$2018/8/15 = Day \ \ 1$杂题整理
\(\mathcal{Morning}\)
\(Task1\)高精度\(\times\)高精度
哦呵呵……真是喜闻乐见啊,我发现这一部分比较有意思于是就打算整理下来233。窝萌现在有一个整数\(A = \sum \limits _{i=0}^{\lfloor log_{10}A \rfloor}{a_i \times 10^i}\) 和另一个整数\(B = \sum \limits _{i=0}^{\lfloor log_{10}B \rfloor}{b_i \times 10^i}\) 那么对于这两个而言,我们就可以利用\(FFT\)的思路得出$$Ans_{k} = \sum \limits {}^{}{A_i \times B \times 10^k}$$233就是一个辣鸡卷积而已\(233\)
哦呵呵把高精度的代码存一下日后慢慢练……这一块而还不是很熟……写是能写得出来能不能调出来就不一定了
struct data{
int a[1000], len;
};
data operator + (const data &a, const data &b){
data c;
c.len = max(a.len, b.len);
for (int i = 0; i <= c.len; i++)
c.a[i] = a.a[i] + b.a[i];
for (int i = 0; i <= c.len; i++){
c.a[i + 1] += c.a[i] / 10;
c.a[i] %= 10;
}
if (c.a[c.len + 1]) c.len++;
return c;
}
data operator - (const data &a, const data &b){
data c;
c.len = a.len;
for (int i = 0; i <= c.len; i++)
c.a[i] = a.a[i] - b.a[i];
for (int i = 0; i <= c.len; i++)
if (c.a[i] < 0){
c.a[i + 1]--;
c.a[i] += 10;
}
while (c.a[c.len] == 0) c.len--;
return c;
}
data operator * (const data &a, const int &b){
data c;
c.len = a.len;
for (int i = 0; i <= c.len; i++)
c.a[i] = a.a[i] * b;
for (int i = 0; i <= c.len + 10; i++){
c.a[i + 1] += c.a[i] / 10;
c.a[i] %= 10;
}
for (int i = c.len + 10; i >= 0; i--)
if (c.a[i]){
c.len = i;
break;
}
return c;
}
data operator * (const data &a, const data &b){
data c;
c.len = a.len + b.len;
for (int i = 0; i <= a.len; i++)
for (int j = 0; j <= b.len; j++)
c.a[i + j] += a.a[i] * b.a[j];
for (int i = 0; i <= c.len + 10; i++){
c.a[i + 1] += c.a[i] / 10;
c.a[i] %= 10;
}
for (int i = c.len + 10; i >= 0; i--)
if (c.a[i]){
c.len = i;
break;
}
return c;
}
data operator / (const data &a, const int &b){
data c;
int d = 0;
for (int i = a.len; i >= 0; i--){
d = d * 10 + a.a[i];
c.a[i] = d / b;
d %= b;
}
for (int i = a.len; i >= 0; i--)
if (c.a[i]){
c.len = i;
break;
}
return c;
}
\(Task2\)一道例题
\(\mathcal{\color{red}{Description}}\)
有一个数列 \(A\),已知所有的 \(A[i]\) 都是 \([1; n]\) 内的自然数,并且知道对于一些 \(A[i]\) 不能取哪些值,我们定义一个数列的积为该数列所有元素的乘积,要求你求出所有可能的数列的积的和 \(mod \ \ 1000000007\) 的值。
第一行三个整数 \(n,m,k\),分别表示数列元素的取值范围,数列元素个数,以及已知的限制条数。接下来 \(k\) 行,每行两个正整数 \(x,y\) 表示 \(A[x]\) 的值不能是 \(y\)。
\(n ≤ 10^9; m ≤ 10^9; k ≤ 10^5\)
\(\mathcal{\color{red}{Solution}}\)
假设我们用\(base_{i,j}=1 \ \ or \ \ 0\)表示第\(i\)个数可不可以取。
我们思考暴力的话可以大约$$Ans = \prod \limits_{i=1}^{m}{\sum \limits_{j=1}^{n}{base_{i,j} \times j}}$$这东西是可以经过毒瘤的分配律推出来的……积的和就是和的积……类似这么一个东西。
然后我们思考,一看数据范围就可以知道这个题应该和m没多大关系我们只需要求\(k\)次即可,因为对窝萌而言,那个\(sum\)是可以\(\Theta(1)\)求出来的,并且对于那些没有约束的项窝萌也是可以\(\Theta(1)\)求出来的,所以我们只用去考虑那些有约束条件的几项,胡搞一下就行\(233\)
其实这个题我当时不是很会的原因是因为我并不知道毒瘤的分配律还有这种毒瘤的方法\(2333\)
我发现这个题的原题是\(HNOI2012\)容易题……
于是就直接贴代码吧……他有重复的需要忽略,在样例里给出了,这一点很良心\(hhh\)
#include <cstdio>
#include <bitset>
#include <iostream>
#include <algorithm>
#define ll long long
#define MAXN 1000010
#define mod 1000000007
using namespace std ;
struct node{
ll L, R ;
}In[MAXN] ; ll S[MAXN], J, Last ;
ll L, R, Ans, N, M, K, i, T, base ;
inline ll qr(){
ll k = 0 ; char c = getchar() ;
while(!isdigit(c)) c = getchar() ;
while(isdigit(c)) k = (k << 1) + (k << 3) + c - 48, c = getchar() ;
return k ;
}
inline ll expow(ll A, ll B){
ll res = 1 ;
while(B){
if(B & 1) res = res * A % mod ;
A = A * A % mod ;
B >>= 1 ;
}
return res % mod ;
}
inline bool compare(node A, node B){
if(A.L == B.L) return A.R < B.R ;
return A.L < B.L ;
}
int main(){
cin >> N >> M >> K ;
T = M, base = (1 + N) * N / 2 ; base %= mod ;
for(i = 1; i <= K ; ++ i) In[i].L = qr(), In[i].R = qr() ;
sort(In + 1, In + K + 1, compare) ;
for(i = 2; i <= K ; ++ i)
if(In[i].R == In[i - 1].R && In[i].L == In[i - 1].L ) In[i - 1].L = 19260817000LL ;
sort(In + 1, In + K + 1, compare) ;
for(i = K; In[i].L == 19260817000LL ; -- i) K -- ;
for(i = 1; i <= K ; ++ i) {
L = In[i].L, R = In[i].R ;
if (L != Last) T --, Last = L, ++ J ;
S[J] -= R ;
}
Ans = (Ans + expow(base, T)) % mod ;
for(i = 1; i <= J ; ++ i)
Ans = Ans * (base + S[i]) % mod ;
cout << ( Ans + mod ) % mod << endl ;
}
\(Task3\)一道被我给秒了的例题\(233\)
\(\mathcal{\color{red}{Description}}\)
著名核物理专家 \(pks(233)\) 提出了核聚变特征值这一重要概念。核聚变特征值分别为 \(x\) 和 \(y\) 的两个原子进行核聚变,能产生数值为 \(sgcd(x, y)\) 的核聚变反应强度。其中, \(sgcd(x, y)\) 表示 \(x\) 和 \(y\) 的次大公约数,即能同时整除\(x,y\) 的正整数中第二大的数。如果次大公约数不存在则说明无法核聚变,此时 \(sgcd(x; y) = −1\)。
现在有 \(n\) 个原子,核聚变特征值分别为 \(a_1, a_2,· · · , a_n\)。然后P 又从兜里掏出一个核聚变特征值为 \(a_1\) 的原子,你需要计算出这个原子与其它 \(n\) 个原子分别进行核聚变反应时的核聚变反应强度,即 \(sgcd(a1,a1), sgcd(a1,a2),…; sgcd(a1, an)\)。其中\(n ≤ 100000, a_i ≤ 10^{12}\)
\(\mathcal{\color{red}{Solution}}\)
\(2333\)一个比较显然当时居然没看出来的策略是,找到\(gcd\)之后除以\(lcd\),就是除以最小公共质因子。那我们考虑怎么找\(lcd\),其实就是很简单的,我们质因数分解一下\(a_1\),然后对于每个\(a_i\),我们挨个一下从小到大枚举一下\(a_1\)质因子,而因为\(lcd\)一定是质数……所以我们胡搞就可以。最后总复杂度\(\Theta(nlogn)\)。
好的,作为一眼就把正解看出来的我并不知道复杂度怎么算……并且我认为复杂度不可能是\(nlogn\)!绝对不可能!
真香\(233\)
好吧,质因子个数(不算指数)是\(log\)的,也就是说窝萌最多枚举\(log\)次……是完全可以过的\(233\)
\(Task4\)裴蜀定理
\(emmmm\)好像就是不定方程那一节的一点东西\(233\)……就是说形如\(ax+by = c\)的不定方程若有整数解,必须保证\(gcd(a, b) | c\)。虽然这个定理看起来只能用来\(exgcd\)解不定方程啥的,但是它还可以乱搞一些事情——
\(\mathcal{\color{red}{Description}}\)
给出 \(n\) 个正整数 \((A_1,· · · , A_n)\)。整数序列 \((X_1, · · · , X_n)\) 可以取任意值,要使得 \(S = A_1X_1 + · · · + A_nX_n > 0\), 且 \(S\) 的值最小。求 \(S\)。
\(\mathcal{\color{red}{Solution}}\)
窝萌稍微转化一下就可以发现,这就类似一个不定方程……而因为已经强调了\(X_1 \cdots X_n\)是一个整数序列,所以相当于限制了必须有整数解……那么等式右边的最小值就只能是所有\(A_i\)的\(gcd\)了\(qwqq\)……如果原题目改成"\(mod \ \ k\)意义下最小" 的话,我们就再\(gcd\)上一个\(k\)就行。因为窝萌可以把原式写作$$\sum \limits _{i=1}^{n}{A_iX_i} - kp > 0, p \in N+$$嗯,然后就做完了\(qwqqq\)
\(Task5\)一个比较毒瘤的题……
\(\mathcal{\color{red}{Description}}\) \(\mathcal{\color{red}{Description}}\)
\(5000000\) 组询问,每次给出 \(n\),问 \(n\) 的约数个数。\(n ≤ 10^6\)
\(\mathcal{\color{red}{Solution}}\)
哦呵呵,我就直接把“官方题解”粘过来吧
如果能对 \(n\) 进行质因数分解,$$n = \prod \limits_{}{}{p_i{c_i}}$$其中 \(p_i\) 均为质数。
那么约数个数为\(∏(c_i + 1)\)。用埃氏筛法预处理出 \(2\) 到 \(1000000\) 每个数的最小质因子。
某个非质数第一次被标记时,一定是枚举到了它的最小质因子。
多次令 \(n = n/\) 它的最小质因子,一定会变成 \(1\)。记录下过程中的质因子,就做到了 \(\Theta(logn)\) 质因数分解。
\(Task6\)又一个比较毒瘤的题
\(\mathcal{\color{red}{Description}}\)
给定 n,求有多少正整数数对 (x, y) 满足 $$\frac{1}{x} + \frac{1}{y} = \frac{1}{n!}$$ \(n ≤ 10^6\)
\(\mathcal{\color{red}{Solution}}\)
\(233\)窝萌思考一个比较显然的问题,就是一定会有\(y>n!\)。那窝萌不妨设\(y = n!+T\),那么带回到原式里面就会有$$\frac{1}{x} + \frac{1}{n!+T} = \frac{1}{n!}$$继而有$$x = \frac{n!^2}{T}+n!$$那么其实一共就有\(\tau(n!^2)\)个合法答案,所以我们转而求\(n!^2\)的约数数量。
但是显然的是我们并不可以直接求解,当然我不知道高精度之后会怎么样,估计\(nlogn\)一下还是有可能过的。但是考虑到常数巨大,所以卡过\(1e6\)基本上是痴人说梦。所以我们思考一种清新脱俗我根本想不出来的做法。
窝萌考虑筛出所有的\(1-n\)素数来,然后对于一个素数而言,由于窝萌要判断的对象是\(n!\),他有一个奇妙的性质就是$$n!=\prod \limits_{i=1}^{n}{i}$$那么也就是说我们只需要判断对于一个当前给定的素数\(p\),在\(1-n\)的所有数里面,\(p\)作为因子出现了多少次即可。那么也就是这个式子:
$$Ans = \prod \limits _{p \in prime }^{p \leq n}{\sum \limits _{i \geq 1}{pi \leq n}{\lfloor \frac{n}{p^i}} \rfloor +1}$$
我们每次遍历一遍,保证只加一次,譬如质数\(3\),三的倍数的个数产生的贡献是一,三的平方的倍数产生的贡献是二,但是我们从前往后扫的话,每次就只要增长一个贡献即可(类似于去重操作\(233\))
\(\mathcal{Afternoon}\)
嗝……考了个试……啥都不会\(233\)
\(\mathcal{\color{red}{Description \ \ of \ \ T1}}\)
给定 \(n\),\(a[1] \cdots a[n]\),求 \(a[1]!+a[2]!+...+a[n]!\)
\(\mathcal{\color{red}{Solution}}\)
\(sb\)高精度,调了半天……原因详情请见游记……得分\(100pts\)
#include <cstdio>
#include <cstring>
#include <iostream>
#include <algorithm>
#define MAX 3030
using namespace std ;
struct node{
int A[MAX], Len ;
}Ans, _Fac[MAX] ;
int N, base[MAX], i, j, Mx ;
node operator + (const node &J, const node &L){
node ret ; memset(ret.A, 0, sizeof(ret.A)) ;
ret.Len = max(J.Len, L.Len) ;
for (j = 0; j <= ret.Len ; ++ j) ret.A[j] = J.A[j] + L.A[j] ;
for (j = 0; j <= ret.Len ; ++ j) ret.A[j + 1] += ret.A[j] / 10, ret.A[j] %= 10 ;
if (ret.A[ret.Len + 1]) ret.Len ++ ;
return ret ;
}
node operator * (const node &J, const int &L){
node ret ; memset(ret.A, 0, sizeof(ret.A)) ;
ret.Len = J.Len ;
for (j = 0; j <= ret.Len ; ++ j) ret.A[j] = J.A[j] * L ;
for (j = 0; j <= ret.Len + 10; ++ j) ret.A[j + 1] += ret.A[j] / 10, ret.A[j] %= 10 ;
for (j = ret.Len + 10; j >= 0; -- j)
if (ret.A[j]){ret.Len = j ; break ;}
return ret ;
}
inline int qr(){
int k = 0 ; char c = getchar() ;
while(!isdigit(c)) c = getchar() ;
while(isdigit(c)) k = (k << 1) + (k << 3) + c - 48, c = getchar() ;
return k ;
}
inline bool cmp(int A, int B){return A > B ;}
int main(){
freopen("a.in", "r", stdin) ;
freopen("a.out", "w", stdout) ;
cin >> N ;
_Fac[0].A[0] = _Fac[1].A[0] = 1, _Fac[0].Len = _Fac[1].Len = 0 ;
for (i = 1; i <= N; ++ i) base[i] = qr(), Mx = max(base[i], Mx);
for (i = 2; i <= Mx; ++ i) _Fac[i] = _Fac[i - 1] * i ;
for (i = 1; i <= N; ++ i) Ans = Ans + _Fac[base[i]] ;
for (i = Ans.Len; i >= 0 ; -- i) printf("%d", Ans.A[i]) ;
}
\(\mathcal{\color{red}{Description \ \ of \ \ T2}}\)
给一个 \(n \times m\) 的矩阵染色, 每个点可以染 \(k\) 种颜色, 求没有任意一行或任意一列颜色完全相同的方案数。 答案对 \(998244353\) 取模。 对于\(100\)%的数据满足 \(n,m<=1000000,k<=1000000000\)
\(\mathcal{\color{red}{Solution \ \ of \ \ T2}}\)
其实窝萌是可以\(k^{mn}\)枚举矩阵,然后直接\(\Theta(n^2)\)暴力判断是否合法。总复杂度过不去是真的,但是暴力总是可以暴力的吼。以下是三十分的:
#include <cstdio>
#include <iostream>
#define MAX 2010
#define ll long long
using namespace std ;
int Ans, N, M, K, i, c[MAX][MAX] ;
inline bool Chk(){
for(i = 1; i <= N; i ++){
bool mark = 1 ;
for(int j = 2; j <= M ; j ++) if (c[i][j - 1] != c[i][j]) mark = 0 ;
if(mark) return 0 ;
}
for(i = 1; i <= M; i ++){
bool mark = 1, now = c[i][i] ;
for(int j = 2; j <= N ; j ++) if (c[j][i] != c[j - 1][i]) mark = 0 ;
if(mark) return 0 ;
}
return 1 ;
}
void dfs(int x, int y){
if (y == M + 1) {x ++, y = 1 ;}
if (x == N + 1) {
if(Chk()) Ans ++ ;
return ;
}
for(int j = 1; j <= K ; ++ j) c[x][y] = j, dfs(x, y + 1) ;
}
inline ll expow(ll A, ll B){
ll res = 1 ;
while(B){
if(B & 1) res = res * A % 998244353 ;
A = A * A % 998244353 ;
B >>= 1 ;
}
return res % 998244353 ;
}
int main(){
freopen("b.in", "r", stdin) ;
freopen("b.out", "w", stdout) ;
cin >> N >> M >> K ;
if (N <= 15 && M <= 15 && K <= 1000) dfs(1, 1) ;
else {
int t1 = N, t2 = M ;
N = max(t1, t2), M = min(t1, t2) ;
Ans = expow(expow(K, M) - K, N) - (expow(K, M) - K) % 998244353 ;
}
cout << Ans ; return 0 ;
}
\(hhh\)我发现我是真不会暴搜啊……还是\(yjk\)现场教的我\(2333\)……还有那个特判大数据挂了……\(wzk\)推的式子好像不大行…… \(hhhh\) 然后说正解:容斥(出题人上午讲的组合特别水……然后下午就考容斥……一点也不君子嘤嘤嘤)
\(233\) 我不知道这个容斥是啥意思……但是好像并不妨碍对其他东西的理解……
我们设\(f_{i,j}\) 表示一共有\(i\) 行和\(j\) 列颜色相同的方案数。
那么比较明显的是,有以下几组等式:
稍微解释一下什么意思,这部分我理解的比较清楚的原因是我考试的时候考虑到这里了……如果只有行冲突,行与行是独立的,所以乘法原理直接\(\prod k\) 即可。只有列冲突同理。但是我们思考当出现行和列同时冲突的时候,行列的颜色必须一致,比如你一行和一列当前都假设不合法,那么他们一定都有相同的颜色,所以是\(k\)而不是\(\prod k\) 。
然后窝萌思考这样一个一个容斥:
$Ans = \sum \limits_{i=0}{n}{\sum\limits_{j=0} {(-1)^{i+j} \times C_{n}^{i} C_{m}^{j}} \times f_{i,j} \times k^{(n-i)(m-j)} } $
\(2333\) 其中\(-1\)那一项是容斥的标准操作,然后组合数……就是单纯的组合数,最后一项是枚举剩下的不同色的格子的方案。
题外话:嗯,其实每一项我考场上都考虑出来了——起码说明考虑的比较全面,但是式子还是没推出来……\(GG\)
然后我们预处理阶乘\(+\)枚举\(\Theta(n^2)\) 可以过掉\(70\)%的数据……好像海星\(233\)
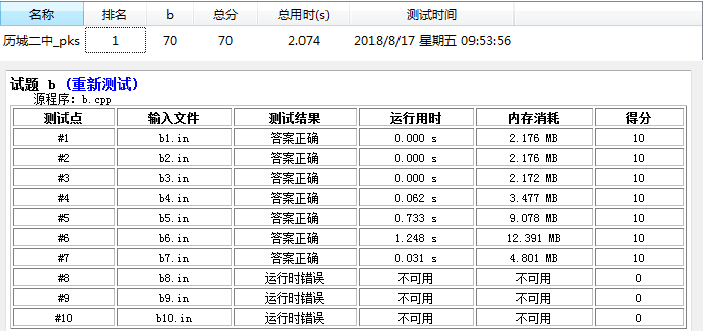
\(2333\)这个题的时限是\(2s\) 这是七十分做法,时间复杂度\(\Theta(n^2logn)\)。
#include <cstdio>
#include <iostream>
#define MAXN 3000
#define ll long long
#define mod 998244353
using namespace std ; ll i, j, Ans ;
ll N, M, k, F[MAXN][MAXN], Fac[MAXN] ;
inline ll expow(ll A, ll B){
ll res = 1 ;
while(B){
if(B & 1) res = res * A % mod ;
A = A * A % mod ;
B >>= 1 ;
}
return res % mod ;
}
int main(){
freopen("b.in", "r", stdin);
freopen("b.out", "w", stdout);
scanf("%lld%lld%lld", &N, &M, &k) ;
Fac[0] = F[0][0] = 1 ; int T = 0 ;
for(i = 1; i <= max(N, M) ; ++ i){
Fac[i] = Fac[i - 1] * i ;
if(i >= 13) Fac[i] %= mod ;
}
for(i = 1; i <= max(N, M) ; ++ i){
F[i][0] = F[0][i] = expow(k, i) ;
if(F[i][0] > mod) F[i][0] %= mod, F[i][1] %= mod ;
}
for(i = 1; i <= N ; ++ i)
for(j = 1; j <= M; ++ j)
F[i][j] = k ;
for(i = 0; i <= N ; ++ i)
for(j = 0; j <= M ; ++ j)
if(i + j & 1)
Ans = (Ans - F[i][j] * (expow(k, (N - i) * (M - j)) * Fac[M] % mod * Fac[N] % mod) % mod
* expow(Fac[i], mod - 2) % mod * expow(Fac[N - i], mod - 2) % mod * expow(Fac[j], mod - 2) % mod * expow(Fac[M - j], mod - 2) % mod) % mod ;
else
Ans = (Ans + F[i][j] * (expow(k, (N - i) * (M - j)) * Fac[M] % mod * Fac[N] % mod) % mod
* expow(Fac[i], mod - 2) % mod * expow(Fac[N - i], mod - 2) % mod * expow(Fac[j], mod - 2) % mod * expow(Fac[M - j], mod - 2) % mod) % mod ;
while(Ans < 0) Ans += mod ;
cout << Ans % mod ;
}
```
然后满分做法嘛,我们考虑只需要给它二项式定理一下。我们思考当\(i =0\)或者\(j=0\) 时,窝萌直接暴力计算即可。而当它们都是正整数时,我们思考把原式变个形,忽略掉\(i = 0,j = 0\)的情况\(放心会加回去的(放心会加回去的)\):
\(Ans' = k\sum\limits_{i=1}^{n}{\sum\limits_{j=1}^{m}{(-1)^{i+j}C_n^iC_m^j \times k^{(n-i)(m-j)}}}\)
\(Ans' = k\sum\limits_{i=1}^{n}{(-1)^iC_n^i\sum\limits_{j=1}^{m}{(-1)^jC_m^j \times (k^{n-i})^{m-j}}}\)
然后对这一步窝萌二项式定理一下第二个\(\Sigma\)就会变成:
\(Ans' =k\sum\limits_{i=1}^{n}{(-1)^iC_n^i((k^{n-i} - 1)^m - (k^{n-i})^m)}\)
嗯,然后这就很开心,窝萌可以用\(\Theta (nlogn)\)的时间算啦!
最后直接贴\(std\)吧\(233\)……是\(zyd\)大佬写的\(qwq\)
#include <cstdio>
#include <cstring>
#include <string>
#include <cmath>
#include <iostream>
#include <algorithm>
#include <map>
#include <set>
#include <queue>
#include <vector>
using namespace std;
typedef long long ll;
typedef unsigned int uint;
typedef unsigned long long ull;
typedef pair<int, int> PII;
#define fi first
#define se second
#define MP make_pair
ll read()
{
ll v = 0, f = 1;
char c = getchar();
while (c < 48 || 57 < c) {if (c == '-') f = -1; c = getchar();}
while (48 <= c && c <= 57) v = (v << 3) + v + v + c - 48, c = getchar();
return v * f;
}
const ll MOD = 998244353, MOD2 = MOD - 1;
const int N = 1010000;
ll n, m, K;
ll fac[N], inv[N];
ll pw(ll a, ll b)
{
a = (a % MOD + MOD) % MOD;
b = (b % MOD2 + MOD2) % MOD2;
ll re = 1;
while (b)
{
if (b & 1)
re = re * a % MOD;
a = a * a % MOD;
b >>= 1;
}
return re;
}
ll C(int n, int m)
{
if (n < 0 || m < 0 || n - m < 0) return 0;
return fac[n] * inv[m] % MOD * inv[n - m] % MOD;
}
int main()
{
//freopen("b.in", "r", stdin);
//freopen("b.out", "w", stdout);
fac[0] = 1;
for (ll i = 1; i <= 1000000; i++)
fac[i] = fac[i - 1] * i % MOD;
inv[0] = inv[1] = 1;
for (ll i = 2; i <= 1000000; i++)
inv[i] = (MOD - MOD / i) * inv[MOD % i] % MOD;
for (ll i = 1; i <= 1000000; i++)
inv[i] = inv[i - 1] * inv[i] % MOD;
n = read(), m = read(), K = read();
ll ans = pw(K, n * m);
for (ll i = 1; i <= n; i++)
if (i & 1)
ans = (ans - C(n, i) * pw(K, i) % MOD * pw(K, (n - i) * m) % MOD + MOD) % MOD;
else
ans = (ans + C(n, i) * pw(K, i) % MOD * pw(K, (n - i) * m) % MOD) % MOD;
for (ll i = 1; i <= m; i++)
if (i & 1)
ans = (ans - C(m, i) * pw(K, i) % MOD * pw(K, (m - i) * n) % MOD + MOD) % MOD;
else
ans = (ans + C(m, i) * pw(K, i) % MOD * pw(K, (m - i) * n) % MOD) % MOD;
for (ll i = 1; i <= n; i++)
if (i & 1)
ans = (ans - C(n, i) * K % MOD * ((pw(pw(K, n - i) - 1, m) - pw(K, (n - i) * m) + MOD) % MOD) % MOD + MOD) % MOD;
else
ans = (ans + C(n, i) * K % MOD * ((pw(pw(K, n - i) - 1, m) - pw(K, (n - i) * m) + MOD) % MOD) % MOD) % MOD;
printf("%lld\n", ans);
}
\(\mathcal{\color{red}{Description \ \ of \ \ T3}}\)
你需要设计一套纸币系统, 现在已经有了 \(n\) 种不同样式的纸币,你只需要为它们设计面值。 每种纸币的面值都是 \(B\) 的约数(不同种纸币面值可以相同) , 但是 \(B\) 还未知, 只知道 \(L\leq B\leq R\),在这个国家,支付时会给定 \(d\), 只要支付的总额模 \(K\) 与 d 同余即可。 为了让人们能应对支付时给出不同 \(d\) 的所有情况(假设可以使用的纸币没有限制),请问你在 \(B\) 取值的所有可能性下设计方案数的和。答案对 \(998244353\) 取模。
\(\mathcal{\color{red}{Solution \ \ of \ \ T3}}\)
嗯,我们假设给定的面值为\(A_1,A_2 \cdots A_n\) ,那么我们可以得到比较一个方程(组):
\(A_1X_1 + A_2+X_2 + A_3X_3\cdots + A_nX_n + wK = G, w \leq 0,X_i \in Z,G\in [0,K - 1]\)
那么我们根据裴蜀定理思考,方程有解的情况一定是$$gcd(A_1,A_2 \cdots A_n,K) | G$$而$$\because G \in [0,K - 1], gcd(0, 1, 2, \cdots K - 1) = 1$$ $$\therefore gcd(A_1,A_2,\cdots A_n, K) \leq 1$$
所以一个合法的序列,其\(gcd\)必须为1。
那窝萌就可以用\(n! logn\) 的时间来搞个\(dfs\) ……但事实上如果\(K\)是素数的话,此时任何序列经过一些变换都可以成立。因为我们思考对于一个序列而言,其中和\(K\)不互质的数只有\(K\)的倍数。那么对于一个\(K\)的倍数而言,我们考虑\(S = \alpha K,\alpha \in Z\) 那么总是可以表示成\(\beta K + (K - t)+ \omega K + t\) 其中$$\beta +\omega + 1=\alpha$$ 也就是说对于一个\(K |A_i\)。我们总可以找其他无关紧要的\(B\)的因子来替换它,或者即使不能替换我们也可以让\(X_i\)恒为零而不去考虑这一项。所以最后很棒的是我们直接\(\tau(B)^n\)暴力乘法原理即可,当然不要忘了前提:\(K\)是素数。
于是这样我们就可以拿到\(50\)分了:\(30\)分努力 +\(20\)分运气\(2333\)
那么\(50pts\)的代码大概长这样
#include <cmath>
#include <cstdio>
#include <cstring>
#include <iostream>
#include <algorithm>
#define MAX 2025
#define ll long long
#define mod 998244353
using namespace std ; int i, S ;
int L, R, K, N, B, P[MAX], cnt, Ans, base[MAX] ;
inline ll expow(ll A, ll B){
ll res = 1 ;
while (B){
if (B & 1) {
res = res * A ;
if (res > mod) res %= mod ;
}
A = A * A ; if (A > mod) A %= mod ;
B >>= 1 ;
}
return res % mod ;
}
inline bool Chk(){
int G = K ;
for(int k = 1 ; k <= N ; ++ k) G = __gcd(G, base[k]) ;
return G == 1 ;
}
void dfs(int Step){
if(Step == N + 1){if(Chk()) ++ Ans ; return ;}
for(int k = 1; k <= cnt ; ++ k) base[Step] = P[k], dfs(Step + 1) ;
}
int main(){
freopen("c.in", "r", stdin) ;
freopen("c.out", "w", stdout) ;
cin >> L >> R >> K >> N ;
if(R <= 11){
for(B = L; B <= R; ++ B){
cnt = 0 ; S = sqrt(B) ;
for(i = 1 ; i <= S ; ++ i)
if(!(B % i)){
P[++ cnt] = i ;
if(i * i == B) break ;
P[++ cnt] = B / i ;
}
dfs(1) ;
}
cout << Ans << endl ; return 0 ;
}
for(B = L ; B <= R ; ++ B){
cnt = 0 ; S = sqrt(B);
for(i = 1 ; i <= S ; ++ i)
if(!(B % i)){
++ cnt ;
if(i * i == B) break ;
++ cnt ;
}
Ans += expow(cnt, N) ;
}
while(Ans < 0) Ans += mod ; cout << Ans % mod << endl ;
}
那么接下来窝萌考虑满分做法。我们稍微具象化一下窝萌要求的东西,其实就是
\(\sum\limits_{p_1|B}\sum\limits_{p_2|B}\cdots \sum\limits_{p_n|B}[gcd(p_1,p_2 \cdots p_n,K) =1]\)
窝萌讲这个式子记作\(f(B)\) ,那窝萌实际上是求\(\sum\limits_{i=L}^{R}f(i)\) 。窝萌观察这个函数,通过意会法我们可以了解到,这玩意儿好像是积性函数\(233\)。那窝萌不妨稍微缩小一下规模,考虑\(B\)的一个因子\(p^c\),和\(K\)的一个n与此对应的因子\(p^{\Omega}\) 。那窝萌从唯一分解定理老看,其实是在求
\(\prod\limits_{p^c | B,p^\Omega |K}\sum\limits_{i_1 = 0}^{c}\sum\limits_{i_2 = 0}^{c}\sum\limits_{i_3 = 0}^{c} \cdots \sum\limits_{i_n = 0}^{c}[\min(i_1,i_2,i_3 \cdots i_n,\Omega)=0]\)
那这其实就是一个组合数啊\(233\) ,在这里我们分两种情况考虑:
\(\color{purple}{case1\#:\Omega = 0}\)
此时我们发现原式中的\(i\)们可以取\(0\),也可以不取\(0\),但是剩下的不去零的取啥都行,联系乘法原理,窝萌的的求和公式变成了这样:
\(\sum\limits_{k=0}^{n}{\binom{n}{k}c^{n-k}}\)
二项式定理一下就变成了$$(c+1)^n$$
\(\color{purple}{case2\#:\Omega \neq 0}\)
此时窝萌发现不能不取了,所以就要忽略一项,就是表示取零个的\(\binom{n}{0}c^n\)这一项。所以窝萌用上边的结果做个差即可,即\((c+1)^n-c^n\)
好的,窝萌现在已经处理出了所有质数的幂,之后呢,我们就可以像普通的筛积性函数一样筛了。做个前缀和就搞定了\(233\) .注意哦,不是完全积性函数呢,所以要分成互质的两部分\(233\) .
然后开心的代码长这样:
#include <cstdio>
#include <iostream>
#define MAXN 81
#define MAX 10001000
#define ll long long
#define mod 998244353LL
using namespace std ;
ll _P[MAXN], F[MAX], i, j, t, cnt ;
ll L, R, K, N, base[MAX], _prime[MAX] ;
inline ll expow(ll A, ll B){
ll res = 1 ;
while (B){
if (B & 1) res = res * A % mod ;
A = A * A % mod ;
B >>= 1 ;
}
return res % mod ;
}
int main(){
freopen("c.in", "r", stdin);
freopen("c.out", "w", stdout);
cin >> L >> R >> K >> N ;
for (i = 0; i <= MAXN - 1; ++ i) _P[i] = expow(i, N) ;
for (i = 2; i <= R ; ++ i){
if(!base[i]){
_prime[++ cnt] = i, base[i] = 1 ;
}
for(j = 1; j <= cnt && i * _prime[j] <= R ; ++ j){
if(!(i % _prime[j])){
base[i * _prime[j]] = base[i] ; break ;
}
base[i * _prime[j]] = i ;
}
}
for (i = 1 ; i <= cnt ; ++ i)
if (K % _prime[i] == 0)
for (j = 1, t = _prime[i] ; t <= R ; ++ j, t *= _prime[i])
F[t] = (_P[j + 1] - _P[j] + mod) % mod ;
else
for (j = 1, t = _prime[i] ; t <= R ; ++ j, t *= _prime[i])
F[t] = _P[j + 1] ; F[1] = 1 ;
for (i = 2; i <= R ; ++ i)
if(base[i] > 1) F[i] = F[base[i]] * F[i / base[i]] % mod ;
for (i = 2; i <= R ; ++ i)
F[i] = (F[i] + F[i - 1]) % mod ;
cout << (F[R] - F[L - 1] + mod) % mod << endl ;
}
相比之下,我比\(std\)快了不少\(2333\)

这几道我钻了好几天……导致最近进度一直很慢\(233\)……不过说实话题都挺好的\(2333\)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号