python字符串和编码
文内容取自“廖雪峰官方网站的python教程”
https://www.liaoxuefeng.com/wiki/1016959663602400/1017075323632896
字符编码
ASCII编码:只有127个字符被编码到计算机,英文字母大小写、数字、一些符号;
Unicode编码:把所有语言都统一到一套编码中;
两者区别
ASCII编码是1个字节,Unicode编码是2个字节
问题:文本全部英文,Unicode编码比ASCII编码多一倍空间,在存储上不划算。
解决:出现UTF-8编码

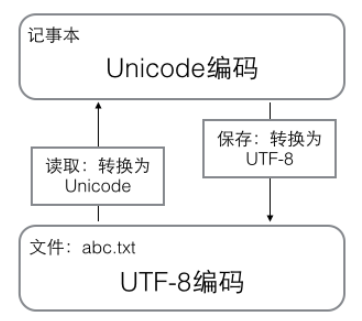
计算机系统通用的字符编码工作方式
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输时,转为UTF-8编码。
用记事本编辑时,从文件读取的UTF-8字符被转换为Unicode字符存到内存里,编辑完成后,保存时再把Unicode转换为UTF-8保存到文件。
示意图如下:
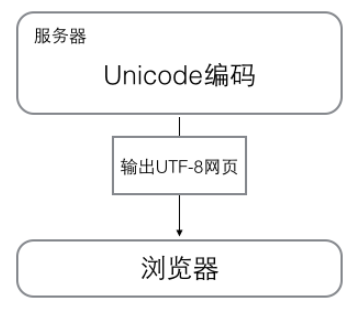
浏览网页时,服务器会把动态生成的Unicode内容转换成UTF-8再传输到浏览器。
示意图如下:
python的字符串
单个字符编码,使用ord()函数获取字符的整数表示,chr()函数把编码转换为对应字符
>>>ord('A')
65
>>>chr(66)
'B'
python对于bytes类型的数据用带b前缀的单引号或双引号表示
x = b'ABC'
注意
ABC和b'ABC' 前者是str,后者虽然内容显示和前者一致,但bytes的每个字符只占用一个字节。
已Unicode表示的str通过encode()方法可以编码为指定的bytes
>>>'ABC'.encode('ascii')
b

 浙公网安备 33010602011771号
浙公网安备 33010602011771号