

决策树 随机森林 adaboost
熵、互信息
决策树学习算法
信息增益
ID3、C4.5、CART
Bagging与随机森林
提升
Adaboost/GDBT
熵、互信息
熵是对平均不确定性的度量。
平均互信息:得知特征Y的信息而使得对标签X的信息的不确定性减少的程度。描述随机变量之间的相似程度。(条件熵、相对熵:差异性)
决策树
决策树学习采用的是自顶向下的递归方法,有监督学习。
其基本思想是以信息熵为度量构造一棵熵值下降最快的树,到叶子节点处的熵值为零,此时每个叶节点中的实例都属于同一类。
建立决策树的关键,即在当前状态下选择哪个属性作为分类依据。根据不同的目标函数,建立决策树主要有一下三种算法。
ID3 信息增益:g(D,A) = H(D) - H(D|A) 特征A对训练数据集D的信息增益,选择互信息最大的特征为当前的分类特征。
C4.5 信息增益率:gr(D,A) = g(D,A)/H(A) 增加惩罚,泛化能力
CART
分类回归树算法:CART(Classification And Regression Tree)算法采用一种二分递归分割的技术,将当前的样本集分为两个子样本集,
使得生成的的每个非叶子节点都有两个分支。因此,CART算法生成的决策树是结构简洁的二叉树。由于CART算法构成的是一个二叉树,
它在每一步的决策时只能是“是”或者“否”,即使一个feature有多个取值,也是把数据分为两部分。
分类树两个基本思想:第一个是将训练样本进行递归地划分特征空间进行建树的想法,第二个想法是用验证数据进行剪枝。
CART算法的原理:
上面说到了CART算法分为两个过程,其中第一个过程进行递归建立二叉树,那么它是如何进行划分的 ?
设 代表单个样本的
代表单个样本的 个属性,
个属性, 表示所属类别。CART算法通过递归的方式将
表示所属类别。CART算法通过递归的方式将 维的空间划分为不重叠的矩形。
维的空间划分为不重叠的矩形。
划分步骤大致如下:
(1)选一个自变量 ,再选取
,再选取 的一个值
的一个值 ,
, 把
把 维空间划分为两部分,一部分的所有点都满足
维空间划分为两部分,一部分的所有点都满足 ,
,
另一部分的所有点都满足 ,对非连续变量来说属性值的取值只有两个,即等于该值或不等于该值。
,对非连续变量来说属性值的取值只有两个,即等于该值或不等于该值。
(2)递归处理,将上面得到的两部分按步骤(1)重新选取一个属性继续划分,直到把整个 维空间都划分完。
维空间都划分完。
对于连续变量属性来说,它的划分点是一对连续变量属性值的中点。假设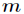 个样本的集合一个属性有
个样本的集合一个属性有 个连续的值,
个连续的值,
那么则会有 个分裂点,每个分裂点为相邻两个连续值的均值。每个属性的划分按照能减少的杂质的量来进行排序,
个分裂点,每个分裂点为相邻两个连续值的均值。每个属性的划分按照能减少的杂质的量来进行排序,
而杂质的减少量定义为划分前的杂质减去划分后的每个节点的杂质量划分所占比率之和。
而杂质度量方法常用Gini指标,假设一个样本共有 类,那么一个节点
类,那么一个节点 的Gini不纯度可定义为
的Gini不纯度可定义为

其中 表示属于
表示属于 类的概率,当Gini(A)=0时,所有样本属于同类,所有类在节点中以等概率出现时,Gini(A) 最大化,此时
类的概率,当Gini(A)=0时,所有样本属于同类,所有类在节点中以等概率出现时,Gini(A) 最大化,此时 。
。
Gini系数:
在CART算法中, 基尼不纯度表示一个随机选中的样本在子集中被分错的可能性。
分类度量时,总体内包含的类别越杂乱,GINI指数就越大(跟熵的概念很相似)。
当一个节点中所有样本都是一个类时,基尼不纯度为零。
一个节点A的GINI不纯度定义为:
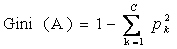
其中,Pk表示观测点中属于k类的概率,当Gini(A)=0时所有样本属于同一类,当所有类在节点中以相同的概率出现时,
Gini(A)最大化,此时值为(C-1)C/2。
(基尼不纯度为这个样本被选中的概率乘以它被分错的概率。假设y的可能取值为{1, 2, ..., m},令fi是样本被赋予i的概率,
则基尼指数可以通过如下计算:)(Gini系数与熵之间的关系: lnx = 1 - x 近似)
对于分类回归树,A如果它不满足“T都属于同一类别or T中只剩下一个样本”,则此节点为非叶节点,
所以尝试根据样本的每一个属性及可能的属性值,对样本的进行二元划分,假设分类后A分为B和C,
其中B占A中样本的比例为p,则C为q(显然p+q=1)。
则杂质改变量:Gini(A) -p*Gini(B)-q*Gini(C),每次划分该值应为非负,只有这样划分才有意义,
对每个属性值尝试划分的目的就是找到杂质改变量最大的一个划分,该属性值划分子树即为最优分支。
(即选择Gini不纯度最小的特征做为划分)
建树完成后就进行第二步了,即根据验证数据进行剪枝。在CART树的建树过程中,可能存在Overfitting,许多分支中反映的是数据中的异常,
这样的决策树对分类的准确性不高,那么需要检测并减去这些不可靠的分支。决策树常用的剪枝有事前剪枝和事后剪枝,CART算法采用事后剪枝,
具体方法为代价复杂性剪枝法。
参考博文:http://blog.csdn.net/acdreamers/article/details/44664481
http://www.dataguru.cn/article-4720-1.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号