

sd10
1、SAE-diffusion:利用sae能看到初期模型构图,还能干预图像的物体生成位置以及图像整体风格。但是论文没有探索图片的编辑。
(1) sae编码解码
![]()
![]()
sae loss,如果只有重建损失,会出现很多dead feature(从未被激活的sae 特征,即对应的激活值一直为0,他们占用sae很多参数容量,却无实际功能),因此设计辅助损失aux,激活dead feature使其共同参与重建,具体而言,在训练过程中维护一个动态更新的 “死亡特征列表”,然后计算重建误差 e= x - x^,误差 e 代表由于dead feature导致的sae未完全重建的 “信息缺口”,接着从 “死亡特征列表” 中筛选出激活优先级最高的前 kaux 个 dead feature,得到重建后的误差 e^ =Wdec zdead ,其中 zdead是这kaux个 dead feature 的激活向量,初始为0,后续通过梯度更新调整:
![]()
![]()
![]()
(2) 收集sae激活并训练sae
选择 Stable Diffusion v1.4(SDv1.4),采用 LAION-COCO 数据集的 150 万条训练提示产生中间的激活,过程中收集:不同文本提示下的扩散时间步t时(早期,中期,晚期)第ℓ个(包括Unet中间层,靠近输入和输出层的2头层)交叉注意力 Transformer 块的输出与输入的差值(维度:Hℓ×Wℓ×dℓ,如 16×16×1280 的特征图,看成一个空间意义上的豆腐)。训练sae用的是差值的第(i,j)位置的向量
(3)sae 特征标注
由于传统llm缺乏解析空间关系,物体计数能力,因此采用vision-based pipeline进行标注:对生产的图像用RAM 图像标注+Grounding DINO 目标检测+SAM 分割,若某个(i,j)位置的sae特征激活了,则遍历图像中的每个tag区域,iou最大的则作为该sae特征的标注,比如CID 0 对应的标注是ground、dirt、floor,另外通过 Word2Vec embedding的平均值来存储标注,所有sae特征的标注结果构建成 concept dictionary。
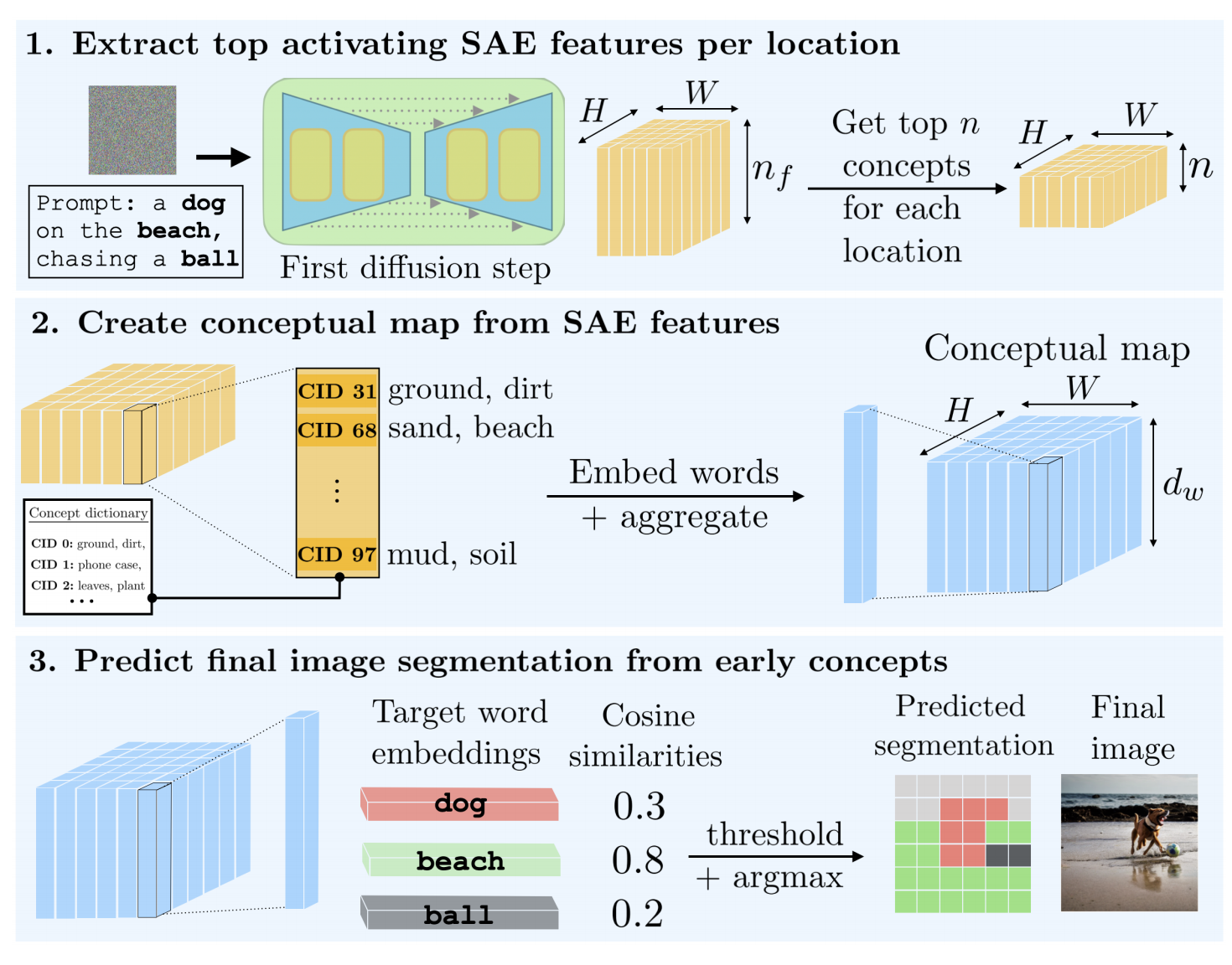
(4)初期构图预测
图1:给一个输入prompt,对去噪早期的unet块差值的每个(i,j)位置做sae解析(h*w*nf),对于单个向量,得到n个sae激活最大的概念,得到空间上每个位置的n个概念
图2:对这n个概念的语义向量取平均,作为这个位置预测的sae的语义向量,所有位置的语义向量构成conceptual map。
图3:对于prompt的每个实体得到实体语义向量,那实体语义向量去和conceptual map每个位置做相似度计算,大于某个阈值,则conceptual map的对应位置就是这个实体了,由此就能得到初期构图了(prediction segmetation)
(5)利用sae干预图像生成
【控制物体空间上的位置】:设要控制的物体作为o,Co是与它相关的集合(有哪些概念设计到了o,形成的概念集合),现在希望这个物体出现在位置(i,j)。在差值(i,j)的位置上加上Co的sae特征,其他位置减去Co的sae特征(感觉可以改进一下:仅在原本要生成该物体的区域做减法,而不是所有其他位置),β控制干预力度:
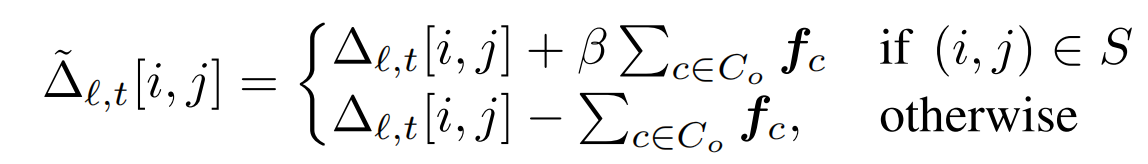
其中,β要避免过度干预导致图像失真或语义偏移,由于未干预的特征会通过unet残差路径绕过干预,因此需要较大的β来 “覆盖模型天然的构图倾向信号”,比下面的风格干预要大,同时不同位置的β要随着位置做自适应调整:
![]()
【控制生成图像的整体风格】:设想要的风格为c,则在差值的所有位置上加上c的sae特征:
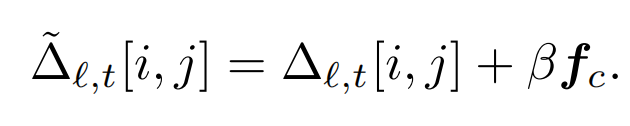
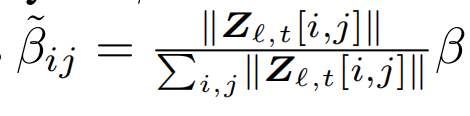
实验1(图5):先建立一个映射——每个概念都有自己在图中的激活区域,这个激活区域可以作为概念自己的semantic segmentation mask。取 up_blocks.1.attentions.0 ,利用 Concept dictionary 观察去噪早期和晚期的前5个高激活的 concept map ,验证了 Concept dictionary 的准确性——部分 Concept 能够对应上早期构图的布局信息,部分 Concept 能够对应上晚期图中的细节物体。
实验2(图6):从5个概念扩展到10个概念,换了个图,加了个t=0.5的记录,和实验1没什么区别,然后从另一个角度分了下:很多概念的激活区域存在重叠,这个重叠是从多个维度进行的描述,而不是真正的重叠冗余。有些概念用于描述图像的全局风格,那么它的激活热力图呈 “全图均匀分布”。还有些概念对图像语义无关,仅仅为了sae优化而存在,没有语义意义,对图像的内容贡献度小。
实验3(图7):根据提示词观察构图。对一个测试提示词,提取里面所有的名词,用(4)初期构图预测 的方法得到不同时间步的 predicted segmentation。这个 predicted segmentation 和 gt 图像做定性观察比较和定量iou计算。可以得到:在初期查看 predicted segmentation ,就能够知道提示词里的这些东西会在图像的什么位置,随着扩散时间步数的增加,会越来越精确,重合度越来越高。up_block 能提供更加精确的segmentation。
实验4(图8): 不同时间步的空间位置干预的可视化,4个位置干预(左上,左下,右上,右下),3个样本,早中晚期的时间步。显示早期做干预更有效。
实验5(图9):不同时间步的风格干预的可视化,3个风格,4个样本,早中晚期的时间步。由于同一个风格的概念,在不同时间步是不一样的,此时首先确定t=0.5的目标风格的概念,然后拿这个概念的word2vec语义向量分别去t=0和t=1的概念字典里匹配和它语义最近的2个概念,由此,这三个概念分别对应3个时间步的同一个要转换的风格。分析的得到,风格干预最好在t=0.5中期进行,如果在早期会影响图像布局,如果在晚期,仅仅在细节上有改动。
还有个问题是:怎么确定想要的目标风格的概念是哪个,因为只能找到与“卡通风格”相关的概念,这个概念是不是真的表示卡通风格并不确定,因此引入concept intensity γc,计算每个生成图片的激活强度,从高到低取前n张图片,看看n张图片是不是都是卡通风格,才能确定是不是自己要找的概念。因此通过计算concept intensity γc,每个概念有自己的图像集,就能从视觉上分辨出每个概念的图像语义。实验5就是先通过此方法,找到t=0.5所对应的目标概念。γc的计算风格如下:
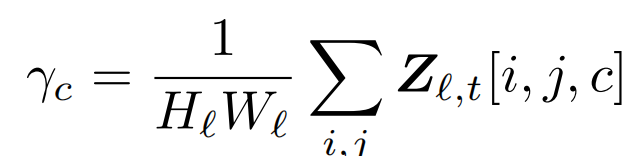
实验6(图19-32):通过计算 concept intensity γc ,展示了4个概念分别对应的图像集,每个图一个概念。
实验7(图10):全局风格干预时,不同的 β 对早中晚期的图像生成风格的影响。分析得到:早期干预会影响布局,晚期干预仅影响细节,中期干预有效,且 β 越大效果越明显。
2、Riemannian Geometry 的扩散模型编辑
扩散模型隐变量 xt 所处的空间 X 为:curved manifold,要研究 X 需要研究空间里面每一个点的切空间 Tx(属于向量空间,因此 Tx 的规则由内积决定)。
bottleneck layer of the U-Net 的特征空间 H 先前被证明是欧几里得空间,具备线性结构,可以使用欧几里得度量,这样能通过 H 里的 pullback Euclidean metric (把有明确度量 H 的度量 “拉回” 到无自带度量 X,这个概念源自于Riemannian geometry)来找到 X 切空间的局部潜在基,这些基作为一组 “互不干扰、且都能产生显著语义变化” 的编辑方向,步骤如下:
(1)从X的切空间映射到H的切空间—— u = Jx v,其中雅可比矩阵Jx = ∇xh。
(2)定义:潜在空间切向量 v 的拉回范数的平方 = 特征空间 H 中向量 u 的内积:
![]()
(3)定义:用拉回范数的 “最大值”来寻找 X 切空间的局部潜在基。具体做法:先找一个 “单位长度” 的向量 v₁,让它的拉回范数平方 ||v||²ₚ₈最大(意味着能让特征空间产生语义变化),再找一个 “单位长度” 的向量 v₂,满足两个条件:一是它的拉回范数平方 ||v||²ₚ₈尽可能大;二是它与 v₁“正交”(即方向完全无关,不会重复覆盖同一语义)。实际计算中,通过SVD直接得到局部潜在基:Jₓ的奇异值分解(SVD)公式 Jₓ = UΛVᵀ ,其中 Vᵀ 是 “右奇异矩阵 V” 的转置,其列向量就是 “右奇异向量 vᵢ”,且 vᵢ属于切空间 Tx,U是 “左奇异矩阵”,其列向量就是 “左奇异向量 uᵢ”,且 uᵢ属于特征空间的切空间 ,且{v1, v2 · · · , vn} 就作为X的切空间的基, {u1, u2 · · · , un}就作为H的切空间的基。扩散模型中,不同的提示词对应不同的雅可比矩阵Jx,因此每个提示词都有独特的空间结构。
前面的理论都是在讲图像编辑全流程的(3),下面总结图像编辑全流程:
(1)输入图做DDIM inversion (DDIM inversion 是 deterministic-inversion ,采样步骤无随机噪声,从同一 x₀出发总能得到相同的 x_T,而 random-inversion 反转过程引入随机噪声,每次反转生成不同 x_T,结果不唯一)得到 xT
(2)对xT 通过DDIM generation得到 xt
(3)xₜ通过 U-Net 最中间的层得到特征空间 H 的向量 h, xₜ 到 h 的映射的导数作为雅可比矩阵 Jₓ,求Jₓ的奇异值分解(SVD)(幂法近似求解),得到 X 切空间的基{v1, v2 · · · , vn},再从基中选出来要编辑的方向所对应的向量vi(对应的理论解释是:通过有度量的特征空间的切空间,利用拉回范数,来得到没有度量的切空间的基,这个基具备所有语义编辑方向)
(4)模仿 classifier-free guidance公式修改xt:xt_ = xt + γ[ϵθ(xt + vi) − ϵθ(xt)],γ是编辑强度,ϵθ是原始Unet
(5)对修改后的xt_ 做 DDIM generation得到 修改后的图片
实验1(图3):5个原图,3个时间步,无监督编辑效果——取1个局部潜在基的向量取编辑。分析得到,局部潜在基的向量确实具备语义编辑能力,早期编辑是大改,改轮廓和性别,晚期编辑改细节,比如颜色和表情。(个人感觉意义不大,因为现实当中有无数的语义,有限的基远远不够,创新点:是否可以创建无穷个基?)
实验2(图4):2个原图,2个时间步,选3个编辑向量,加了个文本条件。分析得到,加了文本条件后,局部潜在基的语义编辑方向都围绕这个文本。
实验2(图4):3个原图,选1个编辑向量,5个不同提示词。分析得到,利用不同的提示词,不仅可以编辑形状,还能编辑动作。
实验3(图6):借用PSD探讨不同时间步下,局部潜在基所做的编辑是粗粒度编辑还是细粒度编辑。概念补充——给定一个时间步t,功率谱密度(PSD)计算局部潜在基的每个向量的PSD再取平均作为这个基的PSD矩阵,根据这个PSD矩阵可以得到 “频率” 和“功率” 的对应关系,进而得到一个曲线。不同时间步对应不同的曲线。横轴从左到右:低频率代表粗粒度语义,高频率代表细粒度语义,纵轴:高的功率代表产生的变化。分析得到,T时,紫色线得到低频率有更高的能量,则说明 “粗粒度语义变化明显”,即早期的局部潜在基关注粗粒度语义(关注低频); 米色线(t 后期)得到高频率有更高的能量,则说明 “细粒度语义变化明显”,即随着去噪的进行,局部潜在基关注细粒度语义(关注高频)。
实验4(图7): 利用 geodesic metric 说明不同样本的潜在结构随生成过程逐渐分化,个性化越强,通用编辑方向越难找到,解释了在早期可以用统一的编辑方法去编辑不同图像的原因(早期不同样本的切空间类似)。具体计算方式:给定一个时间步,某个数据集的15个样本,计算两两之间的 Geodesic distance 再取平均,Geodesic distance 是用于衡量两个子空间的距离,此处子空间用的是 H 的切空间,因为 H 是 Euclidean space 因此内积好算,用2个子空间的恶基来代表子空间,通过向量夹角来计算,Geodesic distance 的公式:
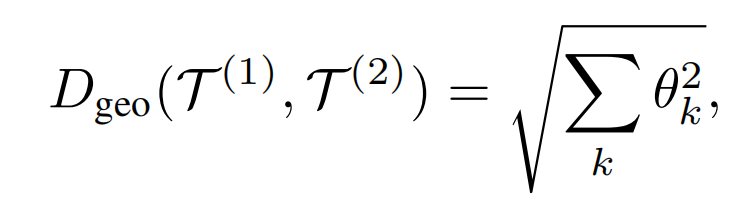
实验用了多个训练数据集,发现使用简单数据集训练的模型,不同时间步的切空间更相似,复杂数据集则相反。
实验5(图8):3个图,早期和中期,parallel transport 的定性效果,进一步验证了对某个样本的早期的编辑方法,可以直接适用到其他样本上,而中期就不行。
实验6(图9):2个数据集,不同时间步之间的Geodesic distance 矩阵的可视化,再次验证使用简单数据集训练的模型,不同时间步的切空间更相似,复杂数据集则相反。
实验7(图10):不同时间步,不同提示词,切空间的相似性,分析得到,提示词越相似,切空间越接近(这不是废话吗,越相似两者特征越一样,当然其他度量也越像了,1个没有意义只会装逼的实验)。纵坐标是 Geodesic distance ,横坐标是文本语义相似度,1个时间步下的同一个样本的2个提示词能得到 1个Geodesic distance作为纵坐标,提示词相似性作为横坐标,然后画到图上。单个时间步下,图10a 能给出 “提示相似度” 与 “切空间距离” 的关系,就可以对这个散点图进一步计算线性关系,用R2去衡量这个线性关系强弱,越高说明线性关系越强,图b就是个补充,没实际意义。
实验8(图10c):验证了提示词在早期侧重粗粒度编辑,晚期侧重细粒度编辑。固定2个不同提示词,计算不同时间步所对应的 Geodesic distance。分析得到,在早期,提示词造成的粗粒度布局差异大,因此 Geodesic distance大,到晚期,提示词造成的细粒度布局差异小,因此 Geodesic distance 小。
实验9(图11a):局限性展示实验,对于某个编辑向量,以为他只编辑胡子,但是通过parallel transport 后,不仅会让女性图片生成胡子还会让他更像男人,说明了这个向量与其他编辑向量产生了一点Entanglement(理想情况下,局部潜在基的语义编辑应该是perfect disentanglement),作者认为这个锅要 数据集 biase来背。
实验10(图11a):局限性展示实验,对于某个编辑向量,编辑过程中产生了 Abrupt change ,作者认为这是扩散模型隐变量 xt 所处的空间 X 过于复杂导致的锅,但这个和作者提出的方法无关,整篇论文并没有讨论渐进性。
3、h-edit 图像编辑
本质上是利用数学的分段函数把不同编辑任务统一起来了,反转之后对xt利用数学工具( Doob’s h-transform )推导的结果进行多轮编辑。具体的:用 Doob’s h-transform 改造原始扩散模型的去噪过程的转移概率,让模型更倾向于生成 “符合编辑目标” 的 xt−1 ,同时保留原图的合理结构,改造后的去噪过程是以ph为转移概率的逆时马尔可夫过程(桥),ph为:
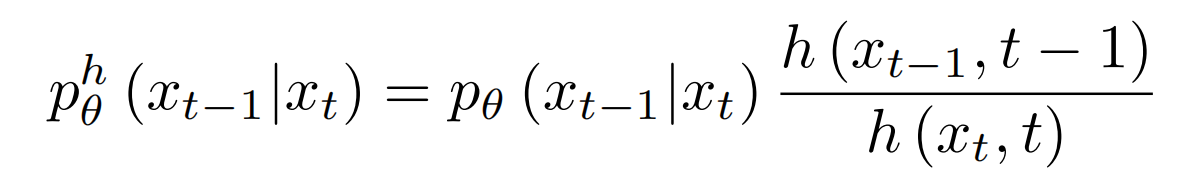
其中 h(xt ,t) 用于衡量 xt 符合 “编辑目标” 的程度,pᵧ(x₀) 是一个预先定义的分布,用来衡量图像 x₀具备目标属性 Y 的概率,pt(xt)是t 时刻的概率分布:
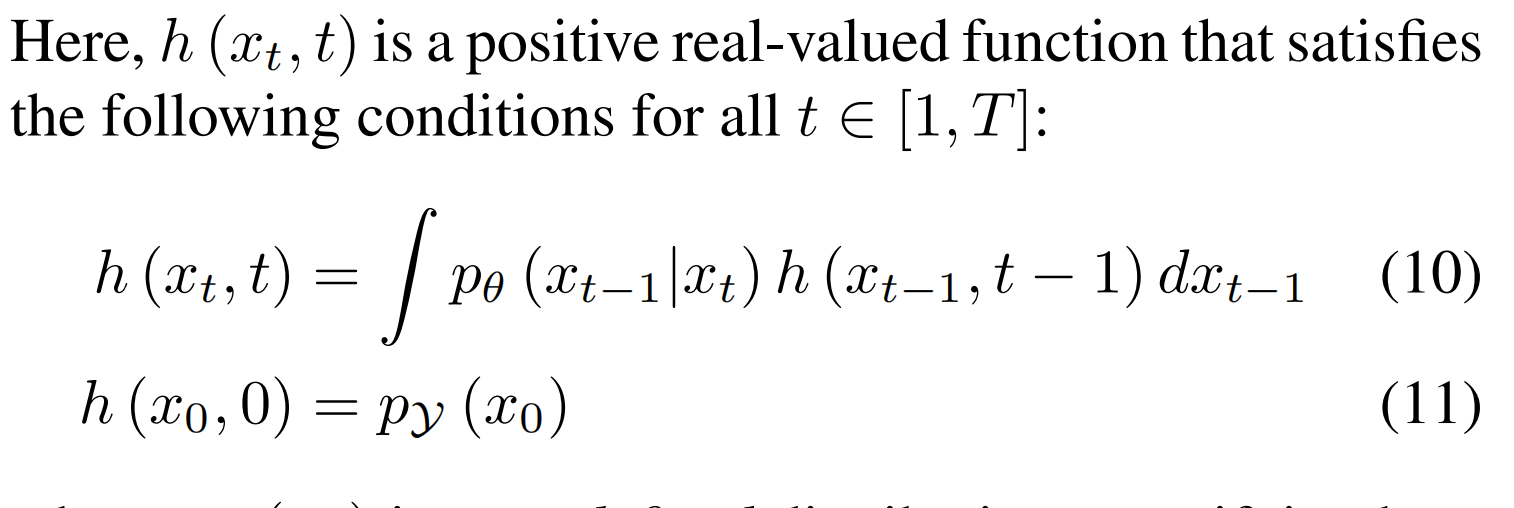
![]()
推论公式验证了:最终编辑出的图像 x₀,既要满足 “看起来真实”(由 p (x₀) 保证,比如像真实照片而非抽象画),又要符合编辑目标(由 pᵧ(x₀) 保证,比如是 “红色的猫” 而非 “蓝色的狗”),两者共同决定了 x₀出现的概率高低:
![]()
采样:由于 h 函数让转移分布非高斯,原始采样行不通,所以用 MCMC 类方法(如 LMC)近似采样 ,采样方式采用单时间步下做多轮迭代,隐式迭代是朝着编辑方向的:
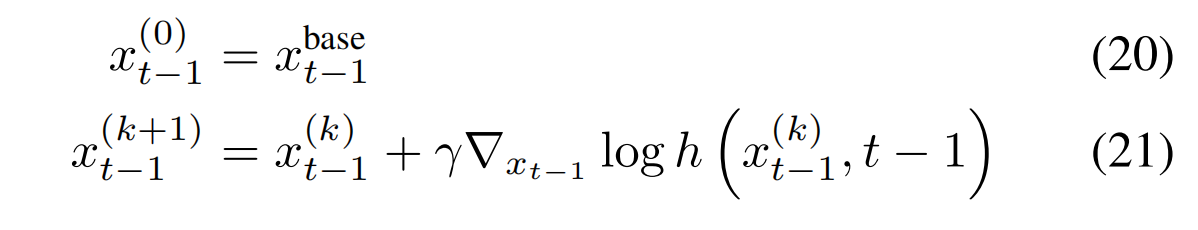
其中对于不同编辑任务,h的计算方法不一样,(1)对于文本引导编辑的 SD:

(2)无明确条件、只有能给 “编辑效果打分” 的工具,即奖励模型(但是只处理清晰图像x₀,不能直接处理含噪图像xₜ),比如人脸交换,风格迁移 ,图像去模糊这些任务的编辑 ,h 的计算方法是:
![]()
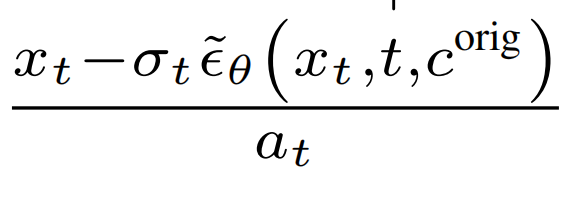
(3)重建编辑任务:
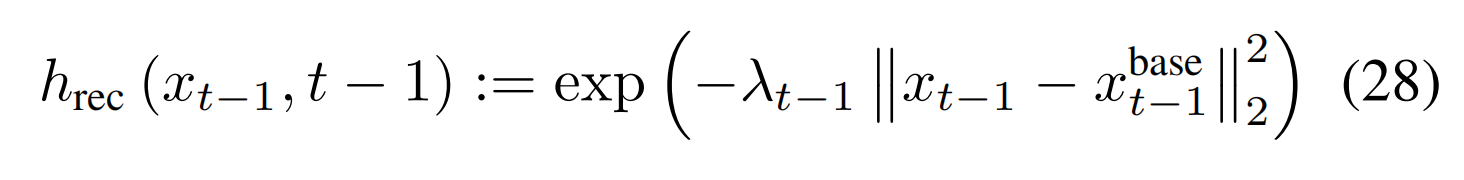
(4)多种编辑任务:
多个 h 函数(对应多个编辑目标)可通过 “乘积” 组合(即 “Product of h-Experts”),且组合后的梯度等于各 h 函数梯度之和
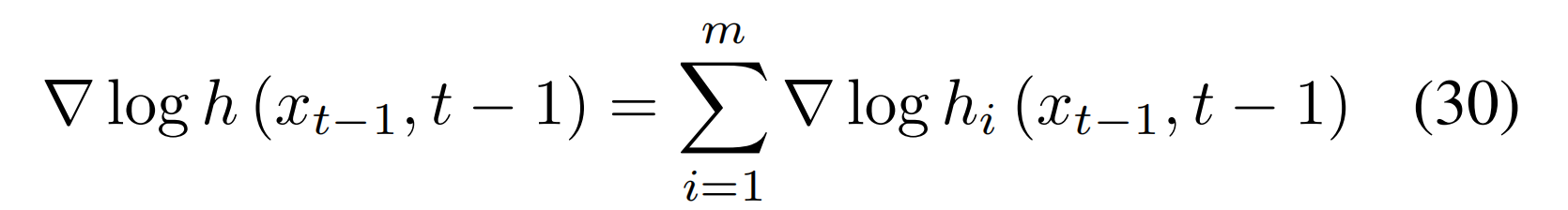
4、pnp
DDIM inversion 本身存在误差:扩散模型的核心过程(加噪 + 去噪)在连续时间下可描述为 ODE,它是可反向的,而DDIM inversion因为是离散步,所以是近似 ODE,进而存在误差的,得到的是带误差噪声。无条件扩散模型(如基础 DDPM)反演无需文本条件;文本引导扩散模型(如 Stable Diffusion、Imagen)反演需要文本条件。默认情况下不启用 CFG(设置 w=1 ),CFG会带来进一步误差,因为CFG 的核心是放大文本对生成的引导作用。如果再对这个带误差对噪声去噪(Forward),如果用的是Classifier-free Guidance,会再次造成误差。
针对 Classifier-free Guidance (CFG)的误差,Optimization-based inversion method ,如 Null-Text Inversion ,训练可学习的“”向量重建DDIM inversion(不启用 CFG,即设置 w=1 ) 的轨迹,重建时开启CFG,采用原图片的描述文本,这样“”向量就保存了结构信息且消除了CFG的误差,编辑图片的时候就用学习后的“”向量。但是 Optimization-based inversion method 迭代步数有限,无法实现完全重建且整体编辑时间慢。由于 DDIM inversion 轨迹和 source 分支的轨迹 存在偏离(这是CFG导致的),Optimization-based inversion method 的作用等价于把两个轨迹拉平了。
prompt2prompt 是比较2个文本的差异从而编辑图片的局部区域,优点是能控制住不编辑的区域。
DDIM inversion + prompt2prompt:图片编辑
DDIM inversion + prompt2prompt + pnp 优化:图片编辑,能更好的保留原图的结构。
pnp改动的核心:对于 DDIM inversion 轨迹和 source 分支的轨迹 存在偏离问题(CFG误差导致的),不再采用迭代优化的方法(比如Null-Text Inversion),而是直接在编辑图片的时候,把2个轨迹的偏离值加到编辑轨迹上,这样就省去了微调。
可以发现图像编辑整体思路都是先DDIM inversion,再采样的时候对xt做一下编辑。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号