Python re正则模块
1.正则概述
就其本质而言,正则表达式(或 RE)是一种小型的、高度专业化的编程语言,要讲他的具体用法要讲一本书!它内嵌在Python中,并通过 re 模块实现。你可以为想要匹配的相应字符串集指定规则;该字符串集可能包含英文语句、e-mail地址、TeX命令或任何你想搞定的东西。然后你可以问诸如“这个字符串匹配该模式吗?”或“在这个字符串中是否有部分匹配该模式呢?”。你也可以使用 RE 以各种方式来修改或分割字符串。今天就来讲讲re模块的最常用的用法
2.常用元字符
字符组:在同一个位置可能出现的各种字符组成了一个字符组,在正则表达式中用[]表示字符分为很多类,比如数字、字母、标点等等。假如你现在要求一个位置"只能出现一个数字",那么这个位置上的字符只能是0、1、2...9这10个数之一。
| 正则 | 待匹配元字符 | 匹配结果 | 说明 |
|---|---|---|---|
| [0123456789] | 8 | True | 在一个字符组里枚举合法的所有字符,字符组里的任意一个字符和"待匹配字符"相同都视为可以匹配 |
| [0123456789] | a | False | 由于字符组中没有"a"字符,所以不能匹配 |
| [0-9] | 7 | True | 也可以用-表示范围,[0-9]就和[0123456789]是一个意思 |
| [a-z] | s | True | 同样的如果要匹配所有的小写字母,直接用[a-z]就可以表示 |
| [A-Z] | B | True | [A-Z]就表示所有的大写字母 |
| [0-9a-fA-F] | e | True | 可以匹配数字,大小写形式的a~f,用来验证十六进制字符 |
| 元字符 | 匹配内容 |
|---|---|
| . | 匹配换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线 |
| \s | 匹配任意的空白字符 |
| \d | 匹配数字 |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| \b | 匹配一个单词的结尾 |
| ^ | 匹配字符换的开头 |
| $ | 匹配字符串的结尾 |
| \W | 匹配非字母或数字或下划线 |
| \D | 匹配非数字 |
| \S | 匹配非空白符 |
| `a | b` |
| [^....] | 匹配除了字符组中字符的所有字符 |
| () | 匹配括号内的表达式也表示一个组`(www.(baidu |
3.量词
-
{n}
表示匹配n次
\d{2}只能匹配两位整数 -
{n,}
表示匹配至少n次
[1-9]{3,}至少匹配三位的数字 -
{n,m}
表示至少匹配nci至多m次
[1-9]{1,3}\.[1-9]{1,3}\.[1-9]{1,3}\.[1-9]{1,3} -
*
重复零次或更多次 -
+
重复一次或多次 -
?
重复零次或一次
3.1 练习
`\d+\.\d|\d+` 匹配整数或者是小数
`\d+\.?\d*` 匹配整数或者是小数 (?表示匹配0个点或者是匹配一个点)
\d+(\.\d+)? 正规的
-
匹配手机号码 11位数 以1开头 第二个数是3-9
^[1][3-9]+\d{9}$ -
判断用户输入的内容是否合法,如果用户输入的对就能查到结果,如果输入的不对就不能查到结果
^1[3-9]\d{9}$ -
从一个大文件中找到所有符合规则的内容
1[3-9]\d{9} -
匹配身份证号
18/15位的身份证号- 15
- 1-9 15
- [1-9]\d
- 1-9 15
- 18
- 1-9 16 0-9/x
- [1-9]\d{16}[\dx]
- [1-9]\d{16}[0-9x]
- [1-9]\d{16}[\dx]
- 1-9 16 0-9/x
- 15
4.正则的贪婪匹配和惰性匹配
-
在量词范围允许的情况下,尽量多的匹配内容
.*x表示匹配任意字符 任意多次数 遇到最后一个x才停下
\d{3,}6 -
非贪婪
# .*?x表示匹配任意字符 任意多次数 但是一旦遇到x就停下来\d{3,}?6
5.转义符
原本有特殊意义的字符,到了表达它本身的意义的时候,需要转义
有一些特殊意义的内容,放在字符组中,会取消它的特殊意义
[().*+?]
[a\-c] - 在字符组中表示范围,如果不希望它表示范围,需要转义,或者放在字符组的最前面\最后面
取消一个元字符的特殊意义的两种方法
- 在这个元字符前面加上\
- 对一部分元字符生效,把这个元字符放在字符组里
匹配1+2 或者是 1-2
1[+-]2
6.re模块方法
6.1 re中的findall 和 search
6.1.1 findall返回所有满足匹配条件的结果
结果返回的是一个列表
import re
ret = re.findall('\d','123123sdasd')
print(ret)
>>>
['1', '2', '3', '1', '2', '3']
import re
ret = re.findall('[a-z]','123123sdasd')
ret2 = re.findall('[sd]','123123sdasd')
print(ret)
print(ret2)
>>>
['s', 'd', 'a', 's', 'd']
['s', 'd', 's', 'd']
6.1.2 search
- 函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以
- 通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。
ret = re.search('[a-z]','12312dsfsdf3243')
print(ret.group())
>>>
d #只返回匹配的第一个结果,用group的方法
6.1.3 findall serch与()分组的关系
- findall
还是安装完整的正则进行匹配,只是显示括号内匹配到的内容
import re
ret = re.findall('2(\d)\d','123123sdasd')
print(ret)
>>>
['3']
- search
- 还是安装完整的正则进行匹配,显示匹配到第一个内容,但是我们可以通过给group方法进行传参数,来获取具体文组中的内容
- 得到的是一个变量
- 变量.group()的结果 完全和变量.group(0)的结果一致
- 变量.group(n)的形式指定获取第n个分组中匹配到的内容
ret = re.search('2(\d)\d','12312dsfsdf3243')
print(ret.group())
>>>
231
ret = re.search('2(\d)(\d)','12312dsfsdf3243')
print(ret.group(2))
>>>
1
ret = re.search('^<h1>(.*)</h1>$','<h1>asdsadasd23232</h1>')
print(ret.group(1))
>>>
asdsadasd23232
范例:
加上括号是为了对真正需要的内容进行提取
ret = re.search('^<h1>(.*)</h1>$','<h1>asdsadasd23232</h1>')
print(ret.group(1))
ret = re.findall('^<h1>(.*)</h1>$','<h1>asdsadasd23232</h1>')
print(ret)
>>>
asdsadasd23232
['asdsadasd23232']
- 匹配exp 中的 5+6 并让相加得出结果
exp = '2-3*(5+6)'
ret = re.search('[(](\d)[+](\d)\)$',exp)
print(ret.group(1))
print(ret.group(2))
print(int(ret.group(1))+int(ret.group(2)))
ret = re.search('(\d)[+](\d)',exp)
print(ret.group(1))
print(ret.group(2))
print(int(ret.group(1))+int(ret.group(2)))
6.1.4 匹配电影名
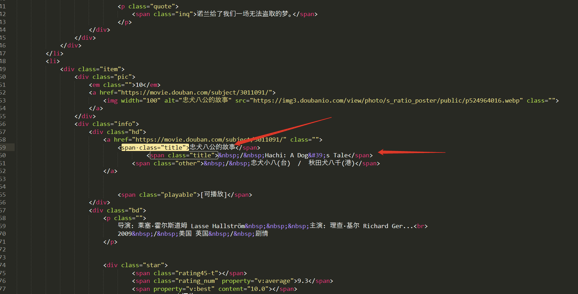
import re
with open('douban.html',mode='r',encoding='utf-8')as f:
info = f.read()
ret = re.findall('<span class="title">(.*?)</span>\s*<span class="title">.*</span>',info)
#<span class="title">机器人总动员</span>
#<span class="title"> / WALL·E</span>
print(ret)
>>>
['肖申克的救赎', '这个杀手不太冷', '阿甘正传', '美丽人生', '泰坦尼克号', '千与千寻', '辛德勒的名单', '盗梦空间', '忠犬八公的故事', '机器人总动员', '三傻大闹宝莱坞', '海上钢琴师', '放牛班的春天', '楚门的世界', '大话西游之大圣娶亲', '星际穿越', '龙猫', '教父', '熔炉', '无间道', '疯狂动物城', '当幸福来敲门', '怦然心动', '触不可及']
6.1.5 取链家相关信息

使用findall
范例:
ret = re.findall('<div class="title">.*?data-sl="">(.*?)</a>.*?<span class="divide">/</span>(.*?)<span class.*?</span>(.*?)<span class="divide">',info,flags=re.S)
print(ret)
>>>
[('金台路交通部部委楼南北大三居带客厅 单位自持物业', '3室1厅', '91.22平米'), ('西山枫林 高楼层南向两居 户型方正 采光好', '2室1厅', '94.14平米')]
正则解释
('
- 匹配全文.*?data-sl="">(遇到data-sl="">就结束)
- 匹配全文(.*?)遇到就结束这时匹配的是'金台路交通部部委楼南北大三居带客厅 单位自持物业'
- 匹配全文.*?/遇到/就结束
以此类推
6.1.6 匹配网站标签
import re
exp = '<h1>asddasdsd</h1></asdsd>'
ret = re.search('<\w+>.*?</\w+>',exp)
print(ret.group())
>>>
<h1>asddasdsd</h1>
6.2 finditer
finditer方法finditer函数跟findall函数类似,但返回的是一个迭代器, 而不是一个像findall函数那样的存有所有结果的list。finditer的每一个对象可以使用group(可以获取整个匹配串)和groups方法;在有分组的情况下,findall只能获得分组,不能获得整个匹配串。
6.2.1 取链家的相关信息
范例:
import re
ret = re.finditer('<div class="title">.*?data-sl="">(?P<name>.*?)</a>.*?<span class="divide">/</span>(?P<room>.*?)<span class.*?</span>(?P<area>.*?)<span class="divide">',info,flags=re.S)
for i in ret: #遍历取出
print(i.group('name'),i.group('room'),i.group('area'))
>>>
金台路交通部部委楼南北大三居带客厅 单位自持物业 3室1厅 91.22平米
西山枫林 高楼层南向两居 户型方正 采光好 2室1厅 94.14平米
7.re模块中的用法
7.1 split
根据匹配到的内容进行切割
- 匹配到了222进行以222进行切割(形成列表)
import re
ret = re.split('\d+','tom222deam')
print(ret)
>>>
['tom', 'deam']
- 可以使用分组进行保留(形成列表)
import re
ret = re.split('\d(\d)\d','tom222deam')
print(ret)
>>>
['tom', '2', 'deam']
7.2 sub
替换的方法
- 我要把字符串中的数字替换成“SED”
import re
ret = re.sub('\d+','SED','tom12323deam123123')
print(ret)
>>>
tomSEDSEDSEDSEDSEDdeamSEDSEDSEDSEDSEDSED
ret = re.sub('\d+','SED','tom12323deam123123')
print(ret)
>>>
tomSEDdeamSED
- 也可以传入参数
ret=re.sub('\d','SED','tom12323deam123123',1) #后面加上一表示只替换一个从左往右的顺序
print(ret)
>>>
tomSED2323deam123123
7.3 match
- 表示以你的匹配条件开头进行匹配
ret=re.match('\d+','132434aasd123213fdf')
print(ret.group()) #相当于^
>>>
132434
7.4 compile
节省了代码的时间
- 使用compile进行定义的正则可以多次调用
import re
ret = re.compile('\d+')
ret = ret.findall('123sdsdsd323')
print(ret)
>>>
['123', '323']
7.5 finditer
- 节省空间
- 形成了迭代器 返回的是结果变量 使用i.group()进行取值
ret = re.compile('\d+')
ret = ret.finditer('123sdsdsd323')
for i in ret:
print(i)
>>>
<re.Match object; span=(0, 3), match='123'>
<re.Match object; span=(9, 12), match='323'>
ret = re.compile('\d+')
ret = ret.finditer('123sdsdsd323')
for i in ret:
print(i.group()
>>>
123
323
7.6 分组命名
(?P<名字>正则表达式)
范例:
import re
ret = re.finditer('<div class="title">.*?data-sl="">(?P<name>.*?)</a>.*?<span class="divide">/</span>(?P<room>.*?)<span class.*?</span>(?P<area>.*?)<span class="divide">',info,flags=re.S)
for i in ret: #遍历取出
print(i.group('name'),i.group('room'),i.group('area'))
>>>
金台路交通部部委楼南北大三居带客厅 单位自持物业 3室1厅 91.22平米
西山枫林 高楼层南向两居 户型方正 采光好 2室1厅 94.14平米
7.6.1 分组命名的引用
- 匹配标签 约束
==
引用了分组名 约束了必须是
exp = '<h1>asddasdsd</h1></asdsd>'
ret = re.search('<(?P<tag>\w+)>.*?</(?P=tag)>',exp)
print(ret.group())
>>>
<h1>asddasdsd</h1>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号