会将数据在缓存中的引用交给用户。不安全,速度快 false:非只读:mybatis觉得获取的数据可能会被修改。mybatis会利用序列化&反序列的技术克隆一份新的数据给你。安全,速度慢 size:缓存存放多少元素; type="":指定自定义缓存的全类名; 实现Cache接口即可。 -->
3.
public class Employee implements Serializable{ }
public class Dept implements Serializable { }
此时让我们来测试一下二级缓存是否有效果。
运行代码:
/** * 二级缓存的使用 */ @Test public void testSecondLevelCache() { SqlSession openSession1 = null; SqlSession openSession2 = null; try { SqlSessionFactory sqlSessionFactory = getSqlSessionFactory(); openSession1 = sqlSessionFactory.openSession(); // 开启第一次sqlSession EmployeeMapperPlus mapper1 = openSession1.getMapper(EmployeeMapperPlus.class); Employee employee1 = mapper1.getEmployeeAndDeptByIdMethod1(2); System.out.println(employee1); openSession2 = sqlSessionFactory.openSession(); // 开启第二次sqlSession EmployeeMapperPlus mapper2 = openSession2.getMapper(EmployeeMapperPlus.class); Employee employee2 = mapper2.getEmployeeAndDeptByIdMethod1(2); System.out.println(employee2); } catch (IOException e) { e.printStackTrace(); } finally { openSession1.close(); openSession2.close(); } }
运行结果:
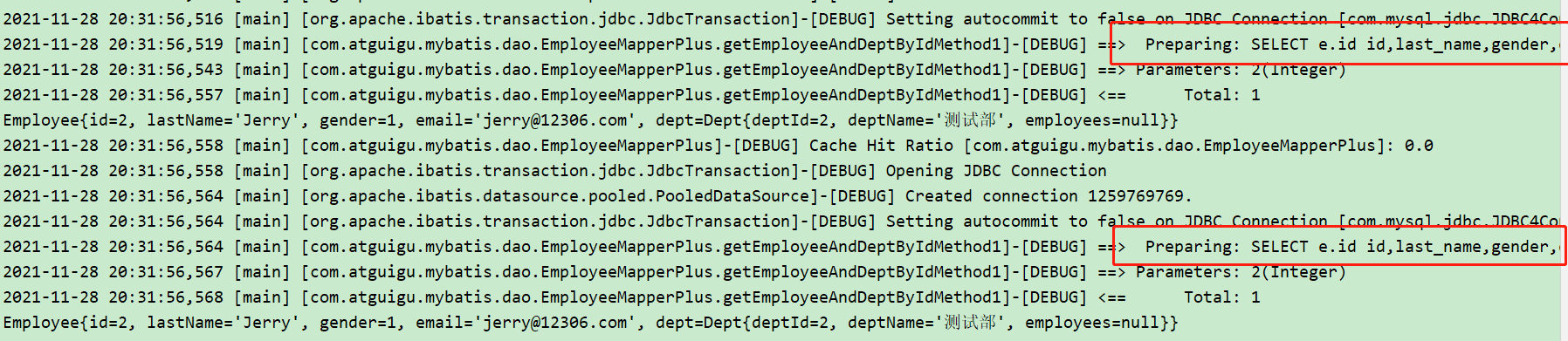
此时发现,在条件相同的情况下,仍然对 SQL 语句解析了两次。
我们找到原因:这里是两次 sqlSession 会话对数据库进行了访问,SQL语句也解析了两次,因此这里仍然是一级缓存,二级缓存未被访问到。
根据上文提到,要使一级缓存失效,需要将 openSession1.close() 提前到 mapper2.getEmployeeAndDeptByIdMethod1(2) 之前,此时再看一下运行结果
运行代码:
/** * 二级缓存的使用 */ @Test public void testSecondLevelCache() { SqlSession openSession1 = null; SqlSession openSession2 = null; try { SqlSessionFactory sqlSessionFactory = getSqlSessionFactory(); openSession1 = sqlSessionFactory.openSession(); // 开启第一次sqlSession EmployeeMapperPlus mapper1 = openSession1.getMapper(EmployeeMapperPlus.class); Employee employee1 = mapper1.getEmployeeAndDeptByIdMethod1(2); System.out.println(employee1); openSession1.close(); // 将 openSession1.close() 提前到 mapper2.getEmployeeAndDeptByIdMethod1(2) 之前 openSession2 = sqlSessionFactory.openSession(); // 开启第二次sqlSession EmployeeMapperPlus mapper2 = openSession2.getMapper(EmployeeMapperPlus.class); Employee employee2 = mapper2.getEmployeeAndDeptByIdMethod1(2); System.out.println(employee2); } catch (IOException e) { e.printStackTrace(); } finally { openSession2.close(); } }
运行结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号