
深入解析 Disruptor:从RingBuffer到缓存行填充的底层魔法
Disruptor,这一由英国金融巨头LMAX匠心打造的高性能并发框架,自诞生之初便肩负着在处理生产者-消费者问题时,追求极致吞吐量与超低延迟的使命。令人瞩目的是,LMAX公司凭借Disruptor框架,成功将订单处理速度飙升至每秒600万次交易(Transactions Per Second,TPS)的惊人水平,这一成就无疑彰显了Disruptor在并发处理领域的非凡实力。
然而,Disruptor的价值远不止于一个框架那么简单。它更是一种颠覆性的并发设计思想,为涉及并发、缓冲区管理、生产者-消费者模型以及事件处理等复杂场景的程序,提供了一种革命性的性能提升方案。
无锁队列
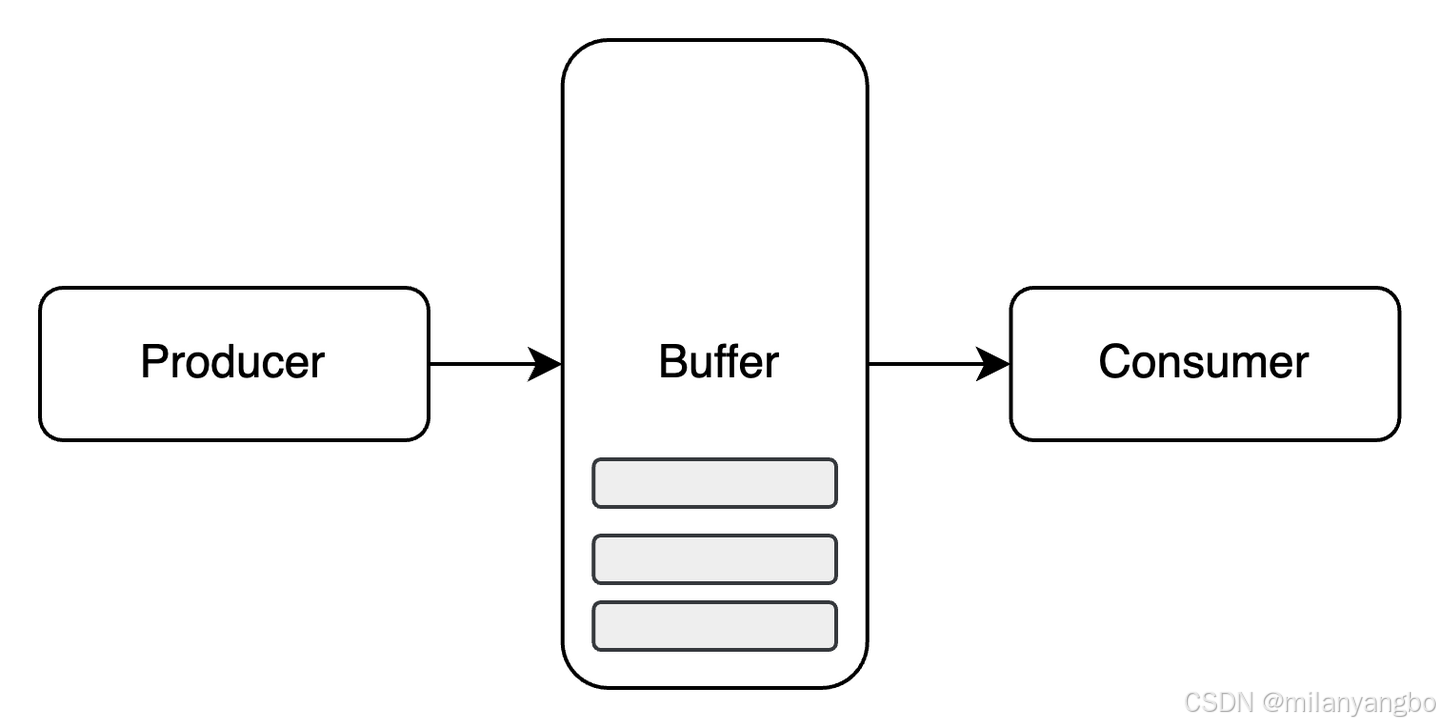
生产者-消费者问题(Producer-Consumer Problem,PCP),作为并发编程中的经典难题,一直困扰着无数开发者。它描述的是生产者和消费者在
共享缓冲区中的协同工作场景,其中的关键挑战在于如何妥善处理生产者和消费者速度不匹配的问题。必须确保,在生产者向缓冲区添加数据时,缓
冲区不会因溢出而崩溃;同时,在消费者从缓冲区获取数据时,缓冲区也不会因空置而停滞。
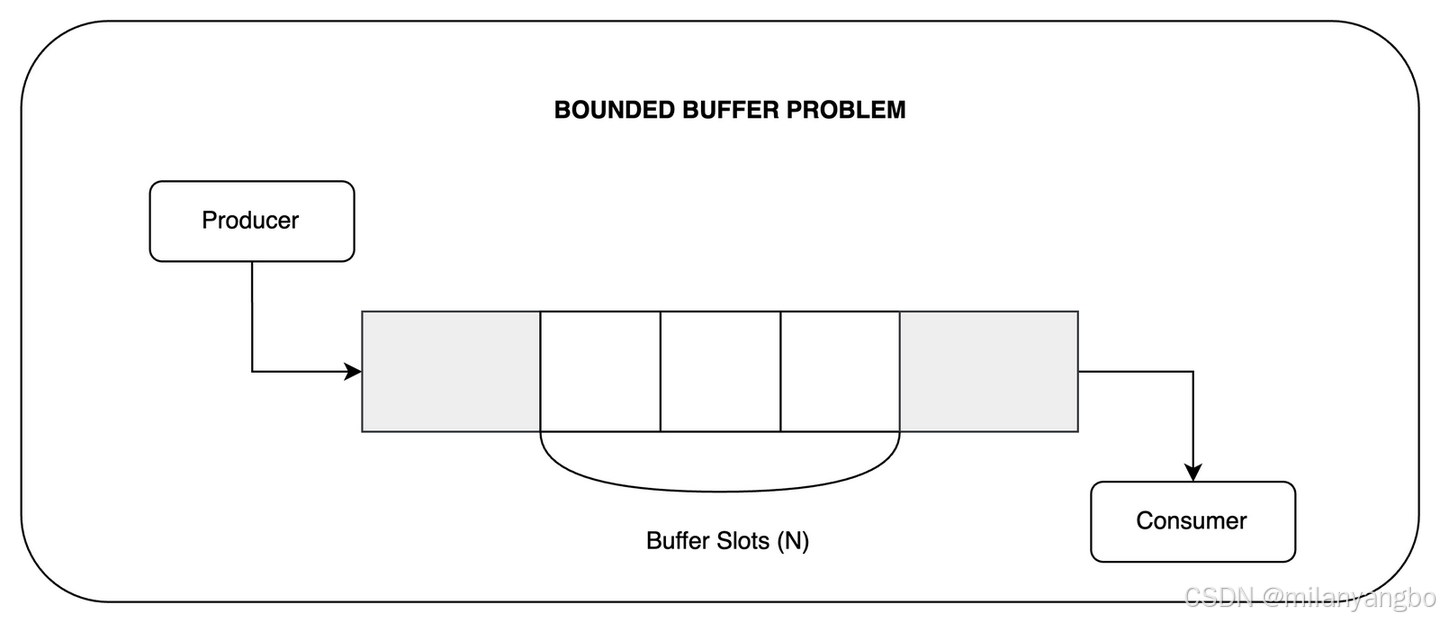
有界缓冲区(Bounded-Buffer),作为生产者-消费者问题的一个特定实例,其缓冲区容量是固定的。这种限制虽然带来了额外的复杂性,但也为优化并发性能提供了机会。当缓冲区满时,生产者必须耐心等待,直到消费者消费了部分数据以腾出空间;反之,当缓冲区为空时,消费者也必须静待时机,直到生产者添加了新的数据。为了协调这种复杂的交互,通常需要借助同步机制,如信号量、条件变量或互斥锁等。
以下代码片段展示了有界缓冲区的一种典型实现方式,它巧妙地运用了锁和条件变量来解决同步问题。
// 生产者缓存区处理
// 条件变量empty
Condition empty;
// 持有互斥锁
lock (mutex);
do{
// 等待直到没有元素的buffer slot大于0
// 至少需要一个没有元素的buffer slot
wait (empty);
}while (true)
// 执行添加元素到buffer slot的操作
put(element)
// 通知条件变量full
signal (full);
// 释放锁
unlock (mutex);
// 消费者缓存区处理
// 条件变量full
Condition full;
// 持有互斥锁
lock (mutex);
do{
// 等待直到有元素的buffer slot大于0
// 至少需要一个有元素的buffer slot
wait (full);
}while (true)
// 执行移除buffer slot元素的操作
remove(element)
// 通知条件变量empty
signal (empty);
// 释放锁
unlock (mutex);
尽管上述实现通过锁和条件变量有效解决了有界缓冲区的同步问题,但在实际编程中,加锁操作往往会带来不容忽视的性能开销。锁的获取和释放,会触发线程的休眠与唤醒,进而引发额外的上下文切换开销。如果临界区代码段过长,锁的争用问题将愈发严重,最终成为制约系统性能的瓶颈。
Disruptor的论文中,一项实验直观展现了锁机制对系统性能的深远影响。该实验聚焦于一个简单的64位计数器,对其进行了高达5亿次的自增操作。测试结果令人惊讶。
1)单线程无锁情况:仅需300毫秒,便轻松完成了5亿次自增操作。
2)单线程加锁情况:耗时急剧增加至10,000毫秒,性能下降了数十倍。
3)双线程加锁情况:耗时更是飙升至224,000毫秒,比单线程无锁实现慢了近1000倍!
面对如此巨大的性能差异,Disruptor提出了其独到的解决方案:无锁(lock-free)编程。
锁,作为并发编程中的常见控制技术,其背后蕴含着两种截然不同的并发控制策略:乐观并发控制(Optimistic Concurrency Control,OCC)与悲观并发控制(Pessimistic Concurrency Control,PCC)。而乐观锁,并非传统意义上的锁,而是一种基于验证的并发协议。它秉持着“多线程间数据竞争概率较低”的乐观假设,允许多个线程在不加锁的情况下直接操作共享数据。仅在提交时,通过精妙的验证机制检测是否存在冲突。一旦检测到冲突(如数据被其他线程修改),便迅速回滚操作并重试。这一机制的核心,正是依赖于原子指令CAS来实现数据的同步更新,确保了并发操作的安全与高效。
在并发编程的实践中,主要有两种途径来实现线程安全。
1)加锁方式:通过互斥锁、读写锁等机制,确保同一时间只有一个线程能够访问共享资源,从而避免数据竞争。但这种方式往往伴随着性能开销和死锁风险。
2)原子变量CAS:利用CAS指令的原子性,实现无锁编程。这种方式在多数情况下能够显著提升并发性能,成为现代并发编程的热门选择。
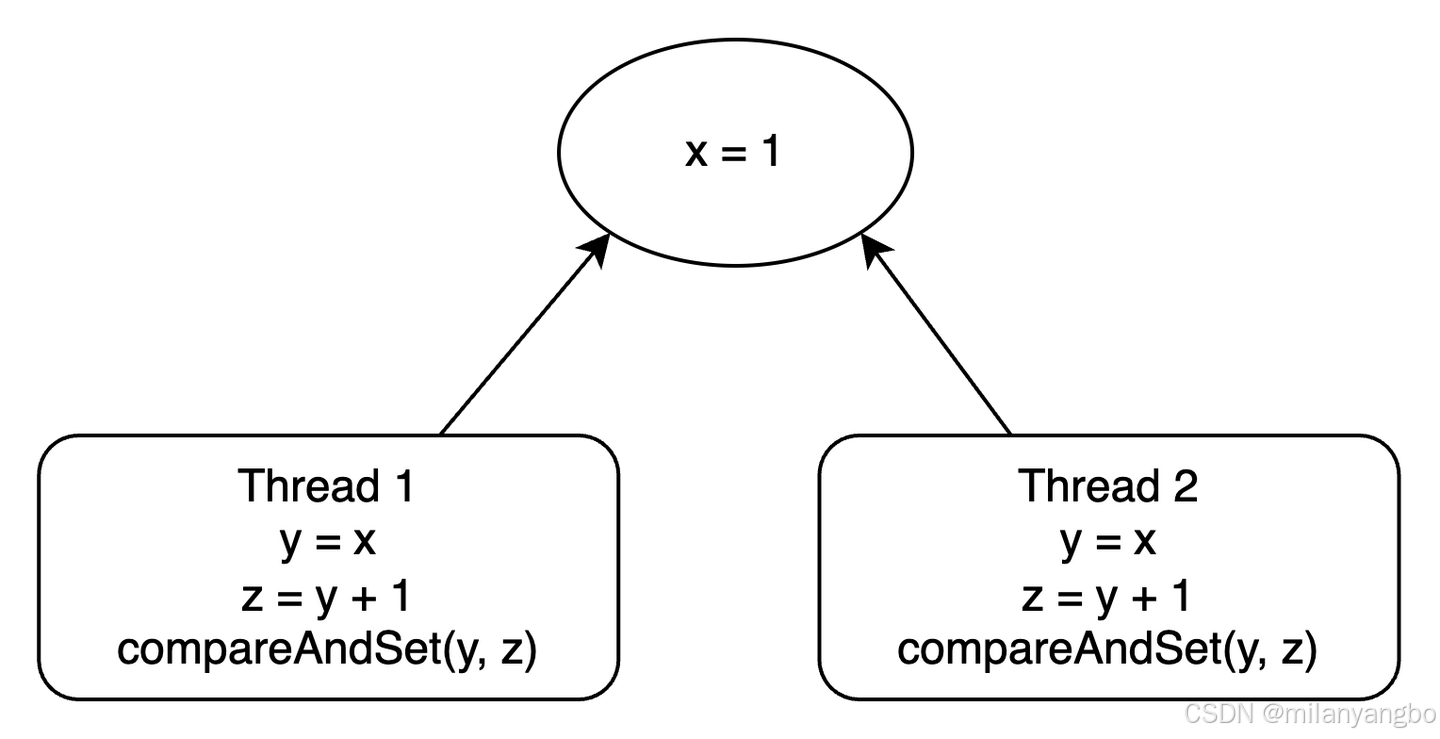
无锁队列(Lock-free Queue)的实现,正是CAS指令在并发编程中的典型应用。早在1994年,John D. Valois便在其论文《Implementing Lock-Free Queues》中,系统地研究了如何使用无锁数据结构实现先进先出(FIFO)队列。他提出了一种基于链表结构的无锁队列设计,通过CAS操作确保入队和出队操作的原子性,从而实现了高效且线程安全的队列操作。
以下代码,展示了无锁队列的一种典型实现。
// 进队列操作
EnQueue(x) {
q = new record(); // 创建新节点
q.value = x; // 设置节点值
q.next = null; // 初始化next指针
p = tail; // 获取当前尾节点
oldp = p; // 保存旧尾节点指针
do {
while (p.next != null) // 遍历至链表末尾
// 获取最新的next
p = p.next;
// 如果p.next非预期旧值null, 表明p.next已被修改
} while( CAS(p.next, null, q) != true);
// 如果当前tail等于oldp时,说明tail没有被修改,将tail设为q
CAS(tail, oldp, q);
}
// 出队列操作
DeQueue()
{
do{
p = head; // 获取当前头节点
if (p.next == null) { // 队列为空时返回特殊值
return empty_queue;
}
// 如果head非预期旧值p, 表明head已被修改
while( CAS(head, p, p.next) != true);
return p.next.value; // 返回出队元素的值
}
Ring Buffer
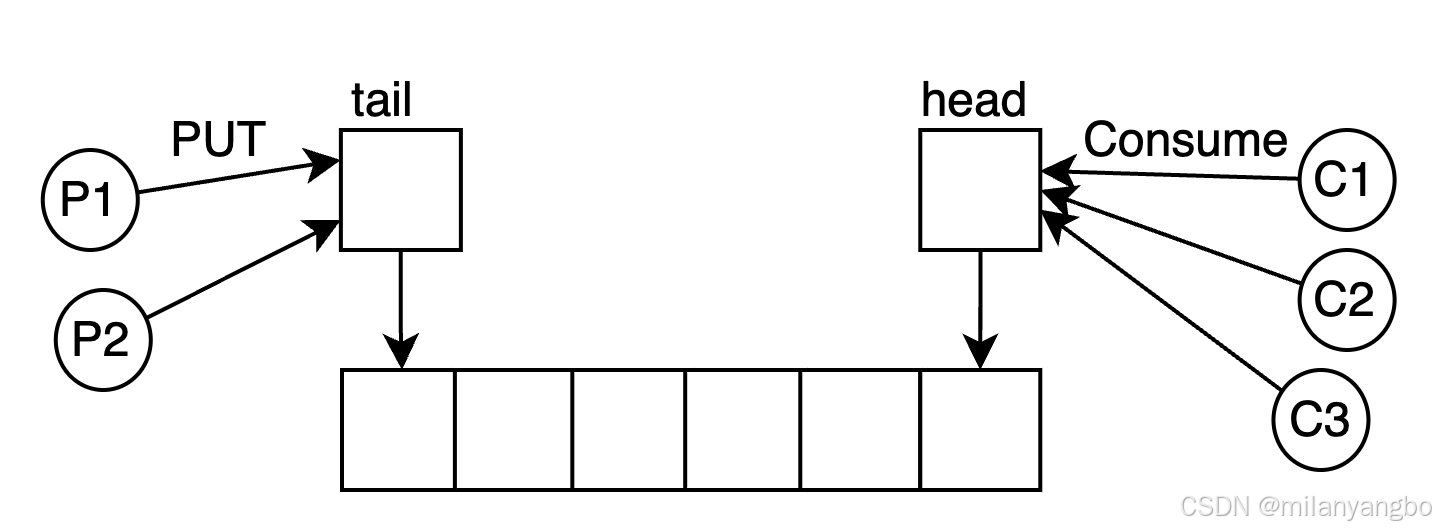
Ring Buffer,又称环形缓冲区或循环缓冲区,是一种极具特色的无锁队列实现方式,在计算机科学领域有着广泛的应用。它不仅能够实现对队列头尾元素的无锁并发控制,还能巧妙解决生产者和消费者之间的协调难题。值得一提的是,Ring Buffer并非Disruptor框架的独家发明,早在Linux内核中就已有了它的身影。
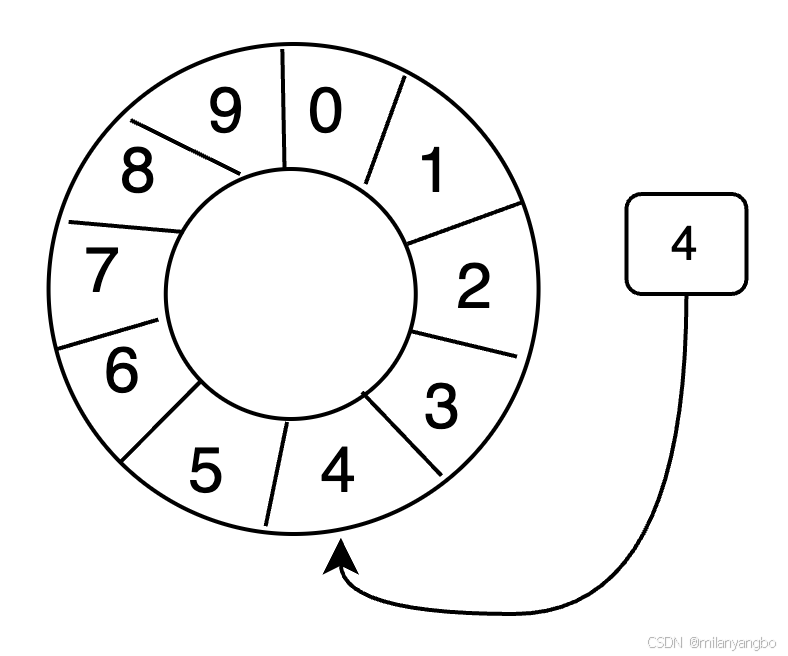
Ring Buffer是一种特殊的数据结构,它采用固定大小的数组来存储数据,数据在数组中的存储方式宛如一个环。当缓冲区被填满时,新写入的元素会覆盖最早写入的元素,这种特性使得它在处理流式数据时非常高效。为了进一步提升效率,数组中的元素在初始化时会一次性全部创建,减少了运行时的动态分配开销。
在消费者消费数据时,Ring Buffer遵循空间局部性原理。处理器会将内存中的当前元素及其后面连续的元素一次性加载进处理器缓存中,从而提升处理器处理元素的速度。这种设计充分利用了现代处理器的缓存机制,使得数据访问更加高效。
Ring Buffer使用一个递增指针来指向缓冲区中下一个可用的元素。随着数据的不断填充,这个指针会持续增加,直到绕过整个环。要找到缓冲区中当前指针指向的元素,可以通过取模操作来实现。
index mod array length = array index
当缓冲区长度2^n,通过位运算,可以加快定位的速度。
index & (array length-1) = array index
例如,当index为9,array length为8时,取模运算9 % 8可以用9 & (8 - 1)来代替,即1001 & 0111 = 0001 = 1。这种位运算的优化使得Ring Buffer在定位元素时更加迅速。
Disruptor框架在使用Ring Buffer时,可以细分为以下几种场景。
1)单生产者单消费者:由于两个线程分别操作不同的指针,因此不需要锁,实现了无锁并发。
2)多消费者:每个消费者各自控制自己的指针,依次读取每个元素。此时只需保证生产者指针不会超过最慢的消费者即可,同样不需要锁。
3)多生产者:多个线程共用一个写指针,此时需要考虑多线程问题。Disruptor使用CAS操作来保证多线程安全。例如,申请写入n个元素时,会检查是否有n个元素可以写入,并返回最大的指针下标。每个生产者会被分配一段独享的空间锁,以确保数据的一致性。
4)生产者与消费者速度不匹配:当生产者生产速度超过消费者消费速度时,生产者会采用休眠策略(如休眠1ns)来等待。反之,消费者则可能采用自旋或加锁等待策略,以在处理器资源和性能之间做出取舍。
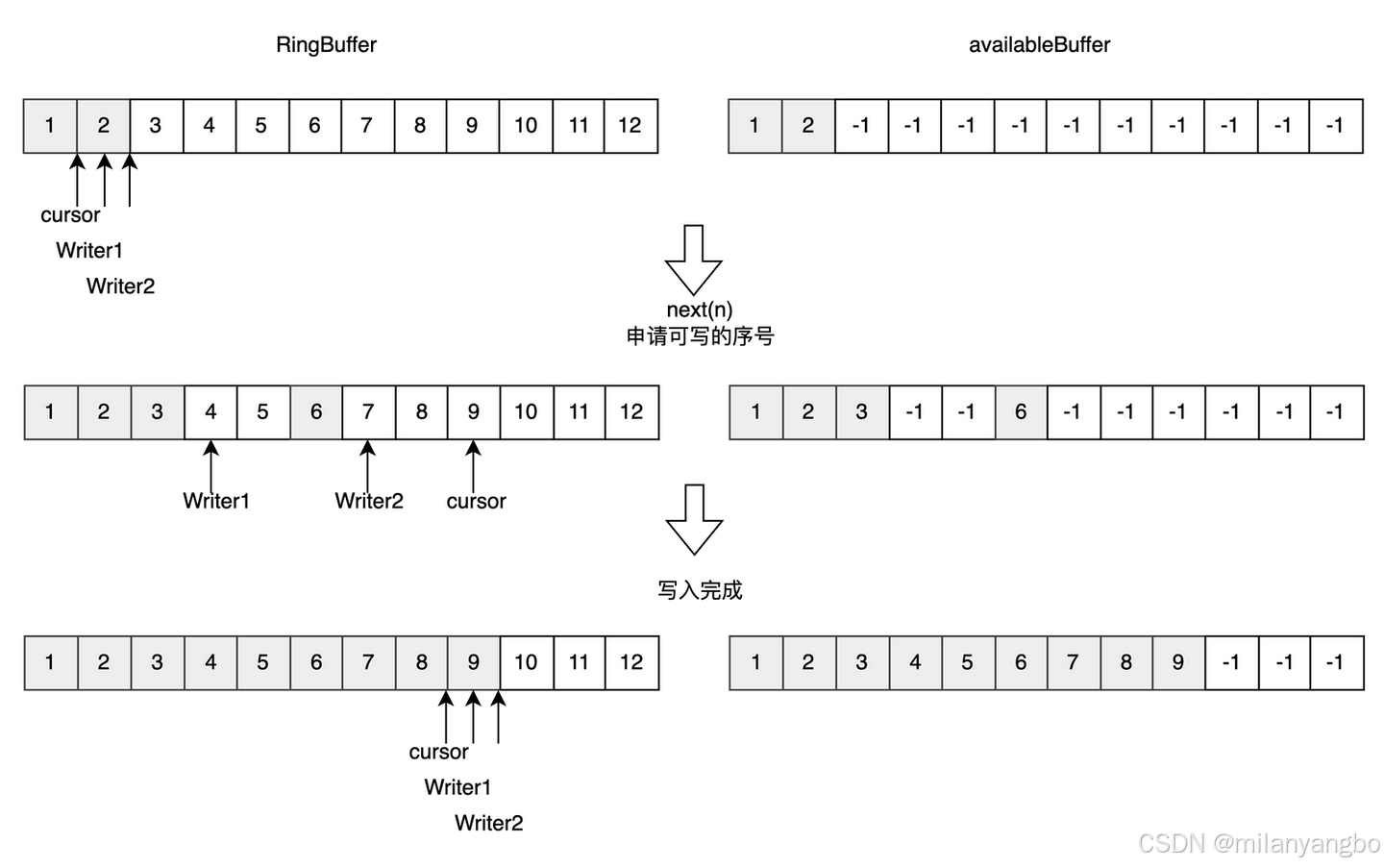
以下代码,展示了如何通过CAS操作来尝试获取Ring Buffer中的可用空间,并确保了多线程环境下的安全性。
// 尝试获取可用缓冲区空间
public long tryNext(int n) throws InsufficientCapacityException
{
// ......
long current,next;
do
{
// 此处先将写指针的当前值备份一下
current = cursor.get();
// 预计写指针将要移动到的位置
next = current + n;
// 判断是否可用的缓冲区空间
if (!hasAvailableCapacity(gatingSequences, n, current)){
throw InsufficientCapacityException.INSTANCE;
}
// 通过cas判断申请的空间是否已经被其他生产者占据
}while (!cursor.compareAndSet(current, next));
return next;
}
缓存行填充
内存的访问速度与处理器运行速度之间存在显著差距,这种速度不匹配会导致处理器频繁等待数据,降低整体计算效率。为解决这一问题,现代处理器在内存与处理器之间引入了多级缓存系统(L1/L2/L3 Cache),其中缓存行(Cache Line)是缓存的基本单位。
1)典型缓存行大小:现代处理器普遍采用64字节缓存行(部分旧处理器为32字节)。
2)空间局部性原理:缓存行设计利用了程序访问数据的空间局部性,即处理器倾向于访问连续的内存块。通过一次性加载整个缓存行(如64字节),处理器可高效读取多个相邻数据项,显著提升访问效率。
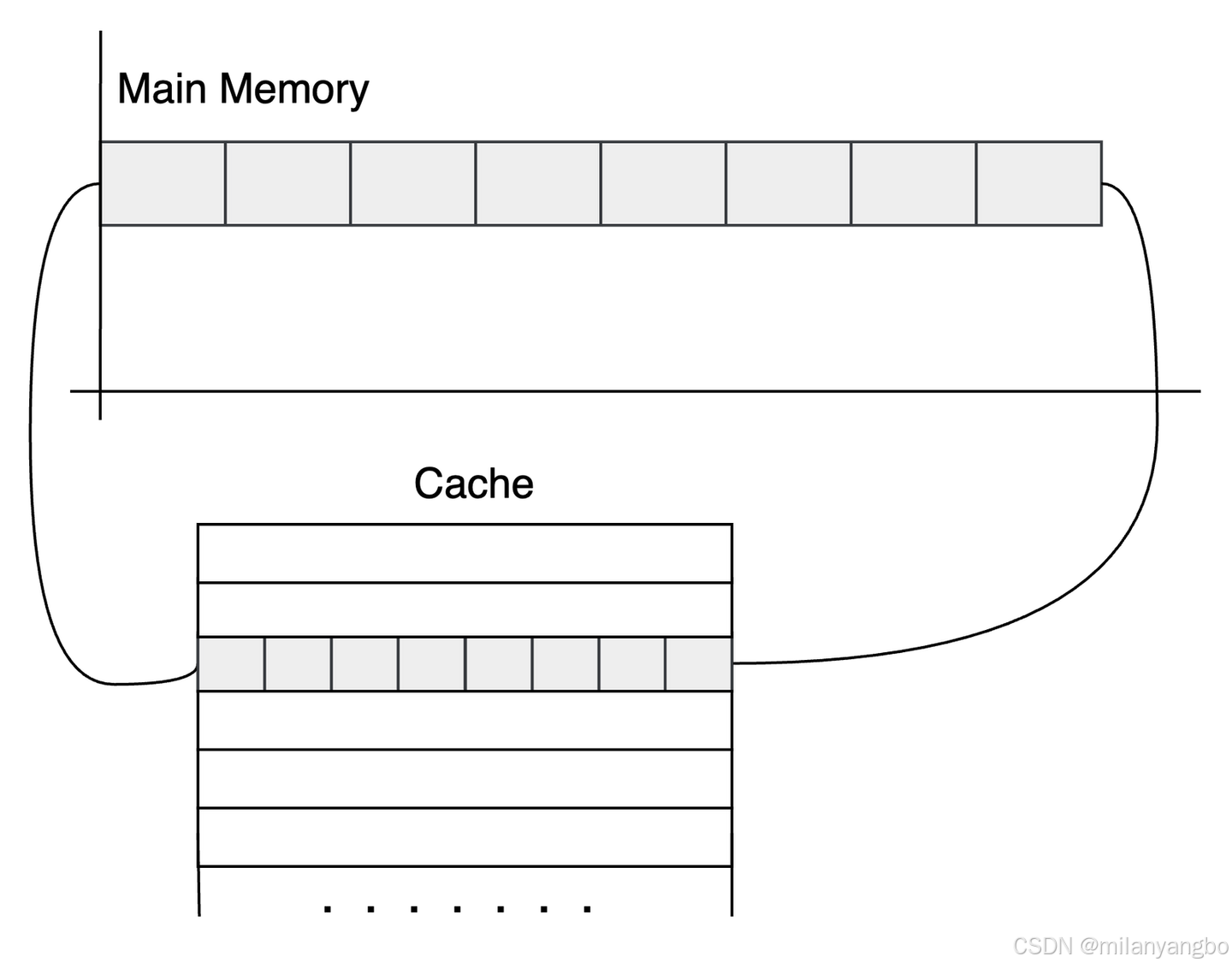
以Java语言为例,一个long类型的变量占用8字节的内存空间,因此在一个64字节的缓存行中,理论上可以存储8个long类型的变量。这种设计使得处理器在读取数据时,能够一次性从内存中读取多个连续的数据项,从而显著提高数据访问的效率。这就是所谓的空间局部性原理,它是计算机系统设计中的一种重要优化策略。
public class CacheLineEffect {
// 考虑一般缓存行大小是64字节,一个 long 类型占8字节
static long[][] arr;
public static void main(String[] args) {
arr = new long[1024 * 1024][];
for (int i = 0; i < 1024 * 1024; i++) {
arr[i] = new long[8]; // 每个缓存行存储8个long变量
for (int j = 0; j < 8; j++) {
arr[i][j] = 0L;
}
}
long sum = 0L;
// 利用缓存行的特性,连续访问同一缓存行内的数据,触发缓存命中,性能更高。
for (int i = 0; i < 1024 * 1024; i+=1) {
for(int j =0; j < 8;j++){
sum = arr[i][j];
}
}
// 不利用缓存行的特性,导致频繁的缓存未命中,需从主内存加载数据,性能显著下降。
for (int i = 0; i < 8; i+=1) {
for(int j =0; j < 1024 * 1024;j++){
sum = arr[j][i];
}
}
}
}
然而,缓存行的这种 "免费加载" 特性存在潜在问题。假设一个生产者和一个消费者各自持有一个 long 类型指针,若这两个指针位于同一个缓存行,当生产者线程修改其指针值时,整个缓存行会被标记为 "脏",导致消费者线程的缓存指针值失效,需重新从主内存加载。
在多核处理器中,为了保证每个核的缓存视图的一致性,通常会采用缓存一致性协议(如MESI协议)。当一个核在其缓存中修改了数据,其他核的相同缓存行就会被标记为无效,即使它要访问的数据并未被修改。
这种无法充分利用缓存行特性的现象,被称为缓存行伪共享(False sharing)。由于缓存行伪共享,线程需要频繁地从主内存中重新加载数据,这会导致大量的缓存未命中,严重影响性能。同时,由于缓存一致性协议的存在,伪共享还会增加处理器间的同步开销。
为了解决伪共享问题,Disruptor框架采用了缓冲行填充(Cache line padding)的技术,通过增加填充来确保Ring Buffer的指针不会和其他变量同时存在于一个缓存行中。这样,就避免了伪共享,消除了与其他变量的意外冲突,减少了不必要的缓存未命中。
public long p1, p2, p3, p4, p5, p6, p7; // cache line padding
private volatile long cursor = INITIAL_CURSOR_VALUE;
public long p8, p9, p10, p11, p12, p13, p14; // cache line padding
未完待续
很高兴与你相遇!如果你喜欢本文内容,记得关注哦!!!
本文来自博客园,作者:poemyang,转载请注明原文链接:https://www.cnblogs.com/poemyang/p/19338254

 浙公网安备 33010602011771号
浙公网安备 33010602011771号