
Introduction to Big Data with Apache Spark 课程总结
课程主要实用内容:
a. 下载,安装visualbox
管理员身份运行;课程要求最新版4.3.28,如果c中遇到虚拟机打不开的,可以用4.2.12,不影响
b. 下载,安装vagrant,重启
管理员身份运行
c. 下载虚拟机
c1.将vagrant加入path,D:\HashiCorp\Vagrant\bin
c2.创建虚拟机存放的目录,比如myvagrant
c3.下载文件mooc-setup-master.zip,解压后,拷贝Vagrantfile到myvagrant
c4.打开visual box图形界面,进入cmd,cd到myvagrant,敲命令 vagrant up
开始下载虚拟机,并打开,如果下载完成,但是打开虚拟机出错;
可以到visual box 图形界面点击打开,碰到一下错误,可尝试用4.2.12版visual box
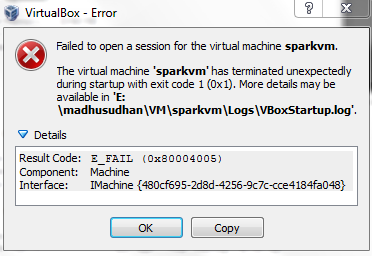
使用说明:i.打开关闭虚拟机:打开visual box 界面,cd进入myvagrant
vagrant up 打开虚拟机,vagrant halt 关闭虚拟机
ii.ipython notebook,进入http:\\localhost:8001
停止正在运行的notebook,点击running,停止
点某 .py文件,运行note book
iii.下载ssh软件,可登入虚拟机,地址为127.0.0.1,端口2222,用户名vagrant,密码vagrant
进入后,敲pyspark,可进入pyspark交互式界面
3.常用函数
Spark中Rdd的生命周期
创建RDD(parallelize、textFile等)
对RDD进行变换
(会创建新的RDD,不会改变原RDD,有
1.对每个元素进行操作-map,flatMap,mapValues
2.筛选 filter
3.排序 sortBy
3.合并结果 reduceByKey,groupByKey
4.合并两个rdd union,join,leftJoin,rightJoin)
以上步骤中rdd都只相当于一个操作手册,并没有真实地在内存中产生数据,称为lazy evaluation
缓存rdd到内存中 cache() ,判断是否cache,访问 .is_cached属性
触发evaluation(包括top,take,takeOrdered,takeSample,sum,count,distinct,reduce,collect,collectAsMap)
4.变量共享
spark有两种变量共享方式
a.广播 broadcast,broadcast后的变量每个partition都会存储一份,但是只能读取,不能修改
>>> b=sc.broadcast([1,2,3,4,5])
>>> sc.parallelize([0,0]).flatMap(lambdax:b.value)
b.累加器 accumulator,只能写,不能在worker被读取
如果累加器只是一个标量,使用很简单
>>> rdd = sc.parallelize([1,2,3]) >>> def f(x): ... global a ... a += x >>> rdd.foreach(f) >>> a.value 13
如果累加器是一个向量,需要定义AccumulatorParam,且zero方法和addInPlace都要实现
>>> from pyspark.accumulators import AccumulatorParam >>> class VectorAccumulatorParam(AccumulatorParam): ... def zero(self, value): ... return [0.0] * len(value) ... def addInPlace(self, val1, val2): ... for i in xrange(len(val1)): ... val1[i] += val2[i] ... return val1 >>> va = sc.accumulator([1.0, 2.0, 3.0], VectorAccumulatorParam()) >>> va.value [1.0, 2.0, 3.0]>>> defg(x): ... global va ... va += [x] * 3 >>> rdd.foreach(g) >>> va.value [7.0, 8.0, 9.0]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号