


code3
ros2 工作空间包含多个功能包,1个功能包包含多个节点,通常在工作工作下新建src文件夹,src里面装功能包。每个功能包有manifest.xml 作为这个包的meta文件。colcon是用来编译的。编译完后会产生三个文件夹:build,install,log。ros2 pkg create 是创建功能包。编译的时候在ws下运行。编译后需要 source install/setup.bash ,以便让系统知道这个包的存在,可通过 ros2 pkg list 找到。rqt_graph 可以看节点之间的关系。
创建节点步骤:
1、创建工作空间:
mkdir -p town_ws/src
cd town_ws/src
2、创建功能包village_li(python 环境下):
ros2 pkg create village_li --build-type ament_python --dependencies rclpy
3、town_ws/src/village_li/village_li 文件夹下写节点文件li4.py,例子:
import rclpy
from rclpy.node import Node
from std_msgs.msg import String, UInt32
# from std_msgs.msg import String
class WriterNode(Node):
def __init__(self, name):
super().__init__(name)
self.get_logger().info("大家好,我是作家 %s"%name)
self.pub_novel = self.create_publisher(String, "sexy_girl", 10) # 创建发布者,传入发布的类型,话题名字,队列大小
self.count = 0 # 章节编号
self.timer_period = 3
self.account = 80
self.timer = self.create_timer(self.timer_period, self.time_callback) # 创建定时器,每self.timer_period秒执行回调函数
self.sub_money = self.create_subscription(UInt32, "sexy_girl_money", self.rec_money_callback, 10) # 订阅(监控)话题 sexy_girl_money,如果该话题收到了消息,则执行回掉函数 rec_money_callback
# 命令:ros2 topic pub /sexy_girl_money std_msgs/msg/UInt32 "{data: 10}" -1 的意思是:往/sexy_girl_money发1次消息,消息内容是{data: 10}
def time_callback(self):
msg = String()
msg.data = "第%d回:%d 次" %(self.count, self.count)
self.pub_novel.publish(msg) # 让发布者发布消息,话题只存最新发的消息,历史的没有
self.get_logger().info("发布了一个章节的小说,内容是:%s"% msg.data)
self.count += 1
def rec_money_callback(self, money):
self.account += money.data
self.get_logger().info("收到%d的稿费,现在账户有:%s的钱 "% (money.data, self.account))
def main(args=None):
rclpy.init(args=args)
li4_node = WriterNode("li4")
# li4_node.get_logger().info("aaaaaaaaaaaa")
rclpy.spin(li4_node) # 让节点一直处于活跃状态
rclpy.shutdown() # 终止节点的运行
4、修改setup.py :
'console_scripts': [
"li4_node=village_li.li4:main"
],
5、到 town_ws 目录下:
colcon build
source install/setup.bash
ros2 run village_li li4_node
accelerate多卡训练:
accelerate config
accelerate launch --num_processes=2 train_ins_ipa_inpainting_facemodel_blip.py
overleaf插入公式:
\begin{align}
公式
\end{align}
overleaf 常用符号:https://www.cnblogs.com/Uriel-w/p/17038327.html
算FID:
pip install pytorch-fid
python -m pytorch_fid path/to/dataset1 path/to/dataset2
du -sh:查看当前目录总大小
df -h:查看磁盘空间情况
git push -f origin main:test:将<本地分支名>main 的代码推送到<远程主机名>origin 上的 test 分支上,-f 是强制覆盖
git branch来查看本地都有哪些分支
.gitignore文件的作用就是在git add时将我们指定的一些文件自动排除在外,不提交到git当中
ssh 无密码登录:
cd ~/.ssh ssh-keygen ssh-copy-id -i id_rsa.pub -p 端口号 root@36.133.182.81 ssh-add -K id_rsa
关闭所有warning:
import warnings warnings.filterwarnings("ignore")
git remote add origin https://github.com/tanzhouxing/medical_gen_pku.git:将 远程主机名 命名为 origin
查看gpu版本,总显存大小,可用显存大小:nvidia-smi --query-gpu=name,memory.total,memory.free --format=csv,noheader
如果要引入同一个包(里面要有__init__.py文件)下的另一个文件,前面加个。就不用写import .了:
import sys,os
sys.path.append(os.getcwd())
设置pycharm在cuda1上调试:environment里面加入CUDA_VISIBLE_DEVICES=1;
直接指定显卡运行:CUDA_VISIBLE_DEVICES=0 python xxx.py
本地文件加载 :tokenizer = BertTokenizer.from_pretrained("/yinxr/ldp/bert-base-uncased")
tmux上翻信息:ctrl+b,【,然后按上键
清空没用的cuda缓存:
if torch.cuda.is_available():
torch.cuda.empty_cache()
for i in itertools.chain(x,y): 遍历x和y里面的所有东西
lr调度方案有:linear,cosine,cosine_with_restarts, polynomial,constant,constant_with_warmup,除了constant 其他都需要warmup,warmup内,lr都是从0线性增加到base_lr
constant :学习率始终等于传入的optimizer的 lr(不变)
CONSTANT_WITH_WARMUP:warmupstep内,lr从0线性增加到base_lr,训练的step>warmupstep,lr恒等于base_lr
linear:当训练的step<=warmupstep,lr从0线性增加到base_lr(optimizer里面的lr),当warmupstep<训练的step<=num_training_steps,lr从base_lr线性降低到0,当训练的step>num_training_steps,lr恒等于0
COSINE:warmupstep内,lr从0线性增加到base_lr,然后在num_training_steps内按照cos曲线降低到0
polynomial:warmupstep内,lr从0线性增加到base_lr,然后在num_training_steps内按照polynomial曲线降低到 指定的 lr_end
OmegaConf.load(".yaml"):将 yaml文件读为字典
字典.pop(key,"123"):返回字典[key],并删除该字典的key,如果找不到key,则返回123
torch.hub.download_url_to_file(url,path):把url的东西下载到path
像素重组:无损的上采样,通道变小,长宽变大,(C*r*r)*W*H---->C*(H*r)*(W*r)
bn = gr.Button("Greet") :一个名字是“greet”的按钮
bn.click(fn=greet, inputs=name, outputs=output):将inputs=name传给函数fn=greet,fn的输出给outputs
from pathlib import Path
for x in Path(路径).iterdir():迭代器,指定路径下的所有一级的文件和文件夹 x.is_file():x是不是文件
tokenizer.add_special_tokens({'additional_special_tokens':["<e>"]}):告诉分词器有个新的字词叫<e>,看到以后不要再细分了
tensor.fill_(2):用2自身覆盖,shape不变
model.train():启用 batch normalization 和 dropout
for name,param in model.named_parameters(): #只是冻住该model的更新,不会影响到其他 model 的更新
param.requires_grad = False
deepseed 作用就是小机器加载大模型,不过时间慢了,原理是GPU显存不够,CPU内存来凑用于加速训练,即:将当前时刻,训练模型用不到的参数,缓存到CPU中,等到要用到了,再从CPU挪到GPU。这里的“参数”,不仅指的是模型参数,还指optimizer、梯度等
pytorch_lightning 就是把模型训练代码解耦了而已
os.scandir(path):当前一级目录下所有文件夹和文件
f.is_dir() :判断是否是文件夹
os.chdir("/var/www/html" ) : 切换到 "/var/www/html" 目录
os.getcwd() # 当前目录
clip_grad_norm_(params_to_optimize, max_norm=5, norm_type=2) # 梯度裁剪,要把它放到optimizer.step()前面,max_norm越小,对梯度爆炸的解决越狠
strftime("%m-%d_%H_%M_%S", gmtime()):显示当前月份-号-时分秒,比如:04-28_03_25_01
释放所有显卡的进程命令:fuser -v /dev/nvidia* -k
释放第0块显卡的进程命令:fuser -v /dev/nvidia0 -k
torch.tile(input, (2,2)):对input,第0个维度上重复2次,第1个维度上重复2次
Path对象.with_stem("asd"):替换文件名,如a/b.jpg->a/asd.jpg
assert 条件 , '提示语':若不满足条件,报错信息是提示语,然后终止程序
image_dataset = ImageDataset(args)
image_dataloader = torch.utils.data.DataLoader(image_dataset, batch_size=batch_size,collate_fn=fn)
for batch in image_dataloader :
for的过程:先去 ImageDataset 调用__getitem__分别拿出batch_size个样本来,然后放到一起给 fn 函数,fn 负责处理这batch_size个样本
tmux安装:
sudo apt-get update
sudo apt-get install libevent-dev
sudo apt-get install tmux
读取parquet文件(可以直接存储字节类型,不用像json文件那样转换)为dataframe:ScienceQA_test_ori = pd.read_parquet('test_2017_sample.parquet', engine='pyarrow')
保存为parquet文件:
hadoop fs -put a multi_modal/test :上传a文件到multi_modal/下
hadoop fs -mkdir multi_modal/tmp_dir:新建目录
hadoop fs -cp multi_modal/test multi_modal/tmp_dir :复制到目录
hadoop fs -rm 文件:删除文件
win:alt+a 固定区域截屏
torch.as_tensor(a):把a转成 tensor
写入csv文件:
import os
import pandas as pd
path = 'temp.csv'
# 一次写入2行
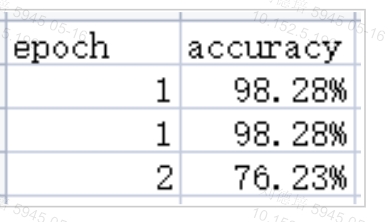
df = pd.DataFrame(data=[['1', '98.2789%'], ['2', '76.2345%']])
# 解决追加模式写的表头重复问题
if not os.path.exists(path):
df.to_csv(path, header=['epoch', 'accuracy'], index=False, mode='a')
else: # 追加下一行写
df.to_csv(path, header=False, index=False, mode='a')
调用openai接口:
openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=messages).choices[0].message.content:得到open的回复
解压zip:jar xf m.zip
将a,b,c文件压缩为m.zip:jar cf m.zip a b c
bash a.sh a b c :$@就是所有参数:a b c
百度网盘命令行下载:
pip install bypy
python -m bypy info:复制链接到浏览器,登录后拷贝码到命令行
把百度网盘要下载的东西挪到:我的应用数据-bypy
python -m bypy downdir 网盘文件夹 目标路径
python -m bypy downfile 网盘文件 目标路径
擅长conda环境:conda remove -n 需要删除的环境名 --all
gdown 命令能下载google文件
pip install gdown
gdown 'https://drive.google.com/uc?id=1H73TfV5gQ9ot7slSed_l-lim9X7pMRiU'
带有.z0x的解压:zip -s 0 FFHQ.zip --out FFHQ-full.zip && unzip FFHQ-full.zip
hugging face上下载指定文件,如一个ckpt文件
from huggingface_hub import hf_hub_download filename = "v1-5-pruned.ckpt" repo_id = "runwayml/stable-diffusion-v1-5" while True: try: path = hf_hub_download(repo_type="model", repo_id=repo_id, filename=filename) except Exception as e: print(e, "retrying") continue break print('finish:',path)
下载某个文件夹下的东西:
from huggingface_hub import hf_hub_download files = ['config.json','diffusion_pytorch_model.fp16.safetensors','diffusion_pytorch_model.safetensors','model.onnx', 'model.onnx_data','openvino_model.bin','openvino_model.xml'] dir = "unet" repo_id = "stabilityai/stable-diffusion-xl-base-1.0" for file in files: while True: try: path = hf_hub_download(repo_type="model", repo_id=repo_id, filename=dir + '/' + file,cache_dir='/root/data/t2i/sdxl' + '/' + dir) # cache_dir 指定下载的位置 except Exception as e: print(e, "retrying") continue break print('finish:',path)
同时下载多个文件:
import torch from diffusers import StableDiffusionPipeline while True: try: pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", revision="fp16", torch_dtype=torch.float16,cache_dir='/root/data/t2i/sdv15') print('ok') break except Exception as e: print(e) continue
下载hugging face的数据集:
from datasets import load_dataset import datasets while True: try: config = datasets.DownloadConfig(resume_download=True, max_retries=100) dataset = datasets.load_dataset( "lambdalabs/pokemon-blip-captions", cache_dir='pokemon-blip-captions', download_config=config) print('ok') break except Exception as e: print(e) continue
pipeline 保存为 diffusers格式
pipeline.save_pretrained('./model', safe_serialization=False) # 在 文件夹model下 转成 diffusers格式 pipeline.save_pretrained(dump_path, safe_serialization=True) # 在 文件夹model下 转成 diffusers格式,其中diffusers格式中的bin文件都转为safetensors格式
安装dlib:conda install -c conda-forge dlib
lsof -i:5174: 查找用了5174端口号的进程
模型只会更新优化器内部的参数,其他可训练参数在进行反向传播时依旧进行求导,只不更新
sd 加载预训练lora,其中lora下要有 pytorch_lora_weights.bin : pipe.unet.load_attn_procs(lorapath)
pipe.unet.load_attn_procs(lorapath) # sd 加载预训练 lora

 浙公网安备 33010602011771号
浙公网安备 33010602011771号