
python基础篇(六)
PYTHON基础篇(六)
- 正则模块re
- A:正则表达式和re模块案例
- B:re模块的内置方法
- 时间模块time
- A:时间模块的三种表示方式
- B:时间模块的相互转换
- 随机数模块random
- A:随机数模块的使用方法
- 系统模块os
- A:系统模块的使用方法
- python解释器交互模块sys
- A:交互模块的使用方法
- 序列化模块
- A:序列化模块的介绍
- B:序列化模块的使用方法
- 模块的导入
- A:模块复用功能的使用说明
- B:模块起别名
- C:多模块同时导入和模块导入规则
- D:from 模块 import 方法
- E:模块执行隔离
- 包的进阶
- A:包的基础介绍
- B:包的基础使用
- C:包的绝对导入和相对导入
♣一:正则模块re
A:正则表达式和re模块案例
正则表达式,只要是和计算机有一定接触的,或多或少都能知道正则表达式,它能快读帮忙匹配到相应的字符,以至于我们常用的execl,word,文件搜索工具等都可以看到正则的影子,正则的发明不亚于鼠标键盘的发明,而且学习计算机必定会接触到正则表达式,而且正则表达式的规则在任何一种语言里面都存在,而且是相同的。


#判断用户输入的电话号码是否合规 import re phone_number=input('请输入有效的电话号码:') if re.match('^(13|15|18)[0-9]{9}$',phone_number): #手机号码必须是13,15,18开头,必须是数字类型,必须满足11位({9}这个是减掉了13,15,18这两位) print('是有效的手机号码') else: print('无效的手机号码')
上面的案例,如果是用for循环去写就会重复写很多代码,且读起来也麻烦,使用正则就会很方便,精简到一行中完成了对号码检验的工作。
| 正则表达式 | 查询字符 | 查询结果 | 表达式说明 |
| 123456789 | 8 | 8 | 匹配1到9数字里面的任意一个数字 |
| 1234567 | a | 无 | 数字只能匹配数字 |
| [0-9] | 5 | 5 | [0-9]和0123456789是一个意思,就是0到9 |
| [a-z] | c | c | 匹配小写的26个英文字母,也就是a到z,同样字母只能匹配字母 |
| [A-Z] | C | C | 和上面的小写相反,匹配大写的26个英文字母 |
| [0-9a-kA-K] | 12cd_FD | 12cdFD | 可以匹配数字,大小写字母a-K,验证16进制,但是不能匹配下划线,要连下划线也要匹配可以使用\w |
字符
| 正则元字符 | 匹配内容 | 匹配结果 | 表达式说明 |
| . | !@#$%^&*90()=-+[]{}\/az | !@#$%^&*90()=-+[]{}\/az | 匹配除换行符以外的任意字符 |
| \w | !@#$%^&*90()=-+[]{}\/az_ | 90az_ | 匹配任意字母数字下划线 |
| \s | !@#$%^&*90() =-+[]{}\/az_ | 空格 | 匹配任意的空白符 |
| \d | !@#$%^&*90() =-+[]{}\/az_ | 90 | 匹配任意数字 |
| \n | !@#$%^&*90() =-+[]{}\/az_ | 换行符 | 匹配换行符 |
| \t | !@#$%^&*90() =-+[]{}\/az_ | 制表符 | 匹配制表符,就是键盘上的tab键 |
| \b | a | 匹配到2个结果 | 匹配一个单词的结尾,也就是边界符 |
| ^ | !@#$%^&*90() =-+[]{}\/az_ | 匹配到1个结果 | 匹配字符串的开始(重要) |
| $ | !@#$%^&*90() =-+[]{}\/az_ | 匹配到1个结果 | 匹配字符串的结尾(重要) |
| \W | !@#$%^&*90() =-+[]{}\/az_ | !@#$%^&*() =-+[]{}\_ | 匹配非字母数字下划线 |
| \S | !@#$%^&*90() =-+[]{}\/az_ | !@#$%^&*90()=-+[]{}\/az_ | 匹配非空白符 |
| \D | !@#$%^&*90() =-+[]{}\/az_ | !@#$%^&*() =-+[]{}\/az_ | 匹配非数字 |
| a|b | abcdf!@@# | ab | 匹配a或者b,|代表或的意思 |
| () | 1333331555522214444 | 133331555514444 | p匹配括号内的表达式,还表示一个组 |
| [123] | 123344553 | 12333 | [中括号里面可以指定要事先匹配的内容,超过中括号的内容不能匹配] |
| [^123] | 123344553 | 4455 | 和上面相反,匹配非括号事先指定的内容 |
在a|b或的正则里面,常用的场景是当一个条件不匹配前面一个就匹配后面一个,所以一般都把匹配比重高且复杂的放前面,比重小短的放后面。
量词
| 正则量词 | 匹配内容 | 匹配结果 | 表达式说明 |
| * | 123 | 3个结果 | 匹配零次或多次,*号必须和其它配套使用,不能单独出现 |
| + | 123 | 2个结果 | 匹配1次或多次,+号必须和其它配套使用,不能单独出现 |
| ? | 123 | 1个结果 | 匹配零次或1次,?号必须和其它配套使用,不能单独出现 |
| {n} | 123 | 3个结果 | 匹配n次,配套使用,不能单独出现 |
| {n,} | 123 | 3个结果 | 匹配n次或多次, 配套使用,不能单独出现 |
| {n,m} | 123 | 3个结果 | 匹配n次或m次, 配套使用,不能单独出现 |
如果量词出现在[]号里面就不需要进行转义,因为在[]号字符组里面标示只能匹配一次,这样量词*,?这样的出现在字符组里面就没有正则的意义了,如果是要计算[1-9]1减去9这样的计算,-号是需要加\斜杠转义的。
.^$符号
| 正则表达式 | 匹配内容 | 匹配结果 | 表达式说明 |
| 1. | 12314133 | 121314 | 匹配所有1.的字符,就是1开头再加1后面的任意一个字符 |
| ^1. | 12314133 | 12 | 匹配必须是以1开头后面1个字符 |
| 1.$ | 12 | 12 | 匹配1后面1个字符,意味着只能匹配两个,后面还多一个都不能匹配 |
其它符号
| 正则表达式 | 匹配内容 | 匹配结果 | 表达式说明 |
| 1.? | 1234123413 | 121213 | ?表示匹配零次或一次,即只匹配"1"后面一个任意字符 |
| 1.* | 1234123413 | 1234123413 | *表示匹配零次或多次,即匹配"1"后面零个和多个任意字符 |
| 1.+ | 1234123413 | 1234123413 | +表示匹配1次或多次,即匹配"1"后面1个和多个任意字符 |
| 1.{1,2} | 1234123413 | 12312313 | 1.表示匹配1后面任意1个字符,但是{1,2}就限制1后面再匹配两个任意字符 |
| 1.*? | 123 | 1 | s上面的*,+,.,?,等单独使用都是贪婪匹配,只要其中一个和?号组队了就变成了惰性匹配 |
惰性匹配就是经可能的匹配最少最短的内容,贪婪匹配就是经可能的匹配最多的内容。
字符集
| 正则表达式 | 匹配内容 | 匹配结果 | 表达式说明 |
| 1[123]* | 1234512456 | 12312 | 表示匹配"1"后面[123]的字符任意次 |
| 1[^123]* | 12345156456 | 1156456 | 表示除了123之外的1后面的字符任意次 |
| [\d] | 12345sz | 12345 | 匹配任意一个数字,和[0-9]一样 |
| [\d]+ | 12az345sz1!@1 | 1234511 | 匹配任意数字,和[0-9]一样 |
分组
| 正则表达式 | 匹配内容 | 匹配结果 | 表达式说明 |
| ^[1-9]\d{13,16}[0-9x]$ | 1234567890123451 | 1234567890123451 | 匹配一个身份证号码 ,但是也可以是任意的16位数字 |
| ^[1-9]\d{14}(\d{2}[0-9x])?$ | 1234567890123451 | 无 | 通过()将其分组,前面必须是1到9的数字满足14位之后,后面分组也要满足两位1-9的数字或者字母x。 |
| ^([1-9]\d{16}[0-9x]|[1-9]\d{14})$ | 123456789123456 | 123456789123456 | 表示先匹配[1-9]\d{16}[0-9x]如果没有匹配上就匹配[1-9]\d{14} |
转义符\
| 正则表达式 | 匹配内容 | 匹配结果 | 表达式说明 |
| \\n | \n | \n | \n本身代表换行符,如果要显示\n就需要加一个\,转译一下 |
| "\\\\n" | '\\n' | \ | 如果在python中,字符串中的'\'也需要转义,所以每一个字符串'\'又需要转义一次 |
| r"\\\n" | \\\n | \\\n | 在字符串之前加r,让整个字符串不转义 |
贪婪匹配
| 正则表达式 | 匹配内容 | 匹配结果 | 表达式说明 |
| <.*> | <12233><123> | <12233><123> | 默认为贪婪匹配模式,会匹配尽量长的字符串 |
| <.*?> | <12233><123> | <12233><123> | 加上?为将贪婪匹配模式转为非贪婪匹配模式,会匹配尽量短的字符串 |
非贪婪匹配
| 正则表达式 | 匹配内容 | 匹配结果 | 表达式说明 |
| [1*?] | 12323 | 1 | 匹配任意次,但是尽可能的少的匹配 |
| [12+?] | 12323 | 122 | 匹配1次或多次,但是尽可能的少的匹配 |
| [2??] | 12323 | 22 | 匹配l零次或1次,但是尽可能的少的匹配 |
| [1,2]? | 12323 | 122 | 匹配n次或m次,但是尽可能少的匹配 |
| [1,]? | 12323 | 1 | 匹配n次以上,但是尽可能少的匹配 |
量词后面加?号就标识惰性匹配(非贪婪匹配),其中.*?是惰性匹配最常用的模式,.*?123标示一直匹配到123就停止。
上述只是正则表达式的一些基本情况,也是平时会用到的部分,当然也需要我们不断的学习正则表达式,正则是在任何语言都存在的功能,属于通用类的内容。
在python中如果需要去匹配上述的特殊字符可以通过r来完成转义的工作
ret=re.findall(r'\\s',r'\s') print(ret) 执行结果: ['\\s']
B:re模块的内置方法
要学习python中的正则需要导入re模块,不然是无法使用的。
re模块中三个重要的方法:
re模块中findall方法
import re ret=re.findall('[a-z]+','abc bac cba') #格式('[a-z]+','abc bac cba')'第一组引号里面是查找的内容',’后面一组引号是要匹配的内容' #在'abc bac cba'里面查找[a到z]+任意次 print(ret) #执行结果: ['abc', 'bac', 'cba'] 可以看到结果都放在了列表中 ret=re.findall('a','abc bac cba') #匹配abc bac cba中所有的a print(ret) 执行结果: ['a', 'a', 'a']
findall(返回所有匹配的结果放在列表中)
findall中的优先查询
ret=re.findall('www.(baidu|qq).com','www.qq.com') #想得到的结果是www.qq.com,因为baidu和qq之间用的|或 print(ret) #执行结果 ['qq']#结果是只取到了qq #为什么会得到这个结果,就是findall是没有group的分组机制,所以它只能优先匹配分组(baidu|qq)分组里面的内容 ret=re.findall('www.(?:baidu|qq).com','www.qq.com') print(ret) #执行结果: ['www.qq.com'] #如果在分组前面加上?:就是取消分组优先 ?号在正则里面标识匹配0次或者1次,在.后面出现的?号就是惰性匹配,匹配到了就结束
在python re模块中(分组优先级的概念),但是在正则里面分组是用于对字符整体进行约束
re模块中search方法
ret=re.search('a','abc bac cba') print(ret) #执行结果: #<_sre.SRE_Match object; span=(0, 1), match='a'> #可以看到不加group返回的就是结果的对象 ret=re.search('a','abc bac cba').group() print(ret) 执行结果: a 只有加了group之后才能正常返回结果 ret=re.search('a','abc bac cba') print(ret.group()) 执行结果: a ret=re.search('h','abc bac cba') print(ret) print(ret.group()) 执行结果: None 可以看到print(ret)的时候,返回的是none,因为h在要找的字符中找不到。 File "C:/pycharm_fill/正则表达式.py", line 30, in <module> print(ret.group()) AttributeError: 'NoneType' object has no attribute 'group' #后面在调用group的时候直接就报错了,这是因为group是没有none方法的,所以就报错了
# ret=re.search('a','abc bac cba') # if ret: # print(ret.group()) # 执行结果: # a ret=re.search('h','abc bac cba') if ret: print(ret.group()) else: print('没有找到该字符') #可以看到找不到内容的时候就不会有报错内容产生了,这个时候可以加一次不能找到结果的输出,当然也可以不需要else的部分 执行结果: 没有找到该字符
search (从前往后匹配,找到一个就返回,返回的变量需要调用group的方法,不然返回的就是变量的对象,如果没有找到的情况下,就会返回None,None是没有group的方法的,结果就会报错)
search如果是正则用的分组,那么要取分组的内容,可以使用group(参数)来获取分组的内容,group(1)就代表取第一个分组里面的内容,如果是给分组命名了,那么就直接取分组名即可
分组命名:
ret=re.search('\d(?P<命名>123)+','123456qasz') ?p<>是分组命名的固定格式,<>号里面写分组名 取分组的内容直接,ret.group(命名)
分组命名引用:
# html1="<h1>hellopython123</h1>" # ret=re.search("<(?P<name>\w+)>\w+</(?P=name)>",html1) # print(ret.group('name')) #上面我对分组进行了命名,后面又用了一次同样的命名,如果在代码里面前后的内容 # #接近,就可以使用分组命名之后在后面应用一次分组名,但是后面引用的分组名必须和前面的命名一致。 # print(ret.group()) # 执行结果 # h1 #分组里面的内容 # <h1>hellopython123</h1> #整理内容 html1="<h1>hellopython123</h1>" ret=re.search(r"<(\w+)>\w+</\1>",html1) #也可以直接定义分组,后面按照位置来引用分组,也可以实现上面的效果 print(ret.group(1)) #如果是分组较多的情况下,还是使用分组命名,可读性高点 print(ret.group()) 执行结果: h1 <h1>hellopython123</h1>
分组命名和应用必须在一条正则里面完成。
re模块中match的方法:
ret=re.match('h','abc bac cba') if ret: print(ret.group()) else: print('没有找到该字符') # 执行结果: # 没有找到该字符 ret=re.match('a','abc bac cba') if ret: print(ret.group()) else: print('没有找到该字符') # 执行结果: # a ret=re.match('c','abc bac cba') if ret: print(ret.group()) else: print('没有找到该字符') # 执行结果: # 没有找到该字符 ret=re.match('ab','abc bac cba') if ret: print(ret.group()) else: print('没有找到该字符') 执行结果: ab
match(match是从头开始匹配,如果正则的规则是从头开始能匹配上就返回一个变量,就是说整个字符串里面,正则刚好匹配了一个字符就返回了,有点像正则里面的^a以a开始,不一样的是字符串即使有多个a,但是match匹配上第一个了就返回了,而且match也是需要调用group的,同时找不到返回None的时候调用group的时候就会报错)
search是查找,match是匹配,两个的是与一定区别的
search和match中的group方法:
ret=re.search('^[1-9](\d{14})(\d{2}[0-9x])?$','129535188108171312') #129535188108171312是身份证 print(ret.group(1)) #这个是匹配了(\d{14})这个括号里面的内容 print(ret.group(2)) #这个是匹配了(\d{2}[0-9x])这个括号里面的内容 执行结果: 29535188108171 312 #可以看到我们在group里面加了指,得到的结果是将身份证进行了拆分,从两个括号里面进行的拆分 group可以在例如我要取身份证后4位和前面所有的内容,分组显示,这个就是需要用到group的功能了,但是也只能在match和search中使用
上面是re模块的最常用的三种方法。
re模块中spilt的方法:
ret=re.split('ab','abcd') #split的用法是,先按照查找的a匹配一次取到bcd,然后再按照bcd取一次,得到结果cd print(ret) 执行结果: ['', 'cd'] ret=re.split('ab','abc bca cba') #如果字符串是在一行的话,即使中间哟空格也是当做一行处理 print(ret) 执行结果 ['', 'c bca cba']
spilt中的优先查询
ret=re.split('(\d+)','abc123bca456cab') #在spilt中也是,如果加了分组(),就会在切的时候还给保留切分的部分 print(ret) #执行结果 #['abc', '123', 'bca', '456', 'cab'] #反之,不用分组就正常切 ret=re.split('\d+','abc123bca456cab') print(ret) #执行结果 ['abc', 'bca', 'cab']
re模块中sub的方法:
ret=re.sub('\d','K','abc1 bca2 cba3') #将'abc1 bca2 cba3'里面的数字(\d)替换成k print(ret) 执行结果: abcK bcaK cbaK ret=re.sub('\d','K','abc1 bca2 cba3',1) #将'abc1 bca2 cba3'里面的数字(\d)替换成k,只替换一个 print(ret) 执行结果: abcK bca2 cba3
re模块中subn的方法:
ret=re.subn('\d','K','abc1 bca2 cba3') # #将'abc1 bca2 cba3'里面的数字(\d)替换成k print(ret) # 执行结果: ('abcK bcaK cbaK', 3) #subn还能告诉你我替换了几个
re模块中compile的方法:
obj=re.compile('\d{3}') #将正则表达式编译成一个正则表达式对象,就是通过compile方法把\d{3}编译一下复制给obj,编译的结果就是正则的规则,上面就是要匹配三个数字 ret=obj.search('abc123cba456bca678') print(ret.group()) ret=obj.findall('abc123cba456bca678') print(ret) #在通过上面已经编译好的规则调用re的其他方法,就可以完成预设定的规则 执行结果: 123 ['123', '456', '678'] #compile的功能在你代码中需要经常用,而且正则规则长而复杂的时候就可以用到compile了
re模块中finditer的方法:
finditer中的iter就是我们之前学的迭代器,find和iter结合之后就能实现一些功能,之前我们介绍过iter有一个优势就是节省内存,那么在需要匹配一个很多内容的情况下iter就有优势了
ret=re.finditer('\d','abc123bca456cab678') print(ret) #执行结果 #<callable_iterator object at 0x0000029B57391BE0> #可以看到返回了callable_iterator这个,说明是一个可用的迭代器 print(next(ret).group()) #执行结果 #1 print(next(ret).group()) #要配合使用next方法 #执行结果 #2 print([i.group()for i in ret])#取全部结果就需要用到for #执行结果 #['3', '4', '5', '6', '6', '7', '8'] finditer执行的结果是拿到了迭代器,迭代器里面的每一个元素要调用group才能拿到结果
flags的多选值
re.I(IGNORECASE)忽略大小写,括号内是完整的写法 re.M(MULTILINE)多行模式,改变^和$的行为 re.S(DOTALL)点可以匹配任意字符,包括换行符 re.L(LOCALE)做本地化识别的匹配,表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境,不推荐使用 re.U(UNICODE) 使用\w \W \s \S \d \D使用取决于unicode定义的字符属性。在python3中默认使用该flag re.X(VERBOSE)冗长模式,该模式下pattern字符串可以是多行的,忽略空白字符,并可以添加注释
ret中的remove的方法:
num1="1,2,4,45.56,12" #注意我要匹配的字符里面有小数 ret=re.findall(r"\d+",num1) print(ret) # 执行结果: # ['1', '2', '4', '45', '56', '12'] #直接把小数给分开匹配了 num1="1,2,4,45.56,12" #注意我要匹配的字符里面有小数 ret=re.findall(r"\d+\.\d+|\d+",num1) #在前面先匹配下小数在匹配整数即可,但是匹配的时候.要转义下,不然就匹配任意字符 print(ret) # 执行结果: # ['1', '2', '4', '45.56', '12']#可以正常取到小数了 #但是如果是要把小数去掉,只要整数,这个就不好办了,只能想办法取出来在去掉 num1="1,2,4,45.56,12" #注意我要匹配的字符里面有小数 ret=re.findall(r"\d+\.\d+|(\d+)",num1)#我直接只用分组优先的原则,让匹配的时候先去匹配有小数的, #后面分组优先了,发现及要匹配小数又要匹配其它数字,结果就不显示了 print(ret) # 执行结果: # ['1', '2', '4', '', '12']#就取到了一个空 print(ret.remove('')) #直接使用remove去除空格就行 print(ret) 执行结果 ['1', '2', '4', '12'] #得到的就是去掉小数的整数
B:re模块的基本使用
♣二:时间模块time
A:时间模块的三种表示方式
时间戳:
import time time1=time.time() print(time1) 这个打印出来的就是时间戳格式,之前我们用于计算程序执行时间的时候用到了, time1=time.time() time2=time.sleep(12) time3=time.time() print(time1-time3) 但是这种格式的时间不便于读取
时间戳 1541051493.6167455打印出来的是一个不便于读取的float类型数字,计算的是从1970年00:00:00开始计算的偏移量。
格式化时间字符串:
格式化时间字符串就是正常可读的时间。
print(time.strftime('%Y:%m:%d %X')) print(time.strftime('%Y:%m:%d %H-%M-%S')) #为什么是格式化时间,首先年月日时分秒是可以自己选要显示那些 #还有就是打印的形式也是可以自己去定义的
%y 两位数的年份表示(00-99) %Y 四位数的年份表示(000-9999) %m 月份(01-12) %d 月内中的一天(0-31) %H 24小时制小时数(0-23) %I 12小时制小时数(01-12) %M 分钟数(00=59) %S 秒(00-59) %a 本地简化星期名称 %A 本地完整星期名称 %b 本地简化的月份名称 %B 本地完整的月份名称 %c 本地相应的日期表示和时间表示 %j 年内的一天(001-366) %p 本地A.M.或P.M.的等价符 %U 一年中的星期数(00-53)星期天为星期的开始 %w 星期(0-6),星期天为星期的开始 %W 一年中的星期数(00-53)星期一为星期的开始 %x 本地相应的日期表示 %X 本地相应的时间表示 %Z 当前时区的名称 %% %号本身
结构化时间:
这个主要表示年,月,日,时,分,秒等,有这样的时间,我们就能计算出上一个时间和下一个时间经过了多少年多少月多少天这样的数值。
time1=time.localtime() print(time1) #执行结果 #time.struct_time(tm_year=2018, tm_mon=11, tm_mday=1, tm_hour=14, tm_min=23, tm_sec=22, tm_wday=3, tm_yday=305, tm_isdst=0) #可以发现是一个元祖 time1=time1.tm_year,time1.tm_yday print(time1) #执行结果 (2018, 305)#可以通过这个单独取时间。
时间戳是给计算机看的,格式话时间字符串是给人看的,结构化是用于计算并更好的表达时间。
B:时间模块的相互转换
上面的三种时间表示方式之间只能通过结构化时间来进行过渡之后相互转换,格式化时间不能和时间戳直接进行转换的。
时间戳转格式化 t1=time.time() print(time.localtime(t1)) print(time.gmtime(t1)) #gmtime是西方时间 #执行结果 #time.struct_time(tm_year=2018, tm_mon=11, tm_mday=1, tm_hour=14, tm_min=38, tm_sec=59, tm_wday=3, tm_yday=305, tm_isdst=0) #time.struct_time(tm_year=2018, tm_mon=11, tm_mday=1, tm_hour=6, tm_min=38, tm_sec=59, tm_wday=3, tm_yday=305, tm_isdst=0)
#格式化时间转时间戳 print(time.mktime(time.localtime())) #执行结果 1541054663.0
#格式化时间转结构化时间 print(time.strptime('2018-11-11','%Y-%d-%m'))#给的时间一定是字符串,后面必须告诉要以什么形式显示 #执行结果 #time.struct_time(tm_year=2018, tm_mon=11, tm_mday=11, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=6, tm_yday=315, tm_isdst=-1)
#结构化时间转格式化时间 print(time.strftime('%Y-%d-%m %H-%M-%S',time.localtime(2000000000))) #同样得提前指定显示的形式%Y-%d-%m %H-%M-%S #执行结果 2033-18-05 11-33-20
print(time.asctime(time.localtime(2000000000))) #执行结果 #Wed May 18 11:33:20 2033 print(time.asctime()) #执行结果 Thu Nov 1 15:55:18 2018
print(time.ctime()) #执行结果 Thu Nov 1 15:56:25 2018 print(time.ctime(2000000000)) #执行结果 #Wed May 18 11:33:20 2033
formerly_time=time.mktime(time.strptime('2013-09-06 12:12:12','%Y-%m-%d %H:%M:%S')) now_time=time.mktime(time.strptime('2018-11-11 12:12:13','%Y-%m-%d %H:%M:%S')) poor_time=now_time-formerly_time The_current_time=time.gmtime(poor_time) print('过去了%d年%d月%d天%d小时%d分钟%d秒'%(The_current_time.tm_year-1970,The_current_time.tm_mon-1,The_current_time.tm_mday-1,The_current_time.tm_hour,The_current_time.tm_min,The_current_time.tm_sec)) 执行结果: 过去了5年2月7天0小时0分钟1秒
♣三:随机数模块random
A:随机数模块的使用方法
返回随机数可以用到的场景不多,但是比如我要一定区间里面抽取一些数据,这个就有点像抽奖,或者是验证码这种的就可以使用随机数模块。
import random print(random.random()) #执行结果 0.06421289957677301 #会随机返回一个大于0小于1的小数 print(random.uniform(1,5)) #执行结果 3.069081294864049 #会在你指定的1到5的区间内返回一个小数
print(random.randint(1,6)) #执行结果 2 6 #返回一个1到6的整数,小于1和等于6的整数 print(random.randrange(1,6,2)) #执行结果 1#返回一个大于1小于6区间内的奇数,而且这个2是步长
#print(random.choice([1,19,68,[99,102]])) #执行结果 68#可以接收一个列表,或者说是可迭代的,在指定的范围随机抽取 print(random.sample([1,12,66,68,32,[99,102]],3)) #执行结果 [1, 68, [99, 102]] #从列表或者可迭代范围内随机抽取指定的数的数据,3就代表指定抽取3个数
num=[2,4,6,8,10,12] random.shuffle(num) print(num) #执行结果 [12, 10, 4, 2, 6, 8]#对指定的数据随机打乱排序 [8, 12, 2, 4, 10, 6]
if 1>0: kk1 = "" for i in range(6): num=random.randint(0,9) letter=chr(random.randint(65,90)) add=random.choice([num,letter]) kk1="".join([kk1,str(add)]) print(kk1) else: print("生成验证码失败")
♣四:系统模块os
A:系统模块的使用方法
os模块这个之前我们也用到了很多,os发生交互的主要是安装python的操作系统,属于进场使用的模块之一,本篇不在做详细的讲解,具体的用法可以参照下面网址来进行查询。
http://www.runoob.com/python3/python3-os-file-methods.html
♣五:python解释器交互模块sys
A:交互模块的使用方法
import sys print(sys.platform) 执行结果 win32 这个方法执行的记过很多情况下不准,如果是非要查看系统版本,建议不要使用这个模块,不过它可以用来查询linux系统上是哪个分支的linux
print(sys.version) 执行结果: 3.6.5rc1 (v3.6.5rc1:f03c5148cf, Mar 14 2018, 03:12:11) [MSC v.1913 64 bit (AMD64)] 可以查询到python解释器的版本
sys.exit()
用来退出程序,这个会用在当程序出现了异常,不能正常退出了,就可以在程序里面写一个exit,告诉系统程序退出,正常的情况下退出返回给系统的是0,错误的情况下返回给系统的就是1
print(sys.path) 返回模块的路径,当我们import某个模块的时候,就是调用的sys.path去找到模块所在的路径,如果是你自己编写的一些模块或者方法要频繁使用的话就可以使用sys.path来指定
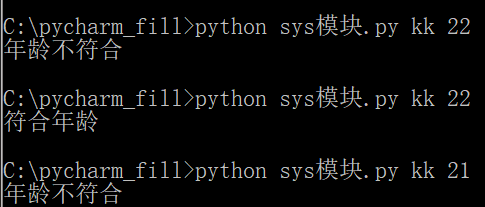
argv1=sys.argv
name=argv1[1]
age=argv1[2]
if name=='kk' and age=='22':
print("符合年龄")
sys.exit()
else:
print('年龄不符合')
我们可以通过定义argv事先指定好一些固定的指,让脚本执行的时候携带这些参数,从而去判断脚本执行的情况:
♣六:序列化模块
A:序列化模块的介绍
首先我们要理解什么是序列,在python里面序列通常指的就是字符串,那么我们理解序列化就简单了,就是将其它数据类型转换成一个字符串类型就是指的序列化。
为什么要转换成字符串类型,其实意义很明显,因为其它的数据类型不方便读,假如你写了一个爬虫爬去了一些数据,结果表现的形式是字典,列表等形式,不明白的人不清楚你这个是什么内容,为了方便普通大众能有好的读取的程序的结果,转化字符串是必要的。
还有就是网络传输的过程中用的形式是byte,也是需要将数据转换成字符串的。
最后就是写了一个程序,有时候就是需要把其它数据类型转换成字符串的或者把字符串转换成其它数据类型的时候,也是需要用到序列化的,当然从其它转换成字符串的也叫反序列化。
json是一种通用的序列化格式,不止在python,包括其它语言也能使用,例如我通过python程序获取了一部分数据,但是这部分数据需要提供给java编写的程序使用,那么json就能很好的把数据转换,给下面的节点程序提供数据来源。
json不是说万能的,一定有在python里面的数据类型,是不能被转换的,所以我们在写程序的时候,一定要尽量少用多种数据类型,避免出现数据不能转换的时候问题
pickle这个弥补json不能转换所有python数据类型的缺点,pickle能解决python里面所有的数据类型序列化,但是缺点就是pickle出来的数据类型只有python才能理解,不通用,例如我在本地写了一个程序,这个程序调用了我本地安装的一个python外部模块(自己编写的模块),然后把这个程序给别人用的时候,别人本地也必须安装这个外部模块,不然我程序里面pickle的数据是不能被python正常识识别的。所以pickle只能用于python。
shelve是python3里面新出现的一种新序列化方法,它能序列化成一个句柄,然后对这个序列化句柄直接操作,相比前面两个要简单方便。
B:序列化模块的使用方法
json模块的四种功能:
import json dic={'k1':22,'k2':'pyhton'} print(type(dic),dic) dic1=json.dumps(dic) print(type(dic1),dic1) 执行结果: <class 'dict'> {'k1': 22, 'k2': 'pyhton'} <class 'str'> {"k1": 22, "k2": "pyhton"} #可以看到类型变成了str类型,而且显示都是双引号显示的 在json里面对数据格式有严格的要求,这个要注意一下。
import json dic={'k1':22,'k2':'pyhton'} print(type(dic),dic) dic1=json.dumps(dic) print(type(dic1),dic1) dic2=json.loads(dic1) print(type(dic2),dic2) #执行结果 <class 'dict'> {'k1': 22, 'k2': 'pyhton'} <class 'str'> {"k1": 22, "k2": "pyhton"} <class 'dict'> {'k1': 22, 'k2': 'pyhton'}#可以看到数据被反序列化了。变回dict类型了
在python能被正常序列化的数据就数字,字符串,字典,列表
元组现在也能被序列化,但是序列化之后会变成列表,这个需要注意下。
import json dic=(123,456,789) print(type(dic),dic) dic1=json.dumps(dic) print(type(dic1),dic1) dic2=json.loads(dic1) print(type(dic2),dic2) #执行结果 <class 'tuple'> (123, 456, 789) <class 'str'> [123, 456, 789] #可以看到变成了列表 <class 'list'> [123, 456, 789] #反序列化也还是列表list,并不能反序列化成元组
dumps和loads是对内存里面的数据进行操作,操作之后的数据还是在内存当中。
dump和load是对文件进行操作
import json dic1={'a':1,'b':2} file=open('kk1.log','w',encoding='utf8') json.dump(dic1,file) file.close() #执行结果: kk1.log文件里面的内容{"a": 1, "b": 2}
import json file=open('kk1.log',encoding='utf8') dic1=json.load(file) print(type(dic1),dic1) file.close() #执行结果: <class 'dict'> {'a': 1, 'b': 2}
import json dic1={'a':1,'b':'呵呵'} file=open('kk1.log','w',encoding='utf8') json.dump(dic1,file) file.close() #执行结果 {"a": 1, "b": "\u5475\u5475"}#发现写到文件里面的中文,我已经制定编码格式了,但是写进去的还是byte类型。 file=open('kk1.log',encoding='utf8') dic1=json.load(file) print(type(dic1),dic1) file.close() #执行结果 <class 'dict'> {'a': 1, 'b': '呵呵'}发现序列化的时候没有问题。 import json dic1={'a':1,'b':'呵呵'} file=open('kk1.log','w',encoding='utf8') json.dump(dic1,file,ensure_ascii=False) file.close() #执行结果 {"a": 1, "b": "呵呵"}#只要使用ensure_ascii=False即可,不影响你读取
import json dic1={'a':1,'b':'呵呵'} file=open('kk1.log','w',encoding='utf8') json.dump(dic1,file,ensure_ascii=False) json.dump(dic1,file,ensure_ascii=False)#我分别写两次数据 file.close() #执行结果 {"a": 1, "b": "呵呵"}{"a": 1, "b": "呵呵"}#文件里面的内容 file=open('kk1.log',encoding='utf8') dic1=json.load(file) print(type(dic1),dic1) file.close() #执行结果 json.decoder.JSONDecodeError: Extra data: line 1 column 20 (char 19) #发现读取的时候报错了 这个是因为dump的数据只能load一次,要么一次性把数据dump进去,在进行load读取出来。
l1=[{'k1':'111'},{'k2':'111'},{'k3':'111'}]
file_log=open('file1','w')
for dic in l1:
str_file=json.dumps(dic)
file_log.write(str_file+'\n') #通过循环dumps数据到flie1文件里面,每循环写一次就换行
file_log.close()
# #执行结果
# {"k1": "111"}
# {"k2": "111"}
# {"k3": "111"}
file_log=open('file1')
l1=[]
for str_file in file_log:
dic_file=json.loads(str_file.strip())#在此处一定要加strip去掉换行
l1.append(dic_file)
file_log.close()
print(type(l1),l1)
#执行结果
<class 'list'> [{'k1': '111'}, {'k2': '111'}, {'k3': '111'}] #可以看到取出来还是和dumps进去的格式一样
解决上面dump分批写,不能读的问题,关键点就在于我每次dumps的时候换行,这样我在读的时候也是一行一行的loads
pickle的用法和json的方法一样,也是dumps,loads,dump,load四中方法,不过pickle就能直接避免json.load读数据的问题,还有就是pickle对文件进行操作的时候都需要加上b。
import pickle l1=[{'k1':'111'},{'k2':'111'},{'k3':'111'}] l2=[{'k1':'111'},{'k2':'111'},{'k3':'111'}] file_log=open('file1','wb') #pickle需要注意dump的时候需要wb的形式 pickle.dump(l1,file_log) pickle.dump(l2,file_log) file_log.close() file_log1=open('file1','rb') #load的时候需要rb的形式 pickle_file1=pickle.load(file_log1) pickle_file2=pickle.load(file_log1) print(pickle_file1) print(pickle_file2) file_log1.close() 执行结果 [{'k1': '111'}, {'k2': '111'}, {'k3': '111'}] #pickle就能避免json.load读数据的问题 [{'k1': '111'}, {'k2': '111'}, {'k3': '111'}]
shelve就区别于上面的json和pickle,它就一种用法就是open,shelve open一个文件之后就会获得一个文件句柄,然后我们可以把需要写的数据类型往句柄里面写。
import shelve file_log=shelve.open("shelve_file") file_log['key']={'int':10,'float':78.2,'string':"kkk"} file_log.close() #执行结果 本地会产生三个文件,shelve_file.bak结尾,shelve_file.dat结尾,shelve_file.dir结尾,这三个文件打开之后发现 内容是读不明白的,但是这三个文件一个都不能少。 file_log1=shelve.open('shelve_file') kk=file_log1['key'] file_log1.close() print(kk) #执行结果 {'int': 10, 'float': 78.2, 'string': 'kkk'}
shelve在官网有做说明,shelve不允许同一时间进行读写操作,所以在写代码的时候一定要看下场景,如果都是读操作,就可以使用shelve,shelve在只读模式下有一个问题,就是只读的模式还能进行写操作,这个得注意下。
import shelve file_log=shelve.open('shelve_file') print(file_log['key']) file_log['key']['nuw_key']='12kkkkk' #在此处我新加了一段字符串 file_log.close() file_log=shelve.open('shelve_file') print(file_log['key']) 执行结果 {'int': 10, 'float': 78.2, 'string': 'kkk'} {'int': 10, 'float': 78.2, 'string': 'kkk'} #结果发现新加的数据并没有被写进去 file_log1=shelve.open('shelve_file',writeback=True) #上面的问题指需要加上writeback=True就可以 writeback参数只要记录在open文件的后面就能记住所有的增删改的操作 print(file_log1['key']) file_log1['key']['nuw_key']='12kkkkk' file_log1.close() 执行结果 {'int': 10, 'float': 78.2, 'string': 'kkk', 'nuw_key': '12kkkkk'}#可以看到数据被加进去了
writeback也是有点明显,就是能让用户操作持久化,但是缺点也是明显的,就是writeback会在每次使用的时候消耗一定内存,而且每次writeback都是一次重新的操作,无论你前面有多少数据,都会重新操作一次,这样也会增加不必要的时间消耗。
♣七:模块的导入
A:模块复用功能的使用说明
在很多情况下我们写的基础功能代码都是可以复用,例如我们上面写的生成验证码的代码,这个时候我在写各种各样的登录相关的代码肯定会用到验证码的功能,那么我们是不是应该把验证码功能制作成一个模块,后面直接一句import 把验证码模块导入就可以使用了。
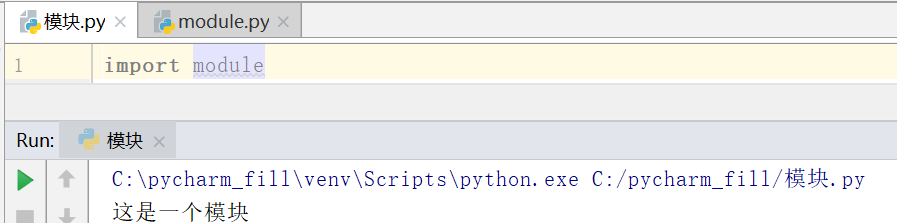
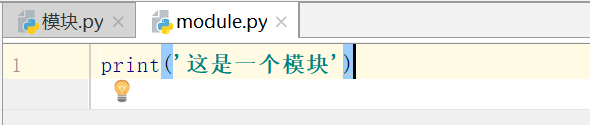
可以看到我写了一个module的python文件,在另外一个模块文件里面import就能将事先写好功能的文件给调用执行,这个就是上面说的模块导入复用,当然import的时候必须指定要导入模块的名字,模块的名字要符合python文件的命名规则。
还是这个文件,虽然能被复用,但是我们在上面学习其它模块的时候,发现模块都都是time.time这样的,我们导入模块用了模块提供的一些方法,并不是说和上面一样很简单的功能。

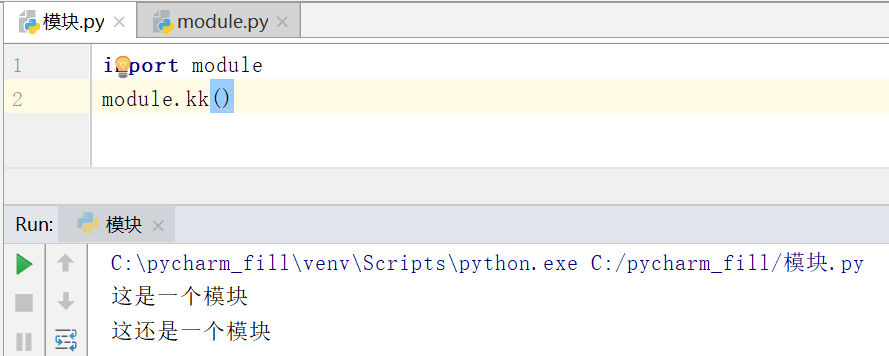
我们在模块里面在加上一个函数,这个函数就相当于模块里面的方法,我们在调用模块在加方法就能直接运行函数得到结果。
那么import是怎么把我写的module给调用执行的了,首先,import module的时候,import会去路径下找文件名相符的文件,然后把文件里面的内容一行一行的读取到内存中(专属的命名空间),这个专属命名就是module,专属命名空间就是以module命名的内存空间,最后我们要去执行module.kk的时候就是执行了事先读取到module命名空间里面的代码。
还有就是这个module命名空间里面的代码即使和当前调用module文件里面的代码有重名的,也不会受到影响,因为module这个空间是和其它内存空间是隔离的,不会因其它空间有相同的名字受到影响。
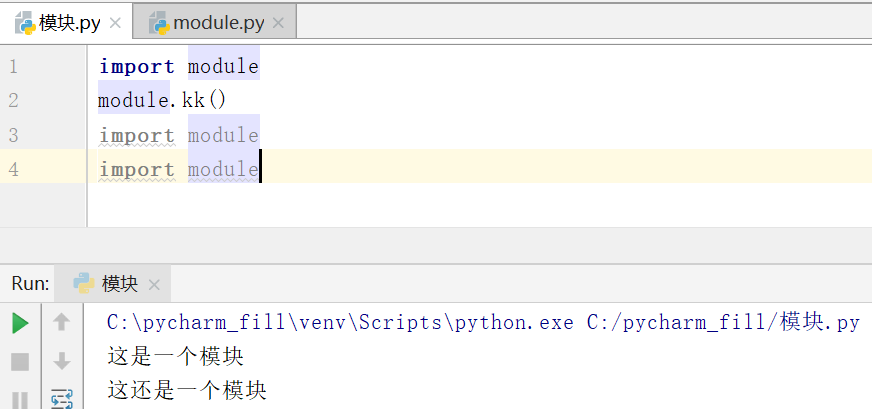
我在一个文件import了module三次,结果发现执行的时候就执行了一次,这个是因为我们在import的时候python会去执行python解释器交互模块sys,然后使用sys里面的sys.modules.keys()方法,这个方法会去检查我导入的module模块是不是已经存在了,存在了就不会重复导入了,如果module不在sys.modules.keys()方法检查检查的结果里面,就会用到sys.path方法去找路径这个模块对应的文件。
在后面import一个自己写的模块的时候,发现导入不成功,解决的思路就应该看看sys.modules.keys()和sys.path出来的结果。
B:模块起别名
给模块起别名的方法很简单,只要在导入模块之后加上一个as,后面在指定别名即可。
import module as mm mm.kk() #执行结果 这是一个模块 这还是一个模块 通过导入模块的时候后面加上as,再加上给模块起的别名,就能完成正常模块所有功能
为什么要给模块起别名,假如我写了两个模块,两个模块都是打开文件,但是一个是专门处理jpg格式的文件,一个是处理png格式的文件,那么这两个模块的基础部分代码都是相同的,都是要取open文件,之后我在其它代码里面import这两个模块的时候,发现我处理的文件夹下面既有jpg格式的文件又有png格式的文件,我就需要在代码里面写jpg.open_flie和png.open_file方法,这样就会出现我能不能只关心open_file文件就行,不需要每次都去指定我是要那种格式的方法,这个时候别名就能完成这种事情,我在代码里面加上判断,不管是那种格式的文件都可以用一个方法给打开。
word='import word' if word==word: import word as file else: import execl as file file.open_file() #执行结果 #这是一个word模块 if word!=word: import word as file else: import execl as file file.open_file() # 执行结果: # 这是一个execl模块
上面只是一种常见的场景介绍,实际情况下,你可能需要和很多文件打交道,别名就能很好的简化你的代码,相当于做了一个兼容的功能,当然记得对你的代码加注释,保证其他人也能看懂。
注意,只要给模块起了别名,模块原本的名字就不可用了。
C:多模块同时导入和模块导入规则
import time import sys import random 在正常情况下我们导入模块都是一个个导入的 import time,sys,random 其实也可以逗号把模块分开,在一行就能导入
模块能在一行同时导入,但是不建议写一行,入股是导入了20个模块,你都写在一行,这样后续代码改起来必然会增加工作量,所以在一行导入模块的时候要保证模块少,且模块都属于一个类型的,这里的类型是指内置模块和扩展模块。在导入模块的时候,也是有规则的,就是先导入内置的,在导入扩展的,最后才是自定义。
D:from 模块 import 方法
from time import sleep sleep(1) 使用from的模块导入方法就能直接使用到模块里面的方法
使用from之后导入的模块方法,本地的代码是不能出现和模块方法同名的代码块方法,这样你导入的模块的方法是不会生效的。
当一个模块方法很多,我也要用到这个里面的很多方法,就可以使用from 模块 import * ,这样就可以一下导入所有的方法。
from time import * sleep=10 sleep(1) 执行结果 TypeError: 'int' object is not callable 会发现执行报错了
from 模块 import *固然好用,但是不太安全,当出现变量名和方法名一致的,模块方法就会失灵了,而且一下导入所有方法,如果是用不上,也会占用一些不必要的空间,所以是用到哪些方法就import哪些方法。
但是有时候我们写代码,不会有那么多时间去规划我代码里面要用到模块里面的那些方法,这个时候import *显然更加便捷,但同时我们又说了import *方法不安全,能不能有一种方法先可以import *进来,然后我在边写边指定用到那些方法,下面我们说到就是__all__方法。
__all__=['time'] #下面strptime方法报错是因为__all__方法导致的,__all__=[]格式,必须是__all__=后面是列表, # 列表里面必须是字符串,这个字符串必须是以存在的方法名 from time import * print(time()) #执行结果 1541558971.905012 #执行结果 #TypeError: _strptime_time() missing 1 required positional argument: 'data_string' #strptime是属于time模块的,上面也import *号,但是还是有报错
这样我们就可以通过__all__每次去指定我要使用模块的那些方法,但是要记住__all__只能对import *后面这个*号做约束。
E:模块执行隔离
在实际的开发场景中,多人协同开发一个功能的时候,都会定下一些共用的基础代码,这些代码会被不同的人所有使用,那么自然而然你的代码就需要迭代优化,那么最好的情况下就是不中断同事的开发进度的基础上进行代码的优化,那么这个就需要使用代码隔离操作。
def open_file(): print('这是一个word模块') print(__name__) #执行结果 __main__#这个结果必须是在有__name__的代码里面执行才能得到main,这样我们就可以控制其它代码调用本函数的时候是否能正常执行 if(__name__) != '__main__': def open_file(): #如果name=main了就执行函数 print('这是一个word模块') else: #否则我就执行其它的内容 print('log')
通过__name__就可以把一些事先准备好的函数给隔离开,避免其它代码import的时候出现问题调试的时候代码会被其它代码给执行掉。
♣八:包的进阶
A:包的基础介绍
什么是包,包就是把一堆模块放在一起的集合就叫做包,可以想象包就是一个工具箱,只要拿到这个工具箱,就可以完成相应的事情。
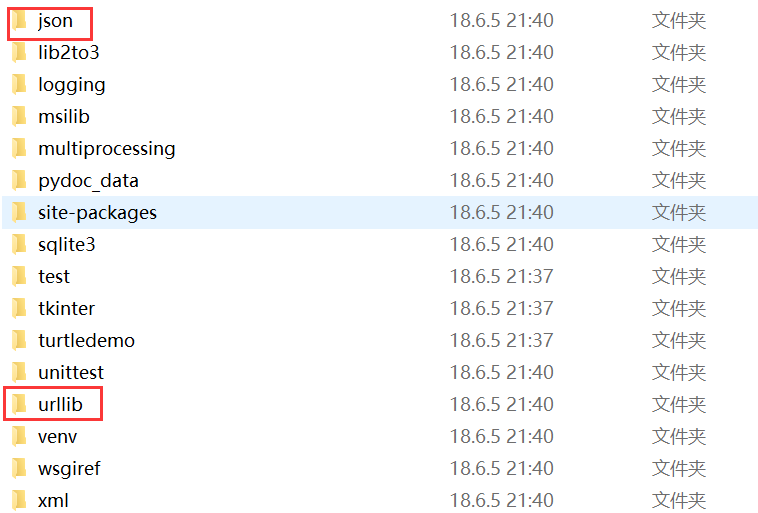
我们进入python的安装目录下到lib目录下我们就可以看到之前我们学习过的很多模块名字的文件夹,其实包在pyhton里面的含义就是吧解决通一类问题的模块放在一个文件夹下面,那么这个文件夹就是包。
这个文件夹里面的文件我们通过一个个打开之后发现一个相同的文件就是__init__.py的文件,在python里面只有含有__init__.py文件才能算做包。而且这边__init__文件在python2里面是必须有的,不然就会有问题,但在python3里面如果没有也是可以用的。
B:包的基础使用
在包的导入方法里面必须遵循:凡是导入带点的,点的左边必须是一个包,而且如果是多层级的包,需要每层递归。
import txt.api.abc as api api.get() #txt是最外面的包 #api是txt里面的包 #abc是代码文件 #get是代码里面方法 #abc.py里面的代码 #def get(): # print('from abc.py') #执行结果 from abc.py
C:包的绝对导入和相对导入
导入之后就没有限制了,点的左边可以是包,函数,模块,类等,但是得满足上的条件。
from txt.api import abc abc.get() #from txt import api.abc 错误的from方法,前面是from后面是import,后面这个import就不能再带点 from txt.api.abc import get get() #txt是最外面的包 #api是txt里面的包 #abc是代码文件 #get是代码里面方法 #abc.py里面的代码 #def get(): # print('from abc.py') #执行结果 from abc.py from abc.py
通过上面的例子,我们也可以看到,无论是import还是from,你必须先从最外的一层目录开始,不能直接跳过最外面的目录import或者from第二次目录的,这个其实就和之前说的sys.path有关,你在import的时候都是先去看目录下有没有这个文件,从最简单的理论上来说,文件要执行必须从1到2再到3,不能直接从2到3,如果你非要import和from第二层目录,可以在sys.path里面指定好。
还是上面路径的问题,包的根本执行方式其实还是最简单的路径去检索方法而已,我们上面执行都是在一行执行import xxx.xxx form xxx这样的形势,如果是换了目录执行方式是import就导入包的第一层目录,这个时候肯定会报错,所以我们要对代码进行优化,保证兼容性性问题。
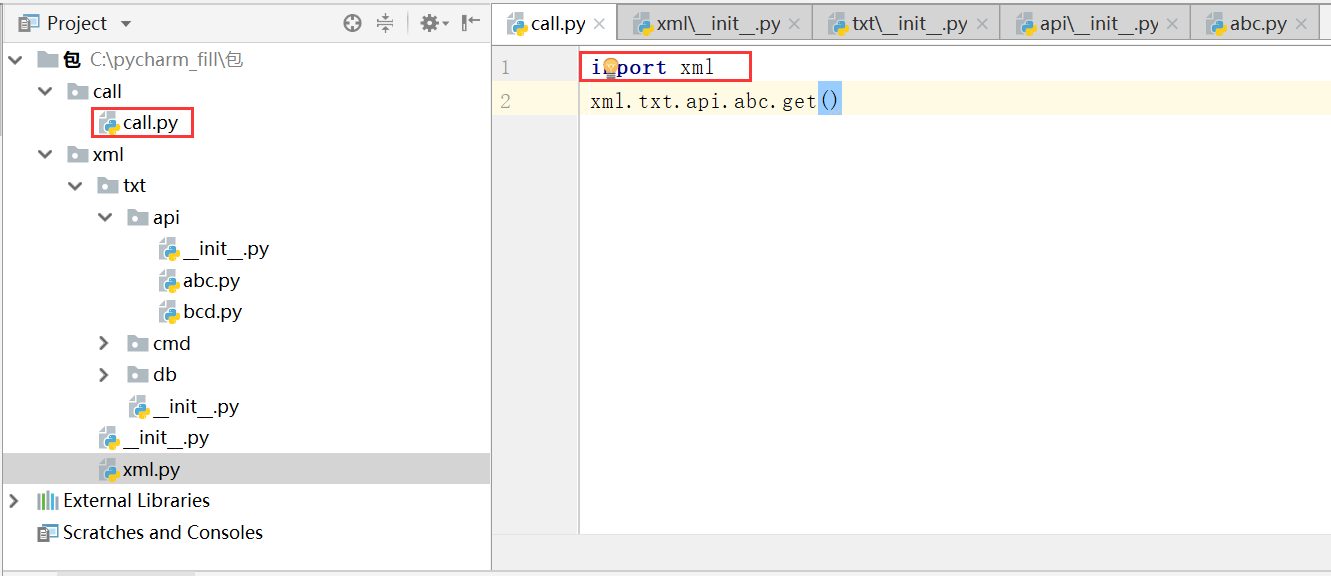
例如上图的结构,我在外面导入包的最外层目录,在第二行包里面的方法,这个时候我们需要在每一层的init文件里面import包里面下一层目录,一层层递归的import。
xml文件下的init文件 from xml import txt txt文件下的init文件 from xml.txt import api api文件下的init文件 from xml.txt.api import abc 通过每一层目录的导入,层层递归 import xml xml.txt.api.abc.get() 执行结果 from abc.py 在外面import的时候就不会有报错了,兼容性更强
我们在使用linux的时候会经常使用cd ..返回上一层目录的操作,在python里面其实也是一样的,一个点代表当前目录,两个点代表上一层目录。
xml文件下的init文件 from . import txt txt文件下的init文件 from . import api api文件下的init文件 from . import abc 我们把之前需要层层写明的目录结构改成点,也是可以执行的。 import xml xml.txt.api.abc.get() 执行结果 from abc.py 在外面import的时候就不会有报错了,兼容性更强
这个优化还有一个好处,就是当我的xml目录调整路径了,我也不用担心我xml里面没一个init需要随之改变目录结构,我只需要在更改的目录下加上新路径就行了,例如from call import xml,等于说无论我xml整个路径放在哪个路径下,我都不用关心xml里面的调用,我只需要关心外面的调用路径是否正确,当然这个调整也存在一个弊端,如果你在xml里面调用xml路径下的方法就有问题了。
在版本2我们看见了可以使用点代表目录,其实我们之前学到的__all__方法也是可以在包里面使用的,当然还是只能控制__all__是用于控制from...import *
所以绝对路径和相对路径都各自有利弊,绝对路径目录结构清晰,但是不能挪动目录所在位置,相对路径能挪动,但是不能包里面调用相同层级下其它的方法。
包在编写的时候要记住不能相互依赖,例如你写了两个包之间相互依赖这种是不行的,但是你可以在包里面依赖python自带的模块。
posted on 2018-12-16 16:09 ppc_server 阅读(368) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号