【神经网络架构搜索】ProxylessNAS直接在ImageNet上搜索
【GiantPandaCV导语】这篇是MIT韩松实验室发布的文章,是第一个直接在ImageNet上进行搜索的NAS算法,并且提出了直接在目标硬件上对latency进行优化的方法。相比于同期算法NASNet、MnasNet等,搜索代价降低了200倍。
0. Info
Title: ProxylessNAS: Direct Neural Architecture Search On Target Task and Hardware
Author: MIT韩松团队
Link: https://arxiv.org/pdf/1812.00332v2
Date: ICLR2019
Code: https://github.com/MIT-HAN-LAB/ProxylessNAS
1. Motivation
之前的算法往往是在Proxy任务(比如CIFAR10、使用更少的epoch等方案)上进行训练,然后迁移到目标数据集(比如ImageNet),但是这种方案是次优的,存在一定的gap。
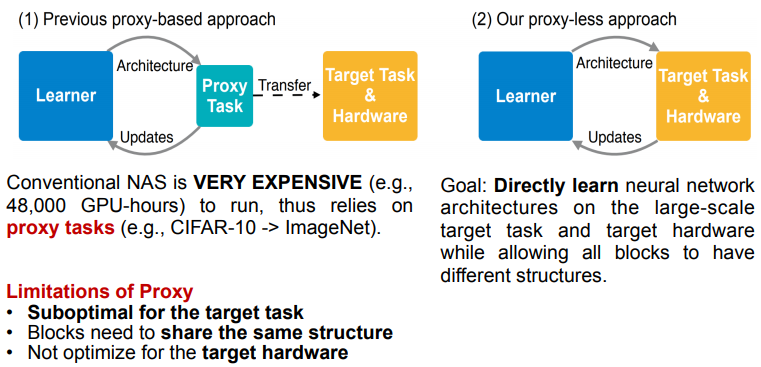
并且之前的Gradient-based NAS比如Darts由于需要将整个超网放在显存中,对资源的占用会比较大,因此对网络的大小带来了限制。
为了解决以上痛点,提出了ProxylessNAS,可以直接为目标硬件平台优化网络,解决了Gradient-based NAS中存在的高内存消耗问题,降低了计算代价。
2. Contribution
ProxylessNAS将搜索代价从40000GPU hours压缩到200GPU hours。
文章主要共享有:
-
ProxylessNAS是第一个不借助proxy任务,直接在目标数据集ImageNet上进行学习的NAS算法。可以有效地扩大搜索空间,达到更好的表现。
-
提出了从Path-level Pruning角度来处理NAS的思路,解释了NAS和模型压缩之间存在的紧密联系。通过使用Path-level binarization节省了一个数量级的内存消耗。
-
提出了Gradient-based方法来处理硬件目标,比如latency。让Latency这种硬件指标也变得可微分。并且ProxylessNAS也是第一个研究不同硬件架构上专用神经网络架构的工作。
-
使用一系列实验来证明ProxylessNAS的直接性directness和定制性specialization。在ImageNet和CIFAR10数据集上取得了SOTA的结果。
3. Method
3.1 过参数网络构建
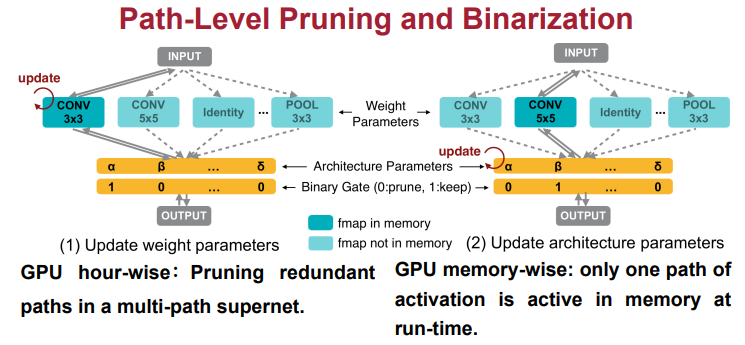
参考了one-shot和darts的搜索空间,构建了过参数网络,
对于one-shot来说,会将所有path路径输出相加;
对于darts来说,使用的是weighted sum的方式得到输出。
以上两种方式的实现都需要将中间结果保存,即所有路径的结果,这样相当于要占用N倍的显存。
为了解决以上问题,提出了Path binarization。
3.2 Path-level binarization
为了降低训练过程中占用的内存,每次训练过参数网络中的单条路径分支。
Path binarization需要引入N个网络架构参数α,pi的计算和darts一直。除此以外还有二进制开关g,1代表保留该路径,0代表不启用该路径。
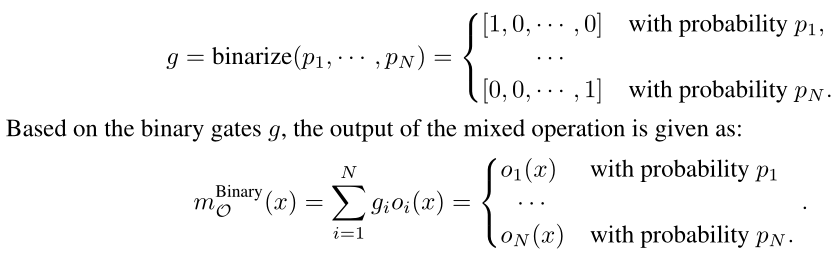
然后得到输出可以看出,在运行过程中,只有单路径被激活,节省了一个量级的显存消耗。
3.3 训练二值化网络
和darts类似,ProxylessNAS交替更新权重参数和架构参数。
-
在训练权重参数的时候,固定住架构参数,然后随机采样二进制开关。然后激活路径对应的网络使用梯度下降算法在训练集上进行训练。
-
在训练架构参数的时候,固定住权重参数,然后更新架构参数。
完成训练以后,选择拥有最高path weight的path作为最终网络结构。
在计算梯度的时候,进行了以下近似:
其中\(\delta_{i j}\)是一个指示器,当i=j的时候为1,反之为0。
但是如果用以上公式进行更新,实际上还是需要N背的计算资源。所以这里每次更新架构参数的时候,采样两条路径,相当于将N降到了2。
ps: 感觉这种方式会导致收敛变慢,相比于Darts,为了内存空间牺牲了时间效率。
3.4 使硬件指标Latency可微分
提出两个方法来解决不可微的目标。
方法一:让Latency可微
F代表对应op的延迟预测器,预测op所对应的延迟。
求偏导:
将Latency作为loss一项:
方法二:使用基于强化学习方法
使用REINFORCE算法来训练二值化权重。
4. Experiment
CIFAR10: 选择PyramidNet作为backbone,具体实现细节需要看原文。

R代表使用强化学习得到的结果,G代表使用梯度优化得到的结果。c/o代表使用了cutout。
ImageNet: 在GPU、Mobile phone、CPU上进行了实验。
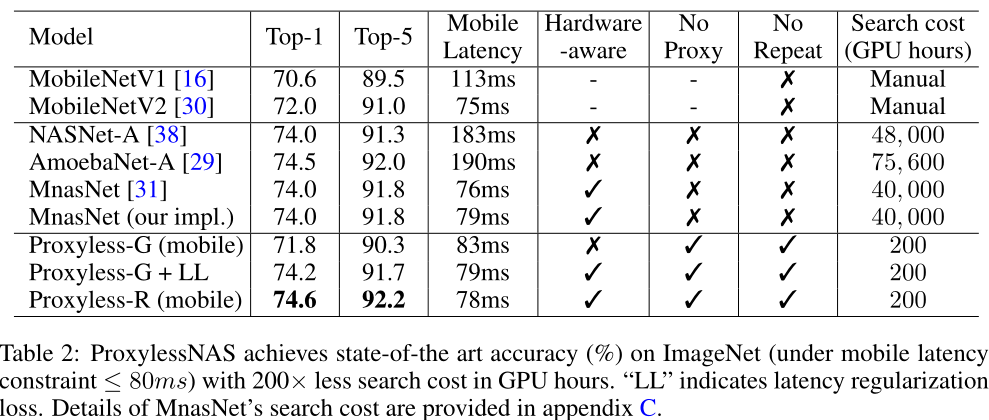
主要关注Search Cost这一栏,相比之前的MNasNet、NASNte、AmoebaNet节省了200倍的GPU hours。
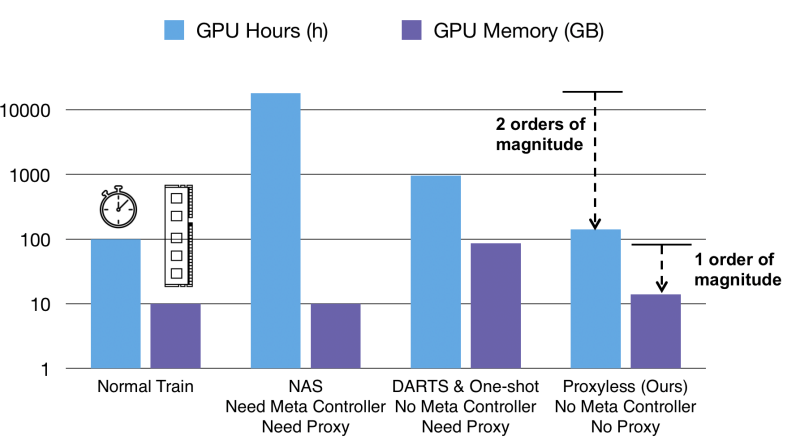
上图结果展示了ProxylessNAS的优越性,其训练的时间和占用的内存都和正常训练属于一个量级。
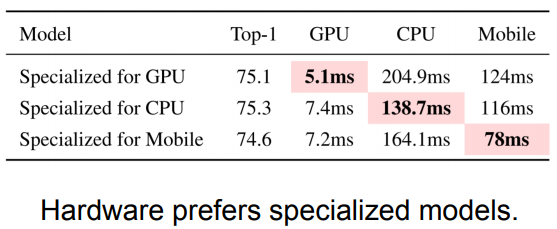
ProxylessNAS专门为不同硬件设计的网络在对应硬件上的延迟是最低的。
5. Revisiting
ProxylessNAS是第一个直接在目标数据集ImageNet上进行训练的神经网络搜索算法,通过使用path binarization解决了以往Gradient-based NAS中存在的显存占用过高的问题,可以做到占用和普通网络相同量级显存。同时ProxylessNAS也是第一个可以为不同的硬件设置定制化网络的算法。
在这个部分补充一些知识点:深度学习中的显存占用分析。并回答几个问题。
问题一:哪些操作会占用显存?
-
模型自身的参数,主要包括权重。有参数的层:卷积、全连接、BN等都包含了大量参数。这部分内容和输入设置无关,模型加载后就会占用显存。
-
模型中间的结果、梯度等。优化器在优化过程中需要保存对应权重的梯度才可以计算,不同优化器需要的中间变量数目不定,比如Adam优化器,动量占用显存最多。
-
输入输出占用的显存。主要包括feature map等,计算得到每一层输出的tensor形状,就可以计算相应需要的显存占用。这部分显存占用是和batch size成正比的。
问题二:显存大小和batch size是否成正比?
有了上边问题做铺垫,这个问题就很好解释了。显存大小包括三个部分,模型自身参数、模型梯度、输入输出占用显存。batch size仅仅会影响到输入输出的显存占用,所以并不是完全成正比。
问题三:如何降低显存占用?
经常会遇到GPU显存溢出out of memory的报错,通过以上分析,可以得知有以下处理方法:
-
使用更小的模型,可以修改模型通道数或者更换模型。
-
降低batch size大小。
-
可以使用amp中的混合精度方法,通过使用fp16降低显存占用。
-
清空中间变量,优化代码比如inplace=True
问题四:增大batch size会带来什么影响?
-
batch size增大可以加快速度,但是是并行计算方面的,带来的增益优先。
-
batch size增大可以减缓梯度震荡,需要更少的迭代次数,收敛更快。但是每次迭代耗时更长。
-
batch size调整的同时也需要调整对应的learning rate,以ImageNet上ResNet50为例,官方推荐的lr=0.1 对照 batch size=256, 假设我要调整batch size=1024,那么新的lr=0.1 x 1024 / 256。
6. Reference
https://arxiv.org/abs/1812.01187
https://oldpan.me/archives/how-to-calculate-gpu-memory
https://blog.csdn.net/liusandian/article/details/79069926
https://zhuanlan.zhihu.com/p/144318917
https://zhuanlan.zhihu.com/p/72604968
https://file.lzhu.me/projects/proxylessNAS/figures/ProxylessNAS_iclr_poster_final.pdf

 浙公网安备 33010602011771号
浙公网安备 33010602011771号