Redis学习
NoSql概述
为什么要用Nosql
关系型数据库:表,和列,有固定格式
非关系型数据库:不需要固定格式,比如存储地理位置,网络信息等等
最经典的代表就是Java中的Map<String,Object>,可以存储各种类型的参数
具体可以看看这个:为什么要使用nosql
Nosql的四大分类


Redis入门
概述
Redis是什么?
Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器
Redis能干什么

Redis的特性

windows安装
官网下载或github官网下载
解压即用
Linux安装
步骤
-
官网下载最新版本redis-6.2.6.tar.gz
-
使用xftp将文件转移到linux的/home/mySoftPacket(记住自己放哪了)
-
解压到/opt/目录下,在/home/mySoftPacket目录使用该命令。
tar -zxvf redis-6.2.6.tar.gz -C /opt/-C表示解压路径,不加-C就只能解压到当前目录
-
环境安装
#在/opt/redis-6.2.6路径下 yum install gcc-c++ #安装c++环境,redis是c++编写的 make #管理员用它通过命令行来编译和安装很多开源的工具 make install #把src目录下的几个二进制文件复制到了系统的/usr/local/bin下面1)关于yum install gcc-c++,可能会爆出一个"is this ok y/d/n"
说明:y表示下载安装,d表示下载不安装,n表示不下载
2)make命令完毕,/opt/redis-6.2.6会多出一个src目录(下图不一致是因为后来我将redis-6.2.6移动到了/opt)

3)make install好像可以省略,不太懂,上面注释是我查的,
-
redis的默认安装路径 /usr/local/bin
![]()
-
在 /usr/local/bin/目录下创建一个文件夹myconfig,将redis.conf文件copy到该目录
![]()
-
修改/usr/local/bin/myconfig下的配置文件redis.conf,修改成后台自动启动,以后无需自己启动
![]()
-
启动server服务
![]()
![]()
-
测试redis
![]()
-
查看redis进程
![]()
-
退出redis服务







此时再查看进程状态

redis性能测试工具

redis-benchmark可选参数
| 1 | -h | 指定服务器主机名 | 127.0.0.1 |
|---|---|---|---|
| 2 | -p | 指定服务器端口 | 6379 |
| 3 | -s | 指定服务器 socket | |
| 4 | -c | 指定并发连接数 | 50 |
| 5 | -n | 指定请求数 | 10000 |
| 6 | -d | 以字节的形式指定 SET/GET 值的数据大小 | 2 |
| 7 | -k | 1=keep alive 0=reconnect | 1 |
| 8 | -r | SET/GET/INCR 使用随机 key, SADD 使用随机值 | |
| 9 | -P | 通过管道传输 |
1 |
| 10 | -q | 强制退出 redis。仅显示 query/sec 值 | |
| 11 | --csv | 以 CSV 格式输出 | |
| 12 | *-l*(L 的小写字母) | 生成循环,永久执行测试 | |
| 13 | -t | 仅运行以逗号分隔的测试命令列表。 | |
| 14 | *-I*(i 的大写字母) | Idle 模式。仅打开 N 个 idle 连接并等待。 |
基础知识
redis有16个数据库
查看redis.conf文件验证

切换数据库
select 0~15

查看数据库容量
dbsize
查看数据库的键数量
keys *
清空数据库
flushdb 清空当前数据库
flushall 清空全部16个数据库
奇怪的知识:为什么redis的默认端口是6379?
粉丝效应:6379是一个女星的名字在按键上的对应数字,创始人好像是她的粉丝~~,他不经意地按下了她的名字,于是6379便成了默认端口
Redis是单线程的!
Redis很快,但实际上它并不是多线程的。redis将数据存储在内存中
多线程导致慢的因素:切换cpu上下文需要消耗时间!
而单线程不需要cpu上下文切换
cpu上下文:程序计数器
CPU 上下文切换,就是先把前一个任务的 CPU 上下文(也就是 CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
五大数据类型
官网文档:
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
Redis-key
设置过期时间
expire key seconds
查看存活时间ttl(time to live)
ttl key
值为-2表示已过期
移动键值到其他数据库
move key 数据库编号(0~15) #移动以后原来数据库的键就不存在了

删除键值 del key
del key
127.0.0.1:6379> flushall
OK
127.0.0.1:6379> set name yfm
OK
127.0.0.1:6379> set age 18
OK
127.0.0.1:6379> del age
(integer) 1
127.0.0.1:6379> get age
(nil)
127.0.0.1:6379>
判断是否存在exists
exists key #判断当前key是否存在,1存在 0不存在

查看键的值类型type
type key
127.0.0.1:6379[1]> get name
"yfm"
127.0.0.1:6379[1]> type name
string
String
字符串添加append
字符串长度strlen
127.0.0.1:6379> FLUSHDB
OK
127.0.0.1:6379> append name yfm #追加字符串,若键不存在则新建
(integer) 3
127.0.0.1:6379> append name ,hello
(integer) 9
127.0.0.1:6379> strlen name #返回键的值的长度
(integer) 9
127.0.0.1:6379> get name
"yfm,hello"
127.0.0.1:6379>
加1 incr key,减1 decr key
127.0.0.1:6379> set age 0
OK
127.0.0.1:6379> incr age #加1
(integer) 1
127.0.0.1:6379> incr age
(integer) 2
127.0.0.1:6379> incr age
(integer) 3
127.0.0.1:6379> get age
"3"
127.0.0.1:6379> decr age #减1
(integer) 2
127.0.0.1:6379> decr age
(integer) 1
127.0.0.1:6379> decr age
(integer) 0
127.0.0.1:6379>
按步长加 incrby key number,按步长减 decrby key number
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> set age 0
OK
127.0.0.1:6379> incrby age 10 #指定步长加10
(integer) 10
127.0.0.1:6379> get age
"10"
127.0.0.1:6379> decrby age 10 #指定步长减10
(integer) 0
127.0.0.1:6379> get age
"0"
字符串截取 getrange ,字符串替换 setrange
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> set slogen "i am watching the kuang vedio!"
OK
127.0.0.1:6379> GETRANGE slogen 0 3 #获取索引从0~3的子字符串,[0,3];
"i am"
127.0.0.1:6379> SETRANGE slogen 0 "he's" #用"he's"替换slogen从0索引开始的子串
(integer) 30
127.0.0.1:6379> get slogen
"he's watching the kuang vedio!"
127.0.0.1:6379>
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> set name hello,yfm
OK
127.0.0.1:6379> GETRANGE name 2 -1 # 如果要获取从某个位置开始的所有字符串,end索引是-1
"llo,yfm"
批量设置键值 mset,批量获取键值 mget
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> mset age 18 name yfm
OK
127.0.0.1:6379> keys *
1) "age"
2) "name"
127.0.0.1:6379> mget age name
1) "18"
2) "yfm"
127.0.0.1:6379>
设置的同时设置过期时间 setex,不存在则设置 setnx(set not exists)
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> SETEX name 30 yfm # setex key seconds value
OK
127.0.0.1:6379> ttl name
(integer) 25
127.0.0.1:6379> ttl name
(integer) 22
127.0.0.1:6379> get name
"yfm"
127.0.0.1:6379> ttl name
(integer) 3
127.0.0.1:6379> keys *
(empty array)
127.0.0.1:6379>
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> setnx name yfm #不存在指定键的时候创建
(integer) 1
127.0.0.1:6379> setnx name abc #存在也不修改值
(integer) 0
127.0.0.1:6379> get name
"yfm"
127.0.0.1:6379>
批量 不存在则设置msetnx (原子性操作,要么同时成功,要么同时失败)
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> set name yfm
OK
127.0.0.1:6379> MSETNX age 18 sex male
(integer) 1
127.0.0.1:6379> MSETNX name yfm1 hobby singing
(integer) 0
127.0.0.1:6379> keys * #这里没有hobby
1) "age"
2) "sex"
3) "name"
127.0.0.1:6379> mget age sex name
1) "18"
2) "male"
3) "yfm"
127.0.0.1:6379>
设置对象 ,实际就是也就是一种格式罢了
-
set user:1
-
msetnx user:1:name yfm user:1:age 18 user:1:sex male
msetnx user=2=name yfm1 user=2=age 19 user=2=sex male
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> set user:1 {name:yfm,age:18,sex:male}
OK
127.0.0.1:6379> mget user:1
1) "{name:yfm,age:18,sex:male}"
127.0.0.1:6379> mget user:1:name user:1:age user:1:sex
1) (nil)
2) (nil)
3) (nil)
===============================================================
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> msetnx user:1:name yfm user:1:age 18 user:1:sex male
(integer) 1
127.0.0.1:6379> mget user:1:name user:1:age user:1:sex
1) "yfm"
2) "18"
3) "male"
127.0.0.1:6379> msetnx user=2=name yfm1 user=2=age 19 user=2=sex male
(integer) 1
127.0.0.1:6379> mget user=2=name user=2=age user=2=sex
1) "yfm1"
2) "19"
3) "male"
127.0.0.1:6379> keys * # 这可以看出,所谓对象只是我们设置的一种格式,本质还是key value
1) "user:1:sex"
2) "user=2=age"
3) "user:1:name"
4) "user=2=name"
5) "user:1:age"
6) "user=2=sex"
127.0.0.1:6379>
组合命令,获取原来的值再设置新值 getset
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> getset name yfm #键不存在返回空
(nil)
127.0.0.1:6379> getset name yfm1
"yfm"
127.0.0.1:6379> get name
"yfm1"
127.0.0.1:6379>
List(列表)
Lpush左边进队,
Rpush 右边进队
Lrange 从左边一个一个把值取出
可以把List想象成一个队列,Lpush就是从左边一个一个入对,Rpush就是从右边一个一个入队。而 Lrange是从左边一个一个取值(left range)
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> lpush list1 l1 l2 l3
(integer) 3
127.0.0.1:6379> LRANGE list1 0 -1
1) "l3"
2) "l2"
3) "l1"
# 上面一次性入队多个值,和下面一个一个入队等价
127.0.0.1:6379> lpush list2 l1
(integer) 1
127.0.0.1:6379> lpush list2 l2
(integer) 2
127.0.0.1:6379> lpush list2 l3
(integer) 3
127.0.0.1:6379> LRANGE list2 0 -1
1) "l3"
2) "l2"
3) "l1"
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> rpush list1 l1 l2 l3 #从右边一个一个进队
(integer) 3
127.0.0.1:6379> LRANGE list1 0 -1 #从左边一个一个出队。先进先出
1) "l1"
2) "l2"
3) "l3"
127.0.0.1:6379>
Lpop 左边出队 ,
Rpop 右边出队
127.0.0.1:6379> FLUSHDB
OK
127.0.0.1:6379> rpush list1 l1 l2 l3 # list1 :l1 l2 l3
(integer) 3
127.0.0.1:6379> rpop list1
"l3"
127.0.0.1:6379> lpop list1
"l1"
127.0.0.1:6379> lpush list2 l1 l2 l3 # list2 :l3 l2 l1
(integer) 3
127.0.0.1:6379> rpop list2
"l1"
127.0.0.1:6379> lpop list2
"l3"
Llen 返回List的长度
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> rpush list1 l1 l2 l3
(integer) 3
127.0.0.1:6379> LLEN list1
(integer) 3
127.0.0.1:6379> rpush list1 l4
(integer) 4
127.0.0.1:6379> LLEN list1
(integer) 4
127.0.0.1:6379>
Lindex 从左边开始算起,返回指定List的指定索引的值
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> rpush list1 l1 l2 l3
(integer) 3
127.0.0.1:6379> rpush list1 l4
(integer) 4
127.0.0.1:6379> LINDEX list1 1
"l2"
127.0.0.1:6379> LINDEX list1 0
"l1"
Lrem 从存于 key 的列表里移除前 count 次出现的值为 value 的元素。 这个 count 参数通过下面几种方式影响这个操作:
- count > 0: 从头往尾移除值为 value 的元素。
- count < 0: 从尾往头移除值为 value 的元素。
- count = 0: 移除所有值为 value 的元素。
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> rpush list l1 l l2 l l3 l l4
(integer) 7
127.0.0.1:6379> LREM list -2 l # 右起
(integer) 2
127.0.0.1:6379> LRANGE list 0 -1
1) "l1"
2) "l"
3) "l2"
4) "l3"
5) "l4"
127.0.0.1:6379>
遇到不懂的,直接搜redis官网查看API
Lset 给指定List的指定 索引 设置新值;不存在指定List或指定索引会报错
127.0.0.1:6379> lrange list1 0 -1
1) "l1"
2) "l2"
127.0.0.1:6379> LSET list1 1 new
OK
127.0.0.1:6379> LRANGE list1 0 -1
1) "l1"
2) "new"
127.0.0.1:6379>
Ltrim list start stop 左起 把索引从[start,top]的元素修剪出来,其余的放弃
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> rpush list1 l1 l2 l3 l4
(integer) 4
127.0.0.1:6379> LTRIM list1 0 1
OK
127.0.0.1:6379> lrange list1 0 -1
1) "l1"
2) "l2"
rpoplpush 组合操作:从一个List1中pop元素,push到另一个List2中
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> rpush list1 l1 l2 l3 l4 l5
(integer) 5
127.0.0.1:6379> RPOPLPUSH list1 list2 # 将list1的l5导出,再导入list2中
"l5"
127.0.0.1:6379> LRANGE list1 0 -1
1) "l1"
2) "l2"
3) "l3"
4) "l4"
127.0.0.1:6379> LRANGE list2 0 -1
1) "l5"
127.0.0.1:6379>
Linsert:(左边是前,右边是后)插入新元素到List的具体元素的前面或后面
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> rpush list1 l1 l2 l3
(integer) 3
127.0.0.1:6379> LINSERT list1 before l2 l1.9
(integer) 4
127.0.0.1:6379> LINSERT list1 after l2 l2.5
(integer) 5
127.0.0.1:6379> LRANGE list1 0 -1
1) "l1"
2) "l1.9"
3) "l2"
4) "l2.5"
5) "l3"
127.0.0.1:6379>
Set(集合)
set 是无序不重复集合
命令都是s开头,表示set
sadd 添加,创建set
smembers 输出指定set所有元素
scard 查看set有多少个元素
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> sadd set1 hello world hello,yfm #添加三个元素
(integer) 3
127.0.0.1:6379> scard set1 #输出set1的元素数
(integer) 3
127.0.0.1:6379> SMEMBERS set1 #输出set1所有元素
1) "world"
2) "hello"
3) "hello,yfm"
srandmember 随机输出一个数
srem 删除指定的元素
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> sadd set1 s1 s2 s3 s4 s5
(integer) 5
127.0.0.1:6379> SRANDMEMBER set1
"s3"
127.0.0.1:6379> SRANDMEMBER set1
"s3"
127.0.0.1:6379> SRANDMEMBER set1
"s1"
127.0.0.1:6379> srem set1 s2 s3 #删除s2,s3两个元素
(integer) 2
127.0.0.1:6379> SMEMBERS set1
1) "s4"
2) "s5"
3) "s1"
127.0.0.1:6379>
sdiff 差集
sunion并集
sinter 交集
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> sadd s1 1 2 3
(integer) 3
127.0.0.1:6379> sadd s2 3 4 5
(integer) 3
127.0.0.1:6379> SDIFF s1 s2 # 差集:s1减去 s1和s2的交集
1) "1"
2) "2"
127.0.0.1:6379> SUNION s1 s2 # 并集
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
127.0.0.1:6379> SINTER s1 s2 # 交集
1) "3"
127.0.0.1:6379>
smove 移动集合里面的一个元素到另一个集合
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> sadd s1 1 2 3
(integer) 3
127.0.0.1:6379> SMOVE s1 s2 1 # 把s1中的1移动到s2
(integer) 1
127.0.0.1:6379> SMEMBERS s1
1) "2"
2) "3"
127.0.0.1:6379> SMEMBERS s2
1) "1"
127.0.0.1:6379>
spop key [count] 删除并获取一个集合里面的元素 随机删除元素
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> sadd s1 1 2 3 4 5
(integer) 5
127.0.0.1:6379> SPOP s1
"5"
127.0.0.1:6379> SPOP s1
"4"
127.0.0.1:6379> SPOP s1
"1"
127.0.0.1:6379> SMEMBERS s1
1) "2"
2) "3"
127.0.0.1:6379>
Hash(哈希)
可以看作是Map集合:key-
map也无序
本质上也是字符串String,不过多了一层key
hset 增 改
hmset 增 (和hset差不多,两者都可以设置多个键值)
hsetnx 增 不存在则设置 (一次只能设置一个键)
hget 查 一次只能获取一个键的值
hmget 查 (可以一次性获取多个键的值)
hgetall 查所有
hdel 删
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> hset user1 name yfm age 18 # 增 改
(integer) 2
127.0.0.1:6379> hget user1 name # 查
"yfm"
127.0.0.1:6379> hget user1 age
"18"
127.0.0.1:6379> HGETALL user1 # 查
1) "name"
2) "yfm"
3) "age"
4) "18"
127.0.0.1:6379> HMSET user1 qq 123 email 123@qq.com # 增
OK
127.0.0.1:6379> HGETALL user1
1) "name"
2) "yfm"
3) "age"
4) "18"
5) "qq"
6) "123"
7) "email"
8) "123@qq.com"
127.0.0.1:6379> HDEL user1 qq email #删
(integer) 2
127.0.0.1:6379> HGETALL user1
1) "name"
2) "yfm"
3) "age"
4) "18"
127.0.0.1:6379>
======================================================
hset #专门测修改
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> hset user name yfm age 18
(integer) 2
127.0.0.1:6379> hset user age 19
(integer) 0
127.0.0.1:6379> hget user age
"19"
127.0.0.1:6379> hgetall user
1) "name"
2) "yfm"
3) "age"
4) "19"
127.0.0.1:6379> hset user name newyfm
(integer) 0
127.0.0.1:6379> hget user name
"newyfm"
127.0.0.1:6379>
hlen 输出Hash的长度(多少个键)
hkeys 返回Hash的所有键
hvals 返回所有键的值
hexists 判断Hash指定键是否存在
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> hset user name yfm age 18 email 123@qq.com
(integer) 3
127.0.0.1:6379> hlen user
(integer) 3
127.0.0.1:6379> hkeys user
1) "name"
2) "age"
3) "email"
127.0.0.1:6379> hvals user
1) "yfm"
2) "18"
3) "123@qq.com"
127.0.0.1:6379> hexists user name
(integer) 1
127.0.0.1:6379>
incrby 自增
127.0.0.1:6379> FLUSHDB
OK
127.0.0.1:6379> hset user age 1
(integer) 1
127.0.0.1:6379> HINCRBY user age 10
(integer) 11
127.0.0.1:6379> HINCRBY user age 5
(integer) 16
127.0.0.1:6379> HINCRBY user age -6
(integer) 10
用Hash存储对象比String更合适:如果使用String,那我们就需要自己设计一种容易阅读的格式,但也会造成书写的麻烦,比如set user:1:name yfm ,用户1的名字是yfm
而Hash的话就简单一些,hset user1 name yfm 。
呃呃呃,比较完感觉不到什么差异,也就少了几个:号......
Zset(有序集合)
Zset和set比较:
Zset在添加值时会多添加一个字段score,然后通过score来实现有序
zadd
zrange 按score升序输出元素列表
zrevrange 按score降序输出元素列表
zrem 删除指定元素
zcard 输出zset的长度
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> zadd salary 5000 xiaoming 2500 xiaohong 5500 yfm
(integer) 3
127.0.0.1:6379> zcard salary #输出zset的长度
(integer) 3
127.0.0.1:6379> ZRANGE salary 0 -1 #按score升序输出元素列表
1) "xiaohong"
2) "xiaoming"
3) "yfm"
127.0.0.1:6379> ZREVRANGE salary 0 -1 #按score降序输出元素列表
1) "yfm"
2) "xiaoming"
3) "xiaohong"
127.0.0.1:6379> zrem salary yfm #删除zset指定的元素
(integer) 1
127.0.0.1:6379> zcard salary
(integer) 2
127.0.0.1:6379>
ZRANGEBYSCORE 按score升序输出元素
zcount 输出score符合指定区间的元素个数
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> zadd salary 650 xm 600 xh 1000 yfm
(integer) 3
#zrangebyscore key min max
127.0.0.1:6379> ZRANGEBYSCORE salary -inf +inf withscores
1) "xh"
2) "600"
3) "xm"
4) "650"
5) "yfm"
6) "1000"
127.0.0.1:6379> zcount salary 0 -1
(integer) 0
127.0.0.1:6379> zcount salary 600 1000 # [600,1000]
(integer) 3
127.0.0.1:6379> zcount salary 0 700
(integer) 2
127.0.0.1:6379>
三大特殊数据类型
geospatial 地理位置
- GeoAdd
- GeoDIst
- GeoRadius
- GeoRadiusByMember
- GeoHash
Geo的使用场景:微信附近的人,打车定位距离
将指定的地理空间位置(经度、纬度、名称)添加到指定的key中。这些数据将会存储到sorted set(Zset)这样的目的是为了方便使用GEORADIUS或者GEORADIUSBYMEMBER命令对数据进行半径查询等操作。
一般来说,都是软件自动导入我们需要的所有地点,而不是像现在一个一个输入
#经纬度的值应该有具体范围,根据具体情况来
127.0.0.1:6379> GEOADD china.city 121.48 31.22 shanghai
(integer) 1
127.0.0.1:6379> GEOADD china.city 113 28.21 changsha
(integer) 1
127.0.0.1:6379> GEOADD china.city 116.46 39.92 beijing
(integer) 1
127.0.0.1:6379> GEOADD china.city 106.54 29.59 chongqing 114.31 30.52 wuhan
(integer) 2
127.0.0.1:6379> ZRANGE china.city 0 -1 #geo 本质上就是Zset,可以使用Zset命令来操作geo数据
1) "chongqing"
2) "changsha"
3) "wuhan"
4) "shanghai"
5) "beijing"
127.0.0.1:6379>
GEODIST 输出两个地方的直线距离
127.0.0.1:6379> GEODIST china.city beijing shanghai km #输出北京到武汉的直线距离,单位km
"1068.4581"
127.0.0.1:6379> GEODIST china.city changsha wuhan km
"286.5926"
127.0.0.1:6379>
GEOPOS 输出指定地点的经纬度
127.0.0.1:6379> GEOPOS china.city chongqing shanghai
1) 1) "106.54000014066696167"
2) "29.58999896356930748"
2) 1) "121.48000091314315796"
2) "31.21999956478423854"
127.0.0.1:6379>
GEORADIUS 搜索指定经纬度,指定范围内的其他地方
这可以用于实现 微信 找附近的人
withdist 输出地点,把距离一起输出
withcoord 输出地点,把地点的经纬度一起输出 (经纬度和地点等价)
count number 限制输出个数。如附件的人可能有上万个,但手机上看到的不过数百个
127.0.0.1:6379> GEORADIUS china.city 100 25 1000 km withdist
1) 1) "chongqing"
2) "823.4134"
127.0.0.1:6379> GEORADIUS china.city 106.6 30 100 km withcoord
1) 1) "chongqing"
2) 1) "106.54000014066696167"
2) "29.58999896356930748"
# 限制个数 count n
127.0.0.1:6379> GEORADIUS china.city 106.6 30 10000 km
1) "chongqing"
2) "changsha"
3) "wuhan"
4) "shanghai"
5) "beijing"
127.0.0.1:6379> GEORADIUS china.city 106.6 30 10000 km count 3
1) "chongqing"
2) "changsha"
3) "wuhan"
127.0.0.1:6379>
GEORADIUSBYMEMBER 输出 指定地点,指定范围内的其他地点
127.0.0.1:6379> GEORADIUSBYMEMBER china.city shanghai 1000 km
1) "changsha"
2) "wuhan"
3) "shanghai"
127.0.0.1:6379> GEORADIUSBYMEMBER china.city shanghai 1 km
1) "shanghai"
127.0.0.1:6379>
GEOHASH 返回一个或多个位置元素的 Geohash 表示
该命令将返回11个字符的Geohash字符串,所以没有精度Geohash,损失相比,使用内部52位表示。越相近就代表经纬度值越接近
127.0.0.1:6379> GEOHASH china.city shanghai chongqing
1) "wtw3s77j9j0"
2) "wm7b26sn1z0"
127.0.0.1:6379> GEOHASH china.city shanghai chongqing beijing
1) "wtw3s77j9j0"
2) "wm7b26sn1z0"
3) "wx4g455wfe0"
127.0.0.1:6379>
Geo实际上就是Zset(数据存储为Zset),所有我们可以使用Zset对Geo数据进行删查
Hyper Loglog
基数:不重复的元素
Hyper lolog是一种基数统计的数据结构
网页中经常会统计用户访问量
传统:使用set集合储存用户id,但id通常是一些uuid之类的较长,存储较费空间。
Hper loglog:2^64个不同元素,只占12KB内存,但会有0.81%的错误率
所以:
如果可以承受错误,我们就可以选择Hyoer loglog计算基数;不能的话,我们才使用set或其他自定义数据类型
pfadd 添加/创建 数据集
pfcount 返回数据集的不重复元素个数
pfmerge 合并多个数据集的不重复元素到新数据集
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> clear
127.0.0.1:6379> PFADD myset 1 2 3 3 4 5 5 6 7
(integer) 1
127.0.0.1:6379> PFCOUNT myset
(integer) 7
127.0.0.1:6379> pfadd newset 6 7 8 9 0
(integer) 1
127.0.0.1:6379> PFCOUNT newset
(integer) 5
127.0.0.1:6379> PFMERGE totalset newset myset
OK
127.0.0.1:6379> PFCOUNT totalset
(integer) 10
127.0.0.1:6379>
BitMap 位图
位存储,适用于存储只有两种情况的数据,要么为0,要么为1
比如说:2020年爆发疫情,中国总共有10多亿人。要存储10亿人的得病情况,只需要将健康的人设置为0,得病的人设为1即可。
又比如说:日常生活中的考勤打卡,365天,打了卡当天就设为1,否则设为0。这样,记录一个人365的打卡情况,一天1bit,8天1B,大约需要46B就可以了。
setbit 设置或者清空key的value(字符串)在offset处的bit值
getbit 获取key指定offset的bit值
bitcount 统计bit为1的bit数
127.0.0.1:6379> FLUSHDB
OK
#setbit key offset bit, offset 和bit 只能是整数
127.0.0.1:6379> SETBIT sign 0 1 # 设置周一到周六都打了卡,周日没打卡
(integer) 0
127.0.0.1:6379> SETBIT sign 1 1
(integer) 0
127.0.0.1:6379> SETBIT sign 2 1
(integer) 0
127.0.0.1:6379> SETBIT sign 3 1
(integer) 0
127.0.0.1:6379> SETBIT sign 4 1
(integer) 0
127.0.0.1:6379> SETBIT sign 5 1
(integer) 0
127.0.0.1:6379> SETBIT sign 6 0
(integer) 0
127.0.0.1:6379> BITCOUNT sign # 获取打卡天数
(integer) 6
127.0.0.1:6379> GETBIT sign 6 # 查看周日是否打卡
(integer) 0
127.0.0.1:6379> GETBIT sign 5 # 查看周六是否打卡
(integer) 1
127.0.0.1:6379>
事务
multi 开启事务
exec 执行事务
127.0.0.1:6379> FLUSHDB
OK
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379(TX)> set name yfm
QUEUED
127.0.0.1:6379(TX)> set name newyfm
QUEUED
127.0.0.1:6379(TX)> get name
QUEUED
127.0.0.1:6379(TX)> EXEC
1) OK
2) OK
3) "newyfm"
127.0.0.1:6379>
discard 丢弃事务
执行该命令,Redis会丢弃队列中所有的命令,一条命令也不会执行
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379(TX)> set name yfm
QUEUED
127.0.0.1:6379(TX)> get name
QUEUED
127.0.0.1:6379(TX)> set age 21
QUEUED
127.0.0.1:6379(TX)> get age
QUEUED
127.0.0.1:6379(TX)> DISCARD # 抛弃事务 ,进入队列的命令一条都不执行
OK
127.0.0.1:6379> EXEC
(error) ERR EXEC without MULTI
127.0.0.1:6379> get name
(nil)
127.0.0.1:6379>
事务的特性
1、无原子性:Redis的事务不具有原子性:单个命令有原子性,多个命令不具有原子性!
当事务中有个别命令出错时,Redis会抛弃错误的命令,继续执行正确的命令
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379(TX)> set age ten # 设置age 为 ten
QUEUED
127.0.0.1:6379(TX)> set name yfm
QUEUED
127.0.0.1:6379(TX)> INCR age # age+1 ,即ten+1,执行会出错
QUEUED
127.0.0.1:6379(TX)> get name
QUEUED
127.0.0.1:6379(TX)> EXEC
1) OK
2) OK
3) (error) ERR value is not an integer or out of range
4) "yfm"
127.0.0.1:6379>
2、序列性:开启事务后,只要不执行事务,输入的命令都会被添加到"队列"中,只有开始执行,才会依照 添加顺序执行队列中的命令
异常
1、编译型异常
简单说,就是开启事务后,如果添加了错误的命令进队,那么就会立刻被Redis发现并报错,之前进队的命令及之后进队的命令都不会被执行
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> MULTI # 开启事务
OK
127.0.0.1:6379(TX)> se name
(error) ERR unknown command `se`, with args beginning with: `name`,
127.0.0.1:6379(TX)> set age 21
QUEUED
127.0.0.1:6379(TX)> set qq 123
QUEUED
127.0.0.1:6379(TX)> get age
QUEUED
127.0.0.1:6379(TX)> get qq
QUEUED
127.0.0.1:6379(TX)> exec #执行事务
(error) EXECABORT Transaction discarded because of previous errors.
127.0.0.1:6379>
2、运行时异常
拿java中的例子说,最经典的就是 byZero异常,代码不会被编译发现出问题,而是运行时出现问题。
回到Redis,实际上也就是Redis无原子性的体现,个别代码运行错误,其余正常命令仍会执行
监控:watch , Redis的乐观锁
先讲一下watch的使用
在我们开启事务前,我们使用watch给想要监视的key上锁,在开始执行事务时,Redis会拿到指定key的值,在对key值进行修改时,Redis会不断和事务中的key的值进行比较,若发现值变化异常,事务中所有命令都会失效
watch实例
# 先是没毛病的案例
127.0.0.1:6379> FLUSHDB
OK
127.0.0.1:6379> set money 100
OK
127.0.0.1:6379> set expense 0
OK
127.0.0.1:6379> watch money # 监控money
OK
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379(TX)> DECRBY money 20
QUEUED
127.0.0.1:6379(TX)> INCRBY expense 20
QUEUED
127.0.0.1:6379(TX)> EXEC
1) (integer) 80
2) (integer) 20
127.0.0.1:6379>
# 这是有毛病的案例
# 注意:这里会开两个终端
# 一、第一个终端代码
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> set money 100
OK
127.0.0.1:6379> set expense 0
OK
127.0.0.1:6379> watch money
OK
127.0.0.1:6379> MULTI #开启事务
OK
127.0.0.1:6379(TX)> DECRBY money 25
QUEUED
127.0.0.1:6379(TX)> INCRBY expense 25
QUEUED
127.0.0.1:6379(TX)> get money
QUEUED
127.0.0.1:6379(TX)> get expense
QUEUED
#二、第二个终端
127.0.0.1:6379> set money 1000 #突然改变money的值
OK
127.0.0.1:6379>
#三、回到第一个终端
127.0.0.1:6379(TX)> exec #watch生效
(nil)
127.0.0.1:6379>
监控生效后如何解决:unwatch
127.0.0.1:6379> UNWATCH
OK
很简单,先放弃原来的那个锁,也就是解锁
然后再次watch,获得最新的锁,再次进行操作即可
Jedis
Jedis是Redis官方推荐使用的Java连接开发工具,是使用Java操作Redis的中间件
测试
-
创建maven项目,导入jar包
<dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>3.7.0</version> </dependency> <!-- https://mvnrepository.com/artifact/com.alibaba/fastjson --> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.78</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.13</version> <scope>test</scope> </dependency>-
开启Redis-server服务
这里使用的是windows的Redis,找到Redis安装目录,找到Redis-server双击启动即可
-
测试
public static void main(String[] args) { Jedis jedis = new Jedis("127.0.0.1",6379); jedis.select(0); jedis.flushDB(); jedis.setnx("name","yfm"); jedis.setnx("age","21"); jedis.setnx("newname","newname"); jedis.incr("age"); System.out.println(jedis.get("age")); }127.0.0.1:6379> keys * 1) "newname" 2) "name" 3) "age" 127.0.0.1:6379> get newname "newname" 127.0.0.1:6379> get name "yfm" 127.0.0.1:6379> get age "22" 127.0.0.1:6379>
-
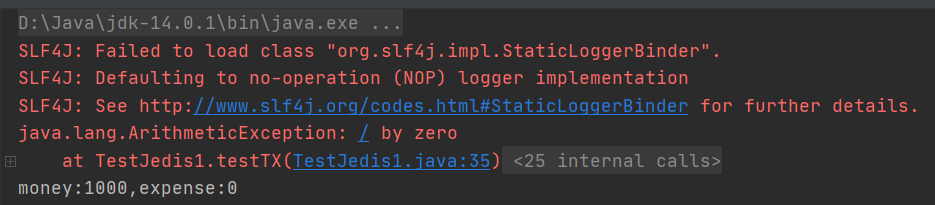
Jedis事务测试
@Test
public void testTX(){
//先创建Jedis对象
Jedis jedis = new Jedis("127.0.0.1",6379);
//选择数据库0
jedis.select(0);
//清空数据库
jedis.flushDB();
//设置参数
jedis.setnx("money","1000");
jedis.setnx("expense","0");
//监控money
jedis.watch("money");
//开启事务
Transaction transaction = jedis.multi();
try {
//命令进队
transaction.decrBy("money",20);
transaction.incrBy("expense",20);
int i=1/0; //抛出异常 处理时会抛弃事务
//执行事务
transaction.exec();
} catch (Exception e) {
transaction.discard();
e.printStackTrace();
} finally {
System.out.println("money:"+jedis.get("money")+",expense:"+jedis.get("expense"));
jedis.close();
}
}
Springboot整合Redis
SpringBoot前提须知
Springboot在2.x版本就不再使用Redis官方推荐的Jedis了,而是使用Lettude
源码分析:
springBoot的自动装配会自动导入很多配置类,具体可以去autoconfigure包去看,共127个类(可能是,差不多这么多)。当然,也不是全部注入,会有@Conditionnal注解帮助,只有导入依赖的才会被注入

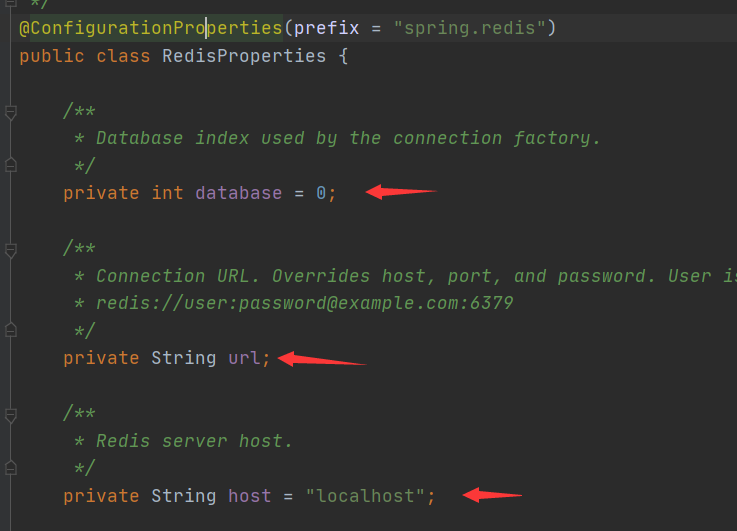
比如说Redis,就会有RedisAutoConfiguration,在这个配置里会自动导入RedisTemplate,而这个RedisTemplate会读取RedisProperties组件的参数(只记得结论~~)。然后我们可以直接通过自动注入@Autowired使用即可

而RedisProperties中就写出了我们可以配置哪些参数
测试使用
-
开启redis-server服务器,找到目录,双击redis-server.exe
-
application.properties配置参数
spring.redis.host=127.0.0.1 spring.redis.port=6379 spring.redis.database=0 -
注入RedisTemplate测试
![]()
@SpringBootTest class Jedis01ApplicationTests { @Autowired private RedisTemplate redisTemplate; @Test void contextLoads() { redisTemplate.opsForValue().set("name","yfm"); System.out.println(redisTemplate.opsForValue().get("name")); } }![]()

自己配置一个RedisTemplate
关于序列化
1、首先,我们要明确一点:如果对象不进行序列化,会报错
@Data
@AllArgsConstructor
@NoArgsConstructor
@ToString
public class User {
private String name;
private Integer age;
}
@Test
void test1() throws JsonProcessingException {
//不序列化User,看有无问题
User user = new User("yfm",21);
//springboot提高jackson对象
// String jsonUser = new ObjectMapper().writeValueAsString(user);
redisTemplate.opsForValue().set("user",user);
System.out.println(redisTemplate.opsForValue().get("user"));
}

2、要进行序列化,我们可以通过Jackson转化为json字符串(工作中常用),也可让pojo实体类实现serialable接口
//第一种方式 :implements Serializable
@Data
@AllArgsConstructor
@NoArgsConstructor
@ToString
public class User implements Serializable {
private String name;
private Integer age;
}
//第二种方式:通过Jackson转化为json字符串
@Data
@AllArgsConstructor
@NoArgsConstructor
@ToString
public class User {
private String name;
private Integer age;
}
@Test
void test1() throws JsonProcessingException {
//不序列化User,看有无问题
User user = new User("yfm",21);
//springboot提高jackson对象
String jsonUser = new ObjectMapper().writeValueAsString(user);
redisTemplate.opsForValue().set("user",jsonUser);
System.out.println(redisTemplate.opsForValue().get("user"));
}
但这两种方式在Redis客户端是乱码的
127.0.0.1:6379> keys *
1) "\xac\xed\x00\x05t\x00\x04user"
127.0.0.1:6379>
自定义template
简单来,就是我们先把框架的组件复制到我们的Config,我们再进行修改
下面是狂神提供的模板可以直接用
@Configuration
public class RedisConfig {
@Bean
@SuppressWarnings("all")
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
//为了使用方便,我们一般使用<String, Object>
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
// 序列化配置
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer=new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper om=new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
//String的序列化
StringRedisSerializer stringRedisSerializer =new StringRedisSerializer();
//key采用String的序列化方式
template.setKeySerializer(stringRedisSerializer);
//hash的key也采用String的序列化方式
template.setHashKeySerializer(stringRedisSerializer);
//value序列化方式也采用Jackson
template.setValueSerializer(jackson2JsonRedisSerializer);
//hash的序列化方式也采用Jackson
template.setHashValueSerializer(jackson2JsonRedisSerializer);
template.afterPropertiesSet();
return template;
}
}
使用:
这里User没用实现Serialable了
@SpringBootTest
class Jedis01ApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void test3(){
redisTemplate.opsForValue().set("user",new User("yfm",21));
}
}
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> get user
"[\"com.yfm.jedis01.pojo.User\",{\"name\":\"yfm\",\"age\":21}]"
127.0.0.1:6379> keys *
1) "user"
127.0.0.1:6379>
RedisUtils
实际工作种通常也会将redis操作封装成一个工具类,提升开发效率
比如学Jdbc,Mybatis都会封装成一个个工具类
RedisUtils实际上内部也是使用我们自己注入的redisTemplate,使用ops操作
package com.kuang.utils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import org.springframework.util.CollectionUtils;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.concurrent.TimeUnit;
@Component
public final class RedisUtil {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
// =============================common============================
/**
* 指定缓存失效时间
* @param key 键
* @param time 时间(秒)
*/
public boolean expire(String key, long time) {
try {
if (time > 0) {
redisTemplate.expire(key, time, TimeUnit.SECONDS);
}
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 根据key 获取过期时间
* @param key 键 不能为null
* @return 时间(秒) 返回0代表为永久有效
*/
public long getExpire(String key) {
return redisTemplate.getExpire(key, TimeUnit.SECONDS);
}
/**
* 判断key是否存在
* @param key 键
* @return true 存在 false不存在
*/
public boolean hasKey(String key) {
try {
return redisTemplate.hasKey(key);
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 删除缓存
* @param key 可以传一个值 或多个
*/
@SuppressWarnings("unchecked")
public void del(String... key) {
if (key != null && key.length > 0) {
if (key.length == 1) {
redisTemplate.delete(key[0]);
} else {
redisTemplate.delete(CollectionUtils.arrayToList(key));
}
}
}
// ============================String=============================
/**
* 普通缓存获取
* @param key 键
* @return 值
*/
public Object get(String key) {
return key == null ? null : redisTemplate.opsForValue().get(key);
}
/**
* 普通缓存放入
* @param key 键
* @param value 值
* @return true成功 false失败
*/
public boolean set(String key, Object value) {
try {
redisTemplate.opsForValue().set(key, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 普通缓存放入并设置时间
* @param key 键
* @param value 值
* @param time 时间(秒) time要大于0 如果time小于等于0 将设置无限期
* @return true成功 false 失败
*/
public boolean set(String key, Object value, long time) {
try {
if (time > 0) {
redisTemplate.opsForValue().set(key, value, time, TimeUnit.SECONDS);
} else {
set(key, value);
}
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 递增
* @param key 键
* @param delta 要增加几(大于0)
*/
public long incr(String key, long delta) {
if (delta < 0) {
throw new RuntimeException("递增因子必须大于0");
}
return redisTemplate.opsForValue().increment(key, delta);
}
/**
* 递减
* @param key 键
* @param delta 要减少几(小于0)
*/
public long decr(String key, long delta) {
if (delta < 0) {
throw new RuntimeException("递减因子必须大于0");
}
return redisTemplate.opsForValue().increment(key, -delta);
}
// ================================Map=================================
/**
* HashGet
* @param key 键 不能为null
* @param item 项 不能为null
*/
public Object hget(String key, String item) {
return redisTemplate.opsForHash().get(key, item);
}
/**
* 获取hashKey对应的所有键值
* @param key 键
* @return 对应的多个键值
*/
public Map<Object, Object> hmget(String key) {
return redisTemplate.opsForHash().entries(key);
}
/**
* HashSet
* @param key 键
* @param map 对应多个键值
*/
public boolean hmset(String key, Map<String, Object> map) {
try {
redisTemplate.opsForHash().putAll(key, map);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* HashSet 并设置时间
* @param key 键
* @param map 对应多个键值
* @param time 时间(秒)
* @return true成功 false失败
*/
public boolean hmset(String key, Map<String, Object> map, long time) {
try {
redisTemplate.opsForHash().putAll(key, map);
if (time > 0) {
expire(key, time);
}
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 向一张hash表中放入数据,如果不存在将创建
*
* @param key 键
* @param item 项
* @param value 值
* @return true 成功 false失败
*/
public boolean hset(String key, String item, Object value) {
try {
redisTemplate.opsForHash().put(key, item, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 向一张hash表中放入数据,如果不存在将创建
*
* @param key 键
* @param item 项
* @param value 值
* @param time 时间(秒) 注意:如果已存在的hash表有时间,这里将会替换原有的时间
* @return true 成功 false失败
*/
public boolean hset(String key, String item, Object value, long time) {
try {
redisTemplate.opsForHash().put(key, item, value);
if (time > 0) {
expire(key, time);
}
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 删除hash表中的值
*
* @param key 键 不能为null
* @param item 项 可以使多个 不能为null
*/
public void hdel(String key, Object... item) {
redisTemplate.opsForHash().delete(key, item);
}
/**
* 判断hash表中是否有该项的值
*
* @param key 键 不能为null
* @param item 项 不能为null
* @return true 存在 false不存在
*/
public boolean hHasKey(String key, String item) {
return redisTemplate.opsForHash().hasKey(key, item);
}
/**
* hash递增 如果不存在,就会创建一个 并把新增后的值返回
*
* @param key 键
* @param item 项
* @param by 要增加几(大于0)
*/
public double hincr(String key, String item, double by) {
return redisTemplate.opsForHash().increment(key, item, by);
}
/**
* hash递减
*
* @param key 键
* @param item 项
* @param by 要减少记(小于0)
*/
public double hdecr(String key, String item, double by) {
return redisTemplate.opsForHash().increment(key, item, -by);
}
// ============================set=============================
/**
* 根据key获取Set中的所有值
* @param key 键
*/
public Set<Object> sGet(String key) {
try {
return redisTemplate.opsForSet().members(key);
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* 根据value从一个set中查询,是否存在
*
* @param key 键
* @param value 值
* @return true 存在 false不存在
*/
public boolean sHasKey(String key, Object value) {
try {
return redisTemplate.opsForSet().isMember(key, value);
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 将数据放入set缓存
*
* @param key 键
* @param values 值 可以是多个
* @return 成功个数
*/
public long sSet(String key, Object... values) {
try {
return redisTemplate.opsForSet().add(key, values);
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
/**
* 将set数据放入缓存
*
* @param key 键
* @param time 时间(秒)
* @param values 值 可以是多个
* @return 成功个数
*/
public long sSetAndTime(String key, long time, Object... values) {
try {
Long count = redisTemplate.opsForSet().add(key, values);
if (time > 0)
expire(key, time);
return count;
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
/**
* 获取set缓存的长度
*
* @param key 键
*/
public long sGetSetSize(String key) {
try {
return redisTemplate.opsForSet().size(key);
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
/**
* 移除值为value的
*
* @param key 键
* @param values 值 可以是多个
* @return 移除的个数
*/
public long setRemove(String key, Object... values) {
try {
Long count = redisTemplate.opsForSet().remove(key, values);
return count;
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
// ===============================list=================================
/**
* 获取list缓存的内容
*
* @param key 键
* @param start 开始
* @param end 结束 0 到 -1代表所有值
*/
public List<Object> lGet(String key, long start, long end) {
try {
return redisTemplate.opsForList().range(key, start, end);
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* 获取list缓存的长度
*
* @param key 键
*/
public long lGetListSize(String key) {
try {
return redisTemplate.opsForList().size(key);
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
/**
* 通过索引 获取list中的值
*
* @param key 键
* @param index 索引 index>=0时, 0 表头,1 第二个元素,依次类推;index<0时,-1,表尾,-2倒数第二个元素,依次类推
*/
public Object lGetIndex(String key, long index) {
try {
return redisTemplate.opsForList().index(key, index);
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* 将list放入缓存
*
* @param key 键
* @param value 值
*/
public boolean lSet(String key, Object value) {
try {
redisTemplate.opsForList().rightPush(key, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 将list放入缓存
* @param key 键
* @param value 值
* @param time 时间(秒)
*/
public boolean lSet(String key, Object value, long time) {
try {
redisTemplate.opsForList().rightPush(key, value);
if (time > 0)
expire(key, time);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 将list放入缓存
*
* @param key 键
* @param value 值
* @return
*/
public boolean lSet(String key, List<Object> value) {
try {
redisTemplate.opsForList().rightPushAll(key, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 将list放入缓存
*
* @param key 键
* @param value 值
* @param time 时间(秒)
* @return
*/
public boolean lSet(String key, List<Object> value, long time) {
try {
redisTemplate.opsForList().rightPushAll(key, value);
if (time > 0)
expire(key, time);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 根据索引修改list中的某条数据
*
* @param key 键
* @param index 索引
* @param value 值
* @return
*/
public boolean lUpdateIndex(String key, long index, Object value) {
try {
redisTemplate.opsForList().set(key, index, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 移除N个值为value
*
* @param key 键
* @param count 移除多少个
* @param value 值
* @return 移除的个数
*/
public long lRemove(String key, long count, Object value) {
try {
Long remove = redisTemplate.opsForList().remove(key, count, value);
return remove;
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
}
总结
学习Redis实际上不难,主要是熟练API,以及懂得各种API的使用场景
Redis.Conf详解
-
Redis单位介绍,忽略大小写
-
include 包含其他文件,就比如spring的import,jsp的include
![]()
-
network
# bind 192.168.1.100 10.0.0.1 # listens on two specific IPv4 addresses # bind 127.0.0.1 ::1 # listens on loopback IPv4 and IPv6 # bind * -::* # like the default, all available interfaces bind 127.0.0.1 -::1 # 1. 绑定IP protected-mode yes port 6379 -
general
daemonize yes #设置为守护线程,默认为no,我们需要改为yes pidfile /var/run/redis_6379.pid #守护线程方式启动,就要指定一个一个pid文件 #日志 loglevel notice #日志等级 1. debug:会打印出很多信息,适用于开发和测试阶段 2. verbose(冗长的):包含很多不太有用的信息,但比debug要清爽一些 3. notice:适用于生产模式 4. warning : 警告信息 logfile "" #设置日志文件名称 databases 16 #数据库数量,默认为16 always-show-logo no #是否显示logo![]()


-
SNAPSHOTTING 快照
持久化,在规定的时间,执行了多少次操作,则会持久到文件 .rdb .aof
redis是内存数据库,如果没用持久化,数据断电即失
#间隔3600秒之内至少修改了1个key,就持久化 save 3600 1 #间隔300秒之内至少修改了100个key,就持久化 save 300 100 #间隔60秒之内至少修改了10000个key,就持久化 save 60 10000 stop-writes-on-bgsave-error yes #持久化出现问题是否继续执行 rdbcompression yes #是否要进行rdb压缩,这会消耗一些cpu资源 rdbchecksum yes #保存rdb文件的时候,是否进行错误校验 dir ./ #rdb文件保存的目录 -
Replication 主从复制
-
security
#获取密码 config get requirepass #设置密码 config set requirepass 123456 #当有密码的时候登录时需要密码登录 auth yourPassword #取消密码 config set requirepass '' -
限制clients
maxclients 10000 # 设置能连上redis的最大客户端数量 maxmemory <bytes> # redis配置的最大内存容量 maxmemory-policy noeviction #内存达到上线的处理策略 1、volatile-lru:只对设置了过期时间的key进行LRU(默认值) 2、allkeys-lru : 删除lru算法的key 3、volatile-random:随机删除即将过期key 4、allkeys-random:随机删除 5、volatile-ttl : 删除即将过期的 6、noeviction : 永不过期,返回错误 -
APPEND ONLY MODE aof模式
appendonly no # 默认不开启aof模式,几乎所有情况都用rdb持久化 appendfilename "appendonly.aof" # 持久化文件名称 # appendfsync always 每次都会修改 sync,消耗性能 appendfsync everysec # 每一秒都会修改 sync # appendfsync no 不会修改 sync,由操作系统自己同步数据,速度最快
Redis持久化
rdb持久化,redis默认方式
1、rdb是采用快照的方式进行持久化
#间隔3600秒之内至少修改了1个key,就持久化
save 3600 1
#间隔300秒之内至少修改了100个key,就持久化
save 300 100
#间隔60秒之内至少修改了10000个key,就持久化
save 60 10000
当满足我们设立的条件时,比如过了3600秒,有1个key修改了,就把数据更新到快照(生成新的dump.rdb文件,dump.rdb文件名是redis.conf可以设置的),生成后新的快照就会替代旧的快照。快照文件是保存在磁盘中的,redis在新快照生成以后就读取快照信息,恢复数据到内存。
2、rdb持久化的过程:
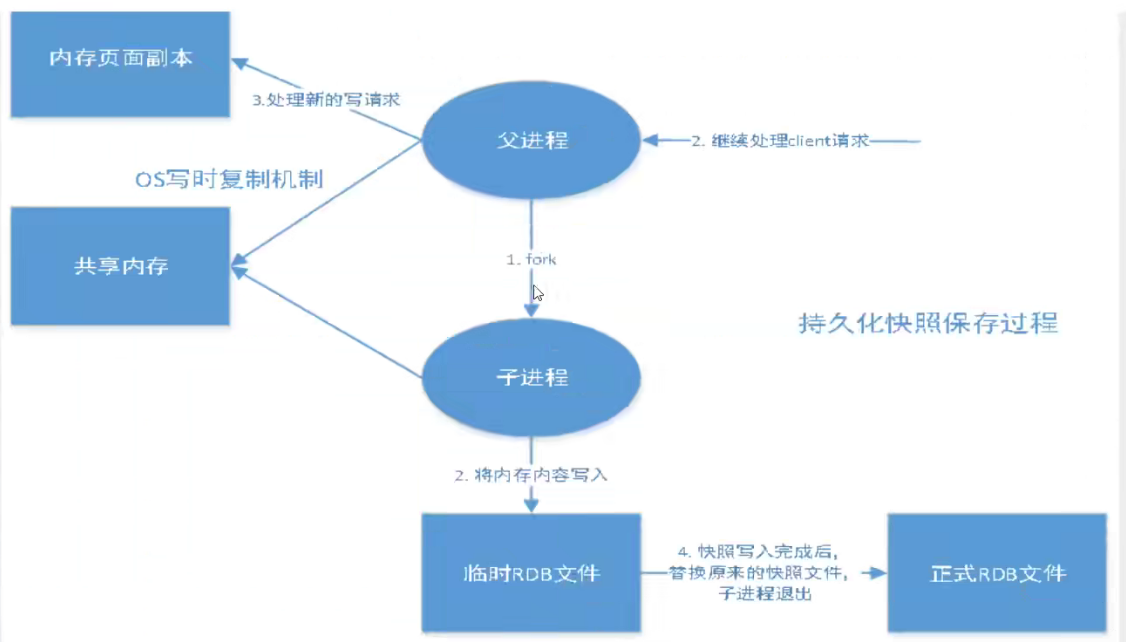
当满足条件,需要生成快照时,父进程会fork一个子进程来完成快照生成(两者共享内存),父进程继续负责客户端的操作,子进程生成临时快照,临时快照生成完毕代替新快照,redis再读取新快照恢复新数据。但最后一次持久化数据可能会丢失。
3、我的困惑:
断开redis服务也会生成dump.rdb(快照),那redis重启后读取dump.rdb不就可以恢复数据了吗,为什么说可能会丢失最后一次要持久化的数据呢?
4、dump.rdb的生成有下列情况:
- 满足save规则(多少秒有多少key修改)
- flushall语句执行
- 断开redis服务,shutdown(断电)
5、Redis读取dump.rdb的目录:/usr/local/bin,这也是dump.rdb默认生成目录
读取dump.rdb恢复数据到内存
config get dir
"dir"
"usr/local/bin"
6、rdb持久化的优缺点:
优点
- 适合大规模数据的持久化
- 适合数据库完整性要求不高的情况
缺点
- 需要一定时间间隔来持久化,如果redis以外宕机,最后一次修改的数据就没了
- fork子进程需要消耗内存空间
aof持久化
1、aof是采取日志记录的方式实现持久化的,append only file

appendonly no # 默认不开启aof模式,几乎所有情况都用rdb持久化
appendfilename "appendonly.aof" # 持久化文件名称
# appendfsync always 每次都会修改 sync,消耗性能
appendfsync everysec # 每一秒都会修改 sync
# appendfsync no 不会修改 sync,由操作系统自己同步数据,速度最快
aof默认是关闭的,当开启后,选择上述三种模式之一。aof会记录所有的写操作,而不会记录读操作,记录的写操作会追加在appendonly.aof文件中(文件中保存的就是命令,也在目录/usr/local/bin)。当redis再次启动,会依次执行appendonly的写命令,恢复数据
2、appendonly.aof文件的修复

#我们可以人为的破坏appendonly的内容,破坏以后,再启动Redis服务会报错,我们就需要使用该命令修复appendonly.aof
redis-check-aof --fix appendonly.aof
3、优缺点
优点:
- 每一次修改都同步,文件的完整性更高
- 每秒同步一次,可能损失一秒的数据
- 从不同步,效率最高
缺点:
- 相对于数据文件来说,aof大小远大于rdb,更耗时间
- aof运行效率也慢于rdb
4、rewrite问题
aof文件默认会无限追加,如果文件大小大于64mb(不一定是64mb,可以在redis.conf设置),就会再fork一个新进程来重写命令 了解有这个东西即可
Redis发布订阅
1、Redis发布订阅介绍
Redis 发布订阅 (pub/sub) 是一种消息通信模式:发送者 (pub) 发送消息,订阅者 (sub) 接收消息。
Redis 客户端可以订阅任意数量的频道。
下图展示了频道 channel1 , 以及订阅这个频道的三个客户端 —— client2 、 client5 和 client1 之间的关系:

当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:

2、Redis 发布订阅命令
下表列出了 redis 发布订阅常用命令:
| 序号 | 命令及描述 |
|---|---|
| 1 | [PSUBSCRIBE pattern pattern ...] 订阅一个或多个符合给定模式的频道。 |
| 2 | [PUBSUB subcommand argument [argument ...]] 查看订阅与发布系统状态。 |
| 3 | PUBLISH channel message 将信息发送到指定的频道。 |
| 4 | [PUNSUBSCRIBE pattern [pattern ...]] 退订所有给定模式的频道。 |
| 5 | [SUBSCRIBE channel channel ...] 订阅给定的一个或多个频道的信息。 |
| 6 | [UNSUBSCRIBE channel [channel ...]] 指退订给定的频道。 |
3、命令演示
# 1、订阅端 订阅频道
127.0.0.1:6379> SUBSCRIBE movieShow
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "movieShow"
3) (integer) 1
# 2、发送端 发送消息
127.0.0.1:6379> PUBLISH movieShow "let's watch a new movie!" #发送消息
(integer) 1
127.0.0.1:6379>
# 3、订阅端 接受消息
127.0.0.1:6379> SUBSCRIBE movieShow
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "movieShow"
3) (integer) 1
1) "message" # 表示接受消息
2) "movieShow" # 频道名
3) "let's watch a new movie!" # 消息内容
4、原理简述:
当有订阅者订阅一个频道时,Redis会生成一个字典,字典的key是一个个频道,而键是一个个订阅了对应频道的所有订阅者的链表。发送消息时,就按照key找到所有订阅者,然后给订阅者发送消息。订阅者都是一个客户端
字典如下:
| 频道 | 链表 |
|---|---|
| 频道1 | 所有订阅者组成的链表1 |
| 频道2 | 所有订阅者组成的链表2 |
| 频道3 | 所有订阅者组成的链表3 |
| ... | ... |
5、发送订阅的使用场景
- 即时聊天
- 订阅关注系统
复杂的好像是用消息中间件来做
Redis主从复制
工作中,我们不会只配置一台redis服务器
工作中,我们不会只配置一台redis服务器,因为如果只有一台机器,那一旦出了问题,那这个故障就会是一个很大的问题,耽误许多人的工作。于是我们会配置多台服务器。
主从复制环境配置
在多台服务器中,我们让其中一台服务器作为主机,只负责写操作,而另外几台作为从机,只负责读操作。而一般,至少有1台主机,2台从机,也就是一主二从,确保万一主机挂了,可以让一台从机及时充当主机正常工作。

主从复制环境配置:
redis服务器中,每一个服务器默认都是主机
只需要配置从机!
#查看主从复制状态
info replication
#只需要配置从机
slaveof ip port
#配置主从复制,首先配置多个服务器
#单机多服务器配置
#要配置一主二从,那么这三台服务器的redis.conf文件中的
#port、 pid、 log、 dump.rdb都不能重复

#一主二从:6380,6381全都认6379为老大
#6379
[root@localhost bin]# redis-server myconfig/redis79.conf
[root@localhost bin]# redis-cli -p 6379
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=42,lag=1
slave1:ip=127.0.0.1,port=6381,state=online,offset=42,lag=1
master_failover_state:no-failover
master_replid:97ffd7494d3456a4c2a9fbe257b69a044ae2f764
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:42
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:42
127.0.0.1:6379>
#6380
[root@localhost bin]# redis-server myconfig/redis80.conf
[root@localhost bin]# redis-cli -p 6380
127.0.0.1:6380> SLAVEOF 127.0.0.1 6379
OK
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:1
master_sync_in_progress:0
slave_read_repl_offset:70
slave_repl_offset:70
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:97ffd7494d3456a4c2a9fbe257b69a044ae2f764
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:70
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:70
127.0.0.1:6380>
#6381
[root@localhost bin]# redis-server myconfig/redis81.conf
[root@localhost bin]# redis-cli -p 6381
127.0.0.1:6381> SLAVEOF 127.0.0.1 6379
OK
127.0.0.1:6381> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:8
master_sync_in_progress:0
slave_read_repl_offset:70
slave_repl_offset:70
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:97ffd7494d3456a4c2a9fbe257b69a044ae2f764
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:70
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:29
repl_backlog_histlen:42
127.0.0.1:6381>
主从复制测试
1、主机不断,从机也不断
#主机可以读写(默认只做写操作)
#从机只可读

2、主机不断,从机断了再连
#从机
127.0.0.1:6380> shutdown
not connected>
#主机
127.0.0.1:6379> set newone newone
OK
127.0.0.1:6379>
#从机
[root@localhost bin]# redis-server myconfig/redis80.conf
[root@localhost bin]# redis-cli -p 6380
127.0.0.1:6380> get newone
(nil)
127.0.0.1:6380> info replication
# Replication
role:master
connected_slaves:0
master_failover_state:no-failover
master_replid:bd2234dc77a8bb4de57e4a49b4f528e0a37dacd9
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6380> slaveof 127.0.0.1 6379 #重新认6379为老大
OK
127.0.0.1:6380> get newone
"newone"
127.0.0.1:6380> keys *
1) "newone"
2) "new"
3) "name"
127.0.0.1:6380>
从机断了以后,再连上来,从机又变成主机了,我们必须重新再手动设置
这种手动设置是暂时的,一旦有从机宕机,我们必须重新设置。所以,我们也可以在从机的redis.conf设置,这种设置是永久的,只要从机一启动,就会认redis.conf配置的主机为老大

手动设置完了以后,我们发现,之前主机写的数据又全部发送给了从机
3、主机断了再连,从机不断
主机使用shutdown退出服务后,我们发现两台从机依旧还是认6379为老大
#6380
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:down
master_last_io_seconds_ago:-1
master_sync_in_progress:0
slave_read_repl_offset:700
slave_repl_offset:700
master_link_down_since_seconds:475
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:56247121c0e11aef2a3c14308f2aef0d134fdf58
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:700
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:337
repl_backlog_histlen:364
127.0.0.1:6380>
主机重新连接,我们发现主机的仍有两台从机6380,6381
[root@localhost bin]# redis-server myconfig/redis79.conf
[root@localhost bin]# redis-cli -p 6379
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=14,lag=1
slave1:ip=127.0.0.1,port=6381,state=online,offset=14,lag=1
master_failover_state:no-failover
master_replid:be46e6014adff297733b29c2519cbfa1af36c6aa
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:14
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:14
127.0.0.1:6379>
显然,主机断开,两位小弟忠心耿耿,一直会等待老大回归,但这样不行。我们希望一台主机宕机后,会有新的从机担任新主机,就好比一个帮派群龙无首,迟早分崩离析!
4、谋朝篡位
#当老大不在了,从机使用这条命令就可以当老大
slaveof no one
5、层层链路,毛毛虫模式
简单说就是6379是6380的老大,6380是6381的老大。前一个是后一个的老大
在6379宕机以前,尽管6380是6381的老大,但也只能读取6379写的数据,而不能主动写数据给6381
当6379宕机了以后,6380使用slaveof no one就真正是6381的老大了
这时候,6379再回来,它就是一光杆司令,除非6380可以再认6379为老大
主从复制原理

哨兵模式:谋朝篡位自动版
之前我们说了,当主机宕机后,我们需要一台从机谋朝篡位变成主机
而哨兵就是来监测主机是否挂了,是否需要换从机为主机的进程
也就是谋朝篡位的自动版
哨兵:sentinel
哨兵模式的原理:哨兵进程通过发消息给redis服务器,如果服务器不回复消息,那么就认为该台服务器挂了


测试哨兵:
-
创建一个关于哨兵的文件sentinel.conf
-
文件内输入基本配置
#哨兵最基本配置 sentinel monitor 被监控名称 host port 1 sentinel monitor myredis 127.0.0.1 6379 1后面的1代表,万一主机挂了,哨兵会在从机之间投票选出主机
-
确定好几个服务器的主从关系
-
使用命令
![]()
redis-sentinel myconfig/sentinel.conf具体详细配置是由运维人员做的,如果感兴趣可以去百度搜索配置,玩一玩
-
手动关掉主机服务shutdown
-
哨兵选出新主机,原来的主机重新连接也只能当新主机的从机

Redis缓存穿透和雪崩
一般情况下,redis做缓存,mysql做存储层
数据访问先访问 redis,redis查的到就返回数据,查不到再来查mysql。
穿透(查不到)
数据访问redis,redis没有,查mysql也没有,如果这时候有大量请求 请求的是查不到的数据,那么就会频繁的访问mysql,这就是缓存穿透,跳过redis缓存查mysql
解决方法:
-
布隆过滤器
-
缓存空值
在redis中对这些查不到的key存储空值,查询的时候返回空值
击穿(大量请求集中访问一个key)
比如微博热搜
大量的请求访问缓存中的一个key,若该key在缓存中过期了,那么针对该key的请求直接访问mysql,这就叫缓存击穿
解决方法:
- 设置key永不过期,但redis内存空间是有限的(我就知道个模糊印象)
- 加互斥锁
雪崩
redis宕机,所有请求全部都直接访问MySQL,这就叫雪崩
解决办法:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号