

大杂烩
实现MooseFS的高可用
#################################################################
-
开篇引题
-
Distributed Replicated Block Device
-
部署MFS
-
部署Corosync+Pacemaker
-
故障模拟测试
-
补充和总结
#################################################################
开篇引题
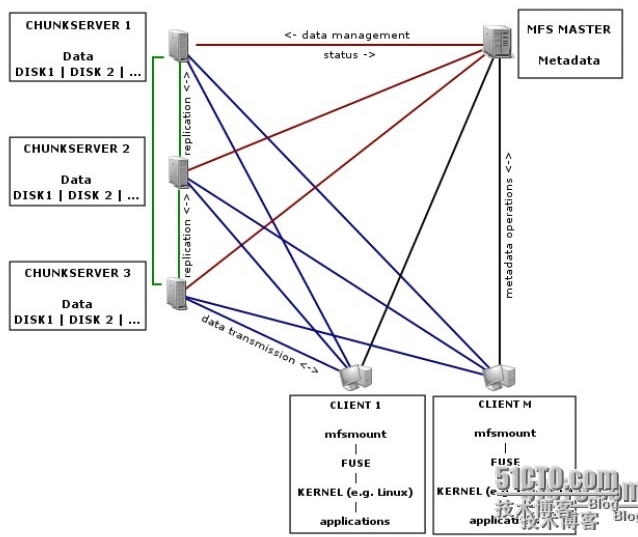
直接上图,有图有真相啊!此图是MFS网络组成和运行原理,先不说图中每种角色的作用(下文会有详细说明),直观信息告诉我们客户端无论是读写请求都需要与MasterServer通信,而图中MasterServer角色只有一个,因此单点故障的因素就显而易见了。解决MFS的单点故障正是本文的初衷,接下来就介绍如何利用多种技术解决MFS的单点故障,实现MasterServer的高可用。
Distributed Replicated Block Device
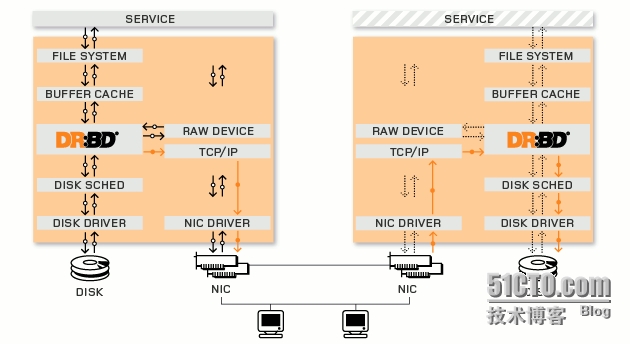
分布式复制块设备是Linux内核的存储层中的一个分布式存储系统,可利用DRBD在两台Linux服务器之间共享块设备、文件系统和数据,类似于一个网络RAID1的功能,内核中的DRBD模块监听特定套接字上,复制系统调用产生的写数据为副本并通过TCP协议发送至DRBD从节点,因为节点间磁盘设备每一个数据位都是相同的,所以DRBD可以实现廉价块级别的数据共享。
DRBD工作模型
主从模型(primary/secondary),同一时刻只能有一个节点提供服务(否则会产生脑裂),从节点无法使用磁盘分区(挂载也不可以)。
主主模型(primary/primary),需要借助于集群文件系统并启用分布式文件锁功能,而且写性能不会有提升.
DRBD管理
内核模块:drbd用户空间
管理工具:drbdadm,drbdsetup,drbdmeta
工作流程(默认模型是Sync)
Async:副本交于本地TCP/IP协议栈就返回(性能最高)
SemiSync:副本交对方TCP/IP协议栈就返回(折中方案)
Sync:副本被secondary存储到磁盘中就返回(性能差)
安装配置DRBD(drbd内核模块必须和内核版本完全匹配)
rpm -ivh drbd-8.4.3-33.el6.x86_64.rpm drbd-kmdl-2.6.32-358.el6-8.4.3-33.el6.x86_64.rpm主配置文件
[root@one packages]# cat /etc/drbd.conf# You can find an example in /usr/share/doc/drbd.../drbd.conf.example
include "drbd.d/global_common.conf";
include "drbd.d/*.res";
全局配置文件
cat /etc/drbd.d/global_common.confglobal {
usage-count yes;
# minor-count dialog-refresh disable-ip-verification
}
common {
handlers {
pri-on-incon-degr "/usr/lib/drbd/notify-pri-on-incon-degr.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
pri-lost-after-sb "/usr/lib/drbd/notify-pri-lost-after-sb.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
local-io-error "/usr/lib/drbd/notify-io-error.sh; /usr/lib/drbd/notify-emergency-shutdown.sh; echo o > /proc/sysrq-trigger ; halt -f";
# fence-peer "/usr/lib/drbd/crm-fence-peer.sh";
# split-brain "/usr/lib/drbd/notify-split-brain.sh root";
# out-of-sync "/usr/lib/drbd/notify-out-of-sync.sh root";
# before-resync-target "/usr/lib/drbd/snapshot-resync-target-lvm.sh -p 15 -- -c 16k";
# after-resync-target /usr/lib/drbd/unsnapshot-resync-target-lvm.sh;
}
startup {
# wfc-timeout degr-wfc-timeout outdated-wfc-timeout wait-after-sb
}
options {
# cpu-mask on-no-data-accessible
}
disk {
on-io-error detach;
# size max-bio-bvecs on-io-error fencing disk-barrier disk-flushes
# disk-drain md-flushes resync-rate resync-after al-extents
# c-plan-ahead c-delay-target c-fill-target c-max-rate
# c-min-rate disk-timeout
}
net {
cram-hmac-alg "sha1";
shared-secret "soulboy";
# protocol timeout max-epoch-size max-buffers unplug-watermark
# connect-int ping-int sndbuf-size rcvbuf-size ko-count
# allow-two-primaries cram-hmac-alg shared-secret after-sb-0pri
# after-sb-1pri after-sb-2pri always-asbp rr-conflict
# ping-timeout data-integrity-alg tcp-cork on-congestion
# congestion-fill congestion-extents csums-alg verify-alg
# use-rle
}
syncer {
rate 1000M;
}
}
定义资源mfs
[root@one packages]# cat /etc/drbd.d/mydata.resresource mydata {
on one.soulboy.com {
device /dev/drbd0;
disk /dev/sdb2; #大小要一致
address 192.168.1.61:7789;
meta-disk internal;
}
on two.soulboy.com {
device /dev/drbd0;
disk /dev/sdb1; #大小要一致
address 192.168.1.62:7789;
meta-disk internal;
}
}
resource mfs {
on one.soulboy.com {
device /dev/drbd1;
disk /dev/sdb3;
address 192.168.1.61:7788;
meta-disk internal;
}
on two.soulboy.com {
device /dev/drbd1;
disk /dev/sdb2;
address 192.168.1.62:7788;
meta-disk internal;
}
}
同步配置文件到从节点
scp /etc/drbd.d/* two.soulboy.com:/etc/drbd.d/初始化资源(分别在两个节点上执行)
drbdadm create-md mfs启动资源(分别在两个节点上执行)
service drbd start将某节点变为主节点(192.168.1.61为主节点)
drbdadm primary --force mydata查看状态确定同步完毕
[root@one packages]# service drbd status1:mfs Connected Primary/Secondary UpToDate/UpToDate C /mfs ext4
格式化文件系统(在主节点)
mke2fs -t ext4 /dev/drbd1允许对方抢占(分别在两节点上执行)
drbdadm primary mfs开机不要自动启动
chkconfig drbd off部署MFS
MFS工作原理
MFS文件系统能够实现RAID功能,节约成本,不逊色于专业的存储系统,可以实现在线扩容。
MFS的四种角色
MasterServer(元数据服务器):负责管理各个ChunkServer及调度文件读写,回收文件空间及恢复多节点拷贝。
Metalogger(元数据日志服务器):负责备份管理服务器的变化日志文件。
ChunkServer(数据存储服务器):真正存储用户数据的服务器,将文件切块相互同步,听从MasterServer的调度为Client提供数据传输,Chunk节点数量越多,可靠性和MFS可用的磁盘空间就会越大。
Client(客户端):客户端通过fuse内核接口远程管理服务器上所管理的数据存储服务器,和使用本地文件系统一样。
安装配置元数据服务
mount /dev/drbd1 /mfs #挂载drbd设备groupadd -g 1000 mfs #两边节点的uid要统一
useradd -u 1000 -g mfs -s /sbin/nologin mfs #两边节点都需要创建
mkdir -pv /mfs #主节点创建数据目录即可
chown -R mfs.mfs /mfs #两个节点修改目录属主和属组为mfs
tar xf mfs-1.6.26.tar.gz
cd mfs-1.6.26
./configure --prefix=/mfs --with-default-user=mfs --with-default-group=mfs
make && make install
cp /mfs/etc/mfsmaster.cfg.dist /mfs/etc/mfsmaster.cfg
cp /mfs/etc/mfsexports.cfg.dist /mfs/etc/mfsexports.cfg
cp /mfs/var/mfs/metadata.mfs.empty /mfs/var/mfs/metadata.mfs
主配置文件
vim /mfs/etc/mfsmaster.cfg# WORKING_USER = mfs #运行用户
# WORKING_GROUP = mfs #运行组
# SYSLOG_IDENT = mfsmaster #在syslog中标识自己
# LOCK_MEMORY = 0 #是否执行mlockall()以避免mfsmaster进程溢出(默认为0)
# NICE_LEVEL = -19 #运行的优先级
# EXPORTS_FILENAME = /usr/local/mfs/etc/mfsexports.cfg #目录控制文件路径
# TOPOLOGY_FILENAME = /usr/local/mfs/etc/mfstopology.cfg #拓扑类型文件路径
# DATA_PATH = /usr/local/mfs/var/mfs #数据存放路径(changelog,sessions,stats)
# BACK_LOGS = 50 #元数据的改变日志文件数量
# BACK_META_KEEP_PREVIOUS = 1 #
# REPLICATIONS_DELAY_INIT = 300 #延迟复制时间(300秒)
# REPLICATIONS_DELAY_DISCONNECT = 3600 #ChunkServer断开复制的延迟
# MATOML_LISTEN_HOST = * #元数据日志服务器监听的IP地址(*代表任何IP)
# MATOML_LISTEN_PORT = 9419 #元数据日志服务器监听的端口地址(9419)
# MATOCS_LISTEN_HOST = * #用于ChunkServer连接的IP地址(*代表任何IP)
# MATOCS_LISTEN_PORT = 9420 #用于ChunkServer连接的端口(9420)
# MATOCL_LISTEN_HOST = * #用于客户端连接的地址
# MATOCL_LISTEN_PORT = 9421 #用于客户端连接的端口
# CHUNKS_LOOP_CPS = 100000
# CHUNKS_LOOP_TIME = 300 #Chunks回环频率
# CHUNKS_SOFT_DEL_LIMIT = 10
# CHUNKS_HARD_DEL_LIMIT = 25
# CHUNKS_WRITE_REP_LIMIT = 2 #在一个循环里复制到一个ChunkServer的最大Chunks数目
# CHUNKS_READ_REP_LIMIT = 10
# REJECT_OLD_CLIENTS = 0 #弹出低于1.6.0客户端的连接
目录挂载控制文件
vim /mfs/etc/mfsexports.cfg #分为三个部分,无需修改* . rw
* / rw,alldirs,maproot=0
客户端IP 被挂载目录 客户端拥有的权限
为MasterServer提供lsb格式启动脚本
cat /etc/init.d/mfsmaster# chkconfig: 345 91 10
# description: mfs start.
. /etc/rc.d/init.d/functions
. /etc/sysconfig/network
path="/mfs/sbin"
[ "${NETWORKING}" = "no" ] && exit 0
start() {
$path/mfsmaster start
$path/mfscgiserv start
}
stop() {
$path/mfsmaster stop
$path/mfscgiserv start
}
restart() {
$path/mfsmaster restart
$path/mfscgiserv restart
}
status() {
$path/mfsmaster test
$path/mfscgiserv test
}
case "$1" in
start)
start
;;
stop)
stop
;;
restart)
restart
;;
status)
status
;;
*)
echo $"Usage: $0 start|stop|restart|status"
exit 1
esac
exit 0
修改权限
chmod 755 /etc/init.d/mfsmaster导出命令
echo 'export PATH=$PATH:/mfs/sbin' > /etc/profile.d/mfs.sh. /etc/profile.d/mfs.sh
同步启动脚本至从节点
scp -p /etc/init.d/mfsmaster two:/etc/init.d/关闭服务卸载drbd设备
service mfsmaster stopumount /dev/drbd1
部署Corosync+Pacemaker
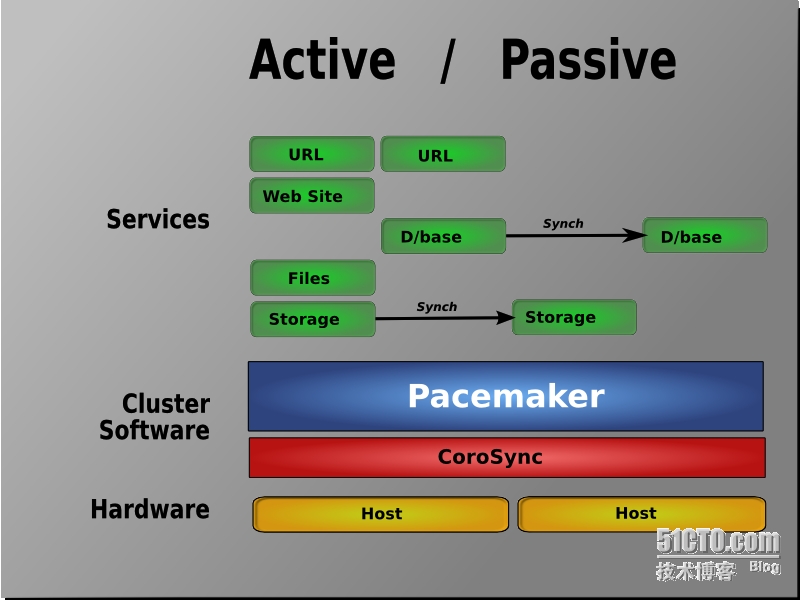
Corosync是集群管理套件的一部分,它在传递信息的时候可以通过一个简单的配置文件来定义信息传递的方式和协议等,RHCS集群套件就是基于corosync实现。但corosync只提供了message layer的能力。集群的资源管理则需要Pacemaker,其管理接口有两个分别是crmsh和pcs。
环境准备
service NetworkManager stop
时间同
主机名称解析的结果等于uname -n
安装(pacemaker作为corosync的插件运行)
yum install -y corosync pacemaker资源管理器配置接口基于crmsh
yum install -y crmsh-1.2.6-4.el6.x86_64.rpm pssh-2.3.1-2.el6.x86_64.rpm生成密钥
corosync-keygencp /etc/corosync/corosync.conf.example /etc/corosync/corosync.conf
配置文件
vim /etc/corosync/corosync.conf #添加pacemaker插件compatibility: whitetank #是否兼容0.8版本的corosync
totem { #用来定义集群节点心跳信息传递
version: 2 #版本号
secauth: on #启用安全认证机制
threads: 0 #启用多少线程完成心跳信息传递
interface { #定义心跳信息传递的接口
ringnumber: 0 #避免循环转发心跳信息
bindnetaddr: 192.168.2.0 #指定网卡的网络地址
mcastaddr: 226.194.61.21 #心跳信息使用的组播地址
mcastport: 5405 #组播监听端口
ttl: 1
}
}
logging { #心跳信息层日志
fileline: off #
to_stderr: no #是否把错误信息发往屏幕
to_logfile: yes #使用自定义日志文件logfile
to_syslog: no #是否记录到系统日志
logfile: /var/log/cluster/corosync.log
debug: off #调试功能
timestamp: on #每次记录心跳信息是否记录时间戳
logger_subsys {
subsys: AMF
debug: off
}
}
amf {
mode: disabled
}
service { #添加pacemaker插件
ver: 0
name: pacemaker
}
aisexec { #可省略
user: root
group: root
}
复制配置文件到其他节点
scp -p /etc/corosync/corosync.conf /etc/corosync/authkey two.soulboy.com:/etc/corosync/分别在两节点启动corosync服务
service corosync start使用crmsh接口定义drbd资源(忽略法定票数、禁用stonith设备)
crm(live)configure# property no-quorum-policy=ignorecrm(live)configure# property stonith-enabled=false
定义原始资源
crm(live)configure# primitive mfs_drbd ocf:linbit:drbd params drbd_resource=mfs op monitor role=Master interval=10 timeout=20 op monitor role=Slave interval=20 timeout=20 op start timeout=240 op stop timeout=100 #定义drbd资源crm(live)configure# ms ms_mfs_drbd mfs_drbd meta master-max="1" master-node-max="1" clone-max="2" clone-node-max="1" notify="true" #定义drbd的克隆资源、克隆属性
crm(live)configure# primitive mfsstore ocf:heartbeat:Filesystem params device="/dev/drbd1" directory="/mfs" fstype="ext4" op monitor interval=40 timeout=40 op start timeout=60 op stop timeout=60 #定义本地挂载资源
crm(live)configure# primitive mfsip ocf:heartbeat:IPaddr params ip="192.168.1.40" op monitor interval=20 timeout=20 on-fail=restart #定义vip
crm(live)configure# primitive mfsserver lsb:mfsmaster #定义mfs服务
定义colocation约束(资源运行在同一个节点上的偏好)
crm(live)configure# colocation mfsstore_with_ms_mfs_drbd_master inf: mfsstore ms_mfs_drbd:Master #挂载资源追随drbd主资源在一起crm(live)configure# colocation mfsserver_with_mfsstore inf: mfsserver mfsstore #mfs服务追随挂载资源
crm(live)configure# colocation mfsip_with_mfsserver inf: mfsip mfsserver #vip追随mfs服务
定义资源组(如果定义了资源组就没有必要定义colocation约束了)
crm(live)configure# group ha_mfsservice mfsstore mfsserver mfsip #本文没有这样做,但特此说明这样做也是可以的定义order约束(资源启动和关闭的次序)
crm(live)configure# order ms_mfs_drbd_before_mfsstore mandatory: ms_mfs_drbd:promote mfsstore:start #节点上存在drbdMaster才能启动mystore服务crm(live)configure# order mfsstore_before_mfsserver mandatory: mfsstore:start mfsserver:start #mystore服务启动才能启动mfs服务
crm(live)configure# order mfsip_before_mfsserver mandatory: mfsip mfsserver #vip启动才能启动mfs服务
定义location约束(资源对节点的倾向性)
location mfsservice_prefer_one ha_mfsservice 500: one.soulboy.com #主节点从故障中回复是否可以将资源抢夺回来,本文没有这样做,特此说明这样做是可以完成资源抢占的。检查语法并保存
crm(live)configure# verifycrm(live)configure# commit
查看集群状态(发现资源都运行在主节点上)
[root@one packages]# crmcrm(live)# status
Online: [ one.soulboy.com two.soulboy.com ]
Master/Slave Set: ms_mfs_drbd [mfs_drbd]
Masters: [ one.soulboy.com ]
Slaves: [ two.soulboy.com ]
mfsstore (ocf::heartbeat:Filesystem): Started one.soulboy.com
mfsserver (lsb:mfsmaster): Started one.soulboy.com
mfsip (ocf::heartbeat:IPaddr): Started one.soulboy.com
查看验证
[root@one ~]# drbd-overview #drbd资源正常1:mfs/0 Connected Primary/Secondary UpToDate/UpToDate C r----- /mfs ext4 5.0G 142M 4.6G 3%
[root@one ~]# service mfsmaster status #mfs资源正常
mfsmaster pid: 13966
mfscgiserv pid:14158
[root@one ~]# ip addr show | grep 192.168.1.40 #vip资源正常
inet 192.168.1.40/24 brd 192.168.1.255 scope global secondary eth0
[root@one ~]# ls /mfs #挂载资源正常
etc lost+found sbin share var
故障模拟测试
安装ChunkServer
useradd mfs -s /sbin/nologintar xf mfs-1.6.26.tar.gz
cd mfs-1.6.26
./configure --prefix=/usr/local/mfs --with-default-user=mfs --with-default-group=mfs
make && make install
cp /usr/local/mfs/etc/mfschunkserver.cfg.dist /usr/local/mfs/etc/mfschunkserver.cfg
cp /usr/local/mfs/etc/mfshdd.cfg.dist /usr/local/mfs/etc/mfshdd.cfg
主配置文件
vim /usr/local/mfs/etc/mfschunkserver.cfg# WORKING_USER = mfs
# WORKING_GROUP = mfs
# SYSLOG_IDENT = mfschunkserver
# LOCK_MEMORY = 0
# NICE_LEVEL = -19
# DATA_PATH = /usr/local/mfs/var/mfs
# MASTER_RECONNECTION_DELAY = 5
# BIND_HOST = *
MASTER_HOST = 192.168.1.40 #元数据服务器的地址
MASTER_PORT = 9420 #元数据服务器监听端口
# MASTER_TIMEOUT = 60
# CSSERV_LISTEN_HOST = *
# CSSERV_LISTEN_PORT = 9422 #此端口用户和其他ChunkServer间复制数据
# HDD_CONF_FILENAME = /usr/local/mfs/etc/mfshdd.cfg #分配给MFS磁盘使用空间配置文件路径
# HDD_TEST_FREQ = 10
# LOCK_FILE = /var/run/mfs/mfschunkserver.lock
# BACK_LOGS = 50
# CSSERV_TIMEOUT = 5
磁盘空间配置文件
vim /usr/local/mfs/etc/mfshdd.cfg/data #/data是一个MFS的分区,实例化为本机一个独立的磁盘挂载分区。
修改权限并启动服务
chown -R mfs:mfs /datamfschunkserver start
Client编译安装
MFS客户端依赖于fuse
tar xf fuse-2.9.2.tar.gzcd fuse-2.9.2
./configure
make && make install
vim /etc/profile #在最后添加
export PKG_CONFIG_PATH=/usr/local/lib/pkgconfig:$PKG_CONFIG_PATH
source /etc/profile #即时生效
export PKG_CONFIG_PATH=/usr/local/lib/pkgconfig:$PKG_CONFIG_PATH
安装MFS客户端
useradd mfs -s /sbin/nologintar xf mfs-1.6.26.tar.gz
cd mfs-1.6.26
./configure --prefix=/usr/local/mfs --with-default-user=mfs --with-default-group=mfs --enable-mfsmount
make && make install
modprobe fuse #加载fuse到内核
挂载MFS文件系统
mkdir /webdata #创建本地目录作为挂载点/usr/local/mfs/bin/mfsmount /webdata -H 192.168.1.40 #挂载MFS到本地/webdata目录
挂载MFSMeta文件系统
mkdir /webdatameta #创建本地MFSMeta目录/usr/local/mfs/bin/mfsmount -m /webdatameta -H 192.168.1.40 #挂载MFSMeta文件系统
client创建文件并查看信息(正常)
[root@five /]# echo "123" > /webdata/one #创建文件[root@five /]# mfsfileinfo /webdata/one #查看副本和存储节点
/webdata/one:
chunk 0: 0000000000000006_00000001 / (id:6 ver:1)
copy 1: 192.168.1.50:9422
copy 2: 192.168.1.64:9422
登录web管理控制台(正常)
模拟主节点故障
crm(live)node# standby #离线,等待几秒钟crm(live)node# online #上线
crm(live)node# cd #回退
crm(live)# status #查看集群资源状态
Online: [ one.soulboy.com two.soulboy.com ]
Master/Slave Set: ms_mfs_drbd [mfs_drbd]
Masters: [ two.soulboy.com ]
Slaves: [ one.soulboy.com ]
mfsstore (ocf::heartbeat:Filesystem): Started two.soulboy.com
mfsserver (lsb:mfsmaster): Started two.soulboy.com
mfsip (ocf::heartbeat:IPaddr): Started two.soulboy.com
client再次创建文件并查看副本数(正常)
[root@five /]# echo "123" > /webdata/two[root@five /]# mfsfileinfo /webdata/two
/webdata/two:
chunk 0: 0000000000000007_00000001 / (id:7 ver:1)
copy 1: 192.168.1.50:9422
copy 2: 192.168.1.64:9422
再次登录web管理控制台(正常)
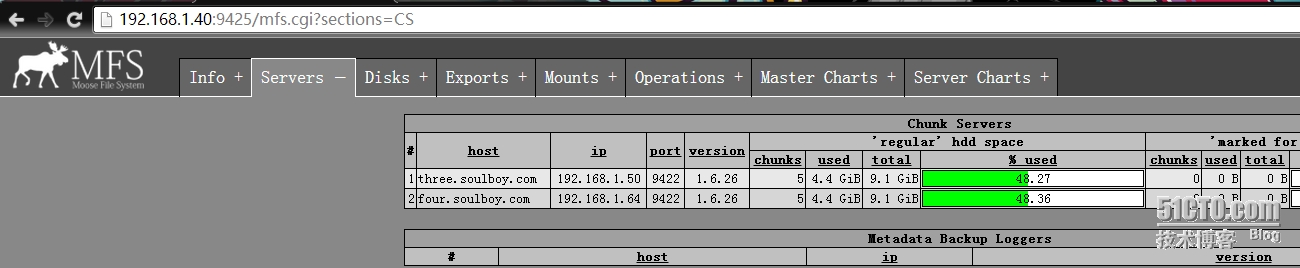
补充和总结
解决MFS单点故障的主要思路是将MasterServer安装在drbd设备目录中,通过corosync+pacemaker将drbd、vip、mount、mfsmaster资源粘合在一起,并通过colocation和order的约束保证了资源间依赖关系和启动次序,此外mfsmaster的启动在pacemaker中定义为lsb风格RA,也就是形如/etc/init.d/目录下的sysv风格的脚本。值得一提的是pacemaker的管理接口,本文中使用的是crmsh,而pcs接口有着比crmsh更强大的功能,可以实现管理集群整个生命周期,支持节点的添加、移除、启动、关闭等操作。
实现mysql的高可用也可以通过本文这种思路实现,具体步骤可参考本文,这里补充下pcs接口的用法,方便读者做对比。
pcs resource create myvip ocf:heartbeat:IPaddr params ip=192.168.1.70 op monitor interval=20 timeout=20 on-fail=restart #定义vippcs resource create mystore ocf:heartbeat:Filesystem params device="192.168.1.50:/mysqldata" directory="/mydata" fstype="nfs" op monitor interval=40 timeout=40 on-fail=restart op start timeout=60 op stop timeout=60 #定义nfs
pcs resource create mysqlserver lsb:mysqld op monitor interval=20 timeout=20 on-fail=restart #定义httpd
pcs resource group add mysqlservice myvip mystore mysqlserver #定义webservice资源组
pcs constraint location mysqlservice prefers two.soulboy.com=500 #定义资源倾向性,资源组webservice对节点二的倾向性为500
pcs constraint order start myvip then start mystore #定义资源的order执行次序,这个貌似不能一下子定义三个资源月约束
pcs constraint order start mystore then start mysqlserver #定义资源的order执行次序
pcs constraint colocation add myvip mystore #定义colocation,如果有资源组可以省略。这个貌似不能一次定义三个资源月约束
pcs constraint colocation add mystore mysqlserver #定义colocation
实现mfs的高可用也可以通过heartbeat+drbd来实现,思路和本文类似,已经大牛撰写,文章内容优质,请参考: qzhijun的BLOG
海量小文件存储利器Mogilefs
#######################################################################
-
数据存储的趋势和大数据带来的挑战
-
分布式存储与CAP定理
-
分布式存储文件系统
-
Mogilefs基本原理
-
Mogilefs实现
-
Nginx反向代理Tracker节点
#######################################################################
数据存储的趋势和大数据带来的挑战
当下我们处在一个互联网飞速发展的信息社会,在海量并发连接的驱动下每天所产生的数据量必然以几何方式增长,随着信息连接方式日益多样化,数据存储的结构也随着发生了变化。在这样的压力下使得人们不得不重新审视大量数据的存储所带来的挑战,例如:数据采集、数据存储、数据搜索、数据共享、数据传输、数据分析、数据可视化等一系列问题。
传统存储在面对海量数据存储表现出的力不从心已经是不争的事实,例如:纵向扩展受阵列空间限制、横向扩展受交换设备限制、节点受文件系统限制。
然而分布式存储的出现在一定程度上有效的缓解了这一问题,之所以称之为缓解是因为分布式存储在面对海量数据存储时也并非十全十美毫无压力,依然存在的难点与挑战例如:节点间通信、数据存储、数据空间平衡、容错、文件系统支持等一系列问题仍处在不断摸索和完善中。
分布式存储与CAP定理
首先要说明的是一个完美分布式系统有三个最重要的元素,他们分别是:
一致性(Consistency):任何一个读操作总是能读取之前完成的写操作。
可用性(Availability):每次操作总是能够在预定时间返回。
分区容错性(Partition Tolerance):在出现网络分区(分布式)的情况下,仍然能够满足一致性和可用性。

2007年,正当所有科学家都在致力于CAP三元素并存的时候,Eric.Brewer教授站了出来并指出CAP永远无法兼顾,只能根据具体应用来权衡和取舍,并且至多两个元素可以共存,后来由两位麻省理工学院的科学家证明此观点是具有前瞻性的,由此形成Brewer的CAP定理。
正所谓鱼和熊掌不可兼得,关注一致性就需要处理因系统不可用而带来写操作失败的情况,反之关注可用性就无法保证每次都能读取到最新的写入操作。传统关系型数据库侧重于CA,而非关系型键值数据库则侧重于AP。
对于大型站点,可用性(Availability)与分区容错性(Partition Tolerance)的优先级会高于一致性(Consistency),这里并不是指完全舍弃一致性,而是通过其他手段实现数据的弱一致性,例如:用户微博的浏览数和评论可以容忍相对长时间的不一致,几乎不会影响用户体验,而股票价格的数据则异常敏感,即便是10秒钟的数据不一致也无法容忍,为了能更形象的了解所谓“各种一致性”需要进行一下内容的回顾。
强一致性(ACID):在单机环境中,强一致性可以由数据库的事务来保证;在分布式环境中,强一致性很难做到,即便是做到也会因为分布式事物所带来的性能低下,不适合在互联网的环境中应用。
弱一致性(包括最终一致性):系统不能保证后续访问返回最新的值,在访问到最新值之前这段时间称之为不一致窗口。
最终一致性:是弱一致性的一种特例,存储系统保证如果对象有多次更新,在渡过不一致窗口之后必将放回最后更新的值。
服务器的一致性:N代表节点的个数;W代表更新的时候需要确认已经被更新的节点个数;R代表读取数据需要的节点数量。
W + R > N ----> 强一致性(通常N=3,W=R=2)
W=N,R=1 ----> 最佳读
W=1,R=N ----> 最佳写
W + R <= N ----> 弱一致性
分布式存储文件系统

Mogilefs基本原理
MogileFS是一个开源的分布式文件系统,用于组建分布式文件集群,由LiveJournal旗下DangaInteractive公司开发,Danga团队开发了包括 Memcached、MogileFS、Perlbal等不错的开源项目:(注:Perlbal是一个强大的Perl写的反向代理服务器)。MogileFS是一个开源的分布式文件系统。主要特性包括:应用层的组件、无单点故障、自动文件复制、具有比RAID更好的可靠性、无需RAID支持等……核心角色如下:
tracker节点:借助数据库保存各节点文件的元数据信息保存每个域中所有键的存储位置分布,方便检索定位数据位置的同时监控各节点,告诉客户端存储区位置并指挥storage节点复制数据副本,进程名为mogilefsd(7001)。
database节点:为tracker节点提供数据存取服务。
storage节点:将指定域中的键转换为其特有的文件名存储在指定的设备文件中,转换后的文件名为值,storage节点自动维护键值的对应关系,storage节点由于使用http进行数据传输,因此依赖于perlbal,storage节点前端可以使用nginx进行反向代理,但需要安装nginx-mogilefs-module-master模块进行名称转换,进程名mogstored(7501),perbal(7500)。
Domain:一个域中的键值是惟一的,一个MogileFS可以有多个域,域可以用来存储不同应用类型的数据的容器。
Host:每一个存储节点称为一个主机,一个主机上可以有多个存储设备(单独的硬盘),每个设备都有ID号,Domain+Fid用来定位文件。
Class:复制最小单位,文件属性管理,定义文件存储在不同设备上份数。
流程图如下:

1、应用层发起GET请求到Nginx。
2、Nginx根据负载均衡机制随机代理到后台Node one。
3、Node one向从服务器发起查询请求。
4、从服务器返回查询结果。
5、Node one将查询结果返回给Nginx。
6、Nginx将查询结果根据模块转换为合理的url方位Node three。
7、Node Three将文件内容通过http协议返回给Nginx。
8、Nginx将结果返回给应用层的请求。
Mogilefs实现
由于各角色和服务之间都是基于套接字通信,就服务本身来说没有耦合性,所以可以使用少量机器运行多种服务角色,功能图如下:

1、通过Nginx+Keepalived实现高可用的负载均衡,通过upstream模块可以有选择性的转发应用层的请求至后端tracker节点。
2、DRBD+Corosync+Pacemaker的机制保证了Mysql的高可用,详细配置请参阅博文:DAS之mysql高可用解决方案。
3、为了进一步提升Mysql的性能引入从节点为其分摊读操作,从节点的数据可以根据具体业务规模来设定,如果使用数据库代理进行读写分离,代理会成为单点故障,则需要为代理做高可用,另外Tracker节点支持手动为其指定从节点,因此可以根据自己的喜好,Mysql代理和复制相关实现请参阅博文:Mysql复制及代理。
安装mariadb
授权
GRANT ALL ON *.* TO 'root'@'%' IDENTIFIED BY 'mypass';
CREATE DATABASE mogilefs;
GRANT ALL ON mogilefs.* TO 'moguser'@'%' IDENTIFIED BY 'mogpass';
FLUSH PRIVILEGES;
##### Tracker节点(可以是所有节点)
安装 mogilefs
修改配置文件如下
vim /etc/mogilefs/mogilefsd.conf
daemonize = 1
pidfile = /var/run/mogilefsd/mogilefsd.pid
db_dsn = DBI:mysql:mogilefs:host=192.168.1.241
db_user = moguser
db_pass = mogpass
listen = 0.0.0.0:7001
conf_port = 7001
query_jobs = 100
delete_jobs = 1
replicate_jobs = 5
reaper_jobs = 1
service mogilefsd start #启动服务
ss -tanlp (LISTEN 0 128 192.168.1.241:7001 )
##### storage节点(可以是所有节点)
安装 mogilefs
mkdir /mogdata/dev1 -pv #创建设备目录
chown -R mogilefs.mogilefs /mogdata/dev2/ #权限
vim /etc/mogilefs/mogstored.conf
maxconns = 10000
httplisten = 0.0.0.0:7500
mgmtlisten = 0.0.0.0:7501
docroot = /mogdata #目录级别
service mogstored start
ss -tanlp (*:7500)
##### tracker节点添加storage节点和常用命令
mogadm check #检测节点
mogadm host list #每个存储节点称为一个host
mogadm host add 192.168.1.213 --ip=192.168.1.213 --ip=192.168.1.213 --status=alive #添加第一个存储节点
mogadm host add 192.168.1.242 --ip=192.168.1.242 --ip=192.168.1.242 --status=alive #添加第一个存储节点
mogadm host add 192.168.1.241 --ip=192.168.1.241 --ip=192.168.1.241 --status=alive #添加第一个存储节点
mogadm device add 192.168.1.213 1 #添加第一个设备,设备号唯一不能重名
mogadm device add 192.168.1.242 2 #添加第二个设备
mogadm device add 192.168.1.241 3 #添加第三个设备
mogadm check #可以查看状态
mogadm domain add files #创建文件存储域
mogadm domain add images #创建图片存储域
mogadm domain list #查看所有域
mogupload --trackers=192.168.1.241 --domain=files --key='/fstab' --file='/etc/fstab' #上传fstab文件,key为'/fstab'
mogfileinfo --trackers=192.168.1.241 --domain=files --key='/fstab' #根据key查看文件存放信息
注释:mogupload工具是为了测试,实际环境中上传是由程序员在代码中使用mogilefs的API进行交互。

Nginx反向代理Tracker节点
##### 配置Nginx安装tng
yum install pcre-devel -y
yum groupinstall "Development Tools" "Server Platform Development"
yum install libxslt-devel gd-devel lua-devel geoip-devel
tengine-1.5.1.tar.gz
nginx-mogilefs-module-master.zip #mogilefs模块需要打补丁
mkdir -pv /var/tmp/nginx/client #模块需要
unzip nginx-mogilefs-module-master.zip
useradd -r nginx
./configure \
--prefix=/usr/local/nginx \
--sbin-path=/usr/local/nginx/sbin/nginx \
--conf-path=/etc/nginx/nginx.conf \
--error-log-path=/var/log/nginx/error.log \
--http-log-path=/var/log/nginx/access.log \
--pid-path=/var/run/nginx/nginx.pid \
--lock-path=/var/lock/nginx.lock \
--user=nginx \
--group=nginx \
--enable-mods-shared=all \
--add-module=/nginx-mogilefs-module-master
make && make install
vim /etc/profile.d/nginx.sh
export PATH=/usr/local/nginx/sbin:$PATH
. !$
提供脚本.....
配置nginx
vim /etc/nginx/nginx.cfg
upstream trackers {
server 192.168.1.242:7001 weight=1;
server 192.168.1.213:7001 weight=1;
server 192.168.1.241:7001 backup;
check interval=3000 rise=2 fall=5 timeout=1000;
check_http_send "GET / HTTP/1.0\r\n\r\n";
check_http_expect_alive http_2xx http_3xx;
}
location /jpg/ {
mogilefs_tracker trackers;
mogilefs_domain images;
mogilefs_methods GET;
mogilefs_pass {
proxy_pass $mogilefs_path;
proxy_hide_header Content-Type;
proxy_buffering off;
}
}
##### 配置keepalived
安装keepalived
vim /etc/keepalived/keepalived.conf # backup priority 99
global_defs {
notification_email {
root@localhost
}
notification_email_from admin@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id LTT
}
vrrp_script chk_nginx {
script "killall -0 nginx"
interval 1
weight -2
fall 2
rise 1
}
vrrp_instance IN_1 {
state MASTER
interface eth0
virtual_router_id 22
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass aaaa
}
virtual_ipaddress {
192.168.1.222
}
track_script {
chk_nginx
}
}
查看负载节点:

模拟GET方法测试Nginx_mogilefs模块:

SAN之可扩展的集群共享存储
###############################
SCSI
SAN
ISCSI
SAN和NAS的对比
ISCSI+gfs2+cLVM的实现
###############################
SCSI
计算机体系结构

-
CPU:核心组件,负责从memory中读取数据并进行处理。
-
Memory:核心组件,通过北桥与外围存储设备进行交换,作为易失性存储有极高的存储效率,但断电后数据会丢失。
-
IDE:有限的接口上,能够连接的设备有限,IDE的控制器在数据传输过程中的协议封装能力很差,整个传输过程需要大量CPU时钟周期的参与,这就意味着CPU要花费大量的时候完成数据的读入和写出,在业务处理比较繁忙和CPU资源极尤为重要的场合下是无法忍受的。
-
SCSI:是一种I/O技术,SCSI规范了一种并行的I/O总线和相关的协议,除了硬盘转速上的提升外,总线的适配器HBA(HostBusAdapter)卡中内置了控制芯片,此控制芯片可以完成协议的封装,可以大量降低CPU的参与,此外由于SCSI的数据传输是以块的方式进行的,因此它具有以下特点:设备无关性、多设备并行、高带宽、低系统开销。
SCSI使用体系结构

-
窄SCSI总线:最多允许8个SCSI设备和它进行连接。
-
宽SCSI总线:最多允许16个不同的SCSI设备和它进行连接
-
SCSI ID:一个独立的SCSI总线按照规格不同可以支持8或16个SCSI设备,设备的编号需要通过SCSI ID(Target)来进行控制,系统中每个SCSI设备都必须有自己唯一的SCSI ID,SCSI ID实际上就是这些设备的地址。
SCSI的局限性

-
传输距离:由于SCSI线缆的长度有限,限制了SCSI的延展性。
-
服务主机:Target数量限制了可服务的主机数。
SAN
-
能够通过非SCSI线缆传输SCSI协议报文,并且能将其路由至目标存储设备的网络成为Storage Area Network(区域存储网络)。

SCSI协议报文

-
Physical Interconnects and Transport Protocols:定义物理传输介质和传输报文格式,通过光信道传输就成为FCSAN,通过IP网络传输就成为IPSAN。
-
Shared Command Set:SCSI共享(公共)命令集,定义存储或读取等相关命令。
-
SCSI Device-Type Specific Command Sets:不同SCSI设备类型特有的命令。
-
Common Access Method:公共访问方法。
ISCSI
IPSAN和FCSAN的对比

-
FCSAN:需要FC的HBA,存储端互相也需要FC的交换机或者SCSI线缆,应用程序存储数据由Adapter Driver向存储网络发起请求并完成数据存取。
-
IPSAN:应用程序的请求先交由SCSI驱动封装(协议报文各种指令),再由ISCSI驱动封装(用于联系ISCSI服务器端),借助于TCP/IP网络发送至ISCSI服务器端。
IPSAN的传输过程


-
ISCSI服务端:通过安装一款成熟的存储管理软件ISCSI Target,也称为Target。
-
ISCSI客户端:可以是硬件,也可以是安装iscsi客户端软,称为Initiator。客户端的连接方式有以下三种:
-
以太网卡+initiator软件:成本低,但需要占用客户端主机部分资源用于ISCSI和TCP/IP协议之间的解析, 适用于低I/O带宽的环境下。
-
硬件TOE网卡+initiator:TOE(TCP Offload Engine)功能的智能以太网卡可以完成ISCSI的封装,但SCSI封装仍以软件方式运作,使得客户端主机可以从繁忙的协议中解脱出来,大幅度提高数据传输速率,降低了客户端主机资源消耗。但TOE功能的网卡,成本较高。
-
ISCSI HBA卡连接:不需要安装客户端软件,全部靠硬件,数据传输性能最好,但成本很高,客户端数量和性价比成反比。
SAN和NAS的对比
注释:由于SAN是在DAS的基础之上增加了延展性,因此下图以DAS作比较:

结论:从图中可以看出NAS的文件系统在服务器端,而SAN的文件系统在客户端,因为SAN的客户端可以实现对分区的创建格式化等操作,而NAS不可以。因此SAN经常配合集群文件系统(gfs2、ocfs)一起使用,为的就是避免多个Initiator对Target的同一资源在同一时刻进行征用带来的脑裂。
ISCSI+gfs2+cLVM的实现
架构图如下:

部署Target端
安装软件包
查看当前磁盘状况(将/dev/sdb2发布出去3GB)
[root@localhost yum.repos.d]# fdisk -lDisk /dev/sdb: 21.4 GB, 21474836480 bytes
255 heads, 63 sectors/track, 2610 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/sdb1 1 1217 9775521 83 Linux
/dev/sdb2 1218 1583 2939895 83 Linux
常用配置
/etc/tgt/targets.conf 配置文件的方式来管理target/etc/sbin/tgt-admin 通过配置文件定义
/usr/sbin/tgtadm 通过命令行的方式管来target
service tgtd start 启动服务
编辑配置文件vim /etc/tgt/targets.conf
<target iqn.2013-08.com.soulboy:sdb1>backing-store /dev/sdb2
initator-address 192.168.1.0/24
</target>
启动服务
命令行方式配置
tgtadm --lld iscsi --mode logicalunit --op new --tid 2 --lun 1 --backing-store /dev/sdb2tgtadm --lld iscsi --mode target --op bind --tid 2 --initiator-address 192.168.1.0/24
部署各节点
安装软件包
确保个节点hosts文件和hostname为如下
[root@node3 ~]# cat /etc/hosts192.168.1.21 node1.soulboy.com node1
192.168.1.22 node2.soulboy.com node2
192.168.1.23 node3.soulboy.com node3
各节点时间同步
ntpdate 192.168.1.101集群逻辑卷 cLVM共享存储做成LVM,借用HA的机制,让多个节点可以同时对一个卷发起管理操作。
vim /etc/lvm/lvm.conflocking_type = 3
定义集群名称
ccs_tool create tcluster添加fence设备
ccs_tool addfence meatware fence_manual添加集群成员
ccs_tool addnode -v 1 -n 1 -f meatware node1.soulboy.comccs_tool addnode -v 1 -n 2 -f meatware node2.soulboy.com
ccs_tool addnode -v 1 -n 3 -f meatware node3.soulboy.com
在各节点依次启动服务
service cman startservice rgmanager start
查看各节点信息
[root@node3 ~]# ccs_tool lsnodeCluster name: tcluster, config_version: 7
Nodename Votes Nodeid Fencetype
node1.soulboy.com 1 1
node2.soulboy.com 1 2
node3.soulboy.com
各节点安装initator配置并启动服务
yum --nogpgcheck localinstall iscsi-initiator-utils-6.2.0.872-16.el5.i386.rpmservice iscsi start 启动服务
各节点客户端执行发现和登陆操作
[root@localhost mydata]# iscsiadm -m discovery -t sendtargets -p 192.168.1.50192.168.1.50:3260,1 iqn.2013-08.com.soulboy:sdb1
192.168.1.50:3260,1 iqn.2013-08.com.soulboy:sdb2
[root@localhost mydata]# iscsiadm -m node -T iqn.2013-08.com.soulboy:sdb2 -p 192.168.1.50 -l
在任意initator上对共享设备创建分区(各节点在本地识别成sdc)
fdisk /dev/sdc在其他节点上执行
partprobe /dev/sdb在节点三创建物理卷
[root@node3 ~]# pvcreate /dev/sdc在节点二使用pvs命令查看
[root@node2 ~]# pvsPV VG Fmt Attr PSize PFree
/dev/sda2 VolGroup00 lvm2 a-- 19.88G 0
/dev/sdc lvm2 a-- 2.80G 2.80G
在节点三创建创建卷组
[root@node3 ~]# vgcreate clustervg /dev/sdc在节点二使用vgs命令查看
[root@node2]# vgsVG #PV #LV #SN Attr VSize VFree
VolGroup00 1 2 0 wz--n- 19.88G 0
clustervg 1 1 0 wz--nc 2.80G 2.80G
在节点二创建逻辑卷
[root@node2]# lvcreate -L 1G -n clusterlv clustervg在节点三使用lvs命令查看
[root@node3 ~]# lvsLV VG Attr LSize Origin Snap% Move Log Copy% Convert
LogVol00 VolGroup00 -wi-ao 17.88G
LogVol01 VolGroup00 -wi-ao 2.00G
clusterlv clustervg -wi-a- 1.00G
在集群逻辑上使用集群文件系统(暂时先创建2个日志区域,加入两个节点)
mkfs.gfs2 -j 2 -p lock_dlm -t tcluster:lktb1 /dev/clustervg/clusterlv各节点创建/mydata目录
mkdir /mydata各节点挂载逻辑卷clustervg至本地/mydata目录中
mount -t gfs2 /dev/clustervg/clusterlv /mydata查看信息
[root@node3 ~]# gfs2_tool df /mydata/mydata:
SB lock proto = "lock_dlm"
SB lock table = "tcluster:lktb1"
SB ondisk format = 1801
SB multihost format = 1900
Block size = 4096
Journals = 2
Resource Groups = 8
Mounted lock proto = "lock_dlm"
Mounted lock table = "tcluster:lktb1"
Mounted host data = "jid=1:id=196610:first=0"
Journal number = 1
Lock module flags = 0
Local flocks = FALSE
Local caching = FALSE
Type Total Blocks Used Blocks Free Blocks use%
------------------------------------------------------------------------
data 524196 66195 458001 13%
inodes 458018 17 458001 0%
补充
#####立刻同步到磁盘gfs2_tool settune /mydata new_files_directio 1
#####默认是60秒,日志刷新次数
log_flush_secs = 60
#####扩展逻辑卷物理边界至2GB(可以指定选项,不指默认就是扩展全部)
lvextend -L 2G /dev/clustervg/clusterlv
mount -t gfs2 /dev/clustervg/clusterlv /mnt
#####扩展逻辑卷逻辑编辑至2GB
gfs2_grow /dev/clustervg/clusterlv
#####磁盘检测命令
fsck.gfs2
#####冻结gfs文件系统(只能读,不能写)
gfs2_tool freeze /mydata
#####解冻,备份数据的时候可以用到。
gfs2_tool unfreeze /mydata
注释:扩展卷组需要iSCSI添加新的设备,和使用LVM一样创建PV,添加入卷组即可不在演示过程。
测试
节点二
/mydata
[root@node2 mydata]# ls
[root@node2 mydata]# touch node2
[root@node2 mydata]# ls
node2
节点三
[root@node3 mydata]# pwd/mydata
[root@node3 mydata]# ls
node2
[root@node3 mydata]# rm -rf node2
节点二
[root@node2 mydata]# pwd/mydata
[root@node2 mydata]# ls
NAS之mysql高可用解决方案
###############################################
NAS
高可用集群
hearbeat v2、crm、NFS实现MySQL高可用集群
NFS作为共享存储所存在的问题
###############################################
NAS
-
(NetworkAttachedStorage):网络附属存储是一种将分布、独立的数据整合为大型、集中化管理的数据中心,以便于对不同主机和应用服务器进行访问的技术。它通过网络交换机连接存储系统和服务器,建立专门用于数据存储的私有网络,用户通过TCP/IP协议访问数据,采用业界标准的文件共享协议如:NFS、HTTP、CIFS来实现基于文件级的数据共享,NAS存储使文件共享访问变的快捷方便,并且易增加存储空间。但NAS本身也有一定的局限性,它会受到网络带宽和网络拥堵的影响,在一定程度上限制了NAS的网络传输能力。
-
NAS的优点:NAS具备文件操作和管理系统,kernel的存在有效解决多个进程在同一时间对同一资源征用带来的数据崩溃(脑裂split-brain);NAS是共享与独享兼顾的数据存储池并且简单灵活创建成本不高。
-
NAS的缺点:NAS本身将会受到网络带宽和网络拥堵的影响;文件级别的数据共享在一定程度上会影响效率。
高可用集群
-
高可用集群,英文原文为High Availability Cluster,简称HA Cluster,简单的说,集群(cluster)就是一组计算机,它们作为一个整体向用户提供一组网络资源。这些单个的计算机系统 就是集群的节点(node)。只有两个节点的高可用集群又称为双机热备,即使用两台服务器互相备份。当一台服务器出现故障时,可由另一台服务器承担服务任务,从而在不需要人工干预的 情况下,自动保证系统能持续对外提供服务。双机热备只是高可用集群的一种,高可用集群系统更可以支持两个以上的节点,提供比双机热备更多、更高级的功能, 更能满足用户不断出现的需求变化,逻辑结构图如下:

-
ccm(Cluster Consensus Menbership Service):监听节点间心跳信息并计算整个集群的票数和收敛状态信息。
-
crmd(Cluster Resource Manager):集群资源管理器实现了资源的分配,资源分配的每个动作都要通过crm来实现,是核心组建,每个节点上的crm都维护一个cib用来定义资源特定的属性,哪些资源定义在同一个节点上。
-
cib(Cluster Infonation Base):集群信息基库是XML格式的配置文件,在内存中的一个XML格式的集群资源的配置文件。
-
lrmd(Local Resource Manager):本地资源管理器用来获取本地某个资源的状态,并且实现本地资源的管理。
-
pengine:PE、TE
-
PE(Policy Engine):策略引擎负责计算集群资源的粘性
-
TE(Transition Engine):事务引擎根据PE计算结果指挥节点进行资源转移
-
stonithd(Shoot The Other Node in the Head):切断故障节点电源。
Messagin Layer软件
-
heartbeat
-
corosync
-
cman
-
keepalived
-
ultramokey
Cluster Resource Manager Layer软件
-
crm
-
pacemaker
-
rgmanager
HA常用组合
-
heartbeat v2+crm
-
heartbeat v3+pacemaker
-
corosync+pacemaker
-
cman + rgmanager
-
keepalived+lvs
hearbeat v2、crm、NFS实现MySQL高可用集群
-
网络结构图如下:

注释:节点1和节点2上运行着HA软件和mysql服务,数据目录在NFS服务器端/mydata目录下,通过HA软件的实时监控可以完成节点故障时资源的自动转移,对于客户端来说VIP表征着mysql服务,并持久可用。
必备条件
-
节点名称必须跟uname -n命令的执行结果一致
-
节点名称和IP对应关系保存在/etc/hosts文件,不依赖于DNS
-
各节点ssh互信通信
-
集群各节点时间需要同步
hostname node1.soulboy.com
vim /etc/sysconfig/network
HOSTNAME=node1.soulboy.com
######修改hosts文件
vim /etc/hosts
192.168.1.131 node1.soulboy.com node1
192.168.1.132 node2.soulboy.com node2
######各节点ssh互信,节点二不再演示
ssh-keygen -t rsa -f ~/.ssh/id_rsa -P ''
ssh-copy-id -i .ssh/id_rsa.pub root@192.168.1.132
######各节点时间同步,需要时间服务器配合crontab
* */5 * * * ntpdate 192.168.1.100
部署HA软件
######各节点安装软件包yum --nogpgcheck localinstall heartbeat-2.1.4-9.el5.i386.rpm heartbeat-gui-2.1.4-9.el5.i386.rpm heartbeat-pils-2.1.4-10.el5.i386.rpm heartbeat-stonith-2.1.4-10.el5.i386.rpm libnet-1.1.4-3.el5.i386.rpm perl-MailTools-1.77-1.el5.noarch.rpm
######各节点提供配置文件
cp /usr/share/doc/heartbeat-2.1.4/{authkeys,ha.cf,haresources} /etc/ha.d/
chmod 600 /etc/ha.d/authkeys
######修改密钥文件authkeys
dd if=/dev/random count=1 bs=512 | md5sum 生成随机数
vim /etc/ha.d/authkeys
auth 1
1 md5 b20f227f85d8f51f76f9feec992061ed
######各节点修改核心配置文件
vim /etc/ha.d/ha.cf
mcast eth0 225.0.100.20 694 1 0 组播
node node1.soulboy.com
node node2.soulboy.com
crm respawn crm从此代替haresources,并实现CRM功能
######复制node1秘钥文件到node2
scp /etc/ha.d/authkeys node2:/etc/ha.d/ -P 复制到node2
######各节点启动服务
service hearbeat start

部署NFS服务器
partprobe /dev/sdbpvcreate /dev/sdb1
vgcreate myvg /dev/sdb1
lvcreate -L 6G -n mydata myvg
mke2fs -j /dev/myvg/mydata
groupadd -g 3306 mysql 添加mysql用户组
useradd -u 3306 -g mysql -s /sbin/nologin -M mysql
mkdir /mydata 创建共享目录
vim /etc/fstab 开机自动挂载
/dev/myvg/mydata /mydata ext3 defaults 0 0
mount -a 挂载
mkdir /mydata/data 创建数据目录
chown -R mysql.mysql /mydata/data/ 修改目录为mysql用户
vim /etc/exports
/mydata 192.168.1.0/24(no_root_squash,rw) 修改共享权限
exportfs -arv
部署mysql服务
######各节点停止heartbeat服务service heartbeat stop
######创建mysql用户和组
groupadd -g 3306 mysql
useradd -g 3306 -u 3306 -s /sbin/nologin -M mysql
mkdir /mydata
mount 192.168.1.230:/mydata /mydata 挂载目录
usermod -s /bin/bash mysql 测试是否可写
su - mysql
touch /mydata/data/a
rm /mydata/data/a
logout
usermod -s /sbin/nologin mysql
umount /mydata 测试正常
#####在节点一上安装mysql
tar xf mysql-5.5.28-linux2.6-i686.tar.gz -C /usr/local/
ln -sv /usr/local/mysql-5.5.28-linux2.6-i686 /usr/local/mysql
chown -R root:mysql /usr/local/mysql/*
mount 192.168.1.230:/mydata /mydata 挂载NFS共享目录到本地mydata目录
#####初始化mysql
/usr/local/mysql 切换目录
scripts/mysql_install_db --user=mysql --datadir=/mydata/data/ 初始化
#####修改相关配置文件
cp /usr/local/mysql/support-files/my-large.cnf /etc/my.cnf
vim /etc/my.cnf
datadir = /mydata/data
innodb_file_per_table = 1 表空间独立
cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqld
chkconfig --add mysqld
chkconfig mysqld off 禁止开机自启动
service mysqld start 启动服务
/usr/local/mysql/bin/mysql 客户端工具
######为Mysql授权远程用户
/usr/local/mysql/bin/mysql
mysql> GRANT ALL ON *.* to 'root'@'%' IDENTIFIED BY 'redhat';
mysql> FLUSH PRIVILEGES;
mysql> create database testdb;
mysql> use testdb
mysql> create table student (id int unsigned not null auto_increment primary key, name char(20));
######停止服务卸载目录
service mysqld stop 关闭mysql服务
umount /mydata 卸载mydata目录
######同步配置文件和启动脚本到node2
cp /etc/my.cnf node2:/etc/
scp /etc/init.d/mysqld node2:/etc/init.d/
######为node2创建/mydata目录
mkdir /mydata
使用crm定义资源
######配置GUI登陆账户密码passwd hacluster
######打开GUI登陆窗口(请确保连接DC)
hb_gui &
1、登陆crm

2、定义资源组

3、定义VIP

4、定义NFS存储

5、定义mysql服务

6、启动资源组

7、查看资源已运行在node2上

8、使用客户端登陆测试

模拟故障测试HA功能是否生效
1、资源组此时运行在node2节点,node1并无任何资源,此时让node2变为standy。

2、crm显示所有资源已成功转移至node1

3、切换至node1端验证真实性

4、mysql客户端第二次查询

crm的补充(关于资源约束)

location: 资源对节点的倾向程度,同一节点所有资源(进程)之和。
caloation:资源间互斥性,两个资源倾向于在一起还是分开。
order: 资源采取动作的次序。
NFS作为共享存储所存在的问题
-
单点故障的问题显而易见
Network File System
#####################################
Local Procedure Call为开发带来的不便
Remote Procedure Call的引入
Network File System
NFS在LAMP架构下的应用
#####################################
Local Procedure Call为开发带来的不便
本地两个进程或进程和内核之间调用函数完成某种功能的过程叫做本地过程调用。

Remote Procedure Call的引入
远程过程调用,不同主机上的两个进程直接依赖于二进制协议通信,它是编程技术及协议,简化分布式应用程序的开发,它一种开发框架,在这种框架下,程序员开发程序无需再考虑网络报文的封装,有RPC底层机制负责完成,RPC本身只是一种协议,它的实现是Portmap。
 Network File System
Network File System
一、NFS简介
和ext3、ext2等一样,也位于内核空间作为内核模块工作的,它基于RPC基础实现,不同主机上的两个进程直接依赖于二进制协议通信,它可以让远程文件系统挂载到本地一个目录。nfs-utils是NFS的安装包,包含了三个主进程:
nfsd (文件传输主进程) 固定端口为TCP/UDP 2049端口
mountd (接收客户端挂载请求) 动态向portmap注册端口
quotad (磁盘配额进程) 动态向portmap注册端口
/etc/exports 主配置文件

注意:由于nfs是基于RCP协议实现,所以请确保portmap服务开启
二、NFS工作机制

三、NFS使用方法
文件系统导出属性
ro 只读rw 读写
sync 同步
async 异步
root_squach 将root用户映射为来宾账号
no_root_squach 非常不安全,客户端管理员此时等于服务器端管理员权限。
all_squash 把用户全部映射为来宾用户,最安全
anonuid,anongid 指定映射的来宾账号UID和GID
简单的通过映射用户ID来标识文件属主和属组,客户端只要有用户ID号跟服务器端一样,就可以具有相应权限,相当不安全,因此通常可以把一个目录或文件锁定为一个服务器端能控制的用户,而所有用户的权限等于此用户的权限,例如:
NFS服务端useradd-u 510 nfstest
touch/shared/nfstest
chownnfstest.nfstest /shared/nfstest
vim /etc/exports 修改主配置文件
/shared192.168.1.0/24(rw,all_squash,anonuid=510,anongid=510)
exportfs -ra
客户端重新挂载并看结果

showmount命令
mount-t nfs 192.168.1.30:/shared/tmp/nfs 挂载远程NFS共享目录至本地showmount -a 192.168.1.30 显示NFS服务器所有文件系统挂载情况
showmount -e 192.168.1.30 显示NFS服务器已被挂在的文件系统和客户端列表
showmount -d 192.168.1.30 显示NFS服务器已被挂在的文件系统列表
exportfs命令(无需重启服务让配置文件生效)
-a-r 重新导出
-u 取消导出
-v 显示过程
-arv 重新导出配置文件内容
-auv (取消所有导出文件系统)
开机自动挂载
vim /etc/fstab192.168.1.30:/shared /tmp/nfs nfs defaults,_rnetdev 0 0
让mountd和quotad等进程监听在固定端口
vim /etc/sysconfig/nfsMOUNTD_PORT=892
RQUOTAD_PORT=875
LOCKD_TCPPORT=32803
LOCKD_UDPPORT=32769
NFS在LAMP架构下的应用

一、NFS服务器端
部署LAMP平台
##########################安装LAMP##########################yum installhttpd httpd-develhttpd 安装httpd
yum installmysql mysql-server mysql-devel mysql 安装mysql
yum installphp53 php53-mbstring php53-mysqlphp 安装php
##########################httpd#############################
#AddDefaultCharset UTF-8 修改字符集
unzip Discuz_X2.5_SC_GBK.zip 加压论坛
mvupload/* /var/www/html/ 发布论坛
service httpd start 启动服务
##########################mysql#############################
mysqladmin -uroot -p password 'redhat' 为数据库添加密码
grant all privileges on *.* to root@'%'identified by 'redhat';
远程授权root
service mysqld start 启动服务
##########################修改权限安装论坛##################
cd/var/www/html
chmod777 config/ data/ data/cache/data/avatar/data/plugindata/data/download/data/addonmd5/data/template/data/threadcache/data/attachment/data/attachment/album/data/attachment/forum/data/attachment/group/data/log/uc_client/data/cache/uc_server/data/uc_server/data/cache/uc_server/data/avatar/uc_server/data/backup/uc_server/data/logs/uc_server/data/tmp/uc_server/data/view/




启动NFS服务
service portmap status 检测portmap服务vim /etc/exports 修改主配置文件
/var/www/html 192.168.1.240(rw,no_root_squash)
exportfs –ra 重新导出目
service nfs start 启动nfs服务
二、NFS客户端
###########################安装LAP平台##########################yum install httpd httpd-devel 安装httpd
yum install php53 php53-mbstring php53-mysql 安装php
service httpd start 启动服务
##########################NFS客户端#############################
mount -t nfs 192.168.1.230:/var/www/html /var/www/html 挂载目录
#AddDefaultCharset UTF-8 修改字符集
service httpd start 启动服务
三、测试
客户端使用浏览器访问192.168.1.240(NFS客户端)

客户端使用浏览器访问192.168.1.230(NFS服务端)

File Transfer Protocol
#####################################
FTP简介
vsftpd基本使用
明文传输带来的安全隐患
安全通信方式
vsftpd + PAM + mysql实现虚拟用户
#####################################
FTP简介
文件传输服务位于应用层,监听21/tcp端口,数据传输模式为自适应,没有交叉编码能力Mine,遵循原文件本身格式,基于TCP协议实现,它有两个连接,命令连接和数据连接,它的工作模式有两种,主动模式和被动模式。
主动模式

被动模式

vsftpd基本使用
特性
文件服务权限等于文件系统权限和文件共享权限的交集
支持虚拟用户
家目录在/var/ftp目录下,/目录被锁定为其家目录
支持匿名用户
支持系统用户
家目录目录在/home/username目录下,/目录没有锁定,可以切换 lcd
支持基于PAM实现用户认证
安装
yum install vsftpdservice vsftpd start
chkconfig vsftpd on
/etc/vsftpd 配置文件
/etc/init.d/vsftpd 服务脚本
/usr/sbin/vsftpd 守护进程
/etc/pam.d/* 配置文件
/lib/security 认证模块
/var/ftp 文件目录,不允许除root用户之外的其他用户具有写权限
常用选项
anonymous_enable=YES 启用匿名用户anonymouslocal_enable=YES 启用系统用户
write_enable=YES 开启写入
anon_upload_enable=YES 开启上传
anon_mkdir_write_enable=YES 开启目录创建
anon_other_write_enable=YES 开启其他写权限,例如delete等……
dirmessage_enable=YES 开启目录进入欢迎提示
vim /var/ftp/upload/.message 当用户切换到此目录时候会显示
xferlog_enable=YES 开启传输日志
xferlog_file=/var/log/vsftpd.log 定义传输日志存储位置和名称
#chown_uploads=YES 是否开启修改用户上传之后修改用户属主
#chown_username=whoever 修改为谁?
#idle_session_timeout=600 命令连接超时时间
#data_connection_timeout=120 数据连接超时时间
#ascii_upload_enable=YES 文本模式上传
#ascii_download_enable=YES 文本模式下载
chroot_list_enable=YES 禁锢用户至自己家目录
chroot_list_file=/etc/vsftpd/chroot_list通过用户列表禁锢那些用户
#chroot_local_user=YES 禁锢所有用户至自己家目录,需要注释上面两项
listen=YES vsftpd是否工作为一个独立守护进程类型;
独立守护进程适合于 (访问量大,在线时间长的服务)
瞬时守护进程 (访问量比较小,在线时间不长的服务)
pam_service_name=vsftpd 基于pam的认证
/etc/vsftpd/ftpusers (文件中用户不能登录,清空/etc/vsftpd/user_list后才真正由此文件控制)
userlist_enable=YES 文件的用户不允许登录(/etc/vsftpd/user_list)
userlist_deny=NO 仅允许文件中的用户可以登录(/etc/vsftpd/user_list)
tcp_wrappers=YES
max_clients 最多允许几个IP访问
max_per_ip 一个IP最多几个请求
举例:让匿名用户可以上传文件
anon_upload_enable=YES 开启mkdir /var/ftp/upload
setfacl -m u:ftp:rwx /var/ftp/upload/
getfacl /var/ftp/upload/
明文传输带来的安全隐患
使用客户端连接FTP服务器

在服务器端使用tcpdum命令抓包
tcpdump -i eth0 -nn -X -vv tcp port 21 and ip host 192.168.1.30

安全通信方式
ftps:ftp+ssl/tls
sftp:OpenSSH,SubSystem,sftp(SSH)
创建私有CA
cd /etc/pki/CAmkdir certs newcerts crl
echo 01 > serial
(umask 077;openssl genrsa -out private/cakey.pem 2048)创建私钥
openssl req -new -x509 -key private/cakey.pem -out cacert.pem -days 3650生成自签证书
生成证书颁发请求并签署
mkdir /etc/vsftpd/sslcd /etc/vsftpd/ssl
(umask 077; openssl genrsa -out vsftpd.key 2048;) 生成私钥
openssl req -new -key vsftpd.key -out vsftpd.csr 生成证书颁发请求
openssl ca -in vsftpd.csr -out vsftpd.crt 签署证书
修改配置文件etc/vsftpd/vsftpd.conf支持ssl、tsl功能
# ssl or tlsssl_enable=YES
ssl_sslv3=YES
ssl_tlsv1=YES
allow_anon_ssl=NO
force_local_data_ssl=YES
force_local_logins_ssl=YES
rsa_cert_file=/etc/vsftpd/ssl/vsftpd.crt
rsa_private_key_file=/etc/vsftpd/ssl/vsftpd.key
客户端软件登陆
本文中使用FlashFXP作为FTP客户端

点击连接

成功连接

在服务器端抓包发现是明文
tcpdump -i eth0 -nn -X -vv tcp port 21 and ip host 192.168.1.30

vsftpd + PAM + mysql实现虚拟用户
一、安装所需要程序
事先安装好开发环境和mysql数据库;
yum -y install mysql-server mysql-develyum -y groupinstall "Development Tools" "Development Libraries"
安装pam_mysql-0.7RC1
tar zxvf pam_mysql-0.7RC1.tar.gzcd pam_mysql-0.7RC1
./configure --with-mysql=/usr --with-opensslrpm包的mysql
make
make install

安装vsftpd
yum -y install vsftpd二、创建虚拟用户账号
准备数据库及相关表,首先请确保mysql服务已经正常启动。而后,按需要建立存储虚拟用户的数据库即可,这里将其创建为vsftpd数据库。
mysql> create database vsftpd;mysql> grant select on vsftpd.* to vsftpd@localhost identified by 'vsftpd';
mysql> grant select on vsftpd.* to vsftpd@127.0.0.1 identified by 'vsftpd';
mysql> flush privileges;
mysql> use vsftpd;
mysql> create table users (
-> id int AUTO_INCREMENT NOT NULL,
-> name char(20) binary NOT NULL,
-> password char(48) binary NOT NULL,
-> primary key(id)
-> );
添加测试的虚拟,用户pam_mysql的password()函数与MySQL的password()函数可能会有所不同。
insert into users (name,password) value ('bob','123'),('tom','321'),('lucy','333');三、配置vsftpd
建立pam认证所需文件vi /etc/pam.d/vsftpd.mysql
auth required /usr/lib/security/pam_mysql.so user=vsftpd passwd=vsftpd host=localhost db=vsftpd table=users usercolumn=name passwdcolumn=password crypt=0account required /usr/lib/security/pam_mysql.so user=vsftpd passwd=vsftpd host=localhost db=vsftpd table=users usercolumn=name passwdcolumn=password crypt=0
修改vsftpd的配置文件,使其适应mysql认证,建立虚拟用户映射的系统用户及对应的目录
useradd -s /sbin/nologin -d /var/ftproot vuserchmod go+rx /var/ftproot
请确保/etc/vsftpd.conf中已经启用了以下选项
anonymous_enable=YESlocal_enable=YES
write_enable=YES
anon_upload_enable=YES
anon_mkdir_write_enable=NO
chroot_local_user=YES
修改为NO,验证不通过SSL
force_local_data_ssl=NOforce_local_logins_ssl=NO
而后添加以下选项
guest_enable=YES 启用来宾用户guest_username=vuser 来宾用户为
并确保pam_service_name选项的值如下所示
pam_service_name=vsftpd.mysql四、启动vsftpd服务并测试
启动服务
service vsftpd startchkconfig vsftpd on 自动启动
查看端口开启情况
netstat -tnlp |grep :21查看数据库

FTP客户端工具登录验证pam是否生效

五、配置虚拟用户具有不同的访问权限
为虚拟用户使用配置文件目录
vim /etc/vsftpd/vsftpd.confuser_config_dir=/etc/vsftpd/vusers_dir
创建所需要目录,并为虚拟用户提供配置文件
mkdir /etc/vsftpd/vusers_dir/touch /etc/vsftpd/vusers_dir/bob /etc/vsftpd/vusers_dir/tom
配置虚拟用户的访问权限;所有虚拟用户的家目录为/var/ftproot;所有的虚拟用户映射到vuser中,而vuser属于匿名用户,因此虚拟用户的访问权限是通过匿名用户指令生效的。
bob可以上传、创建、删除
vim /etc/vsftpd/vusers_dir/bobanon_upload_enable=YES (配置文件中已经开启,这里不写也可以)
anon_mkdir_write_enable=YES
anon_other_write_enable=YES
tom不可以上传
vim /etc/vsftpd/vusers_dir/tomanon_upload_enable=NO
lucy可以上传
主配置文件中匿名上传已启用anon_upload_enable=YES,所以不需要做任何修改bob测试

tom测试

lucy测试

rsync+inotify搭建实时同步系统
rsync简介
rsync是Linux和UNIX系统下的文件同步和数据传输工具,它采用了“rsync”算法使一个客户机和远程文件服务器之间的文件同步,它不同于cp和wget命令完整复制的局限性,它支持增量备份,因此文件传输效率高,因而同步时间很短,具体特性如下:
1、可以镜像保存整个目录树和文件系统
2、可以增量同步数据。文件传输效率高。
3、可以保持原有文件的权限、时间等属性。
4、加密传输数据,保证数据的安全性。
5、可以使用rcp、ssh等方式来传输文件。
搭建远程容灾备份系统
Web服务器为了保证数据安全,每天凌晨2点将数据备份到远程容灾服务器上,由于数据量比较大,每年只能进行增量备份,仅备份当天新增数据,系统环境如下:
Web端配置
主配置文件/etc/rsyncd.conf
密码文件chmod 600 /etc/server.pass
启动rsync守护进程
远程容灾端配置
密码文件chmod 600 /etc/server.pass
添加计划任务crontab -e
分析不足
此时一个远程容灾系统已经搭建完成,但这并非是一个完整意义上的容灾方案,由于rsync需要通过触发才能将服务器端数据同步,因此两次触发同步的时间间隔内,服务器和客户端的数据可能不一致,如果在这个时间间隔内,网站系统出现问题,数据必然丢失,Linux 2.6.13以后的内核提供了inotify文件系统监控机制,用过rsync与inotify的组合,完全可以实现rsync服务器端和客户端的实时数据同步。
rsync+inotify实现数据的实时备份
inotify是一种强大的、细粒度的、异步的文件系统时间监控机制,Linux内核从2.6.13版本起,加入了对inotify的支持。通过inotify可以监控文件系统中添加、删除、修改、移动等各种细微事件,利用这个内核接口,第三方软件可以监控文件系统下文件的各种变化情况,inotify-tools软件正是基于这种需求实现的一个第三方软件。
内容分发服务器实时同步数据对2个Web服务器上,inotify是用来监控文件系统变化的工具,因此必须安装在内容发布节点上,内容发布节点(Server)充当了rsync客户端的角色,2个Web节点充当了rsync服务器端的角色,整个数据同步过程就是一个从客户端向服务器端发送数据的过程,与前面案例中的逻辑结构刚好相反,系统环境如下:
Web1端配置
主配置文件/etc/rsyncd.conf
密码文件chmod 600 /etc/server.pass
启动rsync守护进程并添加开机自动启动
Web2端配置
主配置文件/etc/rsyncd.conf
密码文件chmod 600 /etc/server.pass
启动rsync守护进程并添加开机自动启动
Server端配置
安装inotify-tools
密码文件chmod 600 /etc/server.pass
监控目录变化并同步Web节点脚本
指定权限并放入后台运行
为此脚本添加开机自动启动
测试结果
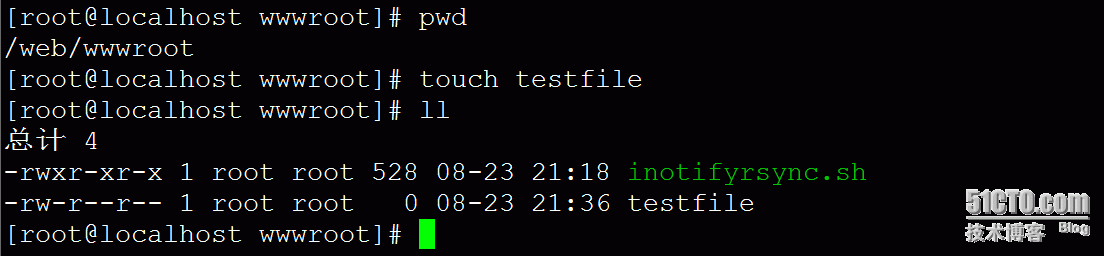
Server端(rsync客户端)创建测试文件,如图:
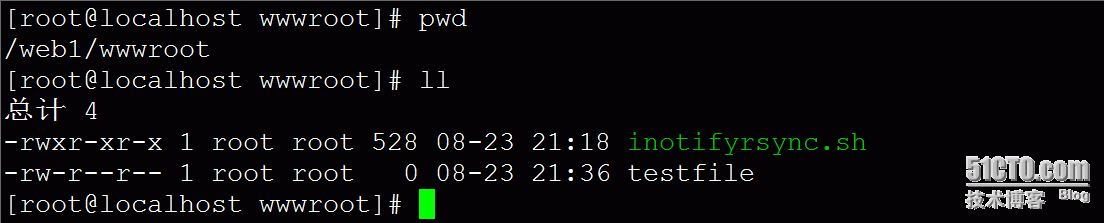
Web1端查看,如图:
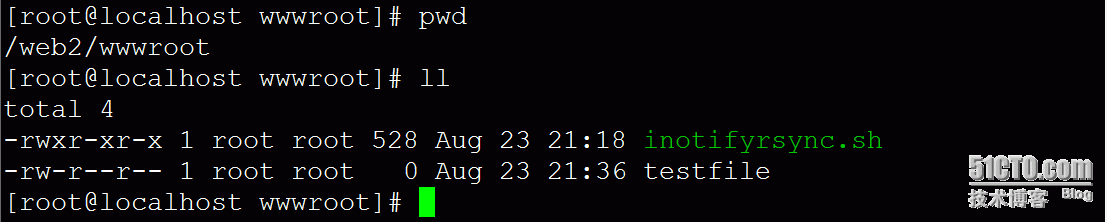
Web2端查看,如图:
HTML5本地存储之Database Storage篇
在上一篇《HTML5本地存储之Web Storage篇》中, 简单介绍了如何利用localStorage实现本地存储;实际上,除了sessionStorage和localStorage外,HTML5还支持通 过本地数据库进行本地数据存储,HTML5采用的是"SQLite"这种文件型数据库,该数据库多集中在嵌入式设备上,熟悉IOS/Android开发的 同学,应该对SQLite数据库比较熟悉。
HTML5中的数据库操作比较简单,主要有如下两个函数:
1、通过openDatabase方法创建一个访问数据库的对象
[javascript] view plaincopy
- var db = openDatabase(databasename,version,description,size)
- databasename:数据库名;
- version:数据库版本号,可不填;
- description:数据库描述;
- size:给数据库分配的空间大小;
2、使用第一步创建的数据库访问对象(如db)执行transaction方法,用来执行事务处理;
[javascript] view plaincopy
- db.transaction(function(tx)){
- //执行访问数据库的语句
- });
3、通过executeSql方法执行查询
[javascript] view plaincopy
- tx.executeSql(sqlQuery,[value1,value2..],dataHandler,errorHandler)
- sqlQuery:需要具体执行的sql语句,可以是create、select、update、delete;
- [value1,value2..]:sql语句中所有使用到的参数的数组,在executeSql方法中,将sql语句中所要使用的参数先用“?”代替,然后依次将这些参数组成数组放在第二个参数中;
- dataHandler:执行成功是调用的回调函数,通过该函数可以获得查询结果集;
- errorHandler:执行失败时调用的回调函数;
本文通过HTML5的数据库支持,重新实现一遍上篇文章中的通讯录管理,待实现功能如下:
- 可创建联系人并保存到数据库中,联系人字段包括:姓名、手机号码、公司、创建时间;
- 列出当前已保存的所有联系人信息;
- 可删除特定联系人信息;
同样,先准备一个HTML页面,如下:
[html] view plaincopy
- <!DOCTYPE HTML>
- <html>
- <head>
- <meta charset="utf-8"/>
- <title>HTML5本地存储之本地数据库篇</title>
- <style>
- .addDiv{
- border: 2px dashed #ccc;
- width:400px;
- text-align:center;
- }
- </style>
- </head>
- <body onload="loadAll()">
- <div class="addDiv">
- <label for="user_name">姓名:</label>
- <input type="text" id="user_name" name="user_name" class="text"/>
- <br/>
- <label for="mobilephone">手机:</label>
- <input type="text" id="mobilephone" name="mobilephone"/>
- <br/>
- <label for="mobilephone">公司:</label>
- <input type="text" id="company" name="company"/>
- <br/>
- <input type="button" onclick="save()" value="新增记录"/>
- </div>
- <br/>
- <div id="list">
- </div>
- </body>
- </html>
界面展现如下:

要实现创建新联系人并存入数据库功能,需要如下简单的JS代码:
[javascript] view plaincopy
- //打开数据库
- var db = openDatabase('contactdb','','local database demo',204800);
- //保存数据
- function save(){
- var user_name = document.getElementById("user_name").value;
- var mobilephone = document.getElementById("mobilephone").value;
- var company = document.getElementById("company").value;
- //创建时间
- var time = new Date().getTime();
- db.transaction(function(tx){
- tx.executeSql('insert into contact values(?,?,?,?)',[user_name,mobilephone,company,time],onSuccess,onError);
- });
- }
- //sql语句执行成功后执行的回调函数
- function onSuccess(tx,rs){
- alert("操作成功");
- loadAll();
- }
- //sql语句执行失败后执行的回调函数
- function onError(tx,error){
- alert("操作失败,失败信息:"+ error.message);
- }
[javascript] view plaincopy
- //将所有存储在sqlLite数据库中的联系人全部取出来
- function loadAll(){
- var list = document.getElementById("list");
- db.transaction(function(tx){
- //如果数据表不存在,则创建数据表
- tx.executeSql('create table if not exists contact(name text,phone text,company text,createtime INTEGER)',[]);
- //查询所有联系人记录
- tx.executeSql('select * from contact',[],function(tx,rs){
- if(rs.rows.length>0){
- var result = "<table>";
- result += "<tr><th> 序号</th><th>姓名</th><th>手机</th><th>公 司</th><th>添加时间</th><th>操作</th></tr>";
- for(var i=0;i<rs.rows.length;i++){
- var row = rs.rows.item(i);
- //转换时间,并格式化输出
- var time = new Date();
- time.setTime(row.createtime);
- var timeStr = time.format("yyyy-MM-dd hh:mm:ss");
- //拼装一个表格的行节点
- result += "<tr><td>"+(i+1)+"</td><td>"+row.name+"</td><td>"+row.phone+"</td><td>"+row.company+"</td><td>"+timeStr+"</td><td><input type='button' value='删除' onclick='del("+row.phone+")'/></td></tr>";
- }
- list.innerHTML = result;
- }else{
- list.innerHTML = "目前数据为空,赶紧开始加入联系人吧";
- }
- });
- });
- }
[javascript] view plaincopy
- Date.prototype.format = function(format)
- {
- var o = {
- "M+" : this.getMonth()+1, //month
- "d+" : this.getDate(), //day
- "h+" : this.getHours(), //hour
- "m+" : this.getMinutes(), //minute
- "s+" : this.getSeconds(), //second
- "q+" : Math.floor((this.getMonth()+3)/3), //quarter
- "S" : this.getMilliseconds() //millisecond
- }
- if(/(y+)/.test(format)) format=format.replace(RegExp.$1,
- (this.getFullYear()+"").substr(4 - RegExp.$1.length));
- for(var k in o)if(new RegExp("("+ k +")").test(format))
- format = format.replace(RegExp.$1,
- RegExp.$1.length==1 ? o[k] :
- ("00"+ o[k]).substr((""+ o[k]).length));
- return format;
- }

要实现具体某个联系人,需执行如下JS代码:
[javascript] view plaincopy
- //删除联系人信息
- function del(phone){
- db.transaction(function(tx){
- //注意这里需要显示的将传入的参数phone转变为字符串类型
- tx.executeSql('delete from contact where phone=?',[String(phone)],onSuccess,onError);
- });
- }
如上截图中的表格样式,可参考如下CSS代码:
[css] view plaincopy
- th {
- font: bold 11px "Trebuchet MS", Verdana, Arial, Helvetica, sans-serif;
- color: #4f6b72;
- border-right: 1px solid #C1DAD7;
- border-bottom: 1px solid #C1DAD7;
- border-top: 1px solid #C1DAD7;
- letter-spacing: 2px;
- text-transform: uppercase;
- text-align: left;
- padding: 6px 6px 6px 12px;
- }
- td {
- border-right: 1px solid #C9DAD7;
- border-bottom: 1px solid #C9DAD7;
- background: #fff;
- padding: 6px 6px 6px 12px;
- color: #4f6b72;
- }

How to import merries diapers from Japan to China?
How to import merries diapers from Japan to China?
Seahog logistics firm can help you!
Chinese tax
Customs clearance
Customs declaration
Seahog Logistics is an international integrated logistics specialist business offering worldwide air freight and sea freight services to clients throughout the world. The company, which is located in Shanghai, was set-up in 1997 and has many years experience in the trade, with a global network of contacts and appointed agents.
Agent: Anna Leung
Mobile: +86 15218771070
Tel: +86 769-89830090
Email: anna@seahog.cn
anna0109@qq.com
QQ:1975088296
Skype: AnnaLeung89
Company: Shanghai Seahog International Logistics Company
Address: Rm 404A, Building B, #1518 Minsheng Rd, Pudong New District,Shanghai City, China
Website: http://www.seahog-ay.com/

第八届中国西南国际煤矿及采矿技术装备展览会

Set模型,集装箱改变世界
集装箱改变世界,集装箱改变了航运的经济规律.并因此改变了全球的贸易流。如果没有集装箱.就不会有全球化,集装箱成为经济全球化的幕后推手,主要有以下三个特性:
1、标准化,减少货物中转及理货时间,提高货物运输效率,降低运输成本,海上集装箱船装卸、中转。(货柜车\火车\轮船)
2、规模化,按集装箱规格来进行业务周转,规模化作业运转,降低运作成本,提高效率。( 30吨、20吨、10吨)
3、模块化,外形方正,尺寸标准化,堆放、装卸、运输方便,功能单一化,无需再包装,节约成本。
日常会有很多场景应用集装箱模式来解决很多问题,可以先看看我们常遇到的问题:
1、业务非常多,每个业务的服务器数量都很大,...
Hadoop分布式文件系统和OpenStack对象存储有何不同
引用:http://blog.csdn.net/starean/article/details/11158979
“HDFS (Hadoop分布式文件系统)和OpenStack对象存储(OpenStack Object Storage)似乎都有着相似的目的:实现冗余、快速、联网的存储。什么样的技术特性让这两种系统因而不一样?这两种存储系统最终趋于融合是否大有意义?”
问题提出之后,很快有OpenStack的开发者进行了回复。本文在此摘抄了前两名回复进行翻译,以供各位参考。
排名第一的答案来自RackSpace的OpenStack Swift开发者Chuck Their:
虽然HDFS与Openstack对象存储(Swift)之间有着一些相似之处,但是这两种系统的总体设计却大不一样。
1. HDFS使用了中央系统来维护文件元数据(Namenode,名称节点),而在Swift中,元数据呈分布式,跨集群复制。使用一种中央元数据系统对HDFS来说无异于单一故障点,因而扩展到规模非常大的环境显得更困难。
2. Swift在设计时考虑到了多租户架构,而HDFS没有多租户架构这个概念。
3. HDFS针对更庞大的文件作了优化(这是处理数据时通常会出现的情况),Swift被设计成了可以存储任何大小的文件。
4. 在HDFS中,文件写入一次,而且每次只能有一个文件写入;而在Swift中,文件可以写入多次;在并发操作环境下,以最近一次操作为准。
5. HDFS用Java来编写,而Swift用Python来编写。
另外,HDFS被设计成了可以存储数量中等的大文件,以支持数据处理,而Swift被设计成了一种比较通用的存储解决方案,能够可靠地存储数量非常多的大小不一的文件。
排名第二的答案来自Joshua McKenty,他是美国宇航局Nebula云计算项目的首席架构师,是OpenStack Nova软件的早期开发者之一,目前是OpenStack项目监管委员会的成员,还是Piston.cc这家基于OpenStack的公司的创始人。
Chuck刚才详细介绍了两者的技术差异,但是没有讨论两者可想而知的融合,OpenStack设计峰会上抛出了融合这个话题。简而言之,HDFS被设计 成可以使用Hadoop,跨存储环境里面的对象实现MapReduce处理。对于许多OpenStack公司(包括我自己的公司)来说,支持Swift里 面的处理是路线图上面的一个目标,不过不是每个人都认为MapReduce是解决之道。
我们已讨论过为HDFS编写包装器,这将支持OpenStack内部存储应用编程接口(API),并且让用户可以针对该数据来执行Hadoop查询。还有一个办法就是在Swift里面使用HDFS。但是这些方法似乎没有一个是理想的。
OpenStack社区方面也在开展研究开发方面的一些工作,认真研究其他替代性的MapReduce框架(Riak和CouchDB等)。
最后,现在有别的一些存储项目,目前“隶属于”OpenStack社区(SheepDog和HC2)。充分利用数据局部性,并且让对象存储变得“更智能”,这是预计会取得进步的一个领域。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号