

sd9
1、Knowledge Distillation in Iterative Generative Models for Improved Sampling Speed
提高采样速度2种方法:schedular优化、蒸馏
本论文基于DDIM,DDPM训练出来的epsilon theta 可以直接用于DDIM。由于DDIM的降噪过程是确定的,但是step多,由此定义了一个确定的教师分布,因此训练一个学生模型使得最终分布和教师分布一样。
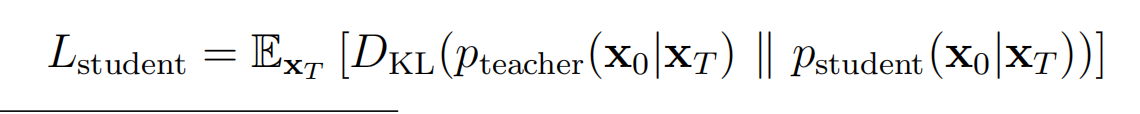
将2个分布视为高斯分布,学生分布为具有可训练参数的均值的分布,因此上式等价于:
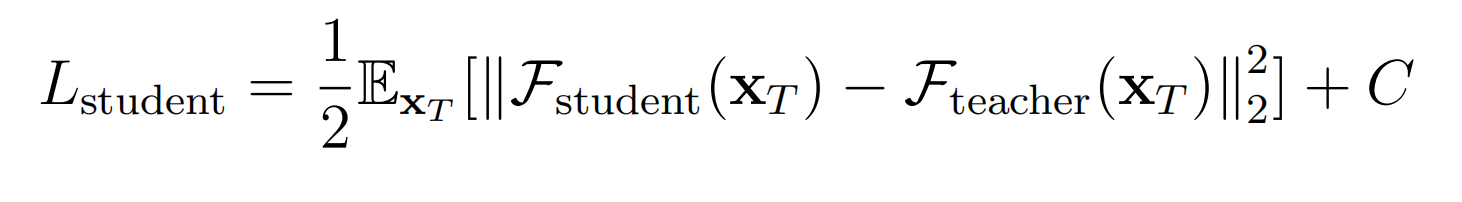
学生模型的网络可以是任意的,这里直接设置为和教师的 epsilon theta 的架构和权重一致,以便加速。
训练过程:将教师网络输入XT,然后迭代很多step算出X0,训练学生网络输入XT后直接算出逼近X0。
缺陷:因为教师网络要跑完所有step才能开始训练,因此速度太慢
2、Progressive Distillation for Fast Sampling of Diffusion Models

(基于DDIM)先训练一个学生,学老师2步的输出,学完之后自己做新的老师,再训练一个新的学生,步数再减半:

缺点:只考虑了DDIM下的推导,且没有考虑 classifier - free guidance
3、On Distillation of Guided Diffusion Models
一阶段蒸馏:
教师分布的输出是考虑了 classifier - free guidance 的,学生模型接受 guidance strength 参数作为额外输入(像时间t一样)。具体的:

二阶段蒸馏:
上述阶段的蒸馏模型作为教师模型,采用 Progressive Distillation for Fast Sampling of Diffusion Models 一样的分布蒸馏方式,区别仅仅是多了 guidance strength 参数作为额外输入,还是基于DDIM。
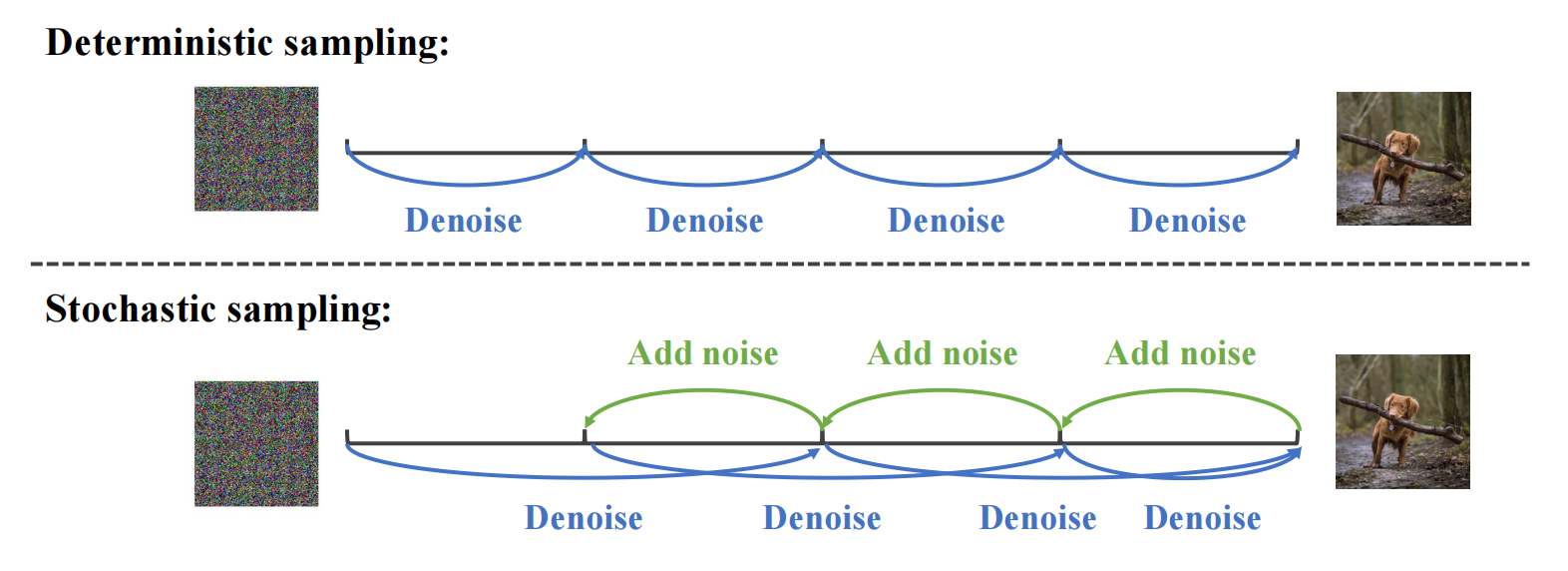
采样阶段,用了 N-step stochastic sampling 技巧,2倍降噪再一倍加噪...目的是:在采样过程中引入了随机性,由于随机扰动的存在,生成的图像也会具有一定差异,从而增加了样本的多样性。:
4、score distillation sampling (SDS)
NeRF 渲染阶段:
输入一个视角的(图片,相机参数),光线从相机出发穿过图片的1个像素后设置多个采样点,这些采样点的空间坐标通过训练好的 MLP 输出预测的颜色和密度信息,密度信息借助物理模型输出采样点的权重,通过预测的颜色加权求和得到预测的图片的像素,遍历多个像素就输出了该视角下的预测的图片。由于输入的视角可能是有限的,可以利用这种渲染方法渲染出没有提供到的视角图片,因此能实现完整的3D渲染
Textured mesh:
给定3D 物体的三角形网格信息以及多张纹理图像,为了渲染出某个相机视角下的2维图像,首先从相机发射出光线穿过这个2维图像的每个像素直到三角形网格上得到交点,通过该交点找到纹理图像对应的颜色,该颜色就作为这个2维图像对应像素的颜色,遍历每个像素之后,这个视角下的2维图像就渲染出来了,如此类推到其他视角。
【方法】
设 某个视角下的图片 = g(theta,相机视角),g 是NeRF渲染过程,theta是渲染中的可训练参数(NeRF parameters)
给一个已知的相机视角c(以参数形式表示),得到 yc(视角文本),随机初始化 theta ,通过 g 得到预测的x0,再加噪声:
![]()
用梯度下降更新法只优化 theta,不动已有的 noise prediction network:

5、variational score distillation (VSD)

【推导】
初始的目标是让两个分布一致:带有可训练参数(θ采样自µ)的 3D 渲染后的分布(左)和 pretrained text-to-image diffusion model 算出来的预测x0的分布,注意优化的是训练参数的分布µ(优化完后θ从中采样),而不是SDS的单个θ:
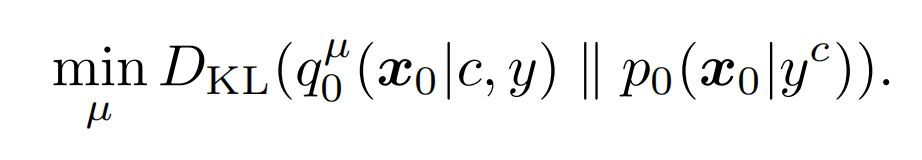
这属于 variational inference problem 。
由于p0非常复杂,所以使用扩散模型将上式转为多个优化问题的组合,即对于任意的时间 t,两个分布在 t 时刻的带有噪声的分布一致:
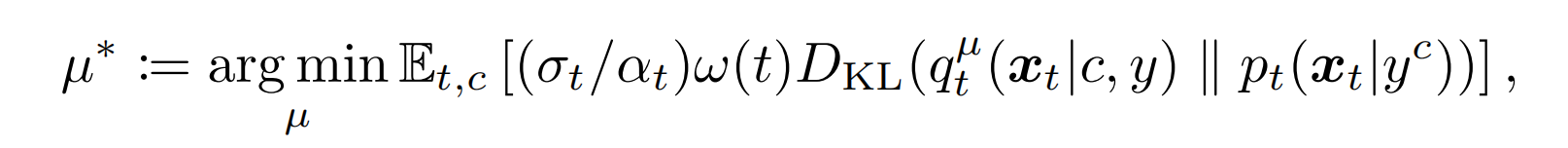
使用ODE方法将分数代替为分布,同时不断迭代更新训练参数,迭代到无穷次就收敛了,τ 时刻(迭代时刻,即ODE time,不是xt的t)的训练参数的变化率满足:
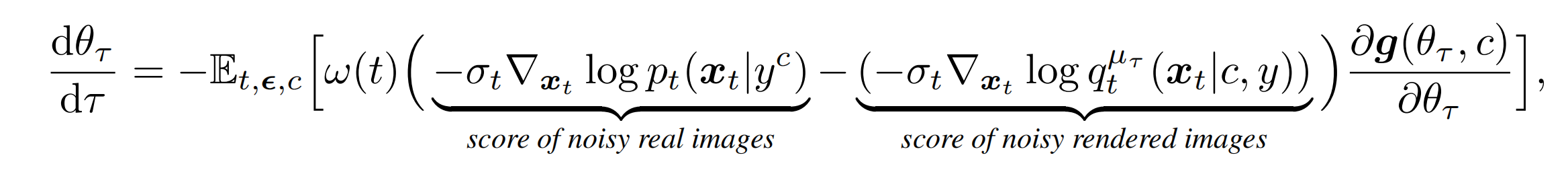
根据Score-SDE,第一个分数可以用:ϵpretrain估计
第二个分数用可训练的ϵϕ估计,通过训练ϵϕ来跟踪当前渲染分布:ϵϕ是把g渲染后的图像(包括所有theta)作为训练集进行的 lora 训练,用ϵpretrain初始化,其中ϵϕ的损失函数:
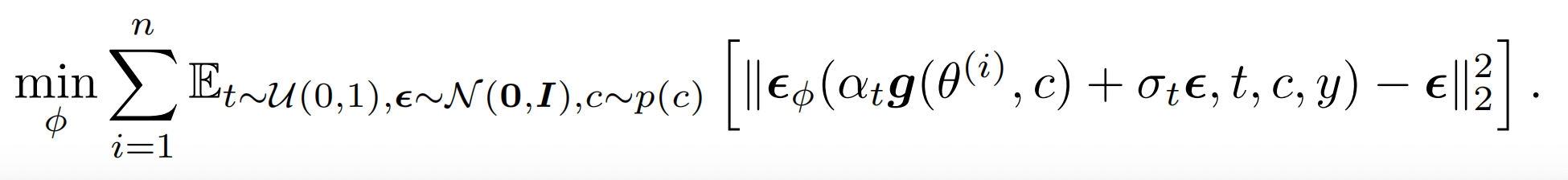
更新 theta 的梯度(即VSD的更新规则):
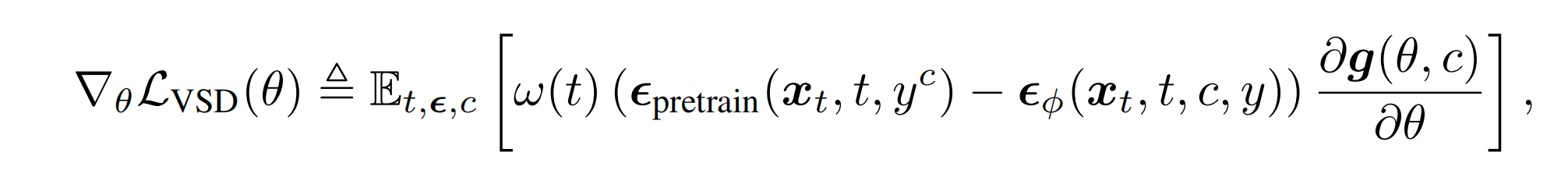
训练时, theta 和 ϵϕ 交替更新即可。
其中θ采样自µ,而µ看成是 n 个θ(pariticles),即将原来的单个参数用多组参数代替,这是为了提高3D场景的真实性和多样性,也可以理解为 n 种 nerf。
【与SDS的区别】
(1)SDS 仅优化一个参数,如果看成分布的话,可以看成是狄拉克分布:Dirac distribution µ(θ|y) ≈ δ(θ−θ (1))。VSD推广到了n个参数,梯度更新更加准确,ϵϕ还能用到 text prompt y,SDS只有单纯的ϵ,VSD更能对起文本。
(2)由于VSD是从分布角度解题的,而训练出来的分布逼近于ϵpretrain,ϵpretrain对2D下的CFG友好,那么促使VSD对3D下的CFG友好(7.5);而SDS的CFG通常特别大(100)
6、DMD
2D下的 diffusion 蒸馏任务

推导:
对于 VSD 的 G 换了个新定义:一步图片生成器,其输出是假分布,G 用预训练好的 diffusion 降噪模型 ubase(z, T-1) 初始化,ubase是将zt输出到zt-1,是图片降噪的预测,不是噪声预测,由于是一步生成,所以 G 没有时间 t 的条件了。
训练目标是使得g的分布pfake和真实分布preal一致(Distribution Matching Loss),计算出2个分布对应的分数,sfake是假分布的分数,sreal是真分布的分数:
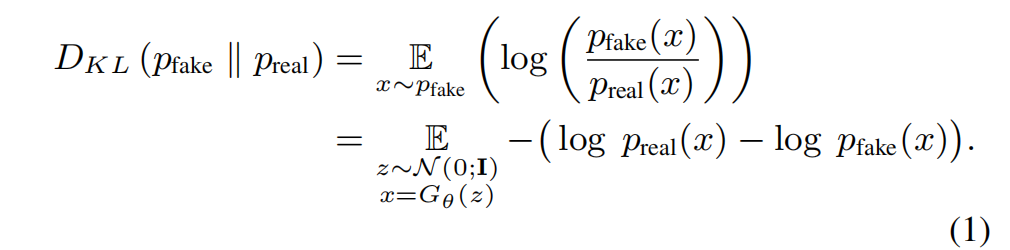
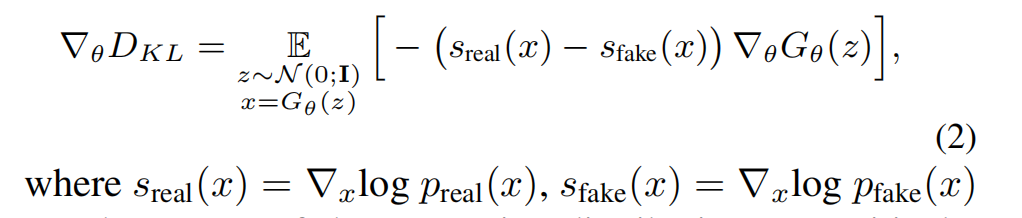
按照VSD类似的推导方法进行推导:根据Score-SDE引入扩散模型估计分数,此时可训练的 ϵϕ 变成了可训练的 ufake(diffusion model),ufake 也用 ubase做初始化,但它有t做条件,可训练是为了代表假分布,由于自然界的真实分布是无法获取的,所以论文是用预训练模型所产生的分布去模拟真实分布,通过让一步生成器的分布趋向于预训练模型的分布,从而趋向于真实分布,此处就把真实分布看成是预训练模型所产生的分布:
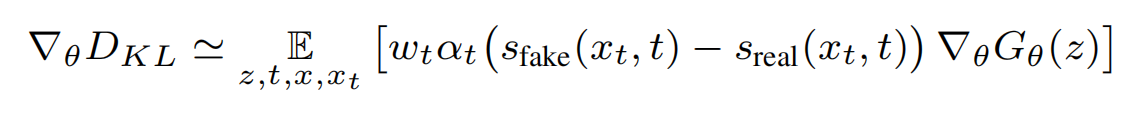
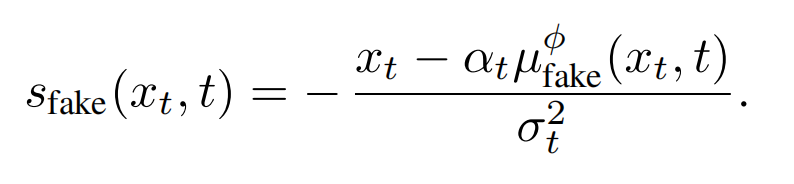
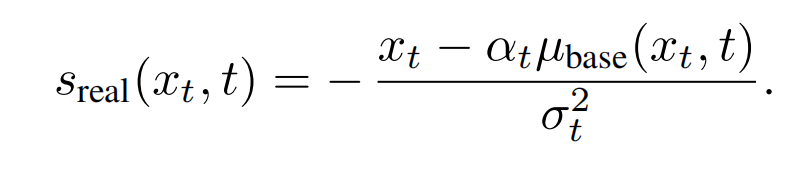
算出梯度后更新theta,这是训练的整体目标(期望2个分布相等)。也是同样的,以(渲染出来的)g的输出做为训练集,更新可训练的ufake, ufake被期望输出预测的x0,这也是为了跟踪当前(渲染)g输出的分布,即代表假分布( denoising score-matching loss on samples from the one-step generator):
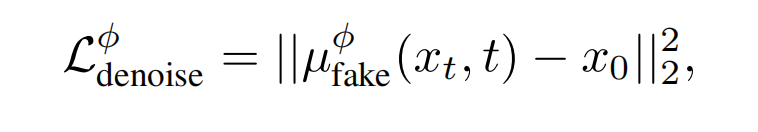
作者对推导过程做了理论和可视化证明:
假定真实分布有2个模式,如果只有sreal,则梯度只指向真实分布的某个高概率密度方向(真实分布的某类图片集),则g生成的样本就会趋向单一模式下的某个区域,对应图(a);

加上 - sfake,-sfake指向真实分布的高概率密度的反方向 或者 低概率方向(由于 sfake 和 sreal 是期望一致的),所以样本会更散一点,g生成的样本就会趋向单一模式下的大部分区域,得到图b。
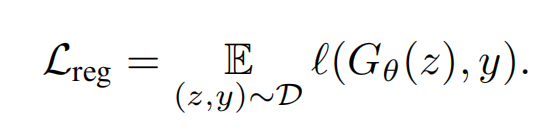
这两个loss一个是从分布的角度训练,一个是从结果的角度点对点训练,但是 DMD2 认为:This regularization objective is also at odds with DMD’s goal of matching the student and teacher in distribution, since it encourages adherence to the teacher’s sampling paths.
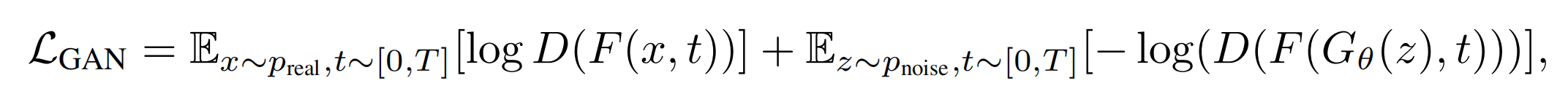
(4)太大的模型比如SDXL没法用一步蒸馏出来,因此把一步生成器G改为多步生成(那速度不就慢了啊)

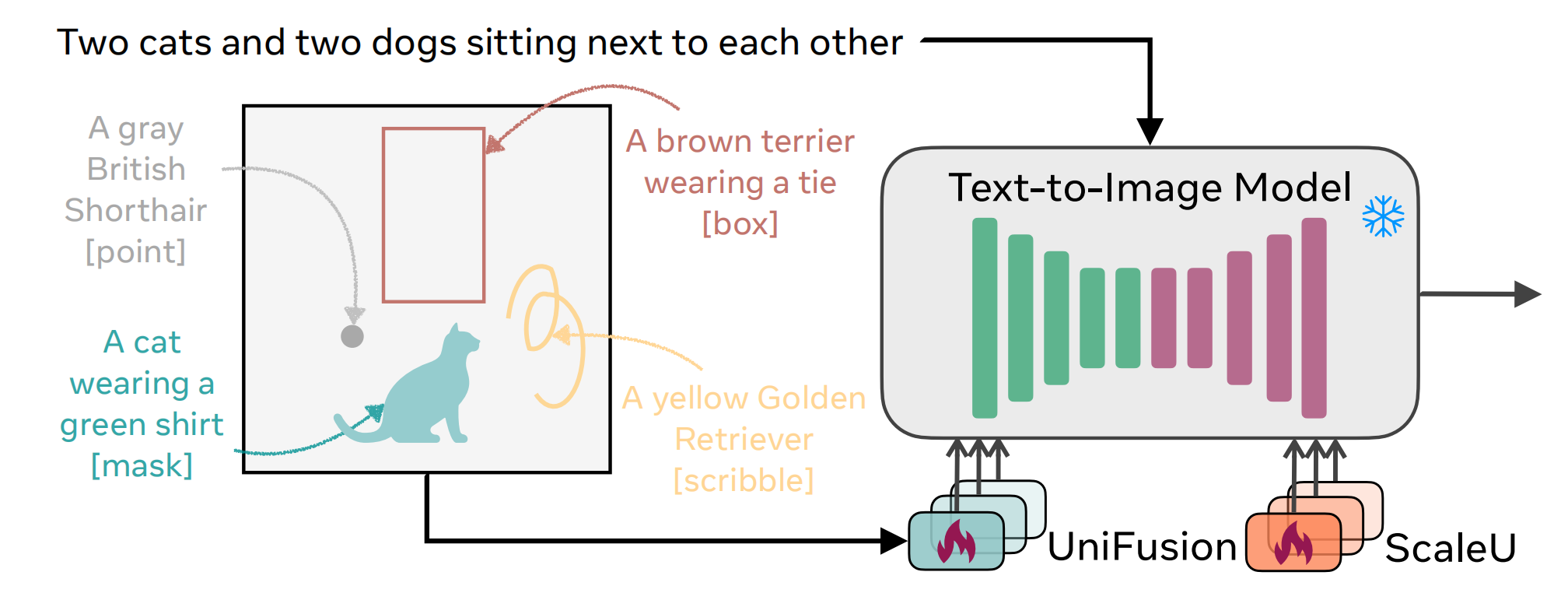
给 diffusion 新增 UniFusion 用于接受位置条件,ScaleU 一个trick。
UniFusion:
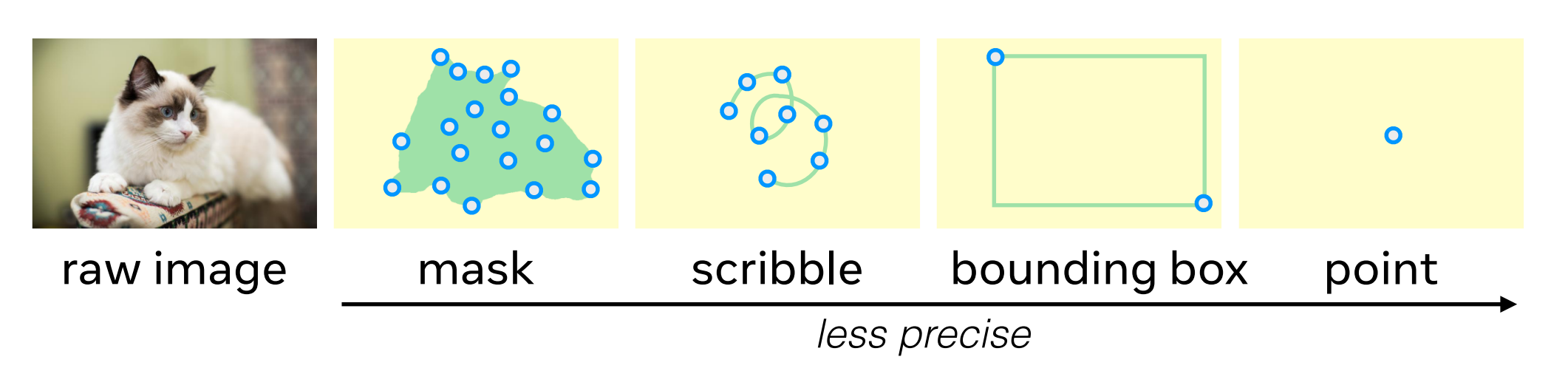
每个位置条件分别通过 Tokenizer。
对于第 i 个实例的每个位置做 Tokenizer :点集坐标通过 Fourier mapping 得到位置向量,该实例的文本通过 CLIP text encoder ,将2个向量拼接结果,再通过 MLP。
假如实例只有1个位置形式,则用 learnable null token 表示其他位置形式,该位置向量 和 learnable null token 加权求和,再和 文本 向量拼接,再通过MLP
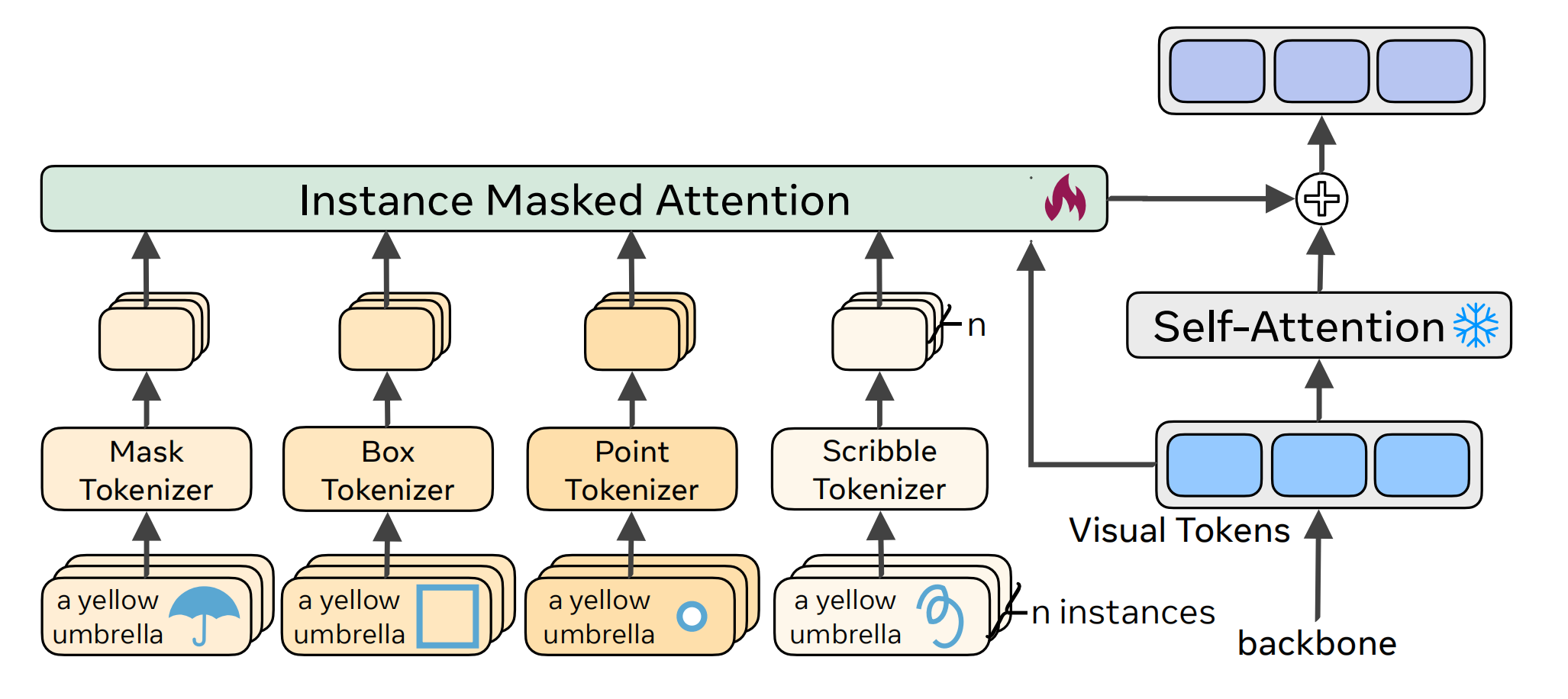
trick1: mask 形式的位置条件token 拼接所有实例的mask 特征图(先放缩,再通过ConvNeXT tiny),以便更好的分开各个实例
Masked Attention:仿照 gligen的设计,所有位置 Tokenizer 后的结果和 visual token 拼接,通过 mask attention, 注入diffusion。
mask attention:在 普通的 self-attention 上加入mask,mask:

trick2:
原始 Unet 跳跃链接主要贡献高频率特征,拼接后导致忽视主特征的语义。
ScaleU: two learnable, channel-wise scaling vectors: sb, ss for the main and skip-connected features
F′b = Fb ⊗ (tanh(sb) + 1)
F′s =IFFT(FFT(Fs)⊙α)
Here FFT(·) and IFFT(·) denote the Fast-Fourier and Inverse-Fast-Fourier transforms, ⊙ is element-wise multiplication, and α(r)= tanh(ss)+1 if r <rthresh otherwise= 1
trick2:
Multi-instance Sampler 避免实例之间的信息泄漏
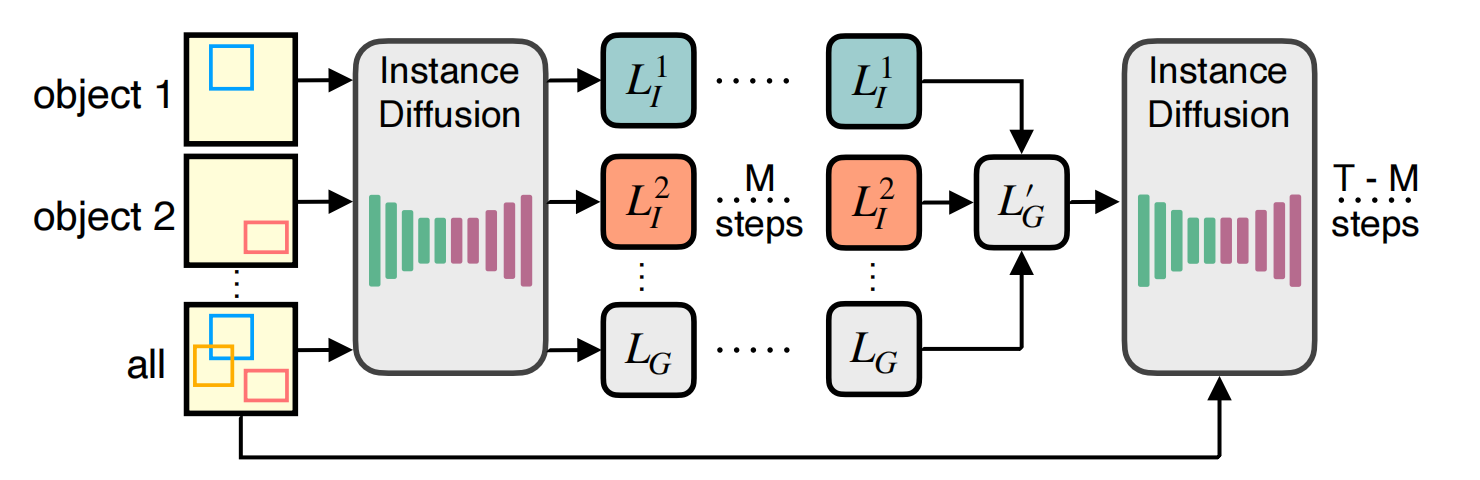
推理的时候,每个实例 和 整体 分别通过 diffsion 降噪 m 步,然后通过取平均来融合
10、multiduffusion
对长的 latent 交错的 crop 出来,分别去噪

11、stitchDiffusion
在造的 h * 2h 的数据集上做训练。对于两个边缘是否能够连续,技巧:降噪的时候,两边分别增补一块区域,增补的再翻转拼接,单独降噪,再原路拼回去。

12、stableSR
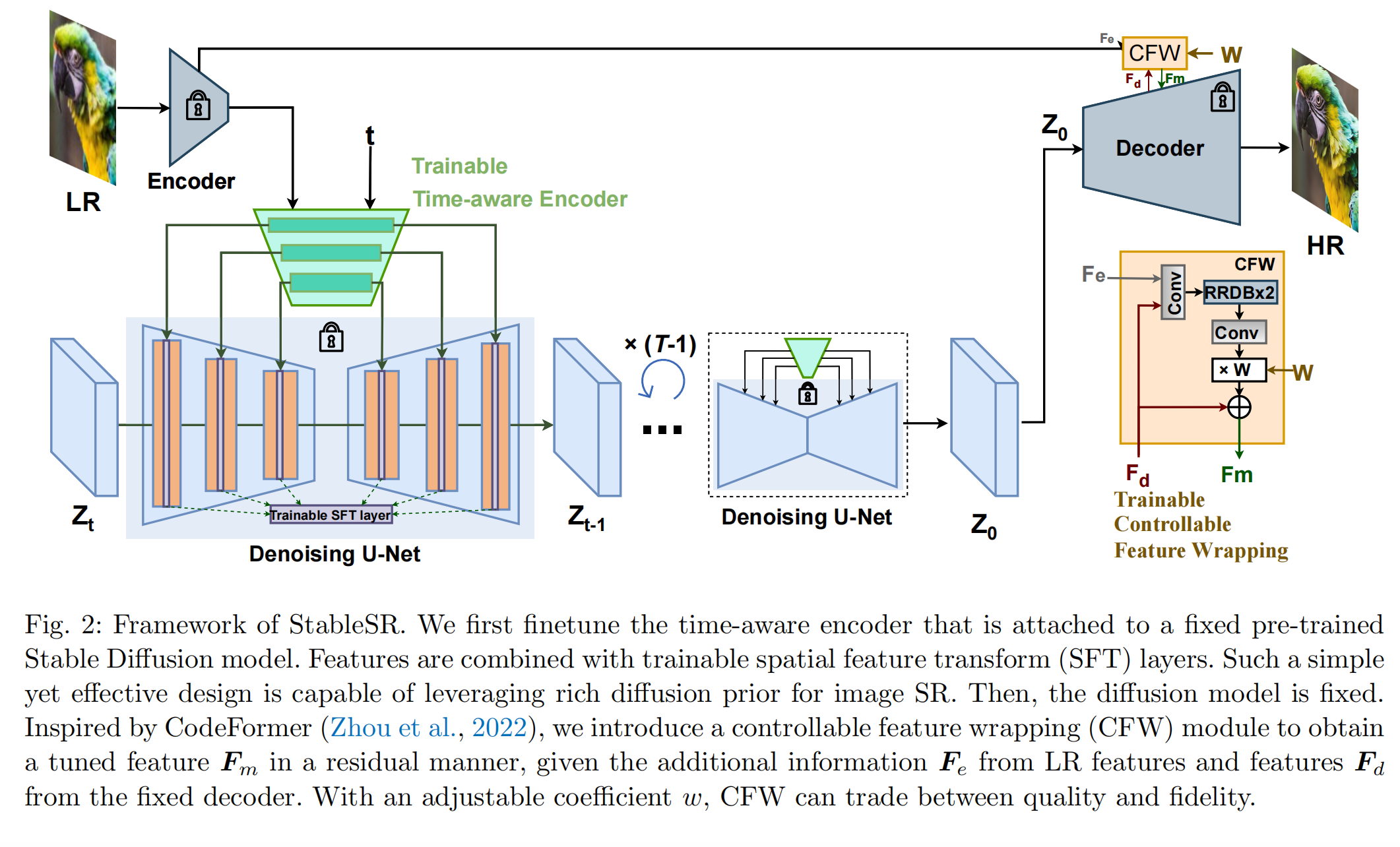
处理任意尺寸的图片:把低分辨率图片分块,块大小为训练的64*64设置,块与块之间有随机的动态重叠,每个块分别降噪,每个块还有自己的权重,降噪完一步就做加权。
13、Any-Size-Diffusion
训练:把图片缩放到候选的比例们中的最相近的
推理:第一步用训练的模型生成任意尺寸图片(其实也就候选那些比例),然后用 stableSR,只是有些块在某些步不降噪,其他步降,这样是加快了速度。
14、cad
对于某个概念,每个参数wi都会对这个概念有贡献度,贡献度大于0表示促进概念生成,否则表示抑制。验证:通过梯度法计算每个参数的贡献度,如果是概念擦除,则把贡献度最高的参数设置为0,如果是概念扩大,则把贡献度最低的那些参数去掉。
J(c,w) :评价参数w对模型生成概念 c 的作用;alpha i 是第 i 个参数对概念 c 的贡献度
假设1: J(c,w) = alpha i 的线性组合
J 形式的假设2(概念擦除):

J 形式的假设3(知识放大):

利用泰勒展开可以近似求出alpha i :

理论验证1:

理论验证2:

15、SAE 和 Transcoder 都是子层而言的。
【SAE】 是自编码器,重建输入和输出,另外让中间向量稀疏,意义:对于一个多义向量,SAE 用更多的维度(单义)去解释这个向量,每个维度对应一个 SAE 特征(体现在 SAE 解码器中),1个sae特征(concept vector)就是将原始向量分解后的单个意思的向量,比如分解到“红色”这个维度后,原始向量在“红色”这个维度上是什么特征,这个sae特征的激活强度通过对应位置的 sae 编码器向量 来表示,即sae编码器向量是激活强度,而sae解码器才储存了sae 特征。每个sae特征对应一个明确的语义概念,sae编码向量表示这个语义有没有被激活。训练好sae以后,给一个向量后(来自某层神经网络),就知道这个向量对应哪些意思(语义),以及这些意思的程度(编码向量的激活程度),结合语言模型整合这些被激活的语义,就知道这个向量的意思了,因此利用训练好的sae,就能知道随便一层的某个向量的意思了。训练的时候,sae是逐层训练的,每层都有自己的sae。那么这些语义(Concept)到底是怎么定义呢,即sae特征标注,这是在sae训练之后进行的,即训练-标注-推理,标注之后的sae特征的语义(Concept)就固定了,标注方法是看某个sae特征被激活时是输入的哪些样本,拿这些样本通过LLM整合语义,就定义为这个sae特征的标注,由此确定语义(Concept)。每个 CID,即Concept ID,就是sae特征的 ID,也就是SAE 解码器权重矩阵的列索引。
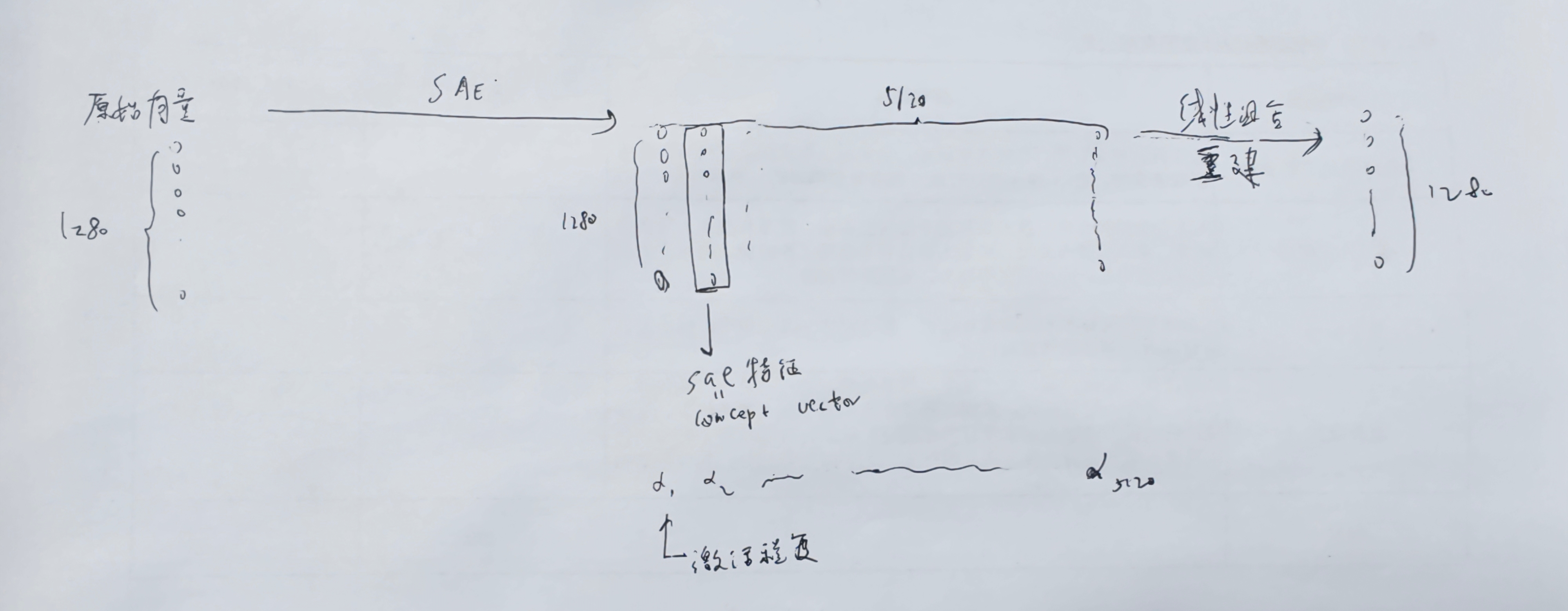
【Transcoder】 重建的是 MLP 的输出,输入和MLP的输入是一样的,可以替换掉 MLP,另外让中间向量稀疏。
每个模型可以有自己的transcoder(解释器),有了它之后,就可以对模型进行解释。即替换模型(对模型的逐层mlp用transcoder替换,这样保持原始的输出不变,同时具备可解释性)。一个模型经过微调之后,原来的transcoder就解释不了现在的模型了,于是需要训练:
(1)训练Transcoder的时候,原始方法是逐层用Transcoder loss做训练;(2)师弟方法:把 Transcoder 替换了 MLP,然后冻结注意力层(保留基础模型的通用推理先验)进行训练(仅做特定领域的适配),没必要全量微调。
16、微调有效性分析方法
(1)PAC shift 分析 (模型微调后,对于提示词的敏感度分析):同一层的2个要对比的向量(微调前后模型的向量),分别映射到PCA 的2维向量,然后第一个分量做差,第二个分量取平均值,得到差异向量,基向量是要微调前模型的向量,第一个分量是0,第二个分量是pca的第二个分量。差异向量和基向量可以做图可视化,差异向量离的越远,说明微调模型对此输入反应很大,对此更敏感。
(2)Feature Distribution Analysis(微调后,看看领域内的知识激活程度):对于领域内微调的模型,检测微调前后的每一层出现领域内特征的比例是多了还是少了,结合微调前特征的比例进行可视化;进一步,将特征分为4类:Input-related, which are associated with input token embeddings and typically appear in lower layers; Correct reasoning, found along correct inference paths in attribution graphs; Wrong reasoning, which contribute to incorrect reasoning chains; and Non-medical, referring to features unrelated to medical semantics,计算微调后,每一层的子类的比例,Input-related 和 Correct reasoning 特征应该比例提高,另两类特征的比例应该降低。
(3)L0 Sparsity - 任务错误率(对于含有transcoder的微调模型性能评估):此处 L0 Sparsity 是横坐标,代表 transcoder 被激活的程度,任务错误率是纵坐标,代表模型对下游具体任务的表现,用于验证在高 L0 Sparsity(特征稀疏)的情况下,微调后的模型性能是否下降
(4)L0 Sparsity - KL Divergence(对于含有transcoder的微调模型特征分布评估):KL Divergence是纵坐标,代表替换模型的输出分布与原模型的分布距离,数值越低,越相似,越说明 transcoder 对 MLP 的替代效果越好(未扭曲原模型的推理逻辑)。
(5)Attribution graph(内部推理机制分析):能展示微调前后,模型内部的推理过程,推理都包括模式匹配(症状与疾病的直接关联)和多跳推理(通过 中间概念构建因果链进行推理)。通过观察2个推理方式的正确性,确定微调后模型的确是修正了底层推理机制,才得到了更好的效果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号