

sd8
1、BeautyREC
源图 I + 参考图 R =》带着 R 妆容的 I
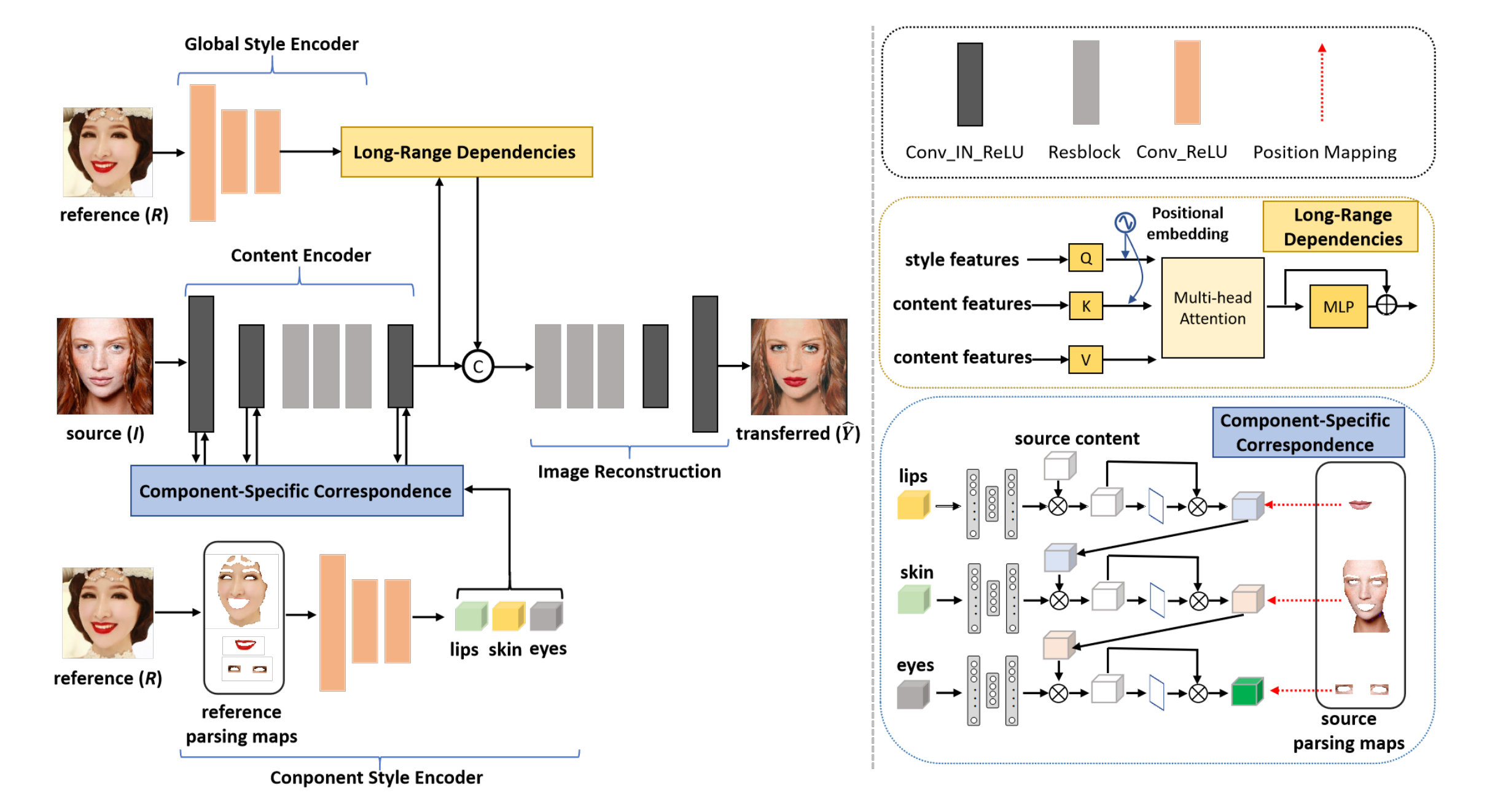
第一行是提取R的整体风格,将它和 I 的特征做 QKV(long range dependencies),第二行是提取 I 的特征,然后 I 的 lip,skin,eyes 和 R的 lip,skin,eyes 特征(第三行的 parcing 提取) 做对应的融合:按照右下角的图,3个部位依次融合。最后对融合的结果做 image reconstruction。
2、emoji
表情序列 + 参考图 =》 改人按照该序列动起来
和InstructAvatar 的第一阶段架构是一样的,就是给了具体的diffusion实现,二阶段没有,因为 InstructAvatar 是用motion generator 产生一段出来的序列,emoji 是已经给定的。
参考图经过2种渠道进入到 Unet 做提示,表情特征拼接到 xt,为了在推理时能迭代式生成长视频,对部分帧 mask 后拼接到 xt(inpainting)
模型理解为:根据参考图片(ID信息)和表情序列,对给定关键帧 inpainting 剩余的黑色帧
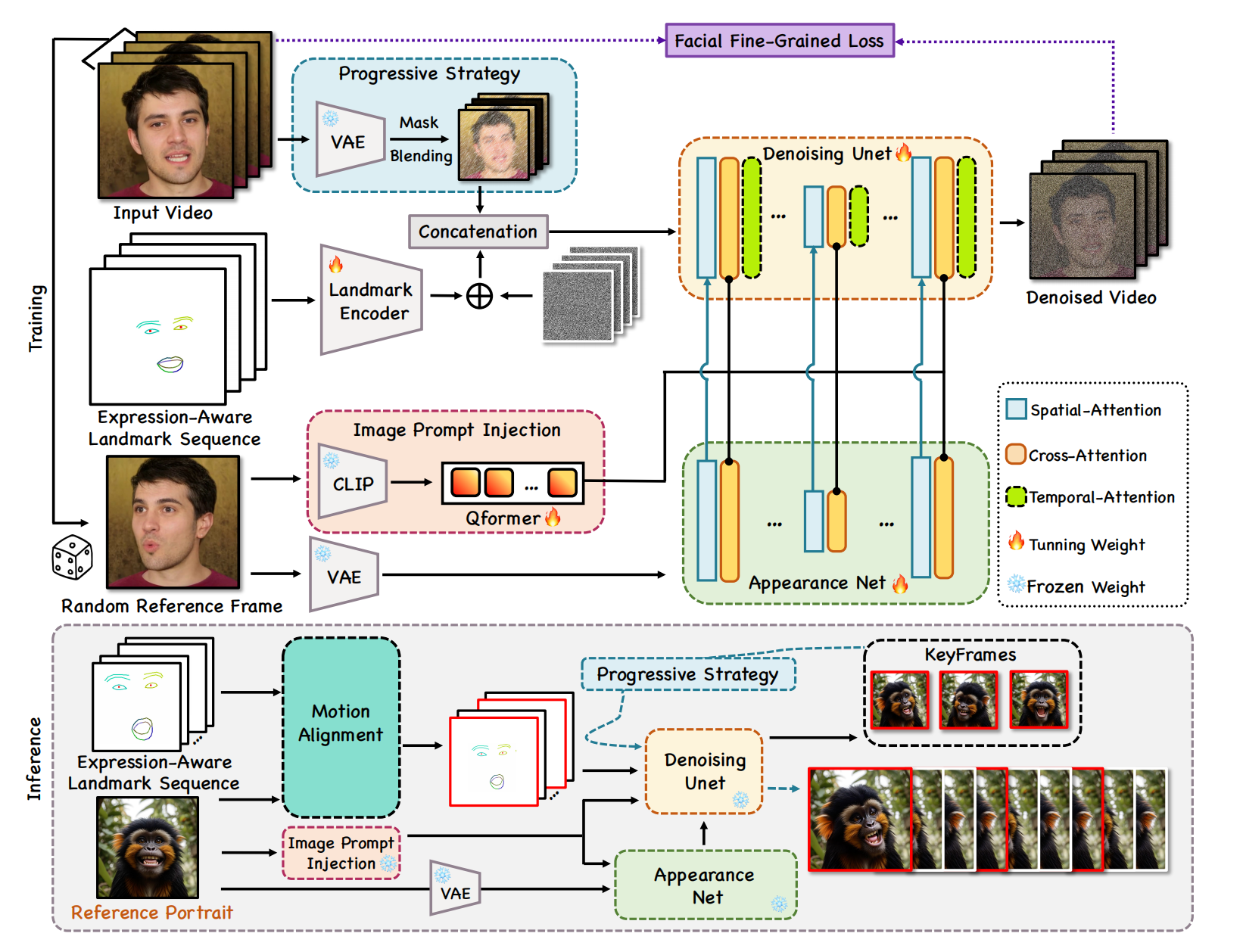
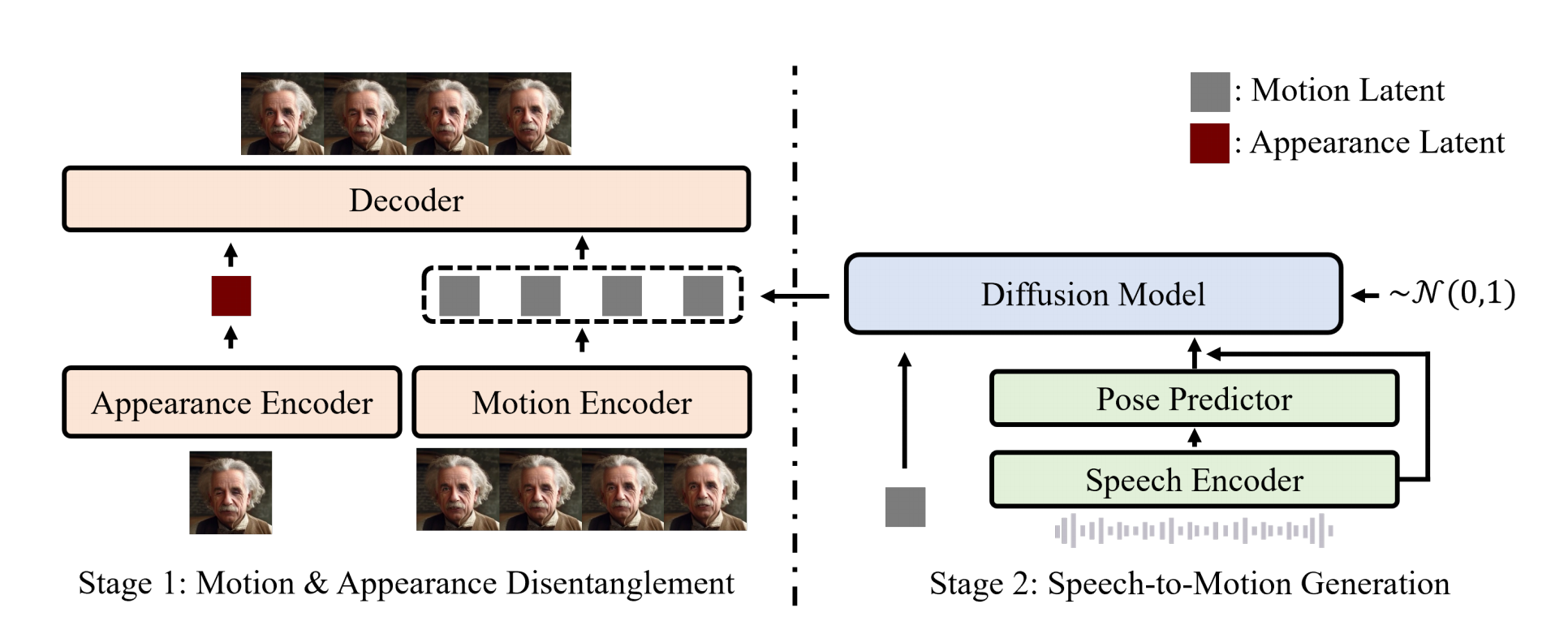
3、 GAIA
音频 + Potrait =》 该人说话的视频
InstructAvatar 的简洁版,InstructAvatar像是抄袭。
分2部分训练,先训练左边 VAE:从1个 clip 抽 2 帧 (i,j),提取第 i 帧的apperance,第 j 帧的motion 特征,经过decoder后应该为 j 帧。
右边:diffusion 主体结构是 conformer,音频条件特征 + mlp(N帧的 head pose,这个用开源工具提取)以 元素积 的方式加到 conformer block 的 Xt
第 i 帧的motion latent 作为参考,和 conformer block 的特征做交叉注意力,它做 K,V。(InstructAvatar 去掉了这个,换成了文本指令)
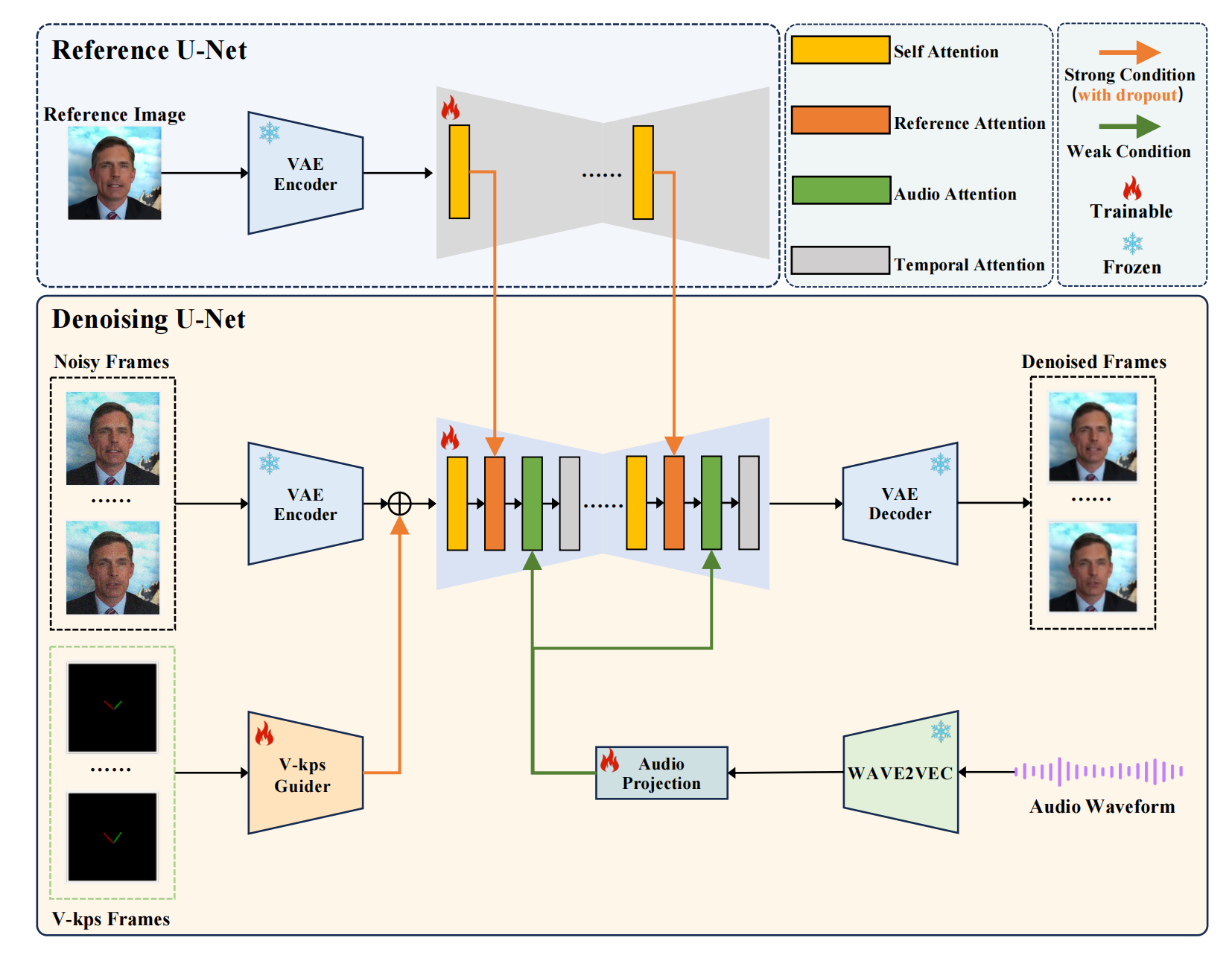
4、v-Express
portrait + 音频 + kps 序列 =》按照音频说话的人
和GAIA不同,用一个diffusion结构就生成了。portrait 做参考图片,单独通过 VAE + unet 生成中间特征,然后作为denoised Unet 的K,V。
主体 Unet 有4个attention,kps 序列特征和Xt(帧序列)相加。音频特征通过 audio attention 注入,temporal atttention 是时间自注意力,用于捕获帧间关系,1帧对应当前音频向量 拼接前后2个音频向量。一开始训练固定音频 attention 和 motion attention,只学会生成帧画质,然后后面阶段都放开,学会理解音频和帧间动作。
5、MegActor
driving video + reference image =》ref image animation
训练:ref image 通过vae + unet 生成细粒度特征然后注入 Denoising Unet(emoji 的 ref unet 那套);
dring video 通过 Drive encoder 后和 ref image 特征做adaln融合,然后和 masked image 拼接(感觉没必要),再和Xt拼接。ref image 的backgroung feature 替换掉文本特征来提供背景信息。通过给 driving video 做人物换脸来实现 driving video 的数据增强:
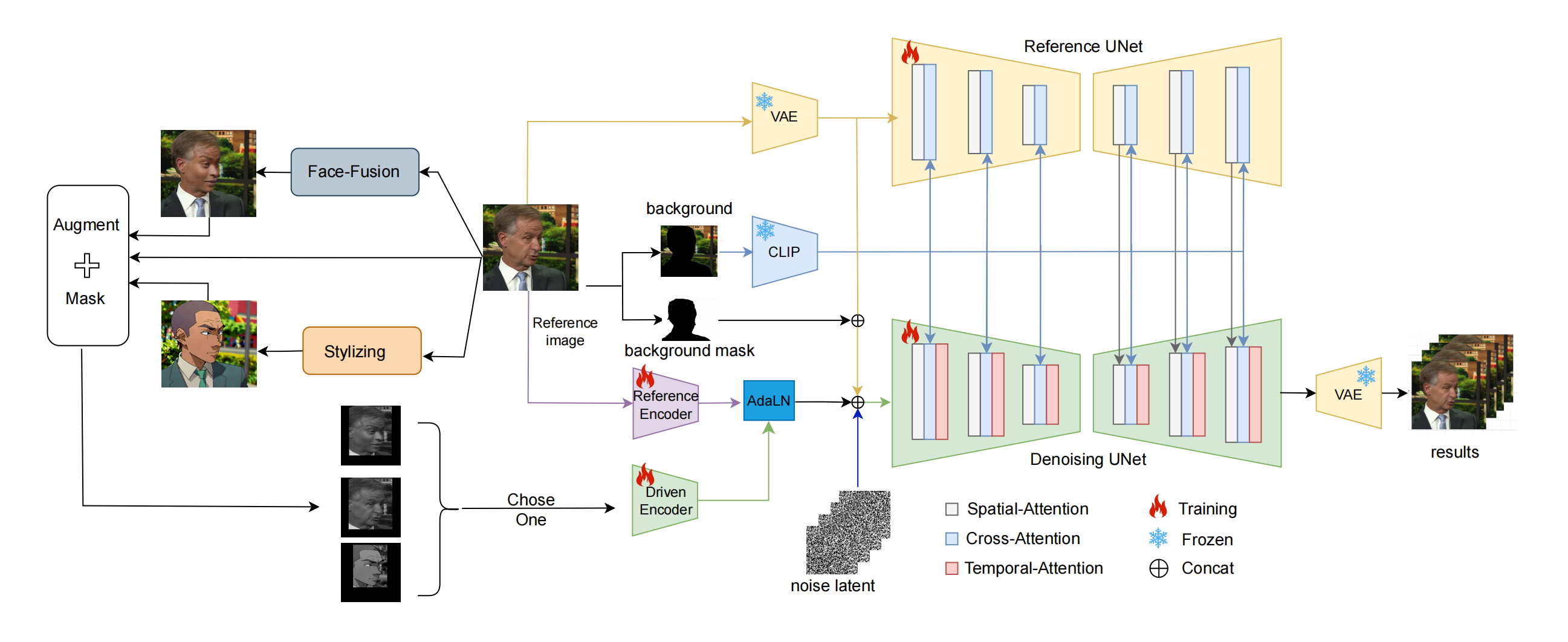
6、face adapter
换脸,其实是 inpainting 任务的另一种实现
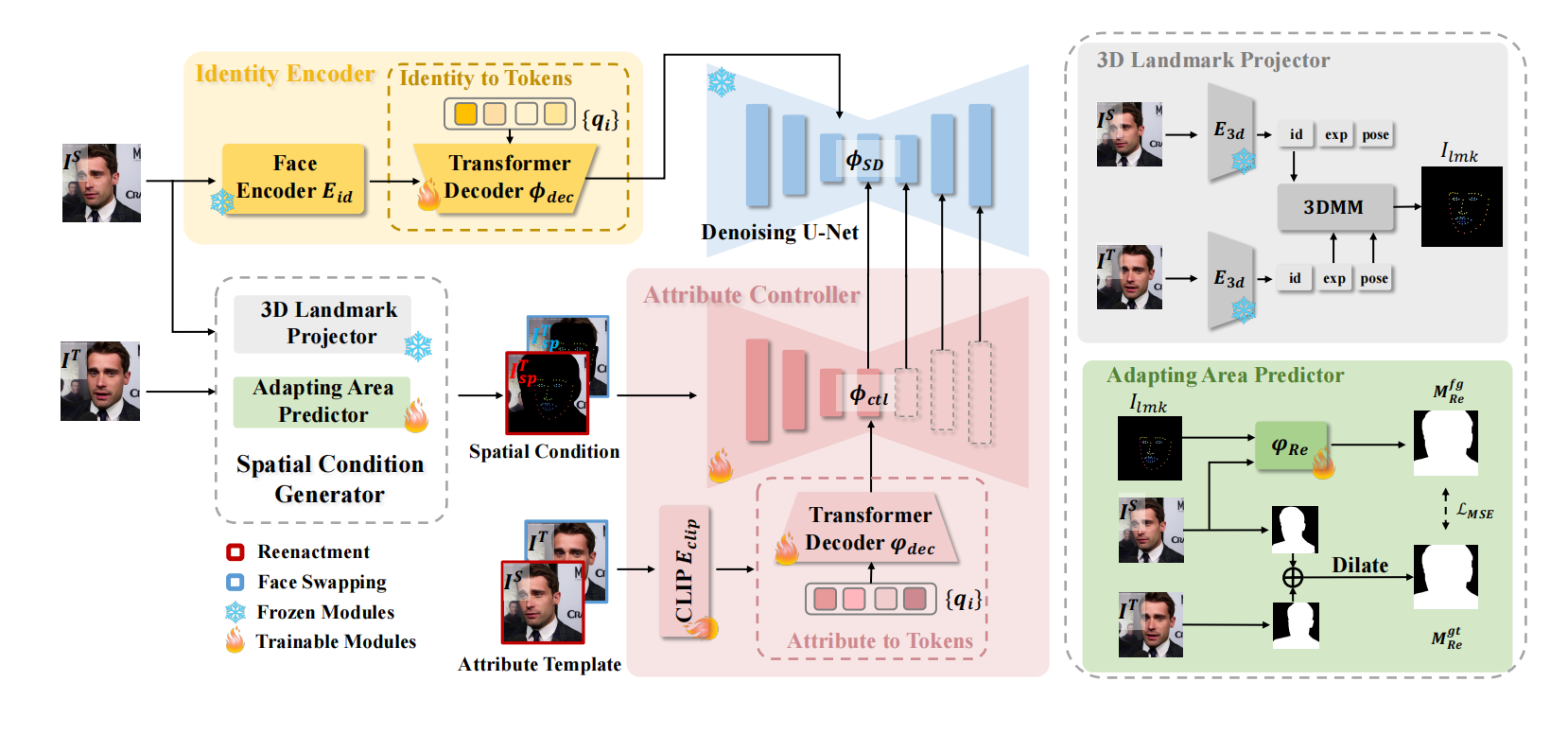
和 ins 的保 ID 一样,都是放到 textual space,结构也都是 sd + controlnet,唯一不同的就是 spatial condition 多了个背景 + ID,故事讲的真tm好
把第一张的ID转移到第二张人上:第一张图提取了 ID,映射到 Tokens,替换掉 denoising unet (正式出图)的 text embedding。第二行类似controlnet 提供条件,3D landmark 解耦 第二张图的 motion 然后合并第1个人的 ID,adaping area predictor 把合并后结果放到膨胀后的mask 内作为结构引导,controlnet 的 text embeding 是 attribute template 的 clip tokens 还是 第一张图 ID。
7、hallo
和 v-Express 结构类似,稍微改了改:face emb 通过 cross attn 注入,音频部分的注意力多个 3个mask 后的 加权和,时间注意力多了个拼接先前的2帧


8、mytalk
音频 + 参考视频 =》参考视频 按照 音频 改变 lip
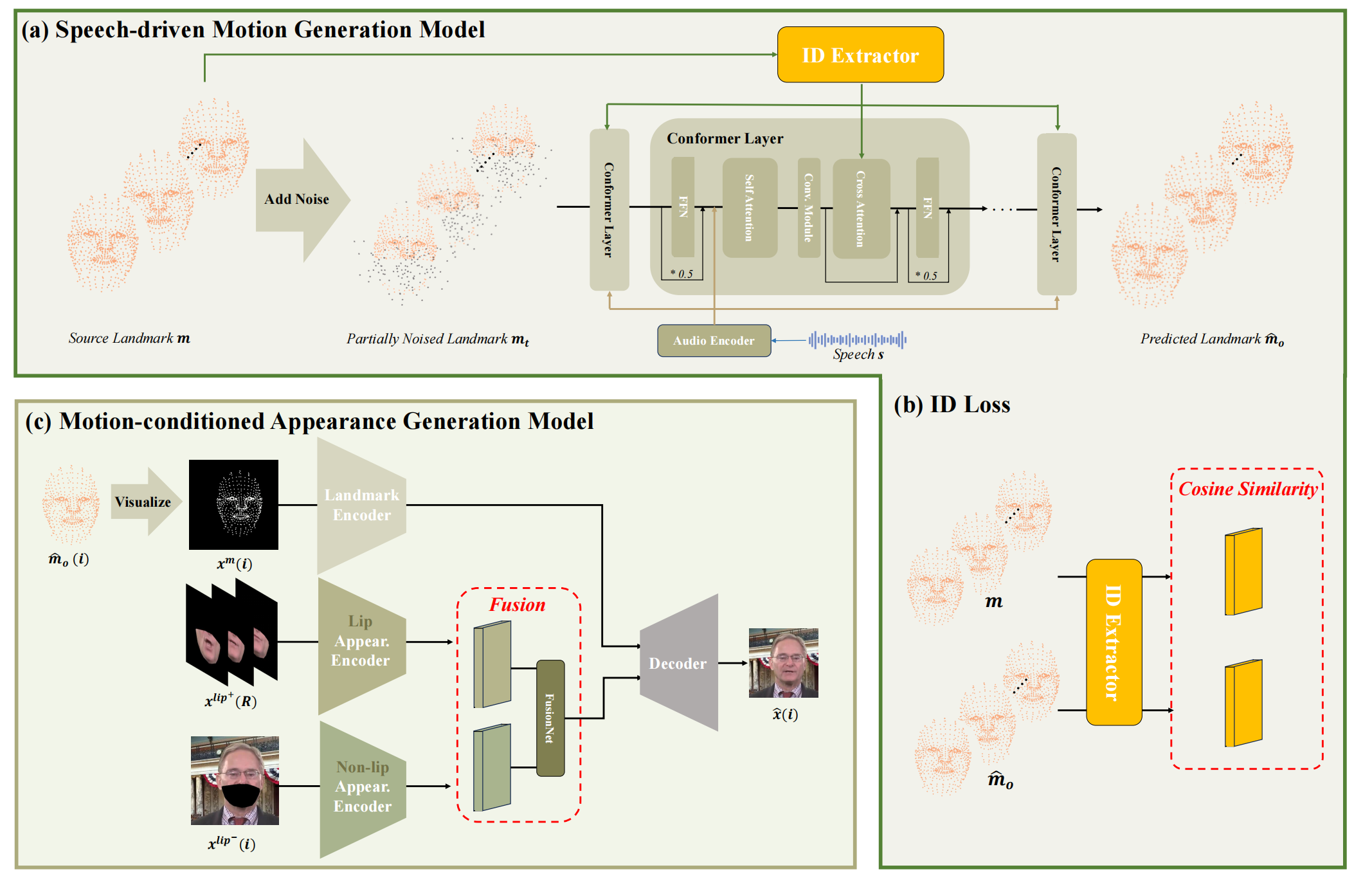
还是2阶段模型。一阶段产生 motion,主体架构是 confromer,接受条件:参考视频的 landmark,该 landmark 的 id 通过 attn 注入,音频。
二阶段接受一阶段结果, 参考视频 lip 外的bg,参考视频随意3帧的 lip 区域(了解 lip 细节),然后 decode
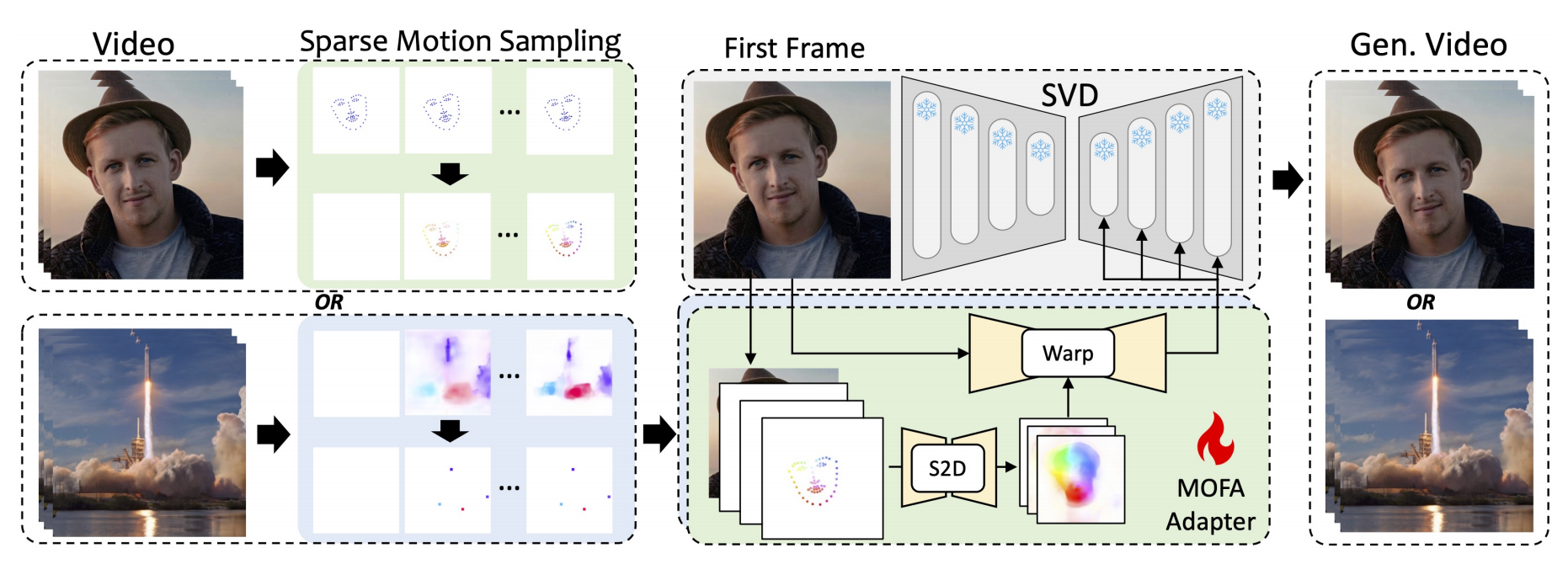
9、MOFA
他的参考图片 + 光流序列 =》 他动起来
还是个一阶段的设计,创新点是他把动作序列、姿态序列通过每帧与第1帧的坐标相减统一为了光流序列。
参考图片还是 ref net,只不过这里复杂了一下(不再是直接拼接):一开始的序列先和ref融合为稠密的序列,再和ref unet中间每层warp,再经过svd encoder做时空融合,然后通过 0 卷积加到denoising unet(训练时固定权重)。
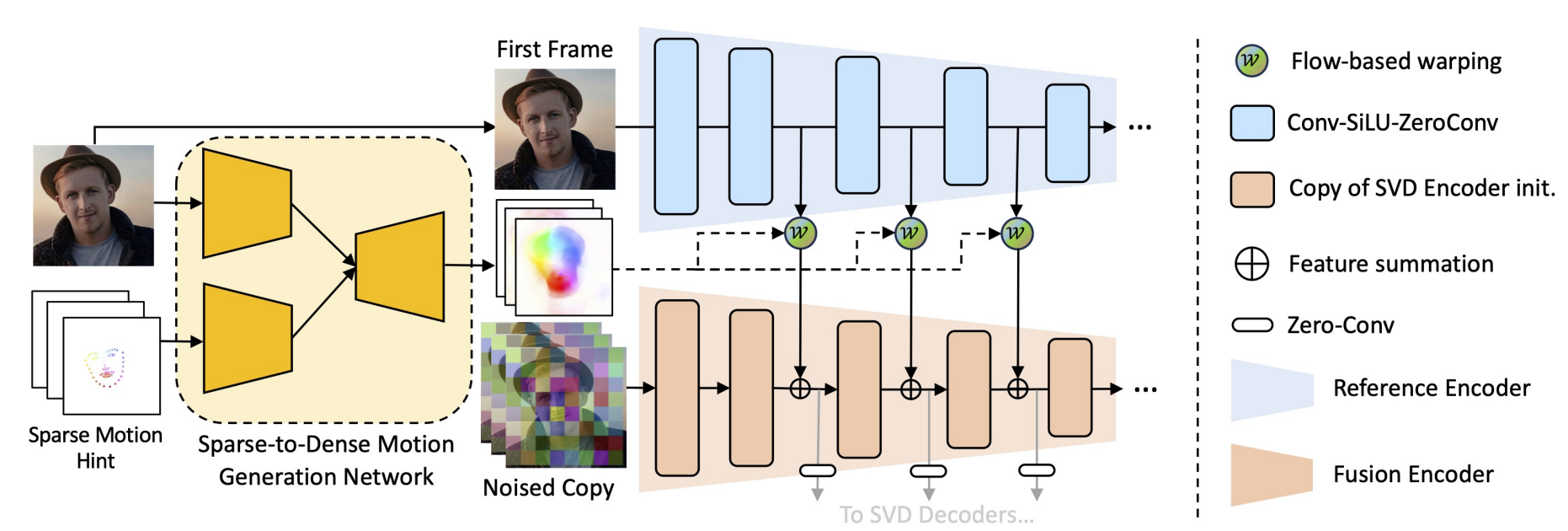
10、vid2vid
驱动视频 + 源图像 =》 源图像动起来
flow 训练:
一个视频取2帧分别作为 源图和 驱动图,对源图提取外形特征fs,期望一个id无关的 flow 能warp fs 得到的y 等同于到驱动图。
id无关的 flow:由于有多个flow,得搞一个mask来加权作为最终的flow。mask:源图 通过 3D 关键点检测网络 L 输出关键点 x s,k(这个和 id 有关,但是与face’s pose and expression 无关),结合驱动关键点,每对关键点算一个 flow,和 fs warp 之后经过 Motion field estimator M 输出 mask。
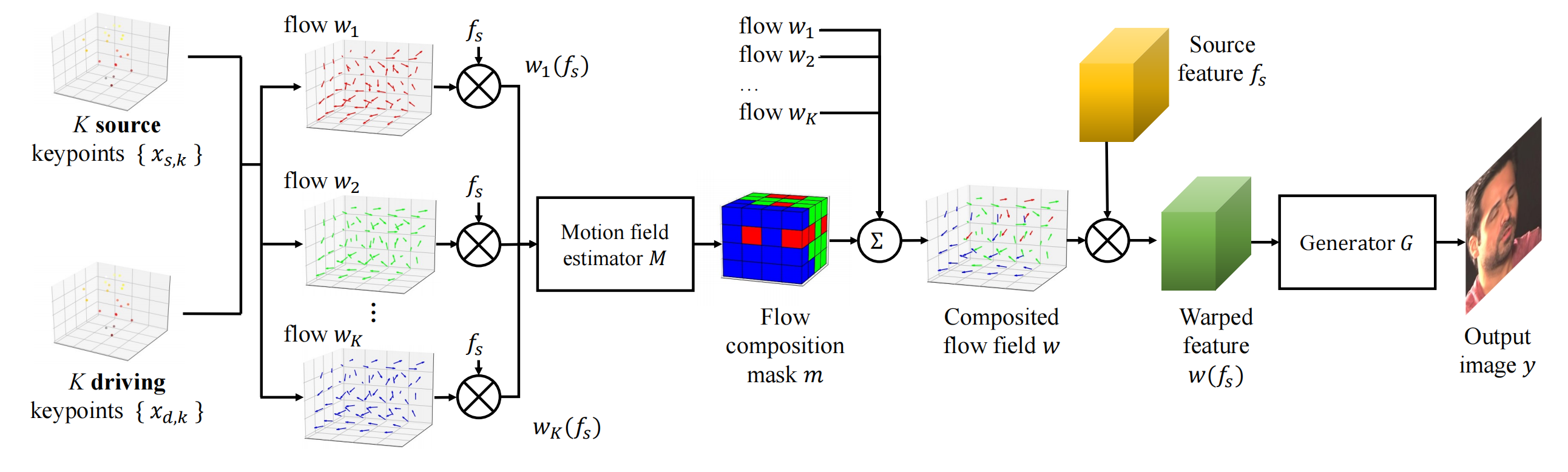
驱动关键点不通过 L,而是通过 x s,k 和 驱动视频的 Head pose (R,t) 和 Expression deformation (delta)推算出来的(下图的x c,k 就是 x s,k):
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号