Storm核心基础
一、Stream:被处理的数据
二、Spout:数据源
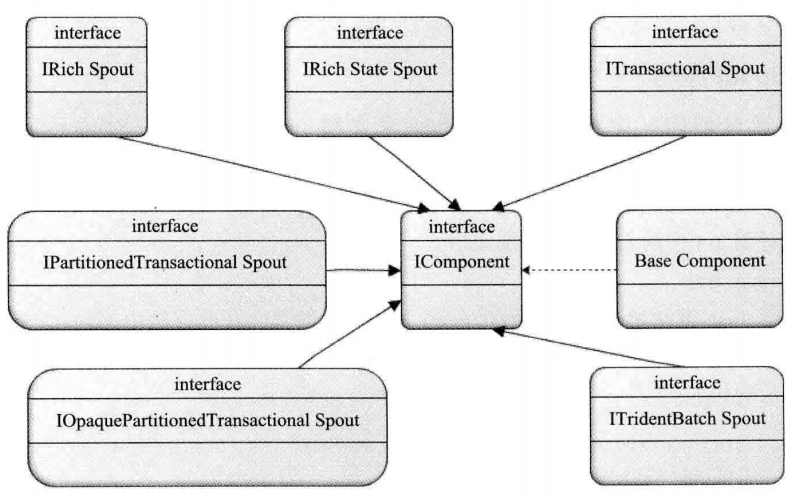
消息源Spout是Storm的Topology中的消息生产者(Tuple的创造者)。如图几个Spout接口都继承自IComponent
Spout从外部获取数据后,向Topology发出的Tuple可以是可靠的,也可以是不可靠的
可靠的:一个可靠的消息可以重新发射一个Tuple(如果该Tuple没有被Storm成功处理)
不可靠的:一个不可靠的消息源Spout一旦发出,一个Tuple就会彻底遗忘,不会在重新发了
Spout可以发射多个Stream,使用OutputFieldsDeclarer.declareStream来定义多个流,然后使用SpoutOutputCollector来发射指定的流
Spout中几个重要的方法:
1、open方法:当一个Task被初始化时会调用此open方法,一般都会在此方法中初始化发送Tuple的对象SpoutOutputCollector和配置对象TopologyContext
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) { this.collector = collector; }
2、declareOutputFields方法:声明当前Spout的Tuple发送流。
public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("sentence"));//告诉组件发出数据流包含sentence字段 }
3、nextTuple方法:发射一个Tuple到Topology都是通过该方法。
public void nextTuple() { this.collector.emit(new Values("123")); }
三、Bolt:处理数据
Bolt是接收Spout发出元组Tuple后处理数据的组件,所有的消息处理逻辑被封装在Bolt中,Bolt负责处理输入的数据流并产生输出的新数据流;Bolt把元组Tuple作为输入,之后处理产生新的Tuple;
1、客户机创建Bolt,然后将其序列化为拓扑,并提交给集群的主机
2、集群启动worker进程,反序列化Bolt,调用prepare方法开始处理元组
3、Bolt处理元组,Bolt处理一个输入Tuple,发射0个或多个元组,然后调用ack通知Storm自己已经处理过这个Tuple了。Strom提供一个IBasicBolt自动调用ack。

在创建Bolt对象时,通过构造方法,初始化成员变量,当Bolt被提交到集群时,这些成员变量也会被序列化,所以通过反序列化可以取到这些成员变量
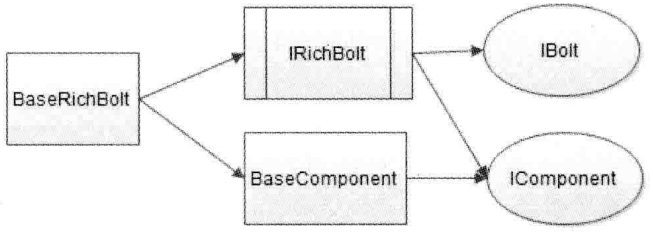
IBolt继承了Serializable,在创建Bolt在序列化之后被发送到具体执行的Worker上,worker在执行Bolt时候先执行perpare方法传入当前执行的上下文,然后调用execute方法,对Tuple进行处理,并用prepare传入的OutPutCollector的ack方法(表示成功)或fail(表示失败)来反馈处理结果
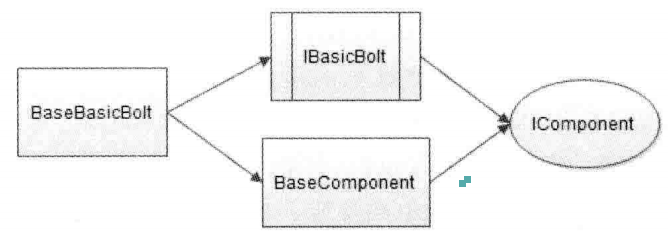
IBasic接口在执行execute方法时,自动调用ack方法,其目的就是实现该Bolt时,不用在代码中提供反馈结果,Storm内部会自动反馈成功
几个重要的方法:
1.prepare方法:preparre方法为Bolt提供了OutputCollector,用来从Bolt中发送Tuple,在Bolt中载入新的线程异步处理,OutputCollector是线程安全的。Bolt中prepare、execute、cleanup等方法中进行
2.declareOutPutFields方法:声明当前Bolt发送的Tuple中包含的字段;Bolt可以发射多条消息流,使用OutputFieldsDeclarer.declareStream方法来定义流,之后使用OutputCollector.emit来选择要发射的流
3、getComponentConfiguration方法:当系统需要每隔一段时间执行特定的处理时,就可以用它
4、execute方法::以一个Tuple作为输入,Bolt使用OutPutColector来发射Tuple,Bolt必须为他处理的每一个Tuple调用ack方法,以通知Storm该Tuple处理完毕了,从而通知该Tuple的发射者Spout
1) emit有一个参数:该参数是发送到下游Bolt的Tuple,此时由上游发来的旧Bolt就此隔断,新的Tuple和旧的Tuple不在属于同一颗Tuple数。新的Tuple另起一颗新的Tuple树
2)emit有两个参数:第一个参数是旧的Tuple的输入流,第二个参数是新的往下游Bolt下发的Tuple流。此时新的Tuple和旧的Tuple还属于同一颗Tuple树,即如果下游的Bolt处理失败,则向上传递到当前Bolt,当前Bolt根据旧的Tuple继续往上游传递,申请重发失败的Tuple,保证Tuple处理的可靠性
四、Tuple:数据单元
Tuple是Strom的主要数据结构,并且是Storm中使用的最基本单元、数据模型和元组;Tuple是一个值列表,Tuple中的值可以是任何类型的,动态类型的Tuple的fields可以不用声明;默认情况下,Storm中的Tuple支持私有类型,字符串,字节数组等作为它的字段值,如果使用其他类型,就需要序列化该类型。
Tuple的默认类型:integer、float、double、long、short、string、byte、binary(byte[])。Tuple可以理解为键值对,其中键就是定义在declareOutputFields方法中的Fields对象,值就是在emit中发送的Values对象
Tuple声明周期:
1、Storm调用Spout的nextTuple方法来获取下一个Tuple
2、Spout通过Open方法的参数提供的SpoutOutputCollector将新的Tuple发射到其中一个输出消息流(发射Tuple时,Spout提供一个message-id,通过这个ID来追踪该Tuple)
3、Storm跟踪该Tuple的树形结构是否成功创建,并根据message-id调用Spout中的ack函数,已确认Tuple是否被完全处理。
4、如果Tuple超时,则调用Spout的fail方法
5、在任务完成后,Spout调用Cloes方法结束Tuple的使命
public interface ISpout extends Serializable { void open(Map var1, TopologyContext var2, SpoutOutputCollector var3); void close(); void activate(); void deactivate(); void nextTuple(); void ack(Object var1); void fail(Object var1); }
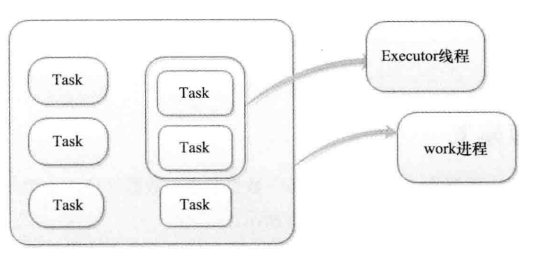
五、Task:运行Spout和Bolt中的线程
同一个Spout/Bolt的Task可能会共享一个物理线程,该线程称为Executor。实际的数据处理由Task来完成,Topology的生命周期中,Task数量不会变化,而Executor数量却不一定,在一般情况下,线程数小于等于Task数量。默认Task的数量等于Executor线程数量,即一个Executor线程只运行一个Task,Executor线程在执行期间会调用该Task的nextTuple或Executor
Worker:是运行这些线程的进程
一个worker进程一直一个Topology子集,他会启动一个或多个Executor线程来执行一个Topology的组件。因此在执行拓扑时,可能跨越一个或多个Worker,Storm会尽量均匀分配任务给所有的worker,不会出现一个Worker为多个Topology服务的情况
六、Stream Grouping:规定了Bolt接收何种类型数据作为输入
Storm包括6种流分组类型:
1、随机分组(Shuffer Grouping):随机分发元组到Bolt的任务,保证每个任务获得相等数量的元组
2、字段分组(Fields Grouping):根据指定字段分割数据流并分组
3、全部分组(ALL Grouping):对于每一个Tuple来说,所有Bolt都会收到,所有Tuple被复制到Bolt的所有任务上
4、全局分组(Global Grouping):全部的流都分配到Bolt的同一任务,就是分配给ID,最小的Task
5、无分组(NO Grouping):不分组的含义是,流不关心到底谁会收到它的Tuple,目前无分组等效于随机分组,不同的是Storm把无分组的Bolt放到订阅Bolt或Spout的同一线程中执行(在可能实现的前提下)
6、直接分组(Direct Grouping):元组生产者决定元组由那个元组消费者接受
七、Topology:是由Straming Grouping连接起来的Spout和Bolt节点网络
1、本地模式:
Config conifg = new Config();
config.setDebug(true); config.setNumWorkers(2); LocalCluster cluster = new LocalCluster(); cluster.submitTopology("test",config,builder.creatTopology());
Utils.sleep(1000); cluster.killTopology("test"); cluster.shutdown();
submitTopology有三个参数:要允许Topology的名称,一个配置对象,以及要运行的Topology的本身
Topoogy是以名称来唯一区别的,可以用这个名称杀掉该Topology,而且必须显示的杀掉,否则他会一直运行
几个比较重要的配置:
config.setNumWorkers(2):定义希望集群分配多少个工作进程来执行这个Topology,Topology中的每个组件都需要线程来执行。每个组件到底用多少个线程是通过setBolt和setSpout来指定的
config.setDebug(true):Storm会记录下每个组件发射的每条信息
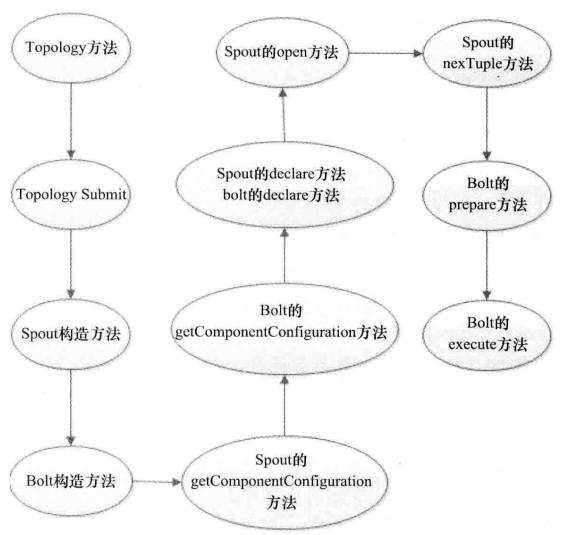
Topology方法调用流程:
1.每个组件(Spout或Bolt)的构造方法和declareOutputFields方法都只被调用一次
2.open和prepare方法被调用多次,在入口函数中设定的setSpout或setBolt中的并行度参数指Execute的数量,是负责运行组件中Task的数量,此数量是多少,上述两个方法就会被调用多少次,在每个Execute运行时调用一次
3.nextTuple方法和execute方法是一直运行的,nextTuple方法不断发射Tuple,Bolt的execute不断接受Tuple进行处理。只有这样不断进行,才会产生无界的Tupe流。
4.提交一个Topology之后,Storm创建Spout/Bolt实例并进行序列化,之后将序列化的组件发送给所有任务所在的节点,在每一个任务上反序列化组件
5.Spout和Bolt之间,Bolt和Bolt之间的通信,通过ZeroMQ的消息队列实现
6.在一个Tuple处理成功之后,需要调用ack方法来标记成功,否则调用fail方法标记失败,重新处理该Tuple
Topology中几个比较重要的并行度相关概念
1.Worker(工作进程):每个worker都属于一个特定的Topology,每个Supervisor节点的Worker可以有多个,每个Worker使用一个额单独的端口,Worker对Topology中的每个组件运行一个或者多个Executor线程来提供Task的执行服务
2.Executor
Executor是产生于Worker进程内部的线程,会执行同一个组件的一个或多个Task
3.Task
实际的数据处理由Task完成,在Topology的声明周期中,每个组件的Task数量不会变化,而Executor的数量却不一定,Executor数量小于等于Task数量,在默认情况下,二者是相等的
worker、executor、task设置
1、Worker设置:可以设置yaml中Topology.workers属性,在代码中通过Config的setNumWorker方法设定
2、Executor设置:通过Topology入口类中的setBolt、setSpout方法的最后一个参数指定,如果不指定,则使用默认值为1
3、Task设置:在默认情况下和Executor数量一致,在代码中通过TopologyBuilder的setNumTasks方法设定具体某个组件的Task数量
Storm集群中的一个物理节点启动一个或多个worker进程,集群的topology都是通过这些进程运行的,然而,worker进程中又会运行一个或多个Executor线程,每个Executor线程只会运行一个Topology的一个组件(spout或bolt)的Task任务,task又是数据处理的实体单元。worker是进程,Executor对应于线程,Spout或Bolt是一个个Task;同一个Worker只执行同一个Topology相关的Task;在同一个Executor中可以执行多个同类型的Task,即在同一个Executor中,要么全部是Bolt类的Task,要么全部是Spout的Task;在运行时,Spout和Bolt需要包装成一个又一个Task

 浙公网安备 33010602011771号
浙公网安备 33010602011771号