3、内存管理机制
一、什么是垃圾回收机制?
垃圾回收机制(简称GC)是Python解释器自带一种机制,专门用来回收不可用的变量值所占用的内存空间。
二、什么是不可用的变量?
简单来讲,我们定义变量将变量值存起来的目的是为了以后取出来使用,而取得变量值需要通过其绑定的直接引用
而取得变量值需要通过其绑定的直接引用(如x=10,10被x直接引用)或间接引用(如y=x,x=10,10被x直接引用,而被y间接引用)
所以当一个变量值不再绑定任何引用时,我们就无法再访问到该变量值了,该变量值自然就是没有用的,就应该被当成一个垃圾回收。
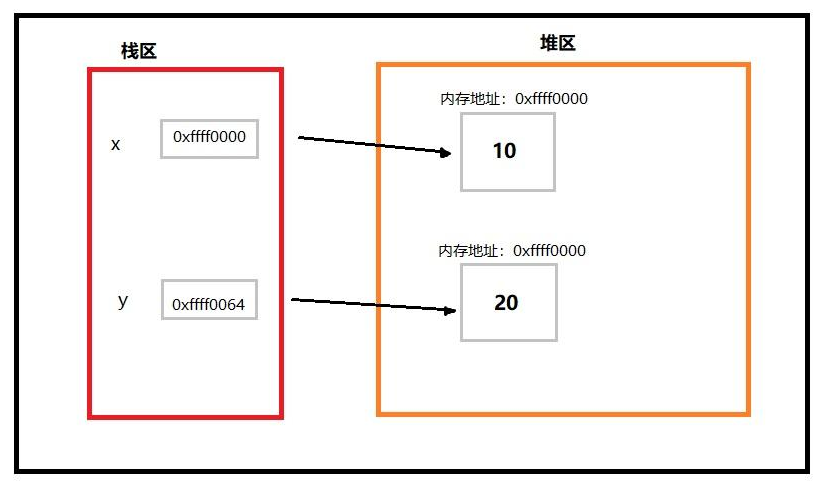
三、堆区与栈区
在定义变量时,变量名与变量值都是需要存储的,分别对应内存中的两块区域:堆区与栈区。
(1)变量名与值内存地址的关联关系存放于栈区
(2)变量值存放于堆区,内存管理回收的则是堆区的内容。
x = 10
y = 20
# 堆区栈区如下图
四、直接引用与间接引用
l2 = [20, 30] # 列表本身被变量名l2直接引用,包含的元素被列表间接引用
x = 10 # 值10被变量名x直接引用
l1 = [X, L2] # 列表本身被变量名l1直接引用,包含的元素被列表间接引
# [10, [20, 30]] # L1输出结果
五、内存管理机制之垃圾回收机制GC
1.引用计数
变量值被变量名关联的次数
# 引用计数增加:
x = 10 # 10引用计数为1
y = x # 10引用计数为2
# 引用计数减少:
x = 20 # 10的引用计数为1
del y # 10的引用计数为0
值的引用计数一旦变为0,其占用的内存地址就应该被解释器的垃圾回收机制回收
优点:简单、直观实时性,只要没有了引用就释放资源。
缺点:循环引用时,无法回收
2.标记/清除
用于解决循环引用导致的内存泄漏问题
# 什么是循环引用呢?
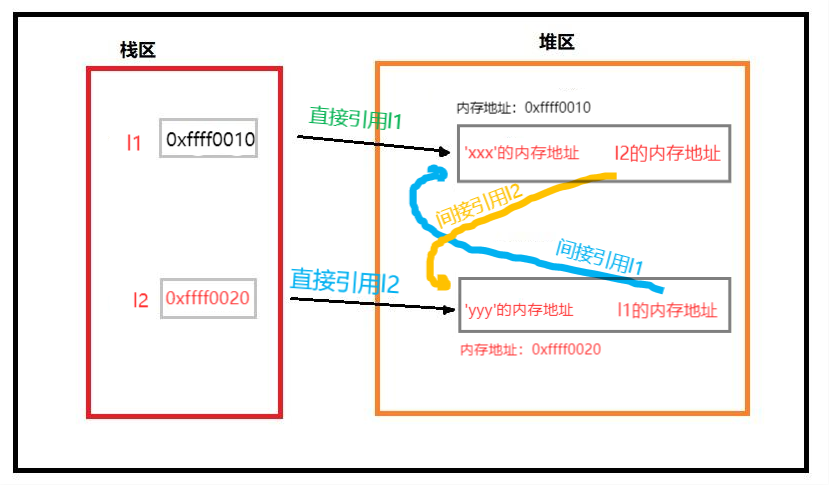
# 如下我们定义了两个列表,简称列表1与列表2,变量名l1指向列表1,变量名l2指向列表2
l1=['xxx'] # 列表1被引用一次,列表1的引用计数变为1
l2=['yyy'] # 列表2被引用一次,列表2的引用计数变为1
l1.append(l2) # 把列表2追加到l1中作为第二个元素,列表2的引用计数变为2
l2.append(l1) # 把列表1追加到l2中作为第二个元素,列表1的引用计数变为2
# l1与l2之间有相互引用
# l1 = ['xxx'的内存地址,列表2的内存地址]
# l2 = ['yyy'的内存地址,列表1的内存地址]
['xxx', ['yyy', [...]]] # l1此时的状态
['yyy', ['xxx', [...]]] # l2此时的状态
# 如果我们这样操作一下会发生什么呢?
del l1 # 列表1的引用计数减1,列表1的引用计数变为1
del l2 # 列表2的引用计数减1,列表2的引用计数变为1
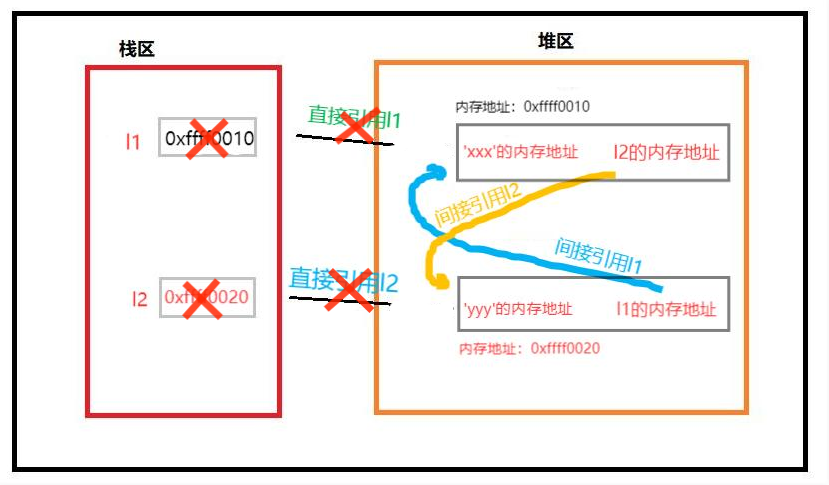
现在我们无法通过变量名访问到这两个列表,但是由于这两个列表相互吸引,引用计数均不为0,那么引用计数机制不就无法将它回收了吗,
所以Python引入了“标记-清除” 与“分代回收”来分别解决引用计数的循环引用与效率低的问题
标记/清除算法的核心:
如果一个值没有关联任何一条以直接引用作为出发点的引用,那么该值就会被标记下来,并且清除。
或者说 一个变量值不存在任何以栈区为出发点的引用,那么标记/清除算法就认为它是垃圾标记/清除算法的做法:
当应用程序可用的内存空间被耗尽的时,就会停止整个程序,然后进行两项工作,第一项则是标记,第二项则是清除
3.分代回收
基于引用计数的回收机制,每次回收内存,都需要把所有对象的引用计数都遍历一遍,这是非常消耗时间的,于是引入了分代回收来提高回收效率,分代回收采用的是用“空间换时间”的策略。
分代回收的核心思想:在历经多次扫描的情况下,都没有被回收的变量,gc机制就会认为,该变量是常用变量,gc对其扫描的频率会降低
优点:降低扫描数数量,提升效率
缺点: 有个别数据无法得到及时的处理
六、内存管理机制之小整数池[-5, 256]
Python为了优化速度,使用了小整数池,这些整数对象是提前建立好的 避免为整数频繁申请和销毁内存空间。不会被垃圾回收。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号