
从硬盘I/O到网络传输:Kafka与RocketMQ读写模型及零拷贝技术深度对比
消息写读
在Kafka的数据存储架构中,一个主题由一个或多个分区组成。在物理存储上,每个主题-分区都对应着硬盘上的一个独立目录,而消息数据则以日志段文件(Log Segment)的形式存储在这些目录中。随着数据的不断写入,当一个日志段文件达到预设的大小(例如1GB)或时间阈值时,它会被关闭并变为只读,同时一个新的可写日志段文件会被创建。这个过程称为日志滚动(Log Rolling)。
从单个分区的微观视角看,所有消息都是以追加(Append-only)的方式顺序写入当前活跃的日志段文件。顺序写入几乎消除了硬盘的寻道时间,其性能接近于内存的读写速度。再结合操作系统的页缓存(Page Cache)机制以及零拷贝(Zero-Copy)技术,只要分区文件的总数在硬件承载范围内,Kafka就能实现极高的数据吞吐量。
然而,当一个Kafka集群中的分区数量失控时(例如,成千上万个主题,每个主题又有数十个分区),问题就会浮现。从操作系统的全局视角来看,硬盘控制器需要在极短的时间内响应来自成百上千个不同文件的写请求。这意味着物理硬盘的磁头必须在这些文件的不同位置之间频繁移动,即所谓的硬盘寻道。这种高并发的、对不同文件位置的写入,使得宏观上的硬盘I/O模式退化为事实上的随机写。
尽管写入端存在这种潜在风险,但Kafka的多分区文件设计为消费端读取消息带来了显著的优势。首先,它天然支持批量读取消息。消费者可以一次性从Broker拉取一个数据块(例如1MB)。这种批量处理的方式极大地减少了网络往返的开销和系统调用的次数。更重要的是,当消费者顺序消费一个分区时,当第一批数据从硬盘读入页面缓存后,后续的顺序读取请求极有可能直接命中缓存。
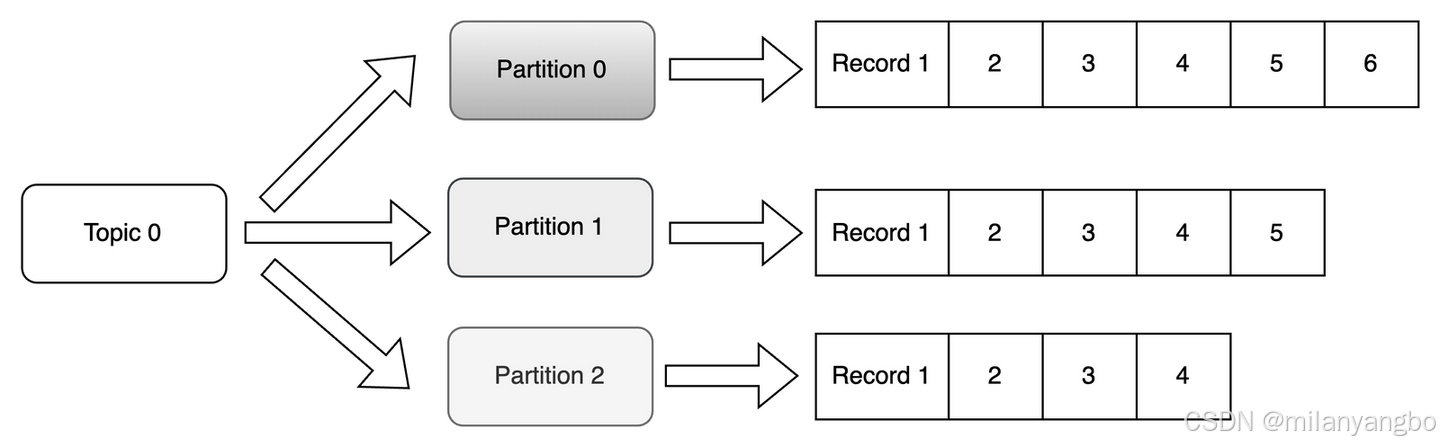
在RocketMQ中,所有主题的所有消息数据,无论其逻辑归属如何,都会被首先写入到一个名为提交日志(CommitLog)的中心化大文件中。这个CommitLog文件由多个固定大小(默认为1GB)的文件顺序组成,当前只有一个文件处于可写状态。因为所有写操作都集中在这一点,即便随着主题和队列数量的急剧增加,硬盘在同一时间也只对一个文件进行追加写入,从而保证了绝对的顺序写。为了进一步提升I/O效率,RocketMQ采用内存映射(mmap)技术来读写CommitLog。
当消息需要被消费时,直接扫描庞大的CommitLog显然是低效的。为此,RocketMQ为每个主题的每个消息队列(ConsumeQueue)建立了一个独立的、轻量级的消费队列文件。每个ConsumeQueue条目都是固定长度的(20字节),其中存储了该消息在CommitLog中的物理偏移量(Offset)(8字节)、消息总大小(Size)(4字节)以及消息Tag的哈希码(8字节)。当消费者拉取消息时,它首先顺序读取对应ConsumeQueue文件中的索引条目,根据获取到的物理偏移量,再到CommitLog中定位并读取到完整的消息数据。这种“先读索引,再读数据”分离的模式,既保证了写入的绝对顺序性,又实现了消费时的高效查找。
此外,为了支持按消息Key或时间范围等维度的快速查询,RocketMQ还提供了可选的索引文件(IndexFile)。其底层数据结构本质上是一个存储在硬盘上的哈希表。IndexFile由文件头、哈希槽(Slot Table)和索引条目列表(Index Linked List)三部分组成。当根据Key查找时,先计算Key的哈希值并定位到对应的哈希槽,该槽内存储了指向最新一条索引条目的指针。由于可能存在哈希冲突,具有相同哈希值的索引条目会通过前向指针形成一个链表。
零拷贝
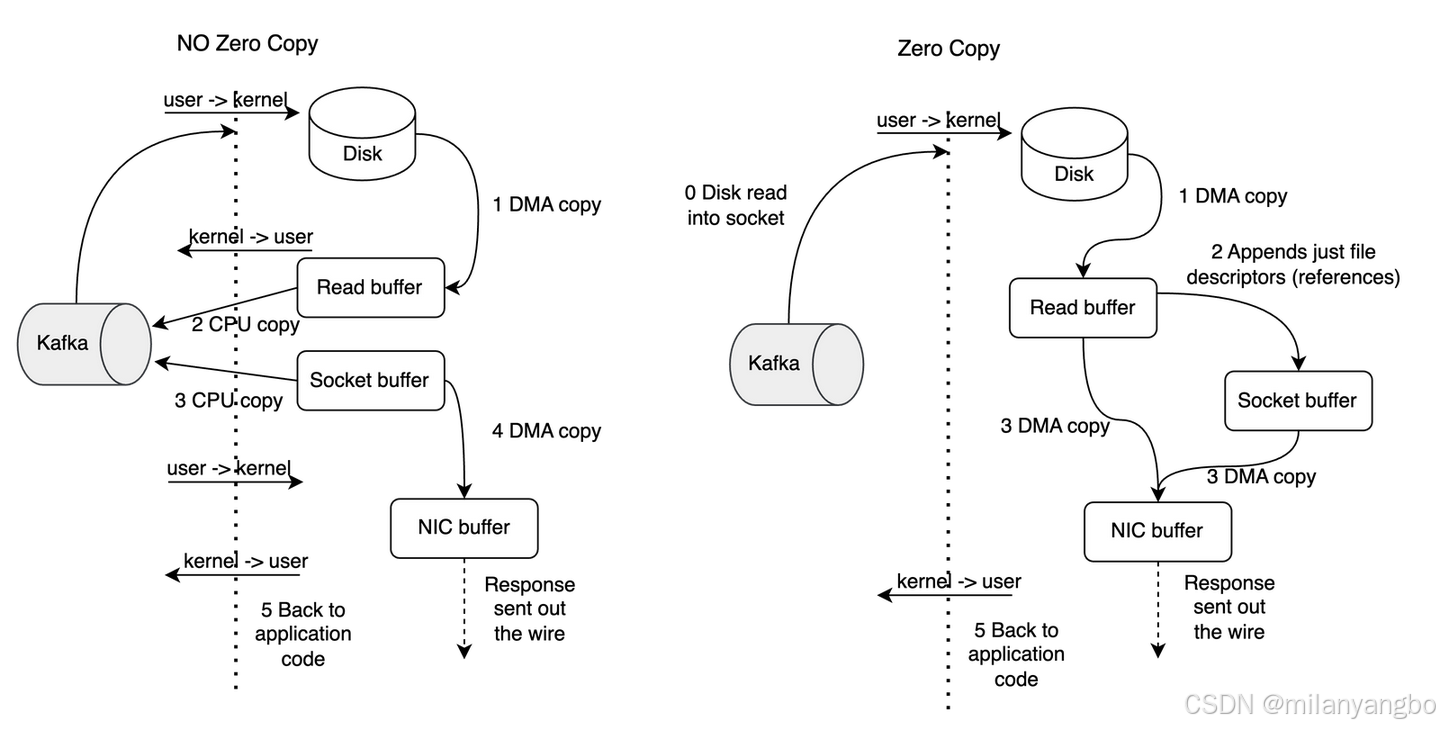
零拷贝(Zero-Copy),其根本目标是减少甚至消除数据在内核空间(Kernel Space)和用户空间(User Space)之间不必要的拷贝。在传统的数据传输流程中,数据从硬盘到网络发送的路径通常是:硬盘 -> 内核缓冲区 -> 用户缓冲区 -> 内核Socket缓冲区 -> 网卡。这个过程中,数据至少被拷贝了四次,并且伴随着多次处理器上下文的切换(从用户态到内核态),这些操作都会大量消耗处理器和内存资源。
零拷贝技术通过更底层的系统调用,让内核直接在不同的I/O设备之间传递数据,从而绕过用户空间的干预。其实现高度依赖于操作系统的支持,例如在LINUX中,最经典的系统调用是sendfile和splice,以及通过mmap实现的变相零拷贝。sendfile指令可以直接将数据从一个文件描述符(如硬盘文件)传输到另一个文件描述符(如网络套接字),数据全程在内核空间中流转,避免了进入用户空间,从而将拷贝次数从四次减少到两次(内核缓冲区到Socket缓冲区)。
Kafka在向消费者发送数据时,广泛使用了Java NIO库中的FileChannel.transferTo()方法。在LINUX系统上,这个Java方法底层正是通过sendfile系统调用实现的。当消费者请求数据时,Kafka Broker可以直接将硬盘上的日志段文件(通常已存在于操作系统的页面缓存中)的数据块直接复制到网卡缓冲区,整个过程数据没有进入Kafka的Java虚拟机的堆内存。
RocketMQ 则主要通过内存映射来利用零拷贝的优势。它使用Java的MappedByteBuffer将核心数据文件(如CommitLog)映射到内存。
1)写入时:生产者发送的消息被写入到这个内存映射区域,这几乎等同于内存写入,速度极快。后续由操作系统负责将这部分内存(脏页)异步刷写回硬盘。
2)读取时:当消费者需要数据时,RocketMQ可以直接从内存映射区读取。此外,RocketMQ还会主动对MappedByteBuffer进行预热,即在服务启动时就将文件内容提前加载到物理内存(页面缓存)中,确保后续的读写操作都能命中内存。
未完待续
很高兴与你相遇!如果你喜欢本文内容,记得关注哦!!!
本文来自博客园,作者:poemyang,转载请注明原文链接:https://www.cnblogs.com/poemyang/p/19299418

 浙公网安备 33010602011771号
浙公网安备 33010602011771号