L02_机器学习任务攻略
目录
Framework of ML
训练模型的过程分为三个步骤:
- 写出一个具有未知数的\(Function\),\(y=f_{\theta}(x)\),\(\theta\)表示模型中的所有的未知参数。
- 定义损失函数\(L(\theta)\),函数的输入就是一组参数,用来判断这一组参数的好坏。
- 进行最优化,寻找让损失函数最小的参数\(\theta^{*}\)
怎样将模型训练的更好
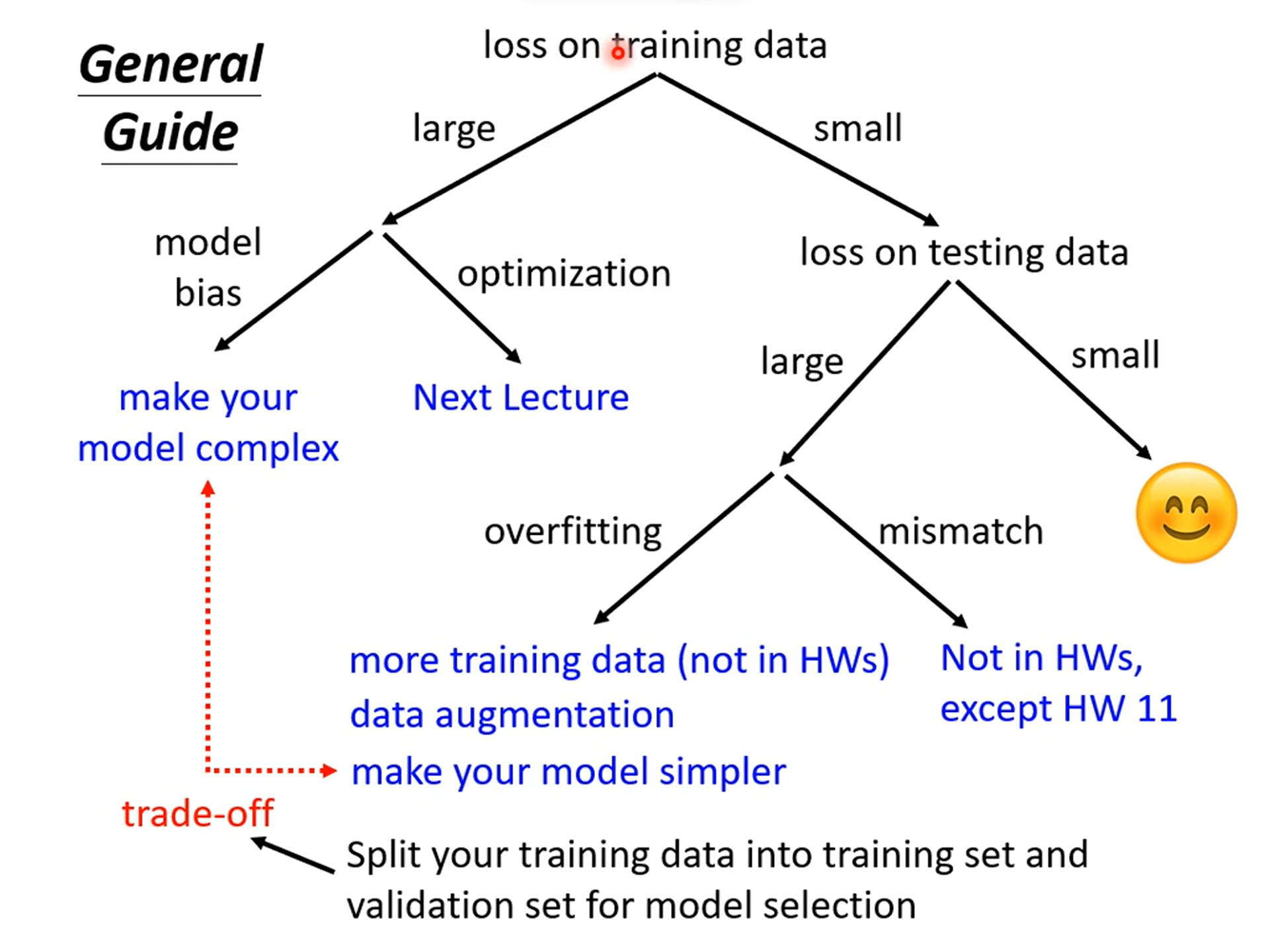
情况一:在训练数据集的Loss比较大
1. 模型过于简单,相当于在大海捞针,但是针不在大海中。
解决方法:增加模型的弹性。
-
增加输入的\(Features\);
-
使用深度学习,使用更多的neurons和layers。
-
Optimization Issue,最优化做的不够好,虽然存在最优的\(\theta^{*}\),但是设计的最优化方法并不能找到,相当于针在海里,但是无法找到。
解决方法:使用更加强大的优化技术。
2. 怎么判断是哪一个问题呢?
通过比较不同的模型,来得知自己的model够不够大。
- 从一个弹性比较小的神经网络(或者其他模型)出发,因为这些模型比较容易进行最优化,一般不会出现失败的情况。
- 然后设计一个更深的神经网络,如果更深的弹性更大的神经网络还没有弹性较小的神经网络得到的Loss小,那就说明是Optimization Issue。
情况二:在训练集的Loss较小,但是在测试集的比较大
Overfitting
举例说明原因
举一个比较极端的例子:
\[Training\quad data :{(x^{1},\hat{y}^{2}),(x^{1},\hat{y}^{2}),\cdots,(x^{N},\hat{y}^{N})}\\
f(x) =
\begin{cases}
\hat{y}^{i}\quad \quad &\exists = x \\
random & otherwise
\end{cases}
\]
这个函数在训练集上的Loss为0,但是在测试集上的Loss比较大。
另一个比较可能的原因是训练资料太少,出现了类似于插值函数中的龙格现象的问题。
解决方法:
-
对训练数据集进行修改。
-
增加训练数据的量;
-
进行
Data augmentation,对原有的数据进行合理的修改;
-
-
对模型进行修改,选择弹性较小的模型,给自己的模型进行限制(不能给出太大的限制)。
- 使用更少的参数,共享相同的参数
- 使用更少的features
- Early stopping
- Reguarization
- Dropout

 浙公网安备 33010602011771号
浙公网安备 33010602011771号