HTTP协议简单认识
1 Internet和HTTP协议
1.1 Internet 因特网
因特网是“Internet”的中文译名,它起源于美国的五角大楼,它的前身是美国国防部高级研究计划局
(ARPA)主持研制的ARPAnet。20世纪50年代末,正处于冷战时期。当时美国军方为了自己的计算机
网络在受到袭击时,即使部分网络被摧毁,其余部分仍能保持通信联系,便由美国国防部的高级研究计划
局(ARPA)建设了一个军用网,叫做“阿帕网”(ARPAnet)。阿帕网于1969年正式启用,当时仅连接
了4台计算机,供科学家们进行计算机联网实验用,这就是因特网的前身。
到70年代,ARPAnet已经有了好几十个计算机网络,但是每个网络只能在网络内部的计算机之间互联通
信,不同计算机网络之间仍然不能互通。为此, ARPA又设立了新的研究项目,支持学术界和工业界进行有关的研究,研究的主要内容就是想用一种新的方法将不同的计算机局域网互联,形成“互联网”。研
究人员称之为“internetwork”,简称“Internet”
在研究实现互联的过程中,计算机软件起了主要的作用。1974年,出现了连接分组网络的协议,其中就
包括了TCP/IP协议。TCP/IP有一个非常重要的特点,就是开放性,即TCP/IP的规范和Internet的技术都
是公开的。目的就是使任何厂家生产的计算机都能相互通信,使Internet成为一个开放的系统,这正是
后来Internet得到飞速发展的重要原因。ARPA在1982年接受了TCP/IP,选定Internet为主要的计算机通
信系统,并把其它的军用计算机网络都转换到TCP/IP。1983年,ARPAnet分成两部分:一部分军用,称
为MILNET;另一部分仍称ARPAnet,供民用。
1986年,美国国家科学基金组织(NSF)将分布在美国各地的5个为科研教育服务的超级计算机中心互
联,并支持地区网络,形成SNSFnet。1988 年,SNSFnet替代ARPAnet成为Internet的主干网。
NSFnet主干网利用了在ARPAnet中已证明是非常成功的TCP/IP技术,准许各大学、政府或私人科研机
构的网络加入。1989年,ARPAnet解散,Internet从军用转向民用。
Internet的发展引起了商家的极大兴趣。1992年,美国IBM、MCI、MERIT三家公司联合组建了一个高
级网络服务公司(SNS),建立了一个新的网络,叫做SNSnet,成为Internet的另一个主干网。它与
SNSFnet不同,NSFnet是由国家出资建立的,而SNSnet则是SNS 公司所有,从而使Internet开始走向
商业化。
1995年4月30日,SNSFnet正式宣布停止运作。而此时Internet的骨干网已经覆盖了全球91个国家,主
机已超过400万台。在最近,因特网更以惊人的速度向前发展,很快就达到了的规模
在90年代,超文本标识语言(HTML),即一个可以获得因特网的图像信息的超文本因特网协议被采
用,使每一个人可以产生自己的图像页面(网址),然后成为一个巨大的虚拟超文本网络的组成部分。
这个增强型的因特网又被非正式地称为万维网,与此同时产生了数量庞大的新用户群。于是,许多人用
“因特网” 一词指这个网络的物理结构,包括连接所有事物的客户机、服务器和网络;而用“万维网”一词
指利用这个网络可以访问的所有网站和信息。
1.2 跨网络的主机间通讯
Socket套接字
套接字Socket是进程间通信IPC的一种实现,允许位于不同主机(或同一主机)上不同进程之间进行通
信和数据交换,SocketAPI出现于1983年,4.2 BSD实现
在建立通信连接的每一端,进程间的传输要有两个标志:IP地址和端口号,合称为套接字地址 socket
address
客户机套接字地址定义了一个唯一的客户进程
服务器套接字地址定义了一个唯一的服务器进程
Socket API
封装了内核中所提供的socket通信相关的系统调用
Socket Domain:根据其所使用的地址
AF_INET:Address Family,IPv4
AF_INET6:IPv6
AF_UNIX:同一主机上不同进程之间通信时使用
Socket Type:根据使用的传输层协议
SOCK_STREAM:流,tcp套接字,可靠地传递、面向连接
SOCK_DGRAM:数据报,udp套接字,不可靠地传递、无连接
SOCK_RAW: 裸套接字,无须tcp或udp,APP直接通过IP包通信
客户/服务器程序的套接字函数
套接字相关的系统调用:
- socket() 创建一个套接字
- bind() 绑定IP和端口
- listen() 监听
- accept() 接收请求
- connect() 请求连接建立
- write() 发送
- read() 接收
- close() 关闭连接
范例:Socket通信Python 3.6实现
需要安装python3
[root@centos8 ~]#dnf install python3
#服务器端tcpserver.py
#!/usr/bin/python3
import socket
HOST='127.0.0.1'
PORT=9527
BUFFER=4096
sock=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
sock.bind((HOST,PORT))
sock.listen(3)
print('tcpServer listen at: %s:%s\n\r' %(HOST,PORT))
while True:
client_sock,client_addr=sock.accept()
print('%s:%s connect' %client_addr)
while True:
recv=client_sock.recv(BUFFER)
if not recv:
client_sock.close()
break
print('[Client %s:%s said]:%s' %
(client_addr[0],client_addr[1],recv.decode()))
client_sock.send(b'tcpServer has received your message')
sock.close()
#服务器端tcpclient.py
#!/usr/bin/python3
import socket
HOST='127.0.0.1'
PORT=9527
BUFFER=4096
sock=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
sock.connect((HOST,PORT))
sock.send(b'hello, tcpServer!,I am tcp client')
recv=sock.recv(BUFFER)
print('[tcpServer said]: %s' % recv.decode())
sock.close()
1.3 HTTP 超文本传输协议
1.3.1 浏览器访问网站的过程
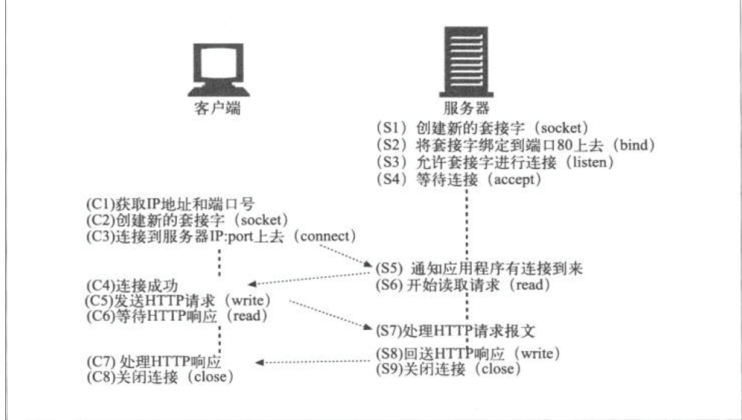
1.3.2 HTTP协议通信过程
HTTP(HyperText Transfer Protocol,超文本传输协议)是一种用于分布式、协作式和超媒体信息系
统的应用层协议[1]。HTTP是万维网的数据通信的基础设计HTTP最初的目的是为了提供一种远距离共享
知识的方式,借助多文档进行关联实现超文本,连成相互参阅的WWW(world wide web,万维网)
HTTP的发展是由蒂姆·伯纳斯-李(Tim Berners-Lee)于1989年在欧洲核子研究组织(CERN)所发
起。HTTP的标准制定由万维网协会(World Wide Web Consortium,W3C)和互联网工程任务组
(Internet Engineering Task Force,IETF)进行协调,最终发布了一系列的RFC,其中最著名的是
1999年6月公布的 RFC 2616,定义了HTTP协议中现今广泛使用的一个版本——HTTP 1.1版
HTTP服务通信过程
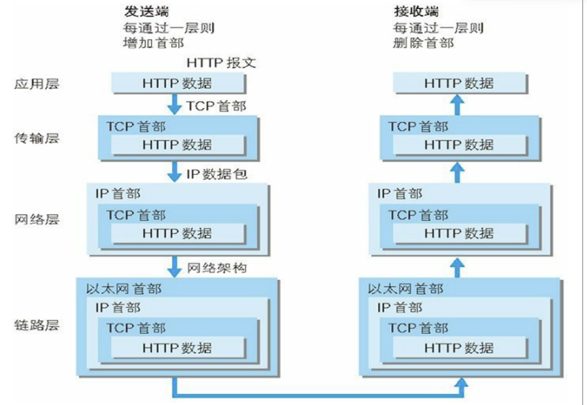
HTTP协议分层
1.3.3 HTTP相关技术和术语
1.3.3.1 WEB开发语言
http: Hyper Text Transfer Protocol 应用层协议,默认端口: 80/tcp
WEB前端开发语言:
- html
- css
- javascript
html
Hyper Text Markup Language 超文本标记语言,编程语言,主要负责实现页面的结构
范例:html 语言
<html>
<head>
<meta http-equiv=Content-Type content="text/html;charset=utf-8">
<title>HTML语言</title>
</head>
<body>
<img src="http://www.magedu.com/wp-content/uploads/2017/09/logo.png" >
<h1 style="color:red">欢迎</h1>
<p><a href=http://www.magedu.com>LiuXinY</a>欢迎你</p>
</body>
</html>
CSS
Cascading Style Sheet 层叠样式表, 定义了如何显示(装扮) HTML 元素,比如:字体大小和颜色属
性等。样式通常保存在外部的 .css 文件中。通过仅仅编辑一个简单的 CSS 文档,可以同时改变站点中
所有页面的布局和外观。
范例 :CSS
#test.html
<html>
<head>
<meta http-equiv=Content-Type content="text/html;charset=utf-8">
<link rel="stylesheet" type="text/css" href="mystyle.css" />
</head>
<body>
<h1>这是 heading 1</h1>
<p>这是一段普通的段落。请注意,该段落的文本是红色的。在 body 选择器中定义了本页面中的默认文本颜
色。</p>
<p class="ex">该段落定义了 class="ex"。该段落中的文本是蓝色的。</p>
</body>
</html>
#mystyle.css
body {color:red}
h1 {color:#00ff00}
p.ex {color:rgb(0,0,255)}
Js
javascript,实现网页的动画效果,但实属于静态资源
范例:javascript
我的第一段 JavaScript
1.3.3.2 URI和URL
URI: Uniform Resource Identififier 统一资源标识,分为URL 和 URN
URN:Uniform Resource Naming,统一资源命名
示例: P2P下载使用的磁力链接是URN的一种实现
magnet:?xt=urn:btih:660557A6890EF888666
URL:Uniform Resorce Locator,统一资源定位符,用于描述某服务器某特定资源位置
两者区别:URN如同一个人的名称,而URL代表一个人的住址。换言之,URN定义某事物的身份,而
URL提供查找该事物的方法。URN仅用于命名,而不指定地址
URL组成

scheme:方案,访问服务器以获取资源时要使用哪种协议
user:用户,某些方案访问资源时需要的用户名
password:密码,用户对应的密码,中间用:分隔
Host:主机,资源宿主服务器的主机名或IP地址
port:端口,资源宿主服务器正在监听的端口号,很多方案有默认端口号
path:路径,服务器资源的本地名,由一个/将其与前面的URL组件分隔
params:参数,指定输入的参数,参数为名/值对,多个参数,用;分隔
query:查询,传递参数给程序,如数据库,用?分隔,多个查询用&分隔
frag:片段,一小片或一部分资源的名字,此组件在客户端使用,用#分隔
URL示例

1.3.3.3 网站访问量
- IP(独立IP):即Internet Protocol,指独立IP数。一天内来自相同客户机IP 地址只计算一次,记录远
程客户机IP地址的计算机访问网站的次数,是衡量网站流量的重要指标 - PV(访问量): 即Page View, 页面浏览量或点击量,用户每次刷新即被计算一次,PV反映的是浏览
某网站的页面数,PV与来访者的数量成正比,PV并不是页面的来访者数量,而是网站被访问的页
面数量 - UV(独立访客):即Unique Visitor,访问网站的一台电脑为一个访客。一天内相同的客户端只被计算
一次。可以理解成访问某网站的电脑的数量。网站判断来访电脑的身份是通过cookies实现的。如
果更换了IP后但不清除cookies,再访问相同网站,该网站的统计中UV数是不变的
网站统计:http://www.alexa.cn/rank/
范例:网站访问统计
甲乙丙三人在同一台通过 ADSL 上网的电脑上(中间没有断网),分别访问 www.magedu.com 网站,并且
每人共用一个浏览器,各个浏览了2个页面,那么网站的流量统计是:
IP: 1 PV:6 UV:1
若三人都是ADSL重新拨号后,各浏览了2个页面,则
IP: 3 PV:6 UV:1
网站访问量
QPS:request per second,每秒请求数
PV,QPS和并发连接数换算公式
- QPS= PV * 页面衍生连接次数/ 统计时间(86400)
- 并发连接数 =QPS * http平均响应时间
峰值时间:每天80%的访问集中在20%的时间里,这20%时间为峰值时间
峰值时间每秒请求数(QPS)=( 总PV数 页面衍生连接次数)80% ) / ( 每天秒数 * 20% )
1.3.4 HTTP工作机制
一次http事务包括:
- http请求:http request
- http响应:http response
Web资源:web resource, 一个网页由多个资源(文件)构成,打开一个页面,通常会有多个资源展
示出来,但是每个资源都要单独请求。因此,一个“Web 页面”通常并不是单个资源,而是一组资源的集
合
资源类型:
- 静态文件:无需服务端做出额外处理
文件后缀:.html, .txt, .jpg, .js, .css, .mp3, .avi - 动态文件:服务端执行程序,返回执行的结果
文件后缀:.php, .jsp ,.asp
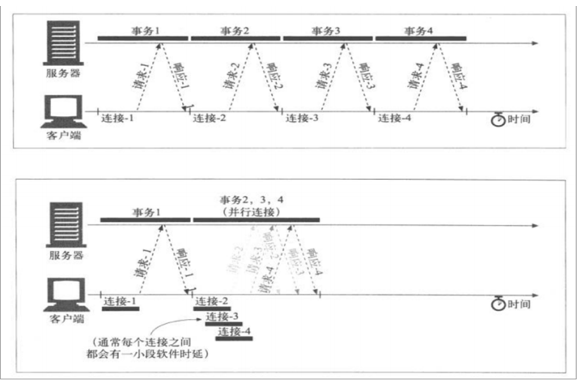
HTTP连接请求
串行和并行连接
串行,持久连接和管道
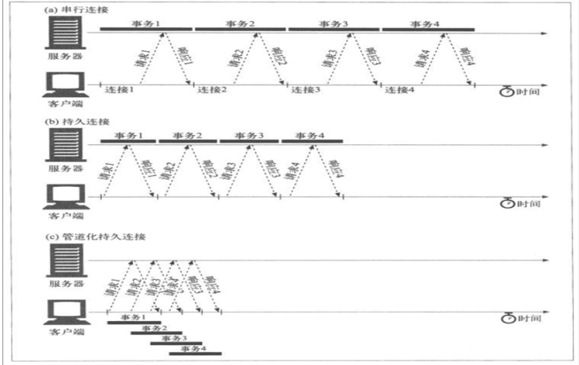
提高HTTP连接性能
- 并行连接:通过多条TCP连接发起并发的HTTP请求
- 持久连接:keep-alive,重用TCP连接,以消除连接和关闭的时延,以事务个数和时间来决定是否关
闭连接 - 管道化连接:通过共享TCP连接,发起并发的HTTP请求
- 复用的连接:交替传送请求和响应报文(实验阶段)
1.3.5 HTTP 协议版本
http/0.9:
1991,原型版本,功能简陋,只有一个命令GET。GET /index.html ,服务器只能回应HTML格式字符
串,不能回应别的格式
http/1.0
1996年5月,支持cache, MIME, method
每个TCP连接只能发送一个请求,发送数据完毕,连接就关闭,如果还要请求其他资源,就必须再新建
一个连接
引入了POST命令和HEAD命令
头信息是 ASCII 码,后面数据可为任何格式。服务器回应时会告诉客户端,数据是什么格式,即
Content-Type字段的作用。这些数据类型总称为MIME 多用途互联网邮件扩展,每个值包括一级类型和
二级类型,预定义的类型,也可自定义类型, 常见Content-Type值:text/xml image/jpeg audio/mp3
http/1.1
1997年1月,引入了持久连接(persistent connection),即TCP连接默认不关闭,可以被多个请求复
用,不用声明Connection: keep-alive。对于同一个域名,大多数浏览器允许同时建立6个持久连接引入
了管道机制,即在同一个TCP连接里,客户端可以同时发送多个请求,进一步改进了HTTP协议的效率
新增方法:PUT、PATCH、OPTIONS、DELETE
同一个TCP连接里,所有的数据通信是按次序进行的。服务器只能顺序处理回应,前面的回应慢,会有
许多请求排队,造成"队头堵塞"(Head-of-line blocking)
为避免上述问题,两种方法:一是减少请求数,二是同时多开持久连接。
网页优化技巧,如合并脚本和样式表、将图片嵌入CSS代码、域名分片(domain sharding)等
HTTP 协议不带有状态,每次请求都必须附上所有信息。请求的很多字段都是重复的,浪费带宽,影响
速度
HTTP1.0和HTTP1.1的区别
- 缓存处理,在HTTP1.0中主要使用header里的If-Modifified-Since,Expires来做为缓存判断的标准,
HTTP1.1则引入了更多的缓存控制策略例如Entity tag,If-Unmodifified-Since, If-Match, If-None
Match等更多可供选择的缓存头来控制缓存策略 - 带宽优化及网络连接的使用,HTTP1.0中,存在一些浪费带宽的现象,例如:客户端只是需要某个
对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1则在请求头
引入了range头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),方便了
开发者自由的选择以便于充分利用带宽和连接 - 错误通知的管理,在HTTP1.1中新增24个状态响应码,如409(Conflflict)表示请求的资源与资源
当前状态冲突;410(Gone)表示服务器上的某个资源被永久性的删除 - Host 头处理,在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL
并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多
个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。HTTP1.1的请求消息和响
应消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad
Request) - 长连接,HTTP 1.1支持长连接(PersistentConnection)和请求的流水线(Pipelining)处理,在
一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟,在
HTTP1.1中默认开启Connection: keep-alive,弥补了HTTP1.0每次请求都要创建连接的缺点
HTTP1.0和1.1的问题
-
HTTP1.x在传输数据时,每次都需要重新建立连接,无疑增加了大量的延迟时间,特别是在移动端
更为突出 -
HTTP1.x在传输数据时,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份,无
法保证数据的安全性 -
HTTP1.x在使用时,header里携带的内容过大,增加了传输的成本,并且每次请求header基本不
怎么变化,尤其在移动端增加用户流量 -
虽然HTTP1.x支持了keep-alive,来弥补多次创建连接产生的延迟,但是keep-alive使用多了同样
会给服务端带来大量的性能压力,并且对于单个文件被不断请求的服务(例如图片存放网站),
keep-alive可能会极大的影响性能,因为它在文件被请求之后还保持了不必要的连接很长时间
HTTPS协议:
为解决安全问题,网景在1994年创建了HTTPS,并应用在网景导航者浏览器中。 最初,HTTPS是与SSL
一起使用的;在SSL逐渐演变到TLS时(其实两个是一个东西,只是名字不同而已),最新的HTTPS也由
在2000年五月公布的RFC 2818正式确定下来。HTTPS就是安全版的HTTP,目前大型网站基本实现全站
HTTPS
HTTPS特点
- HTTPS协议需要到CA申请证书,一般免费证书很少,需要交费
- HTTP协议运行在TCP之上,所有传输的内容都是明文,HTTPS运行在SSL/TLS之上,SSL/TLS运行
在TCP之上,所有传输的内容都经过加密的 - HTTP和HTTPS使用的是不同的连接方式,端口不同,前者是80,后者是443
- HTTPS可以有效的防止运营商劫持,解决了防劫持的一个大问题
- HTTPS 实现过程降低用户访问速度,但经过合理优化和部署,HTTPS 对速度的影响还是可以接受
的
SPDY协议
SPDY:2009年谷歌研发,综合HTTPS和HTTP两者有点于一体的传输协议,主要特点:
- 降低延迟,针对HTTP高延迟的问题,SPDY优雅的采取了多路复用(multiplexing)。多路复用通
过多个请求stream共享一个tcp连接的方式,解决了HOL blocking的问题,降低了延迟同时提高了
带宽的利用率 - 请求优先级(request prioritization)。多路复用带来一个新的问题是,在连接共享的基础之上有
可能会导致关键请求被阻塞。SPDY允许给每个request设置优先级,重要的请求就会优先得到响
应。比如浏览器加载首页,首页的html内容应该优先展示,之后才是各种静态资源文件,脚本文
件等加载,可以保证用户能第一时间看到网页内容 - header压缩。HTTP1.x的header很多时候都是重复多余的。选择合适的压缩算法可以减小包的大
小和数量 - 基于HTTPS的加密协议传输,大大提高了传输数据的可靠性
- 服务端推送(server push),采用了SPDY的网页,例如网页有一个sytle.css的请求,在客户端收
到sytle.css数据的同时,服务端会将sytle.js的文件推送给客户端,当客户端再次尝试获取sytle.js
时就可以直接从缓存中获取到,不用再发请求了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号