

sd4
0、prompt2prompt

动机:认为token对应的cross attn map 具备结构信息。方法:给一个初始的promp P,一个编辑后的prompt P*,初始的噪声一样,同时通过dm生成当前时刻的cross attn map :Mt,Mt*,然后根据Mt,Mt*和 P,P*生成 Mt~以便将原始的结构迁移到新的图片上,然后利用Mt~ 和 P* 通过dm采样下一个时刻的zt-1... 注意,每个时刻都会做M的迁移。
Mt~的生成:如果是P和P*就某个词不一样(P =“a big red bicycle” , P* =“a big red car”),那么一开始采样都用P的map,后面采样采用P*的;如果是P*比P多了新词(P =“a castle next to a river” , P*=“children drawing of a castle next to a river”),那么只替换旧词的map;如果想着重强调某个词的编辑,则对这个词的map 乘以一个权重。
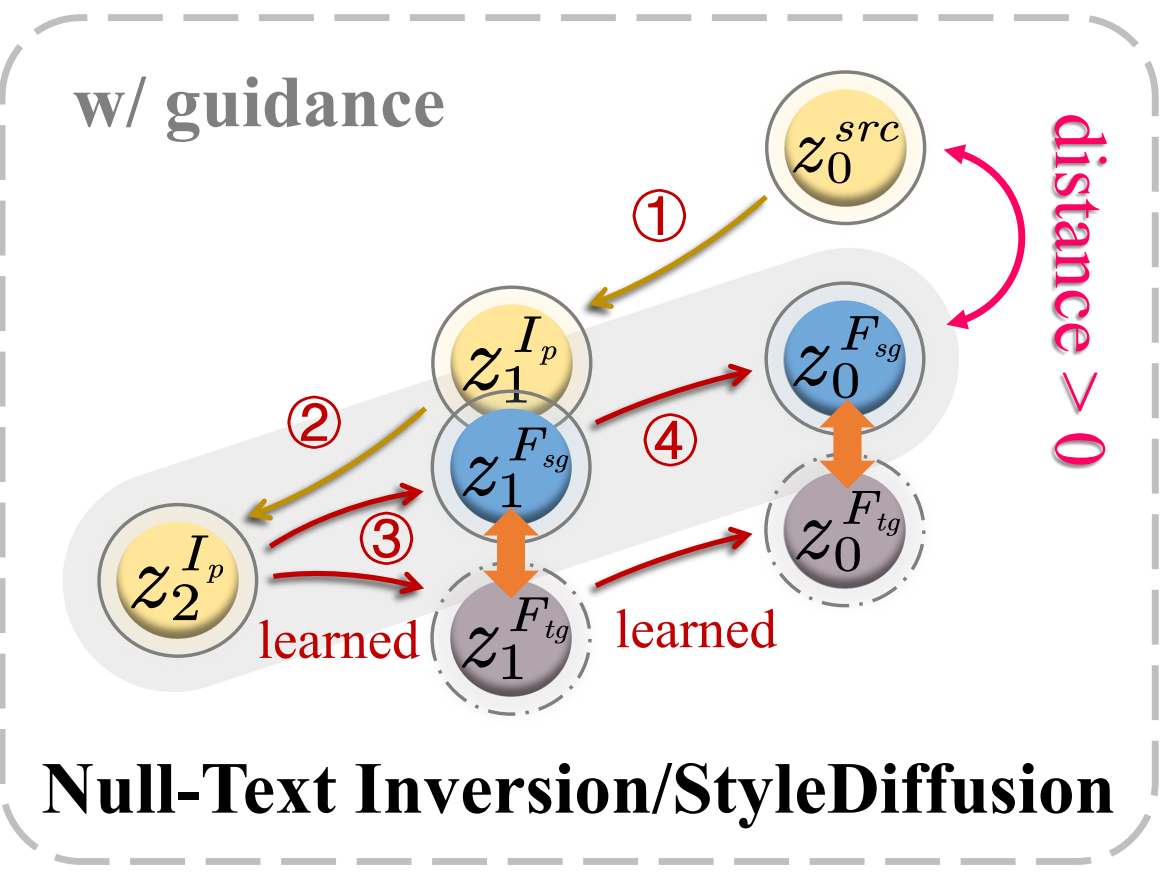
【可视化】可以看出编辑的时候是有2个分支,一个source 分支(图中蓝色),一个target 分支(用于编辑,图中灰色),2个分支都带有CFG,最上面的是 DDIM inversion,序号表示步骤:
1、face0
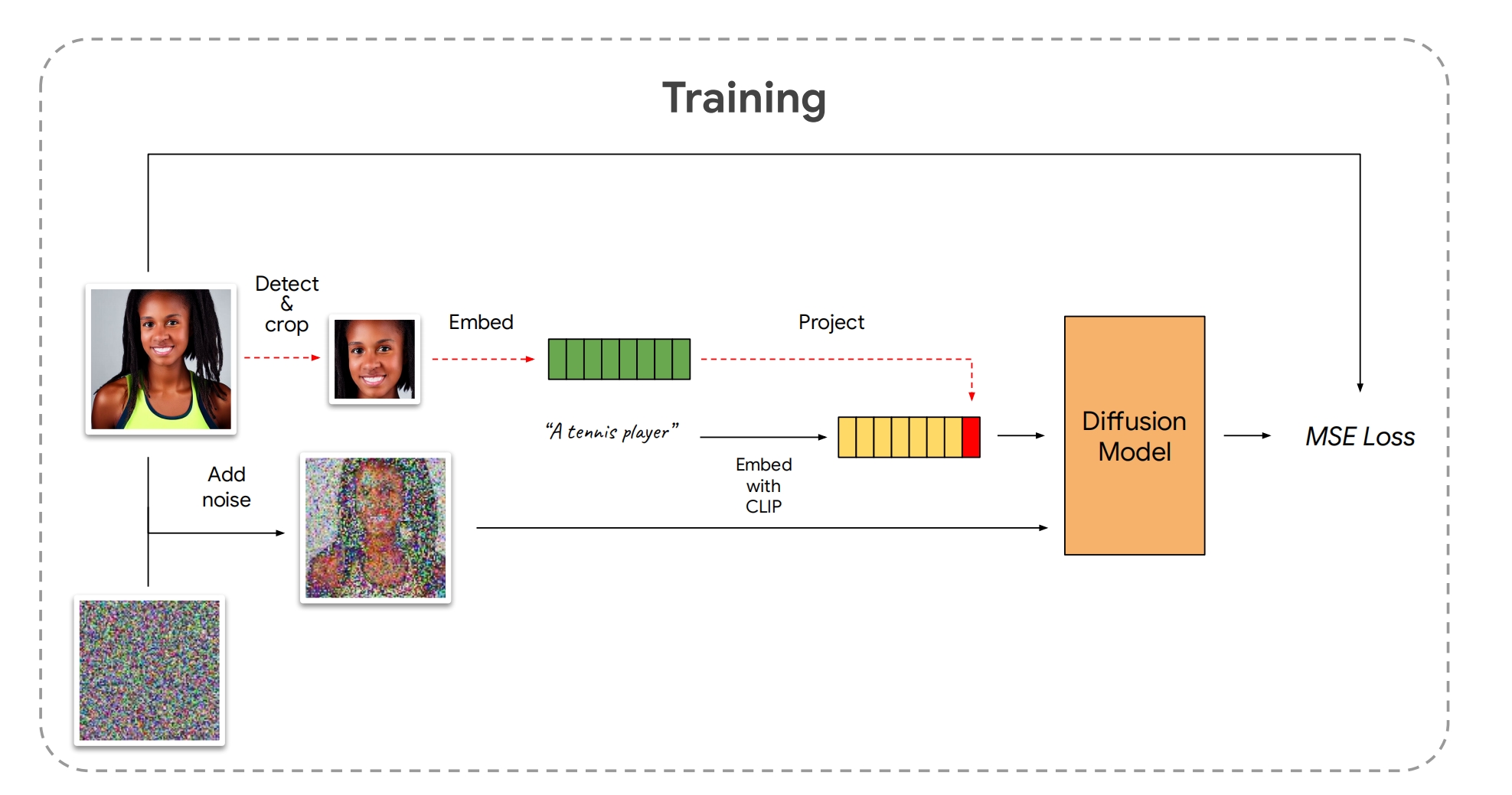
db+id特征,但是不用训练:
LAION上训练一个通用模型,训练的时候需要把人脸图片裁出来,然后提取id向量,在通过多层mlp映射到CLIP空间,然后把文本最后3个 tokens (75-77)的向量替换成向量
2、ShiftDDPM
在前向加噪过程中,给 P(xt|x0,c) 加入偏移项st(c),这样unet就不需要加条件了,是分类器指导和无分类器指导的替代方法:

3、diffusionclip
图,目标文本=>按照目标文本tgt_text编辑后的图(比如人脸图+angry face=》angry 的人脸图)
首先是静态阶段:
将原图x0通过ddim前向过程(T较小)生成噪声(没有条件控制),由于 T 不大,所以这个噪声带一点原图的 id 信息
然后是训练阶段:
将静态阶段生成的噪声,通过ddim解噪出目标图片x(没有条件控制),然后根据src_text(比如face)、tgt_text(比如angry face)、x0、x 计算总loss,然后更新 unet,这样的 unet 就成为了目标是 tgt_text 的 unet。总loss = a * clip_loss + b * id_loss + c * l1_loss

最后是推理阶段:
将静态阶段生成的噪声(普通的ddim模型),用第二步训练(主要是unet)好的 ddim 解噪出图片(没有条件控制)。这个图片就是按照目标文本tgt_text编辑后的图
diffusionclip最大的问题就是,一个模型对应一个编辑方向,比如angry训练一个模型,happy训练一个模型,太麻烦了
4、chatface
diffusionclip的改进版,引入了chatgpt
训练:
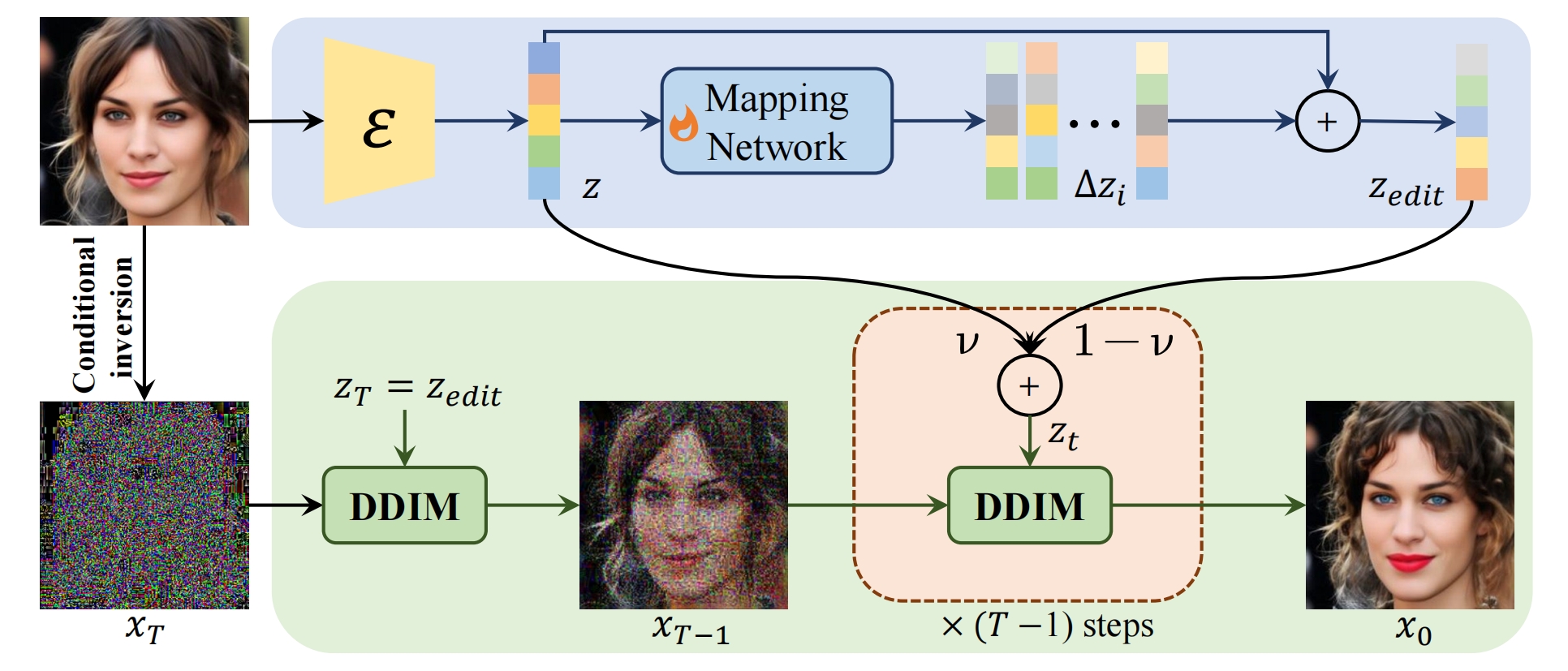
前向过程(又叫inversion):
认为ddim的前向过程生成的XT包含的 id 信息还不够多,于是 引入DAE来编码X0得到id向量 z ,然后Unet 新增个输入条件 z
去噪过程:
显式的引入了既有id又有编辑方向的zt
引入 zedit 表示编辑后的图片 id 向量:将 z 通过mlp得到Δz(奇怪,没有目标文本哪来的Δz?我感觉zt的引入纯属没用),然后加到z上,即
![]()
对z和zedit进行线性差值得到zt,这样即保留id还能引导生成方向,采样过程的Unet用的是zt
loss:
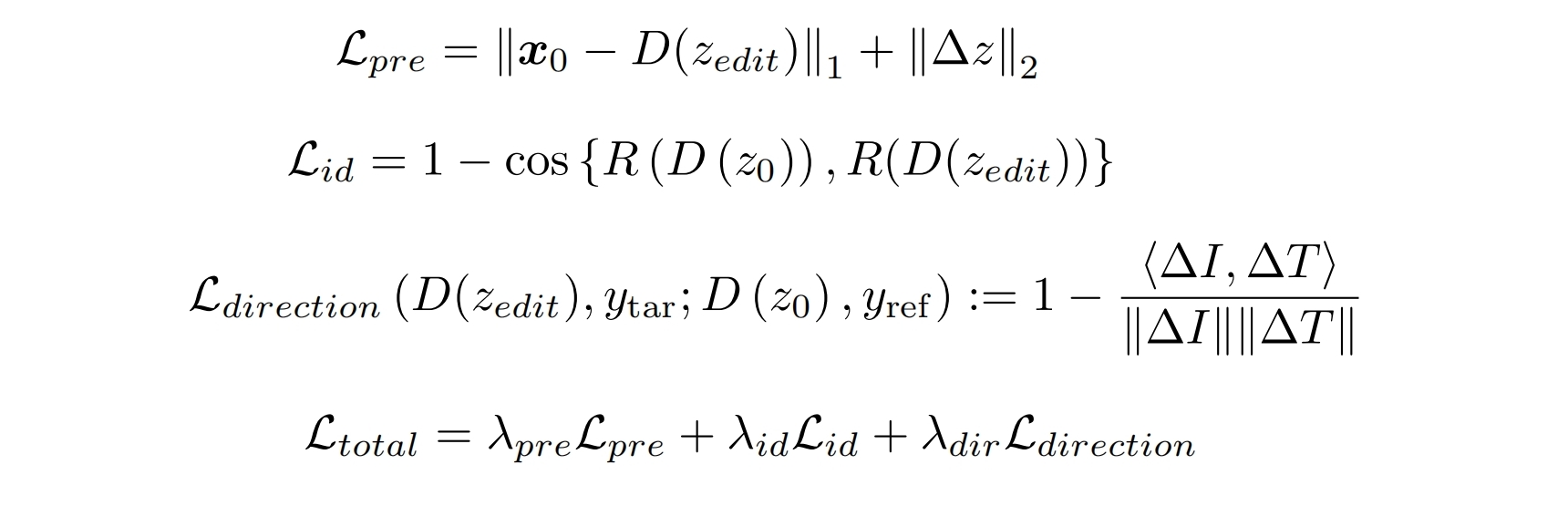
D是ddim的生成过程
注意它的CLIP direction loss是从隐空间映回了像素空间
隐空间的z向量加了约束
Lid是为了保持id不变,R是arcface
Lpre的第一项感觉有问题,应该去掉
5、基于分数的扩散模型
前向过程和ddpm的前向一样
采样:xt->xt-1
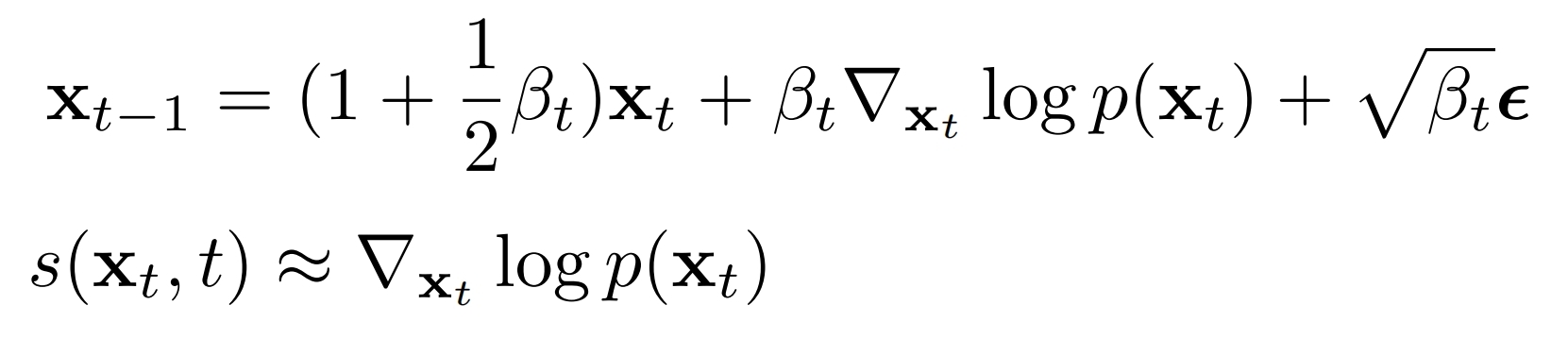
已知xt,预测x0:
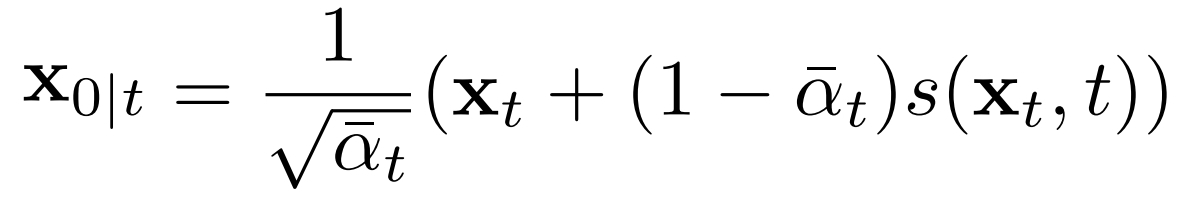
6、基于分数的条件(c)扩散模型
可以实现按照目标条件来编辑,也是在采样阶段引入的指导。如果目标条件是文本,则成了生成文本的图片任务;如果条件是hed,则是基于hed生成图片的任务;
采样:xt->xt-1
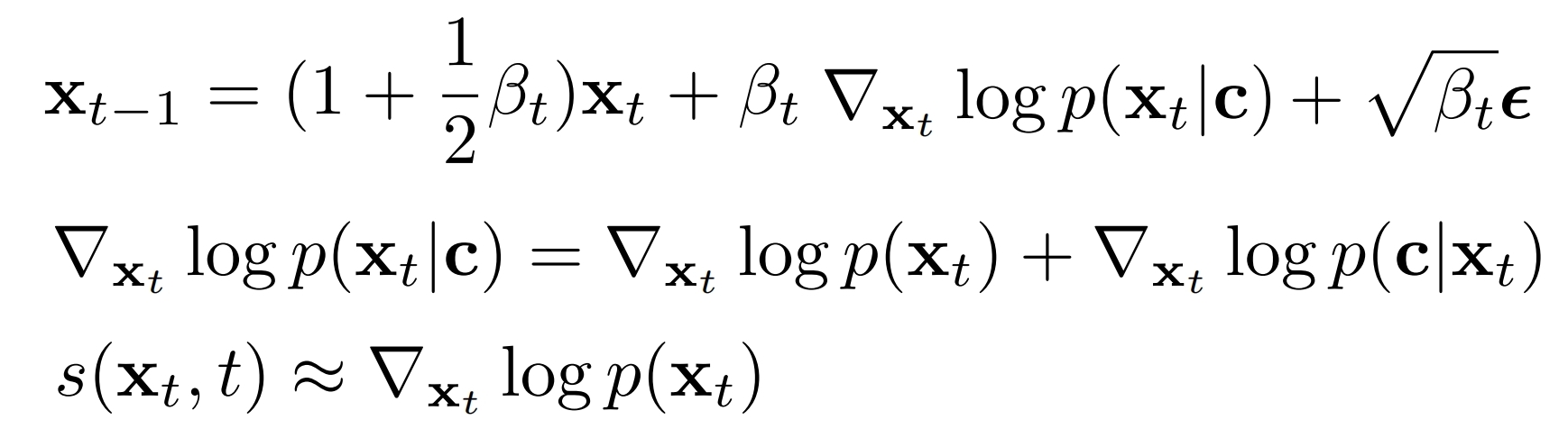
引入能量函数ε(c,xt)后的采样:
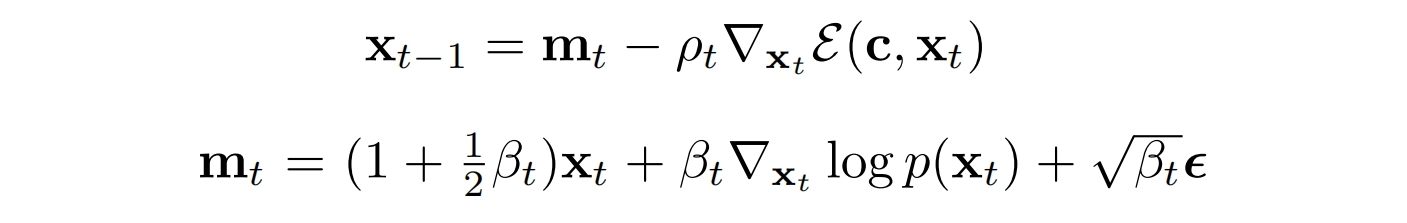
如果用与时间无关且基于条件的预训练网络D来估计能量函数,则最终的采样公式:
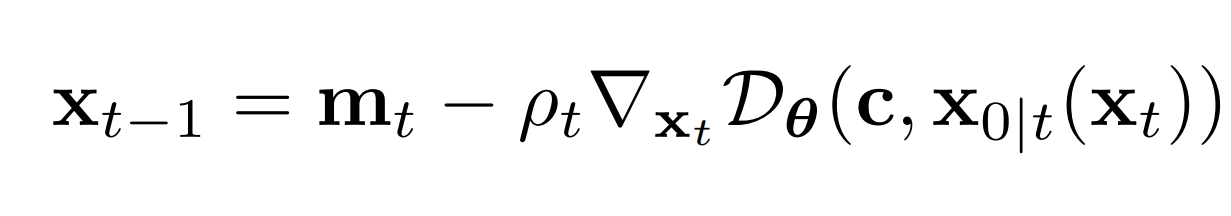
其中:
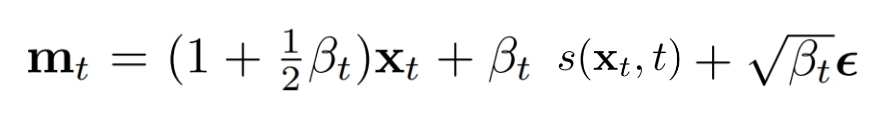
实际代码中的 mt :
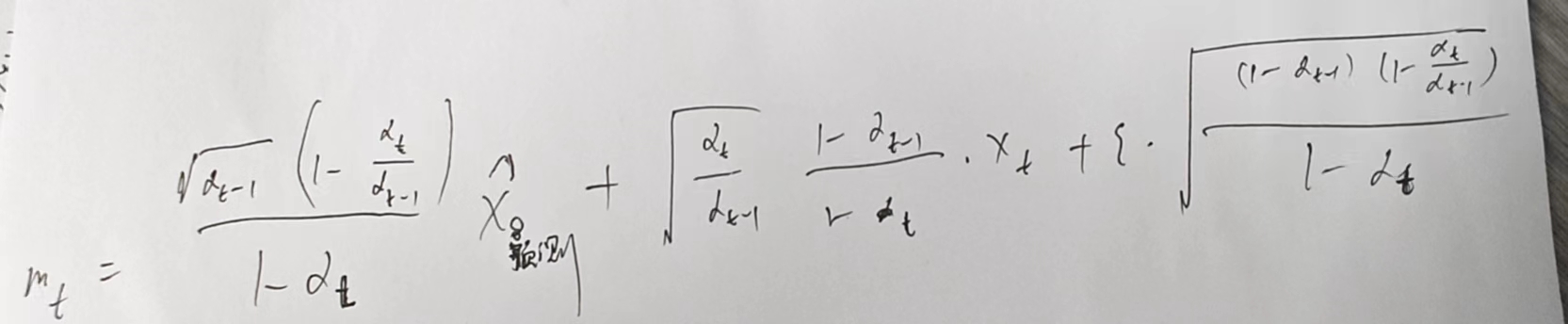
实际代码的pt:

这种采样在小型数据集(如人脸)效果很好,但是在大型数据集上(imageNET)效果很差,这是因为大型数据集上的无条件下的分数具有更大自由度,使得难以朝着目标条件走
FreeDoM 引入了 time-travel strategy使得加入了更多的条件控制:当xt生成xt-1时,再由xt-1按照q(xt|xt-1)生成xt,再由xt生成xt-1。可以设置 time-travel 的次数
单一条件的能量函数:
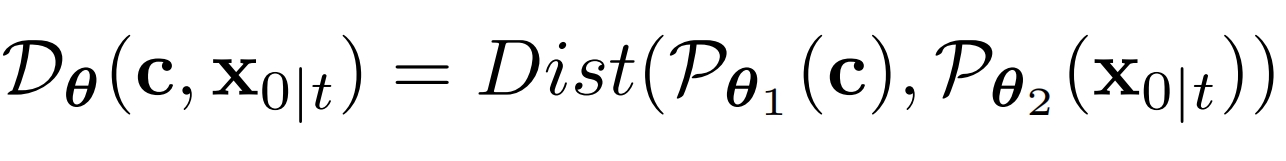
其中Dist是计算两个向量的欧氏距离,Pθ1是神经网络用于将条件c映射为向量,Pθ2是神经网络用于将x0~ 映射为向量
如果条件c是文本,则Pθ1是clip的image 编码器,Pθ2是clip的text 编码器
如果条件c是fp,则Pθ是BiSeNet
如果条件c是id,则Pθ是ArcFace
如果条件c是某个图像的风格,则Pθ:clip的 image 编码器的第三层的所有 patch 向量(196*786)再通过Gram matrix(Perceptual losses for real-time style transfer and super-resolution.),即(196*786)T * (196*786)=768*768 的矩阵
多个条件的能量函数:
就是单个条件的加权和
![]()
实际代码中:带条件的技巧 + time-travel strategy 只在中间的采样阶段(Semantic Stage)使用,实际 time-travel strategy次数设置为3。一开始的采样和最后的采样阶段加上技巧影响不大。所以一开始的采样和最后的采样阶段都用 mt 表示 xt-1
7、unicontrol
1个控制图(可能是mask,sketch...,反之就是1个条件),任务指令,1个文本标题-》生成图
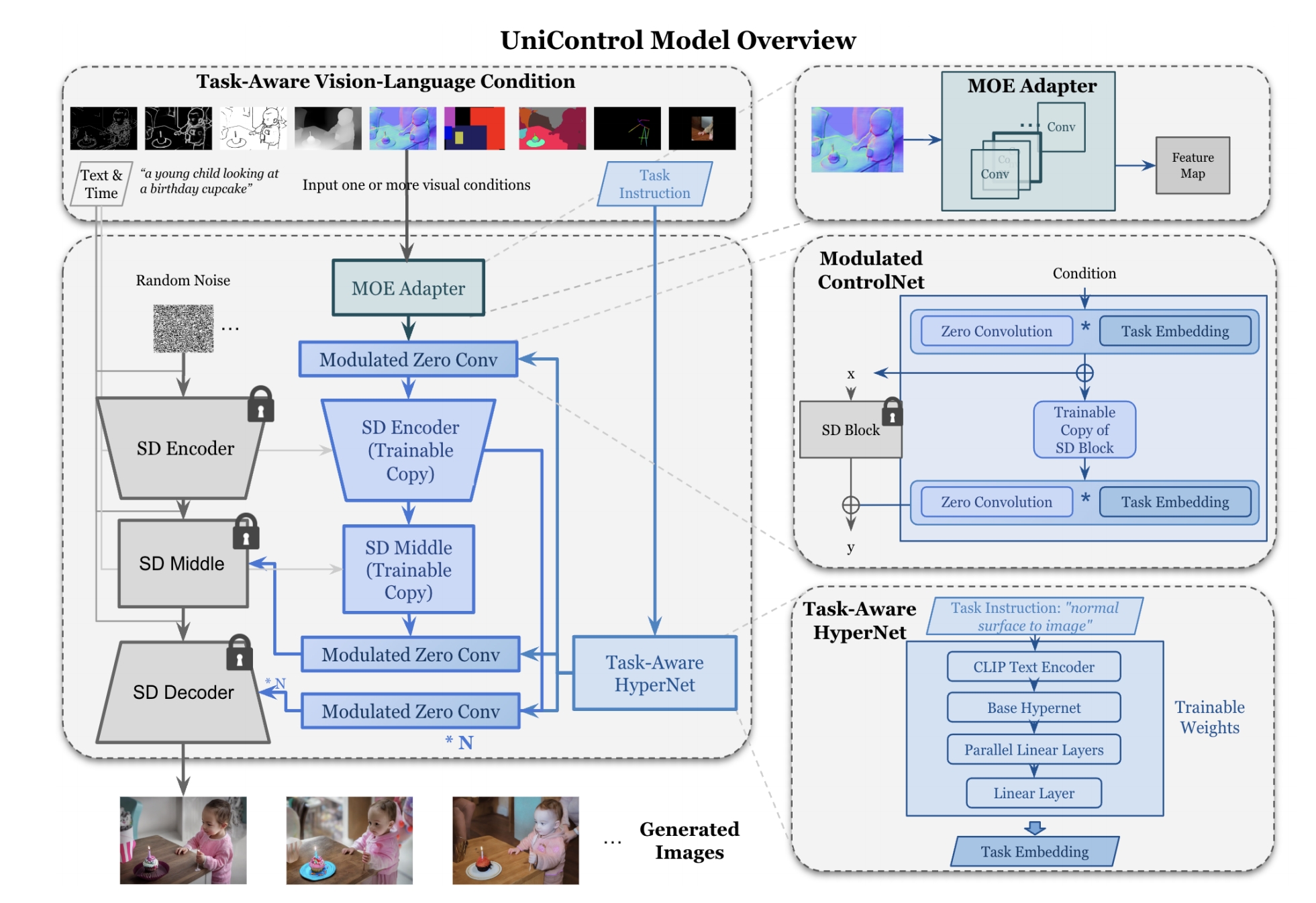
controlnet的改进版,支持多个视觉条件进行混合训练和推理
视觉条件(可能是mask,sketch...,反之就是1个条件)通过moe处理输进来的条件,MOE:就是多个分支代表多个专家,每个分支一个权重,这个权重用gate来计算,最后多个分支加权求和:

另外还加了task-aware hypernet,因为不同视觉条件对应不同的任务指令,比如当输入条件是canny,则指令是:Canny Edge to Image,当hed条件时,指令是 depth map to image
8、videocomposer:可控的文生视频
文本text +
用于提供时间序列,包括
动作序列motion vectors(即所有帧的动作向量图),深度序列(所有帧的深度图),mask序列(所有帧mask后(3个通道)再和mask做厚度拼接,变成4个通道),sketch序列(所有帧的sketch)
和提供空间信息,包括
single_image(第0帧重复16次)single_sketch(第0帧的sketch重复16次)
的参考视频 ref(实际代码里只有动作序列) +
目标图片
=》合成的目标视频
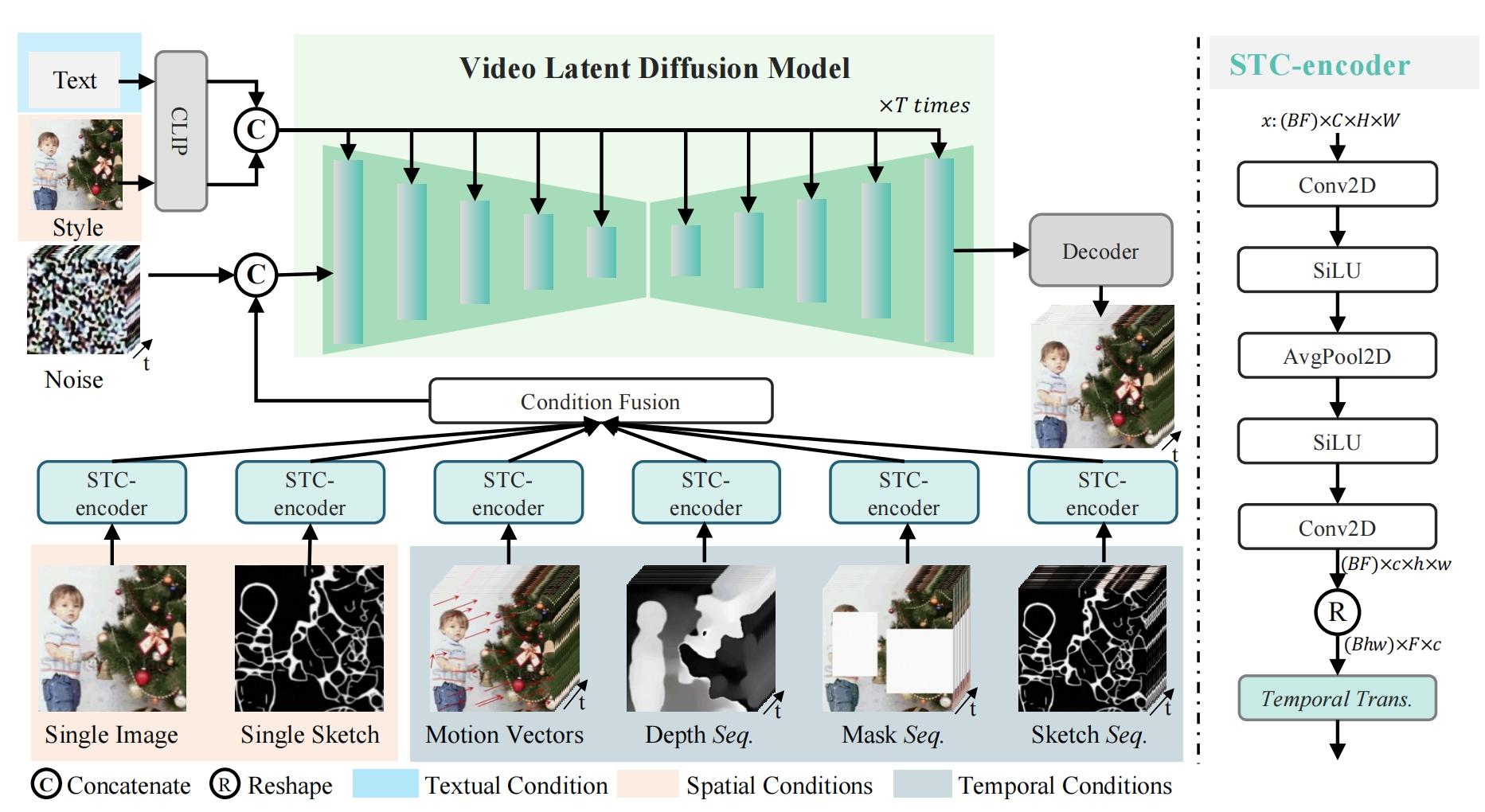
假定视频帧数是16
推理:
左上角提供文本和风格,作为条件3Dnet 的条件输入,3Dnet(论文Video diffusion models.初次引入)就是把时间维度(帧)看成batchsize处理(3 × 3 kernels =》 1 × 3 × 3 kernels),即空间注意力机制,而且由于时间维度的引入,qkv由向量变成了特征图(a temporal self-attention layer),即时间注意力机制。文本通过clip生成 77 * 1024 的序列,图片通过VIT生成1024的风格向量,两者按照字符拼接(C)为 78*1024,然后复制16次,得到 16 * 78 * 1024,输入给 3dunet 做 cross-attention
下面的 single image 是图片(注意和参考视频无关)复制16次,然后通过STC-encoder,其他都是参考视频提供的信息,他们也分别通过STC-encoder
STC负责把时间和空间信息做融合:输入的F是帧数,大小是 batchsize * F * C * H * W,以single image为例,是 16 * 3 * H * W ,通过 conv+silu+池化+ silu+conv (这是为了提取局部空间信息)得到 16 * 8 * 32 * 32的特征图,经过排练R来铺成序列向量,得到1024 * 16 * 8,通过1层Transform层(这是为了建模时间)得到1024*16*8,最后通过R还原为特征图 8 * 16 * 32 *32,作为STC的输出,最后多个STC的输出进行相加,得到 8 * 16 * 32 *32的特征图。
stc的输出合成特征图 和 初始的随机噪声 XT (4 * 16 * 32 * 32)进行厚度拼接:12 * 16 * 32 * 32,得到 ZT,ZT 和 t 和 条件 (16 * 78 * 1024 )共同输入到 3Dunet 里面得到估计的噪声ε1(4 * 16 * 32 * 32)
还要算当左上角的文本和图片都是空的情况下的ε2,两个噪声:guidence * (ε1-ε2)+ε2 得到最终的噪声εθ
εθ和xT(注意不是ZT) 按照ddim 算出xt-1,然后再算一下stc的输出合成特征图 和 xt-1 进行厚度拼接 ...
得到最后的x0(16 * 4 * 32 *32 ),然后用 vae 解码得到合成视频
获取一个帧的动作向量图:
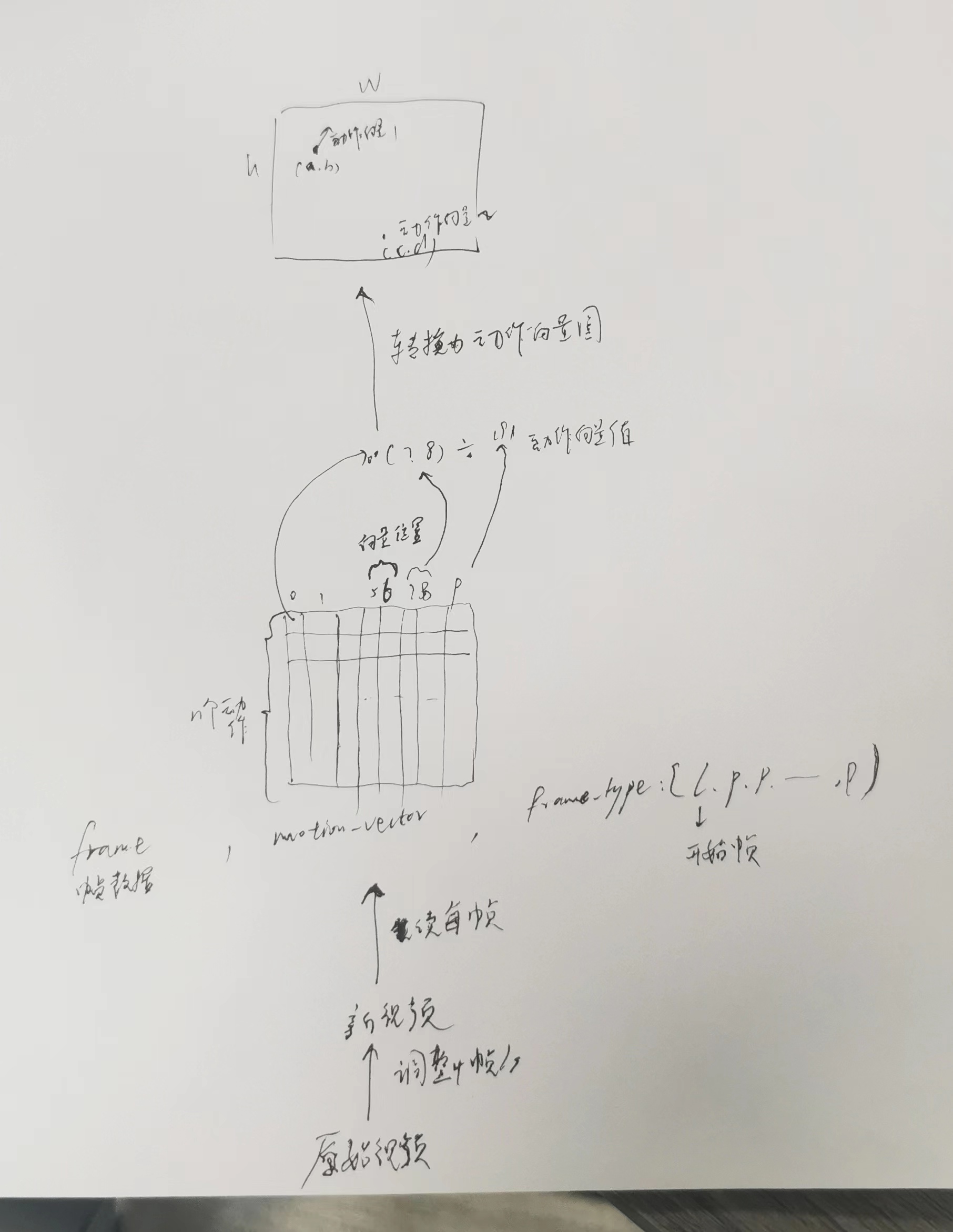
训练:
把推理中用的图片全部换成视频的第一帧。视频一开始要被vae映射才能成为x0。第一阶段是初级阶段,为了建模时间,只有左上角的那部分,不要下面的多条件融合;第二阶段带上下面的多条件训练,为了学习多条件控制
功能:
图片+文+动作序列=》按照文让图按照运动方向动起来:style是图片(或没有),动作序列是参考视频提供的
图片+文=》按照文让图动起来;
single_image + 文=》让single_image动起来;参考视频的第0帧转为single_image
image1 + 深度序列=>按照image1风格且符合深度的视频:参考视频转为深度序列,style是参考视频的中间帧
mask seq + 文 =>视频修复;mask后的参考视频(3个通道)再和mask做厚度拼接,变成4个通道,得到mask seq
mask seq + 文 + 深度seq/sketch seq=>视频修复成给定结构;
sketch图 + 文 =》让sketch动起来:sketch图重复16次作为sketch seq
sketch seq + 文=》按照sketch填充的视频:参考视频转成sketch seq
sketch图 + 文 + 风格图片 =》让sketch具备指定风格且动起来:style是 风格图片,sketch图重复16次作为sketch seq
视频 + 文 + 动作 => 去掉不符合文本描述的背景的视频,相当于视频编辑,把视频里某个东西去掉了
文本 + 深度序列 => 按照文本且符合深度的视频:参考视频转为深度序列
文本 + 深度序列 + 风格图片=> 按照文本且符合深度序列和风格图片的视频:参考视频转为深度序列,style: 风格图片
局限性:训练集 WebVid10M 有水印,质量不高。
9、t2i-adapter
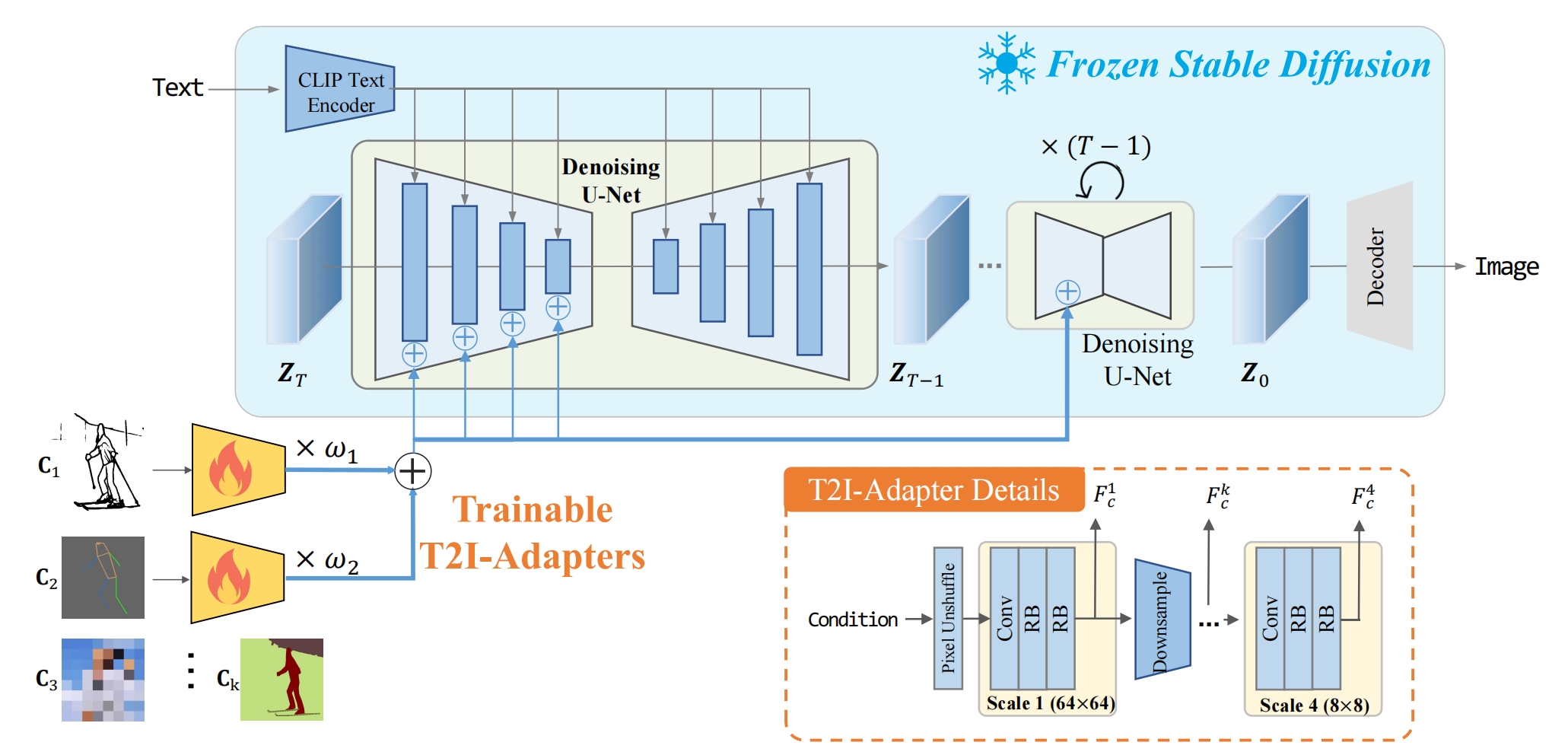
文+可控图片(sketch,pose,颜色..)=》图片,和controlnet功能一样
就是在预训练好的sd模型外接一个复合型adapter,复合型adapter是多个adapter的加权和,每个adapter对应一个视觉条件
训练的时候固定住sd,只训练adapter。训练集和controlnet一样,都是(文,抽出来的条件,原始图片)
10、Tune-A-Video
参考的(文+视频) + 新的文 => 编辑后新的视频,如果底膜用controlnet或者t2iadapter,还能加入参考的视觉条件,比如姿态图序列
微调:为了记住参考的(文+视频)
为了提高 3Dnet 的时间一致性,将空间注意力机制改为时空注意力:当前帧做Q,上一帧和第一帧拼接结果做K和V,而且K和V的权重冻住,只训练Q的权重。时间注意力机制全部训练Q,K,V。交叉注意力只更新Q层,这是为了保留原始权重+优化计算。ffn也冻住。
推理:
先ddim 加噪源视频得到噪声以保留一点结构信息,然后对这个噪声+新的prompt 用ddim采样
和videocomposer比较:虽然videocomposer都能实现大部分任务,但是tune的节省训练成本:类似db,将参考的(文+视频)作为概念去微调,以便记住,然后取推理;tune还能记住人名,用人名去生成视频。
局限性:无法处理多个物体和有遮挡的情况,可能需要引入深度图做进一步研究。
11、FateZero
原文本+原视频+新文本=》按照新文本编辑后的视频
以往方法1:首先ddim inversion:原始视频+原始文本=》zT,然后采样:按照新文本来解噪声,会导致帧间的不一致性
以往方法2:首先ddim inversion:原始视频+原始文本=》zT,然后DDIM Reconstruction:按照原始文本来解噪声并保存中间的注意力权重,最后采样:按照新文本来解噪声同时注入Reconstruction阶段的注意力权重。效果不佳,因为Reconstruction阶段的注意力权重不能保存好原始视频的轮廓和姿态
FateZero方法:首先ddim inversion:原始视频+原始文本=》zT,同时保存中间的注意力权重(和v相乘的权重),然后采样:按照新文本来解噪声同时注入inversion阶段的注意力权重。效果很好,因为inversion阶段的注意力权重可以保存好原始视频的轮廓和姿态。如果在Reconstruction阶段也注入inversion阶段的注意力权重,那么复原原始视频的效果更好。
其中关于注意力权重:包括交叉注意力权重和自注意力权重(Cross-attention map and self-attention map)。交叉注意力权重的注入方式和论文Prompt-to-Prompt类似,prompt当中的每个词都有自己的交叉注意力权重,可以代表这次词的语义表示图。替换的时候只替换新文本中出现在原文本中的旧单词的交叉权重。自注意力权重则先取原文本的交叉注意力权重并进行二值化,白色区域用新文本的自注意力权重,黑色区域用旧文本的自注意力权重。
3Dunet沿用tune的方法,只不过上一帧和第一帧换成当前当前帧和中间帧
和tune比较:是Prompt-to-Prompt的视频改进版本,通过引入inversion的注意力权重更好的保持了原视频的物体轮廓,且无需训练。
局限性:编辑不了大的运动(游泳-》飞行)以及大的形状(天鹅-》龙)
12、Structure and Content-Guided
原视频的深度图序列+新文本=》按照新文本编辑后的视频
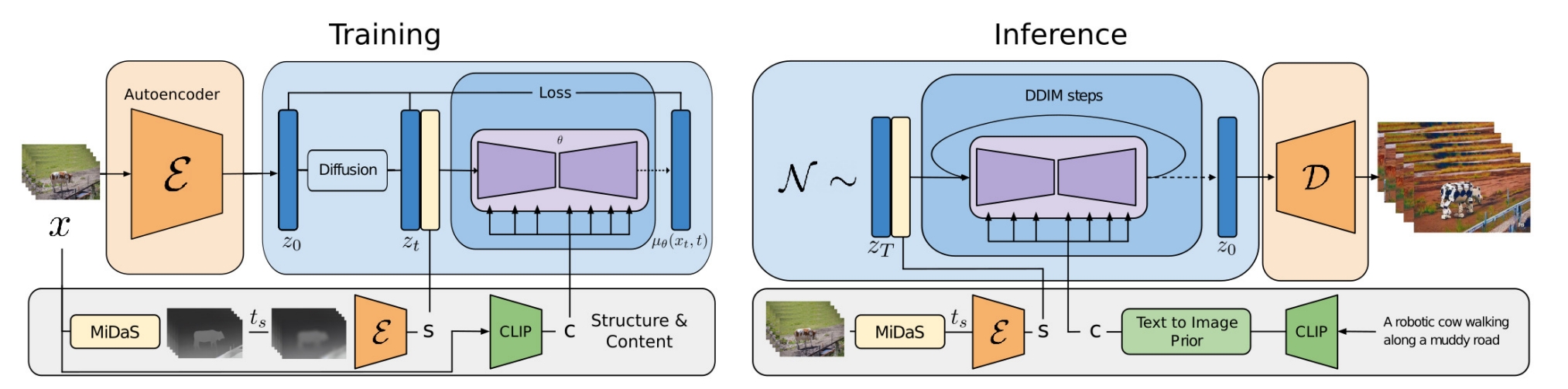
videocomposer的阉割版,只有1个视觉条件:训练阶段的视觉条件只有参考视频的深度seq,深度seq的处理是经过ts步的模糊+编码器得到特征图序列,特征图序列与 zt 拼接。视频中的随意一帧通过clip生成风格向量,没有文本。推理的时候提供参考视频的深度seq,编辑文本通过clip+prior model生成风格向量。
用到的其他技巧:
引入 v-parameterization 改进了扩散模型损失函数,以提高色彩一致性
训练是联合图片和视频一起训的,图片当做单帧的视频
类似 classifier free diffusion guidance,预测阶段为了实现对时间一致性的控制,用图片unet π和视频unet 共同预测噪声,图片unet π起到负提示词的作用,图片unet π用到视频的每一帧当中:
![]()
13、Null-text Inversion
图像重建和图像编辑
训练图像重建:
给定 文+图片,先进行DDIM inversion 并只考虑带文本条件的噪声估计(即设置 guidance scale w = 1,否则最后的噪声向量会不符合高斯分布),得到一个从t=0到t=T的轨迹:ZT*,ZT-1*,...,Z0*,论文把这个轨迹叫做pivot trajectory
为了使得采样出的轨迹能接近 inversion 的轨迹从而保留原图的结构信息,并将这种结构信息保存到空文本的向量当中。于是接下来边采样边训练,考虑有条件和无条件并设置 guidance scale w = 7.5(如果不训练,直接采样,那么生成的图会与原图有很大差别,丧失了原图的结构信息),无条件的文本置为"",先从T到T-1:令损失函数为采样得到的 zt-1 和 ZT-1* 做差再取绝对值,单独更新""所对应的向量,模型其他位置的权重保持不变。这个更新的步骤可以重复N次。更新完后,再重新算 zt-1,用最新的 zt-1 和 ZT-1* 的损失计算,也是只更新""所对应的向量...
图像编辑:用训练好的""所对应的向量,再加上prompt2prompt方法,可以实现 :旧文本+旧图片+新文本=》新图片
局限性:FateZero认为来自重建的结构信息没有来自inversion中的结构信息多;每次要编辑一个图片,都得训练一下图文对,如果是同一个图文对,训练一次就够了,编辑的文本可以五花八门;sd的注意力权重图还不如Imagen的注意力图,所以基于文本的编辑并不是特别强。复杂的结构编辑做不了,比如坐的狗编辑不了站的狗。
14、AnimateDiff
文直接生视频(将自定义的文生图(如db)变成自定义的文直接生视频)
大规模训练:WebVid-10M(文+视频)做训练集 ,改进了 3Dunet,在每个分辨率块上都加入运动模块(运动模块用于捕获视频当中同一位置的帧和帧之间的关系,这是为了提高视频中的动作平滑性和内容一致性)。
运动模块基于Transformer,把h和w都放到了bz维度,然后铺成了 f 个帧,每个帧是 c 维度,所以又叫 temporal transformer,为了不影响原模型的效果,project out 一开始0初始化:
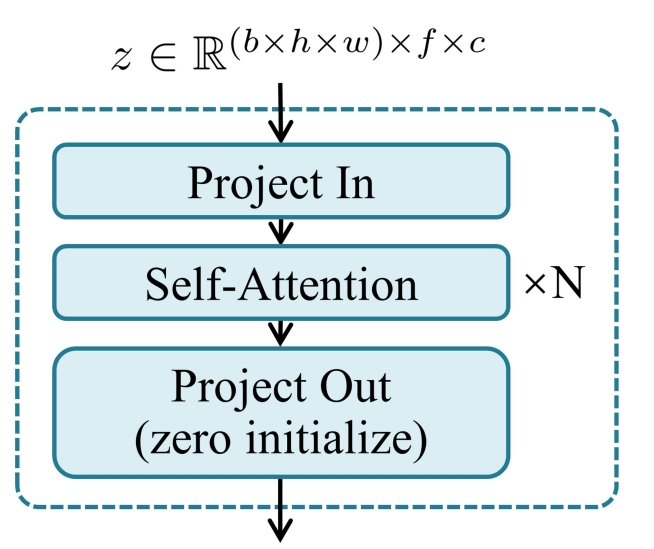
推理:把上面训练好的运动模块按照原来位置插入到各种自定义好的sd模型(比如db训练好的模型)中,根据自定义文本生成视频(原来是根据自定义的文本生成图片)
局限性:如果db训练好的模型是基于不同于真实世界的数据训练得到的,则不能做很好的迁移。不同指定多余条件。
15、 Text2Video-Zero
文生视频(逐帧的生成)
引入Motion Dynamic以提高视频全局的时间一致性(因为所有帧都源于同一个XT'1产生的):
假定要产生m帧的视频,对于第一帧的XT1,直接从高斯噪声采样一个作为XT1,然后将XT1用 DDIM 采样Δt步得到XT'1,再产生一个动作向量δ=(δx=1,δy=1)
对于第 k 帧的XTk:将动作向量拉长 (k-1) 倍,然后拿拉长后的动作向量去扭曲XT'1,随后用DDIM前向加噪 Δt步 得到 XTk。(在XT'1上操作而不在XT上操作的原因就是不影响XT的高斯分布)
引入 Cross-Frame Attention以提高视频中前景物体的 id 一致性:
将SD的自注意力机制全部替换为交叉注意力机制,所有帧全部去注意第1帧:K和V都用第一帧的,Q用第K帧的
背景平滑(可选):
首先对前面的 k 个噪声分别采样并解码得到一个初始视频,然后对每个帧做物体检测,得到掩码 Mk,第一帧在通过Wk扭曲,然后利用掩码做组合运算
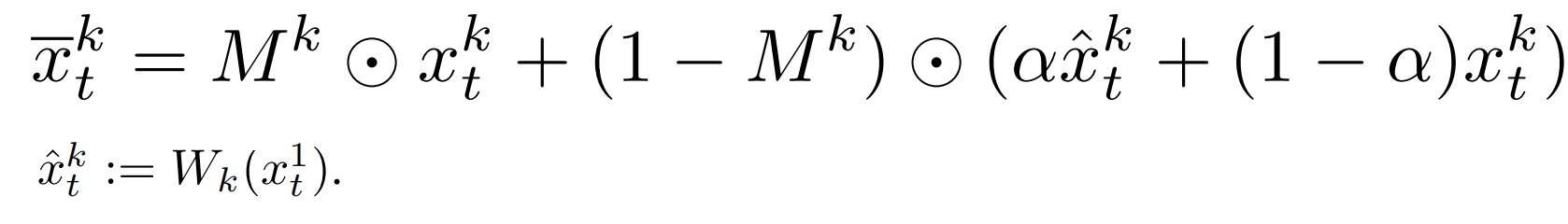
然后 DDIM 就对xkt_做采样得到最终视频
hed(edge...)+prompt =》生成视频:
把 controlnet 自注意力改为帧注意力,都注意第一帧,然后进行逐个帧的采样(实际上按照batch采样),所有帧的噪声XT都是一致的,每个帧都有自己的视觉条件,这个视觉条件可以从条件视频中逐帧抽出。如果controlnet所采用的sd权重来自于db,可以实现概念个性化视频生成
按指令编辑视频:
将 Instruct-Pix2Pix 的自注意力改为 cross-frame attentions,实现了按指令编辑视频
16、IMAGEN VIDEO
较复杂的文生视频
IMAGEN:
文本单独通过更大的Text encoder (如T5)得到语义向量,然后通过一个基本的扩散模型得到一个低分辨率的图片,低分辨率图片 + 文本向量作为两个条件 通过扩散模型生成较高分辨率图片,其中低分辨率图片先上采样到较高分辨率图片,然后和xt做厚度拼接再作为unet的输入数据
较高分辨率图片+文本向量 再通过(级联)扩散模型生成更高分辨率图片
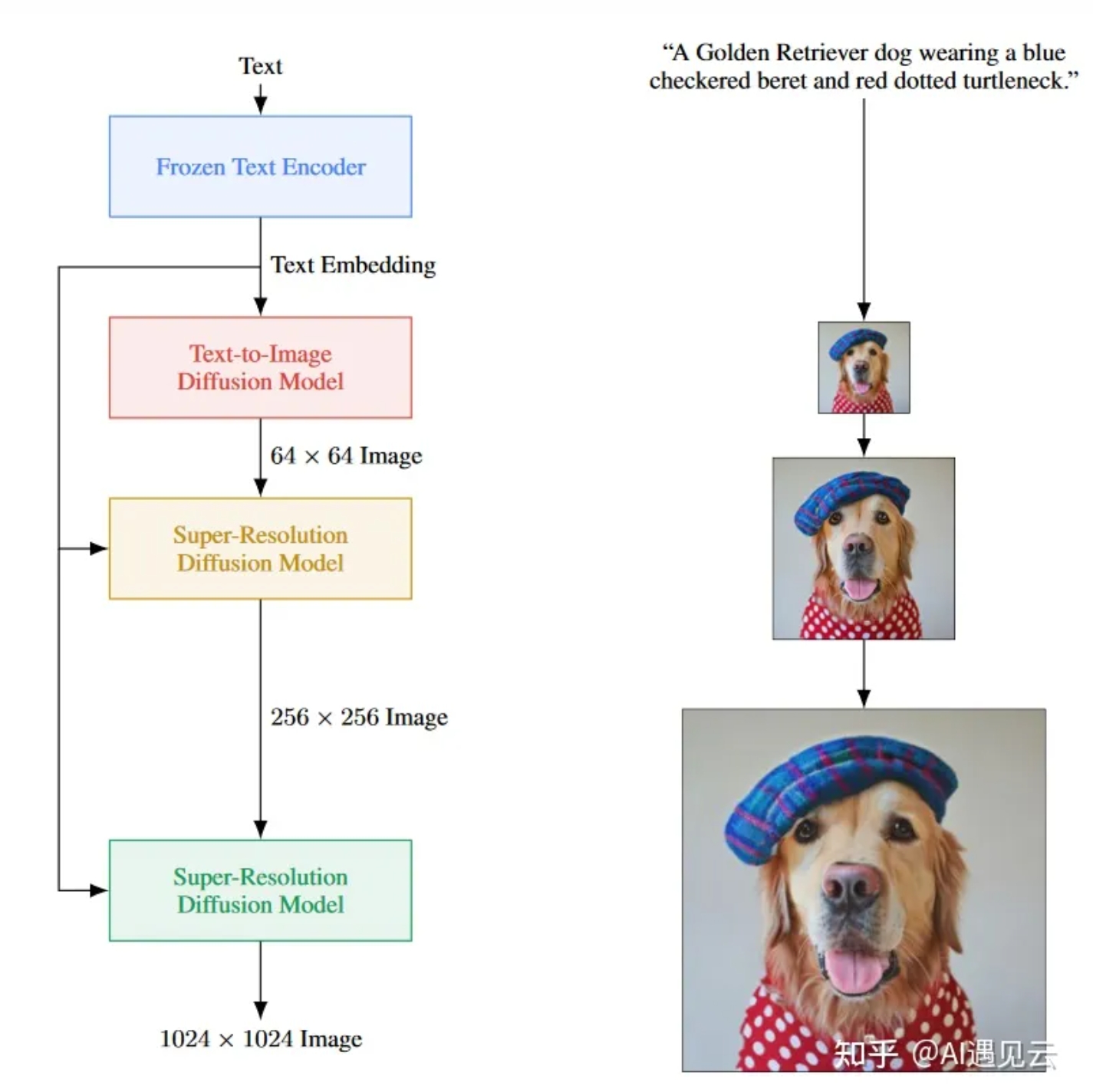
IMAGEN VIDEO 是 IMAGEN 扩展到视频领域,首先是基础视频扩散模型(以文本为条件,生成初始低分辨率视频),然后是SSR、TSR扩散模型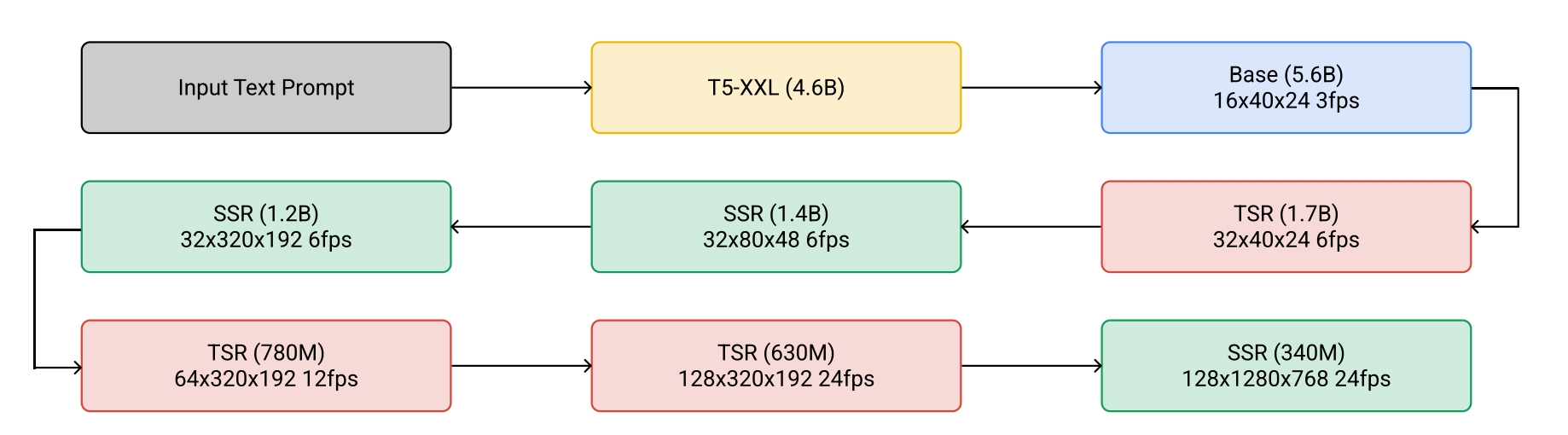
SSR是为了提高视频的分辨率,和上面的 IMAGEN 的超分扩散模型类似
TSR是提高帧数的机制,将低帧数视频通过均匀插入空白帧或者重复帧的方式,然后与有噪声的高帧数视频拼接
针对级联模型,训练中引入噪声增强技巧,用于降低前面输出和后面输入的敏感性
文和视频 、文和图像 联合训练比单独文和视频训练效果更好,且实现从图像到视频的知识转移。
直接clip到指定范围可能导致过饱和,引入dynamic thresholding,给定一个阈值s:
![]()
但这个阈值结合小的guidence权重作用更大,所以采样的时候guidence权重是震荡变化的
使用 progressive distillation 加速采样
17、DREAMIX
基于 IMAGEN VIDEO 改进,采样的时候不用完全随机的噪声,而是将参考视频下采样再加一堆噪声以实现部分结构信息保留。
为了更好的保留参考视频的id信息,还需要微调,微调的时候不仅预测整个视频还要预测视频的单个帧,这样就可以实现对静态图片动起来,对于帧需要 masked temporal attention 以防止时间注意力和卷积(用于学习帧间关系的)被微调。这两个损失函数按权重相加。
文+图片=》animate:图片复制16帧成视频,然后只微调帧( masked temporal attention finetuning),如果产生平移或者缩放的效果,则对这16帧分别做一些透视变换
视频编辑:参考视频下采样再加一堆噪声,再用新文本采样

 浙公网安备 33010602011771号
浙公网安备 33010602011771号