
化整为零、分而治之、异步编排:一文读懂现代并发的底层心法
LongAdder:化整为零,热点分散
在Java多线程编程中,原子变量(如AtomicLong)通过CAS操作实现线程安全的累加。然而,在高并发场景下,大量线程争抢同一原子变量会引发严重的缓存一致性问题。
1)缓存行伪共享:多个线程频繁更新同一缓存行,导致缓存失效和MESI协议频繁触发,处理器性能急剧下降。
2)CAS冲突开销:CAS操作需自旋重试,线程竞争激烈时重试次数增加,进一步拖慢性能。
为解决上述瓶颈,Java 8引入了LongAdder,其核心思想是“分散竞争,延迟求和”。
1)分段累加:将单一累加变量拆分为多个分段变量(cells),每个线程仅更新其专属的分段,避免全局竞争。
2)基础值优化:在低并发场景下,直接更新基础值(base),减少分段数组的开销。
3)最终一致性求和:通过遍历所有分段和基础值,延迟计算总和,降低实时竞争压力。
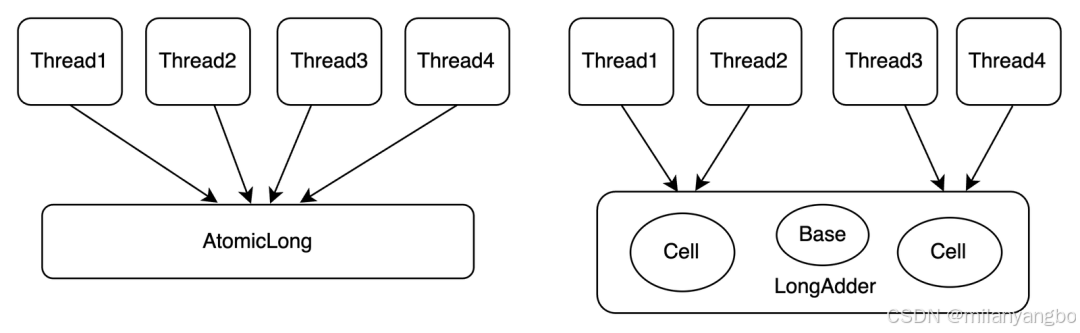
LongAdder的内部实现原理,可以用下面的伪代码演示。
public class LongAdder {
private final AtomicLong[] cells; // 分段数组,每个线程映射到特定分段
private final AtomicLong base; // 基础值,低并发时直接更新
public LongAdder() {
cells = new AtomicLong[16]; // 假设初始化16个分段
for (int i = 0; i < cells.length; i++) {
cells[i] = new AtomicLong(0); // 初始化分段值为0
}
base = new AtomicLong(0); // 初始化基础值为0
}
public void add(long x) {
// 1. 计算线程对应的分段索引(简单取模实现)
int index = (int) (Thread.currentThread().getId() % cells.length);
// 2. 对专属分段执行CAS累加,避免全局竞争
cells[index].addAndGet(x);
}
public long sum() {
// 3. 求和:累加基础值和所有分段值
long sum = base.get();
for (AtomicLong cell : cells) {
sum += cell.get();
}
return sum;
}
}
然而,LongAdder 并非万能钥匙。在并发度较低的场景,AtomicLong 的简单直接反而更高效,就好比小型聚会中,大家直接共享一个果盘更方便,而不需要多个果篮。另外,当需要频繁读取累计结果时,LongAdder 的汇总过程就像逐个篮子统计水果数量,略显繁琐,性能会受影响。Fork/Join:分而治之,任务窃取
Java 7 引入的 Fork/Join Framework 是一种强大的并行编程模型,专为解决“分而治之”(Divide and Conquer)类型的问题而设计。它充分利用多核处理器的计算能力,通过分解任务、并行执行和合并结果,显著提升程序的执行效率。
Fork/Join特别适合处理可以被分解成独立子任务的问题,以实现任务的并行执行,如排序、搜索等。
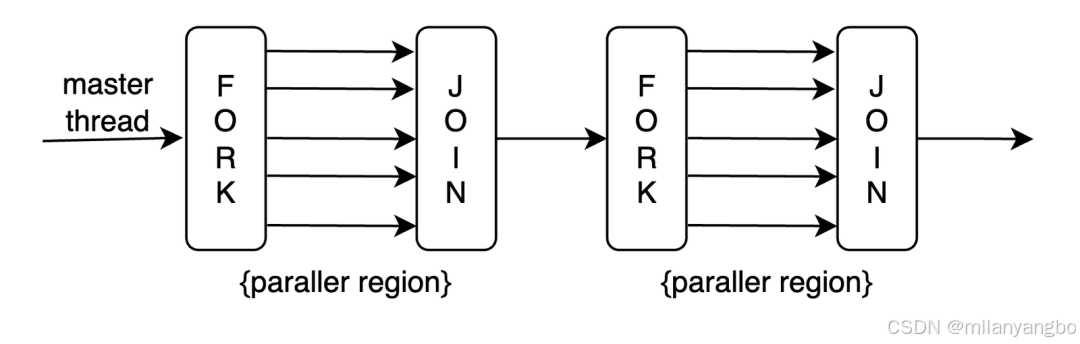
if (任务足够小) {
直接计算并返回结果;
} else {
将任务拆分为N个子任务;
对每个子任务调用 fork() 进行并行计算;
调用 join() 合并子任务的结果;
返回最终结果;
}
在Java 8中引入的并行流计算(Parallel stream computing),内部就是采用的ForkJoinPool来实现的。例如,下面使用并行流实现数组并行求和计算。
public class SumArray {
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
// map在实际编程中,可以是耗时高,计算量大的任务
int sum = numbers.parallelStream().map(i -> i * i).reduce(0, Integer::sum);
}
}
并行编程模型
并行编程模型(Parallel programming model)是一种用于描述和组织并行计算的框架或范式。它提供了一组抽象概念、编程接口和规范,用于指导开发者在多核处理器、分布式系统或并行计算环境中编写并行程序。
常见的并行编程模型包括:数据并行(Data parallelism)、任务并行(Task parallelism)、多线程并行(Multithread parallelism)等。工作窃取
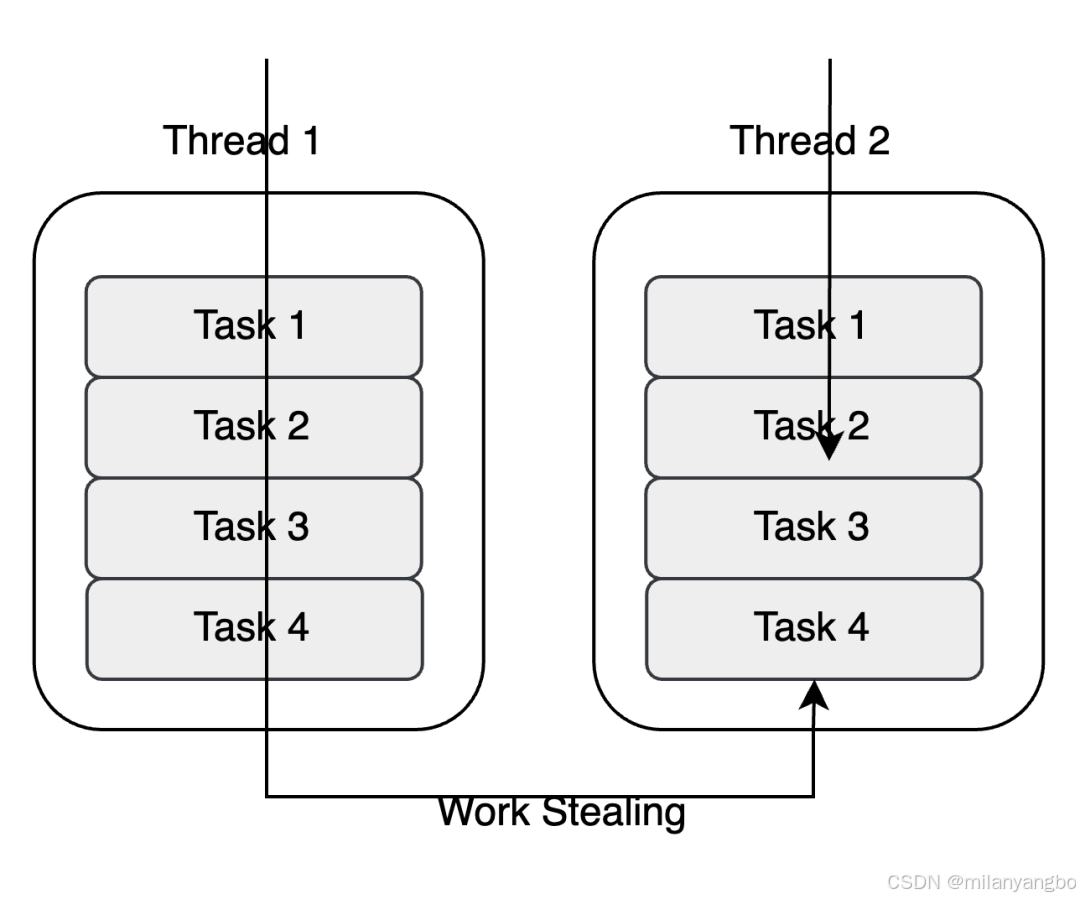
工作窃取(Work Stealing)是一种高效的并行计算调度策略,其主要目标是解决负载不均衡问题,以充分利用所有的处理器核心,从而提升程序的执行效率。
在工作窃取模型中,每个处理器都维护着自己的双端队列(Deque),用于存储分配给自己的任务。当一个处理器完成了所有自己的任务后,它会尝试从其他处理器的任务队列的末尾“窃取”任务来执行。这种策略确保了所有的处理器都能尽可能地保持忙碌状态,从而提高整体的并行性能。
工作窃取策略的一个显著优点是其能够动态地平衡负载。这意味着它能够适应各种不同的任务分布和处理器性能,从而在各种情况下都能提供优秀的性能。
在实际编程实践中,工作窃取调度策略通常由并行编程框架或库来实现。例如,Java的Fork/Join框架就采用了工作窃取策略来动态地分配任务,C++的Intel TBB(Threading Building Blocks)库也使用了类似的策略。
CompletableFuture:构建优雅的异步流水线
CompletableFuture 是 Java 8 引入的一个核心类,它实现了 Future 接口,并在其基础上提供了更强大、更灵活的异步编程能力。与传统的 Future 相比,CompletableFuture 不仅能够表示一个异步计算的结果,还支持丰富的函数式编程特性,使得开发者能够以声明式的方式处理异步任务的执行流程。
CompletableFuture 的核心优势在于其支持链式调用(Chaining),允许在一个 CompletableFuture 上附加多个操作(如转换结果、处理异常、组合多个任务等)。这些操作会在 CompletableFuture 完成时自动触发,从而形成一个流水线式的任务处理流程。
以下是一个简单的示例,展示了 CompletableFuture 的链式调用。
// supplyAsync方法用于启动一个异步任务,thenApply方法用于在任务完成时对结果进行转换
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {
......
// 异步任务,模拟网络请求
return "Hello";
}).thenApply(result -> {
// 对结果进行转换
return result + " World";
});
// 主线程等待异步操作完成
future.join();
// 获取异步执行结果
future.get();
异步编程
异步编程是一种高效的编程范式,旨在优化程序的执行效率和资源利用率。它通过允许程序在等待耗时操作(如网络请求、文件I/O等)完成的同时,继续执行其他任务,从而避免了传统同步编程中的线程阻塞问题。这种非阻塞的执行方式显著提升了程序的响应速度和并发处理能力,尤其适用于I/O密集型任务。
在传统的同步编程模型中,当一个操作需要较长时间完成时,程序会停滞在该操作上,直到操作结束,这种现象称为阻塞。相比之下,异步编程模型允许程序在启动一个耗时操作后,立即转而执行其他任务,而无需等待该操作完成。当操作完成后,程序会通过回调、事件或Future等机制收到通知,并处理操作结果。
异步编程在多种编程语言中都有应用和实现。例如,Java中的CompletableFuture、JavaScript中的Promise,以及Python中的asyncio库等,都提供了强大的异步编程支持。
以下是一个简单的同步与异步读取文件的对比示例(伪代码)。
// 同步执行读取文件操作
let a = read("a.txt");
// 同步等待上次一次文件操作完成
let b = read("b.txt");
// 假设单个文件读取耗时50ms,一共需要耗时100ms
print(a+b)
// 异步执行读取文件操作
let op_a = read_async("a.txt");
let op_b = read_async("b.txt");
let a = wait_until_get_ready(op_a);
let b = wait_until_get_ready(op_b);
// 假设单个文件读取耗时50ms, 由于两次读取文件操作同时异步执行,最终耗时50ms
print(a+b);
fn wait_until_get_ready(Operation) -> Response {
// 阻塞任务,挂起线程,直到operation就绪再唤醒线程(唤醒操作,需要操作系统和硬件的底层支撑)
}
异步编程可以更有效地处理并发问题。当程序需要同时处理多个任务时,异步编程可以让这些任务并发执行,而不是按顺序一个接一个地执行。然而,异步编程的实现离不开操作系统和硬件的底层支持。如果在异步任务执行完之前,处理线程一直对异步任务执行状态进行空轮询,这将会浪费处理器资源。因此,操作系统和硬件的底层支持,如Linux系统支持的select、poll、epoll等技术,对于异步编程的实现至关重要。
以下是一个没有底层支持时,异步编程可能面临的问题的示例(伪代码)。
let op_a = read_async("a.txt");
let a = "";
// 如果没有操作系统和硬件的底层支撑,将不断轮询op_a的任务状态
while true {
if op_a.is_finish() {
a = op_a.get_content();
break;
}
}
print(a);
链式调用
“回调地狱”(Callback Hell)是异步编程中常见的一个问题,尤其在 JavaScript 等单线程、事件驱动型语言中尤为突出。当多个异步操作需要按照特定顺序执行时,开发者可能不得不在一个回调函数中嵌套另一个回调函数,导致代码层级过深、可读性差、难以维护。
以下是一个典型的“回调地狱”示例(JavaScript)。
login(user => {
getStatus(status => {
getOrder(order => {
getPayment(payment => {
getRecommendAdvertisements(ads => {
setTimeout(() => {
alert(ads)
}, 1000)
})
})
})
})
})
链式调用(Chaining)成为一种常用的优化手段。在 JavaScript 中,Promise 机制提供了链式调用的能力。每个 Promise 对象都包含一个 then 方法,该方法返回一个新的 Promise 对象,从而允许开发者将多个异步操作串联起来,形成清晰的逻辑流。
以下是一个使用 Promise 链式调用的示例(JavaScript)。
login(username, password)
.then(user => getStatus(user.id))
.then(status => getOrder(status.id))
.then(order => getPayment(order.id))
.then(payment => getRecommendAdvertisements(payment.total_amount))
.then(ads => {/*...*/});
需要注意的是,Promise 并不是一种可以将同步代码转变为异步代码的魔法工具。它只是一种编程手法,或者说是一种封装方式,并没有借助操作系统的额外能力。Promise 的主要作用是提供了一种更优雅的方式来组织和管理异步操作,使得代码更易于阅读和理解。
总结:与硬件共舞,与冲突和解
Disruptor的环形缓冲、LongAdder的分散热点、Fork/Join的工作窃取、CompletableFuture的异步编排——这些看似迥异的技术,实则殊途同归。它们共同揭示了现代并发设计的核心要义:与其在冲突发生后被动地加锁仲裁,不如在设计之初就主动地消除冲突。
这标志着并发编程的关注点,已从“如何正确加锁”的战术层面,升华为“如何精妙分工、避免锁”的战略高度。
当摩尔定律的红利逐渐消退,真正的性能突破不再依赖于硬件的暴力堆砌,而是源于软件层面与硬件底层机制的“共舞”。无论是利用缓存行特性的内存对齐,还是借助CAS原子指令的乐观更新,每一次技术优化都印证了一个理念:硬件性能的极致发挥,源于对计算本质的深刻理解。这正是并发编程从技术迈向艺术的精髓所在。
很高兴与你相遇!如果你喜欢本文内容,记得关注哦!!!
本文来自博客园,作者:poemyang,转载请注明原文链接:https://www.cnblogs.com/poemyang/p/19384431

 浙公网安备 33010602011771号
浙公网安备 33010602011771号