

spss

汉字选项一般用数字代替
选项录入:

下面每行一个被试,s41,s42,...s45是一个多选题的5个选项。
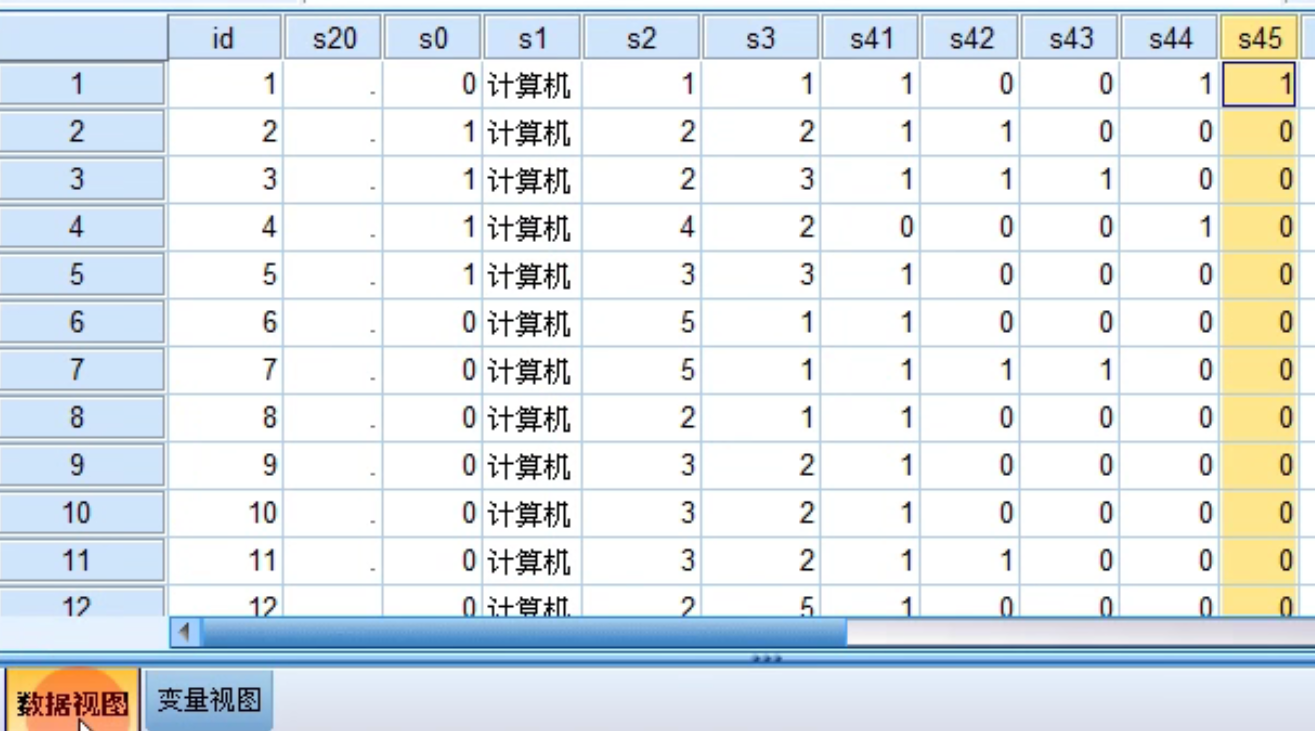
下面每一行一个变量,一个单选题一个变量,所有选项在值那,如果是多选,每个选项一个变量,值是0或者1

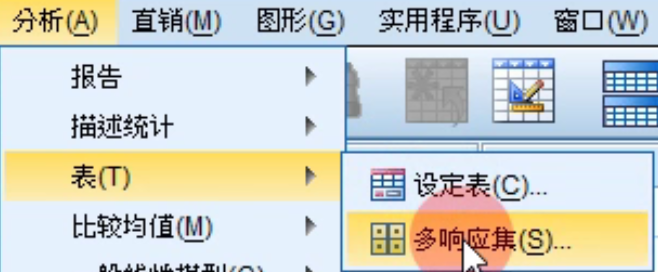
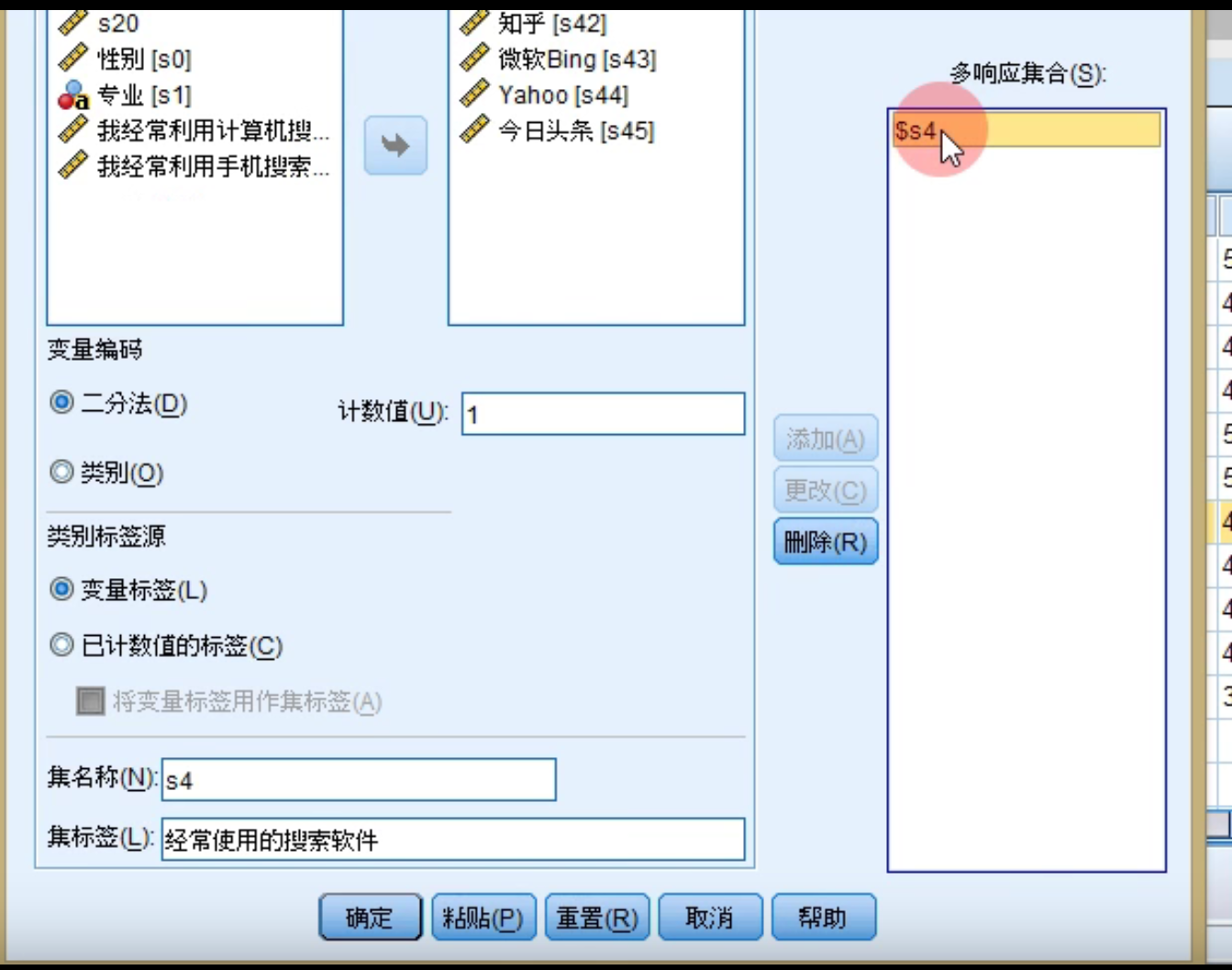
再给多选题设置多响应集,就能进行多选题的分析:
数据个案case就是一个样本
排序:数据-排序个案,单个变量可以直接右键
数据拆分不会打乱原有数据,只会在统计分析之后分组显示结果:
数据-拆分文件,选择一个变量,比较组(各组的结果在一个表)/按组组织输出(各组分别输出),然后开始统计,分析-描述统计-统计
筛选数据:数据-选择个案,筛选器变量=1时,表示符合条件
合并数据:
数据-合并文件-添加个案:多个文件的个案会直接加到后面,不会合并,使用与id不同的文件数据集
数据-合并文件-添加变量:不仅能增加个案, 还能扩充变量,注意把不能重复的变量设置为关键变量,适用于:2个文件里面只有1列 id 是一样的,第二个文件可以有多余的变量

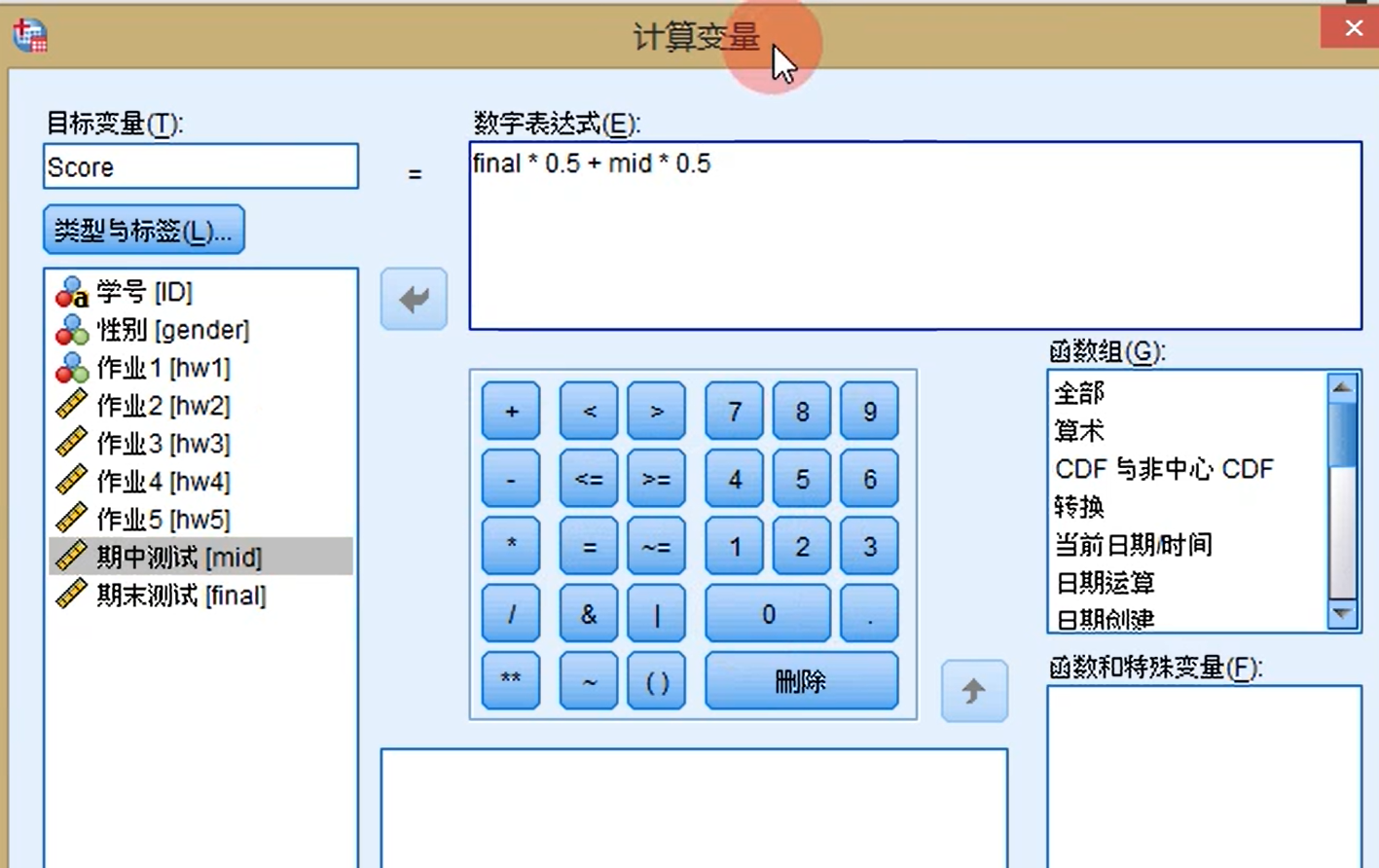
根据多个变量计算一个新增变量:转换-计算变量,目标变量自定义
转换-重新编码为不同变量:根据某个变量的值生成新变量,如成绩在0-60是及格...
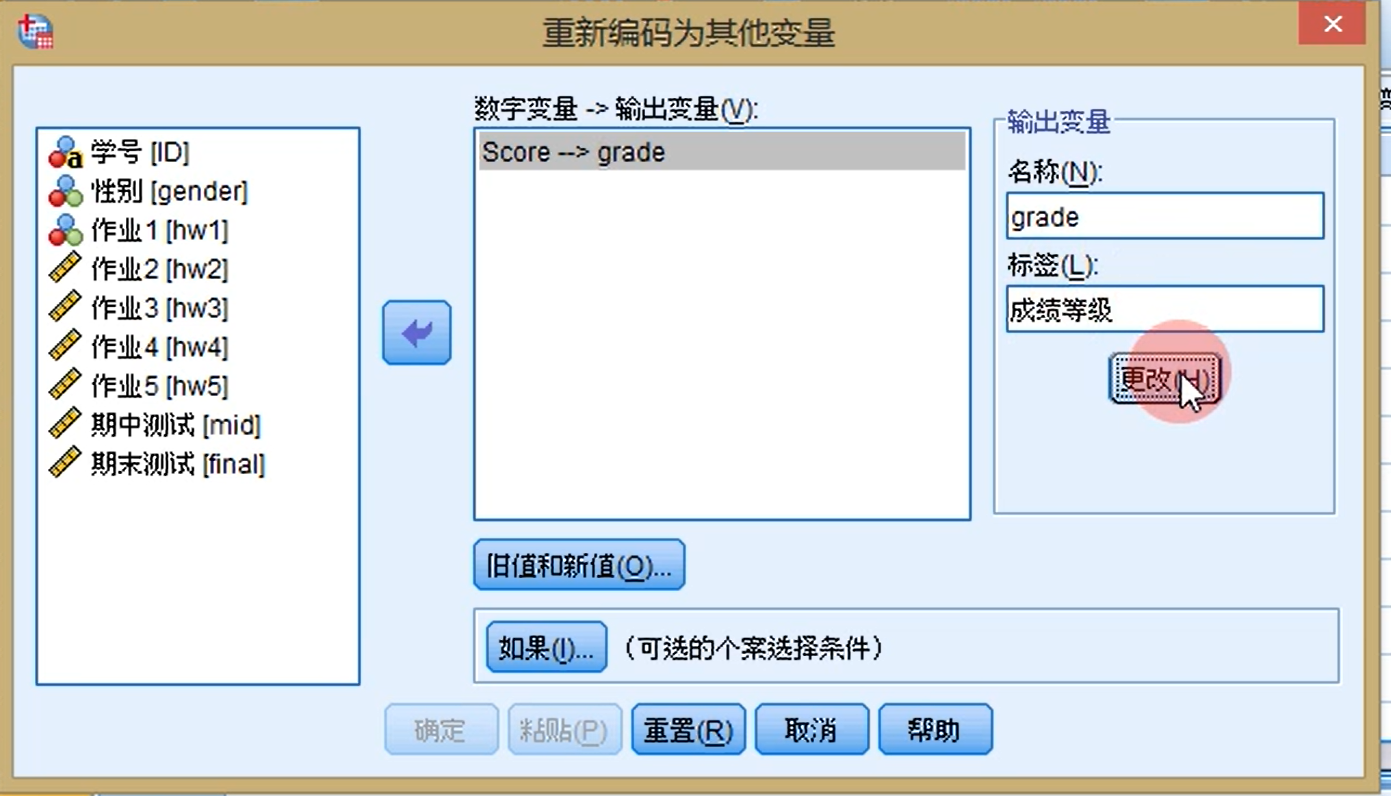

多个页面显示:窗口-拆分窗口
每一行就是一个个案,快速定位到第几行或者第几个变量:

统计平均数、标准差等属于描述统计,t检验属于推论性统计

分析-描述统计-频率:
valid:30,有30个有效数据,25%的个案的分数<82分(百分位数),..

第二行:72分有2人,占6.7%,得到72分的和70分的人共占比10%(累计)

方差和标准差:

偏度:
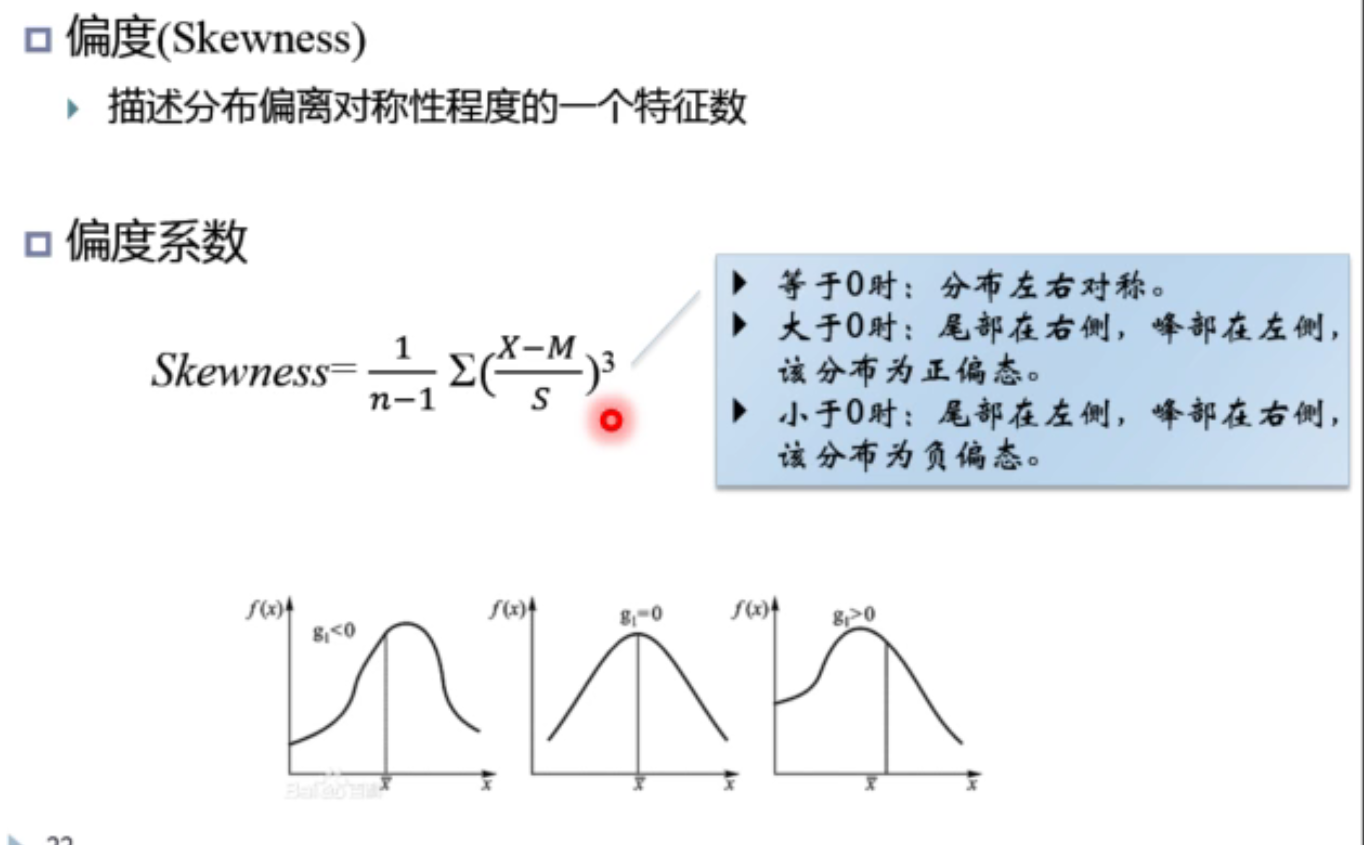
峰度:
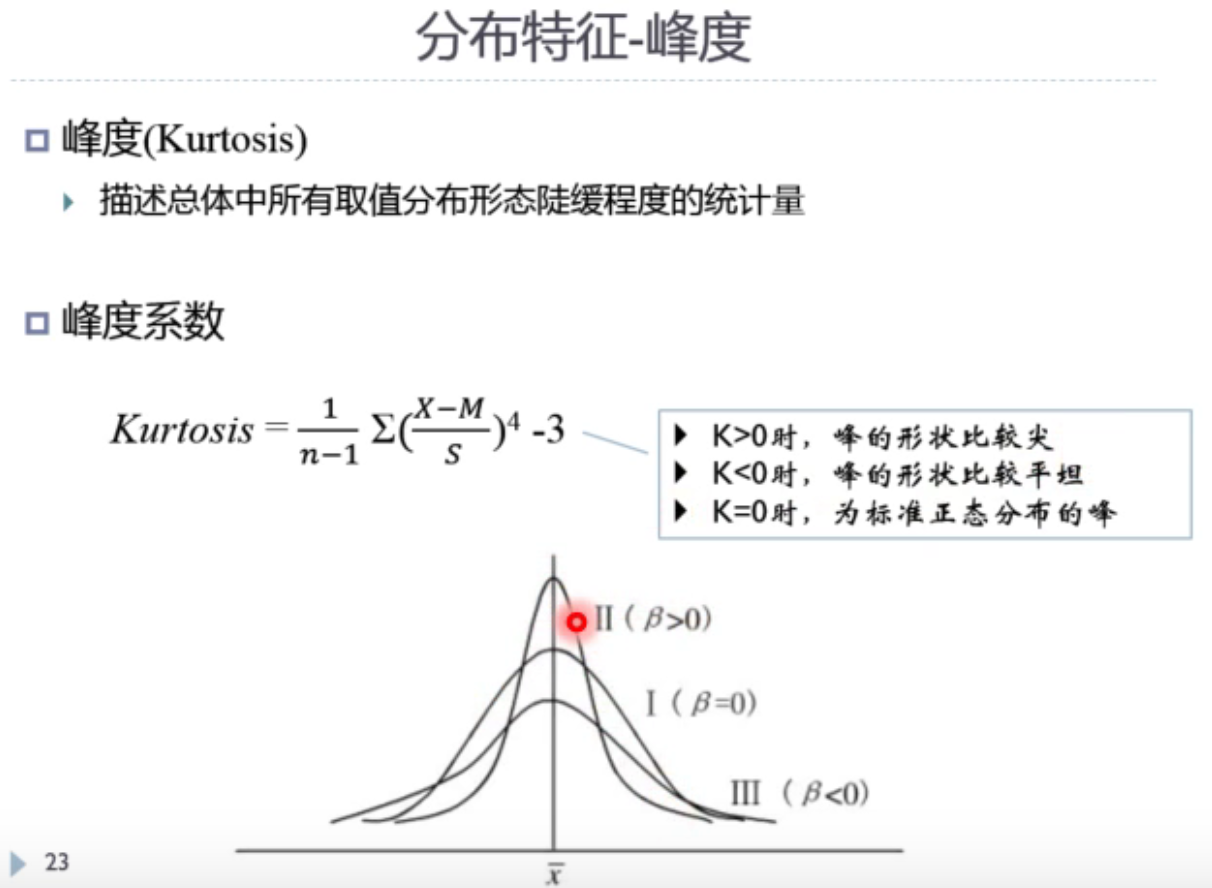
分析-描述统计-描述,再点击选项,可以显示以上数据,如果勾选:将标准化得分另存为变量(z),那会生成Z分数(x-均值)/ 标准差(z分数无单位)
分析 - 描述 - 探索,会列出统计描述:
因变量列表是要分析的变量,因子列表是按组输出,标注个案是用哪个变量的值来做标记,没有的话就是用行号,勾选待检验的正态图可以画出如下,p值看sig,<0.05则不符合正态分布,反之:

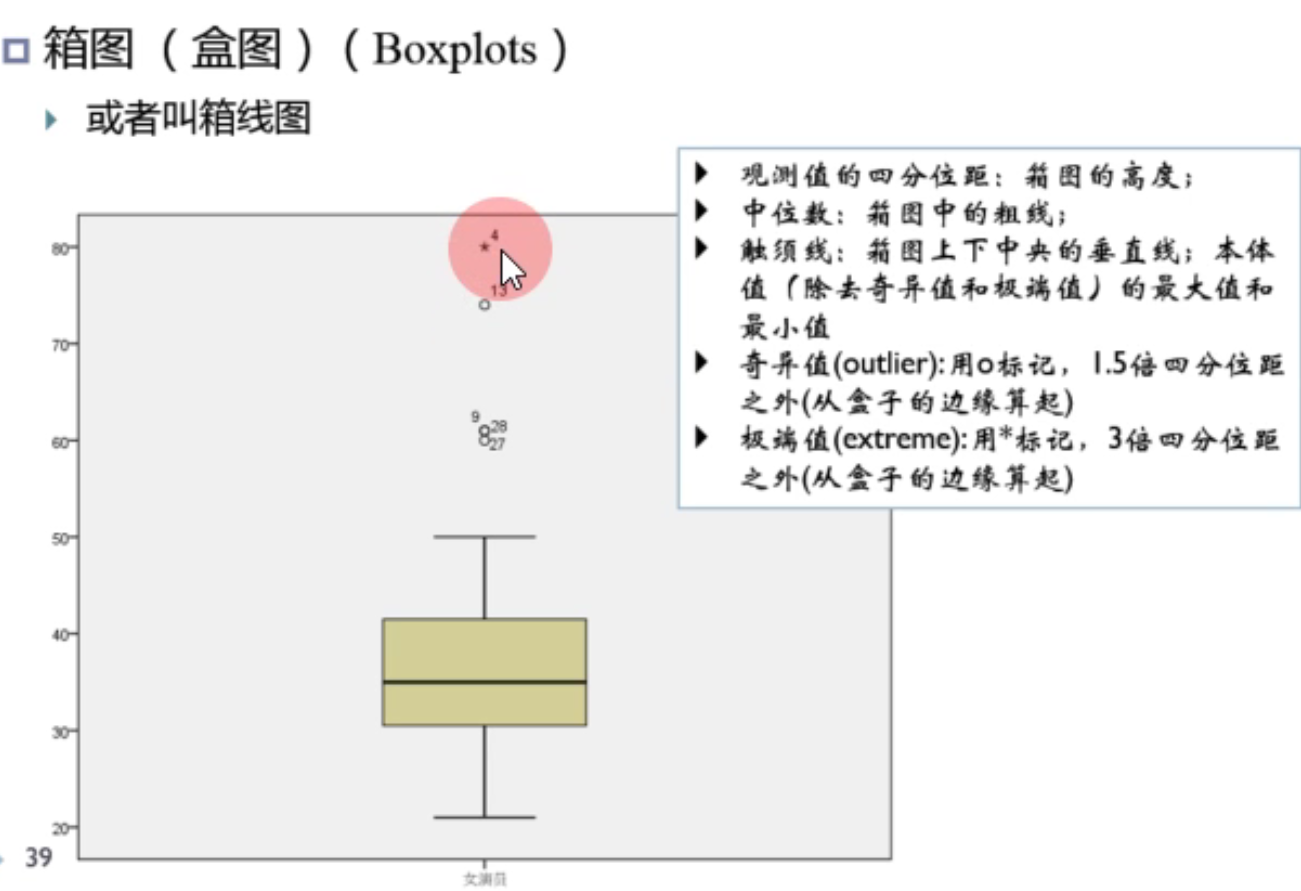
盒图:
中间的粗线是中位数,天线表示剔除了极端值的最大值和最小值
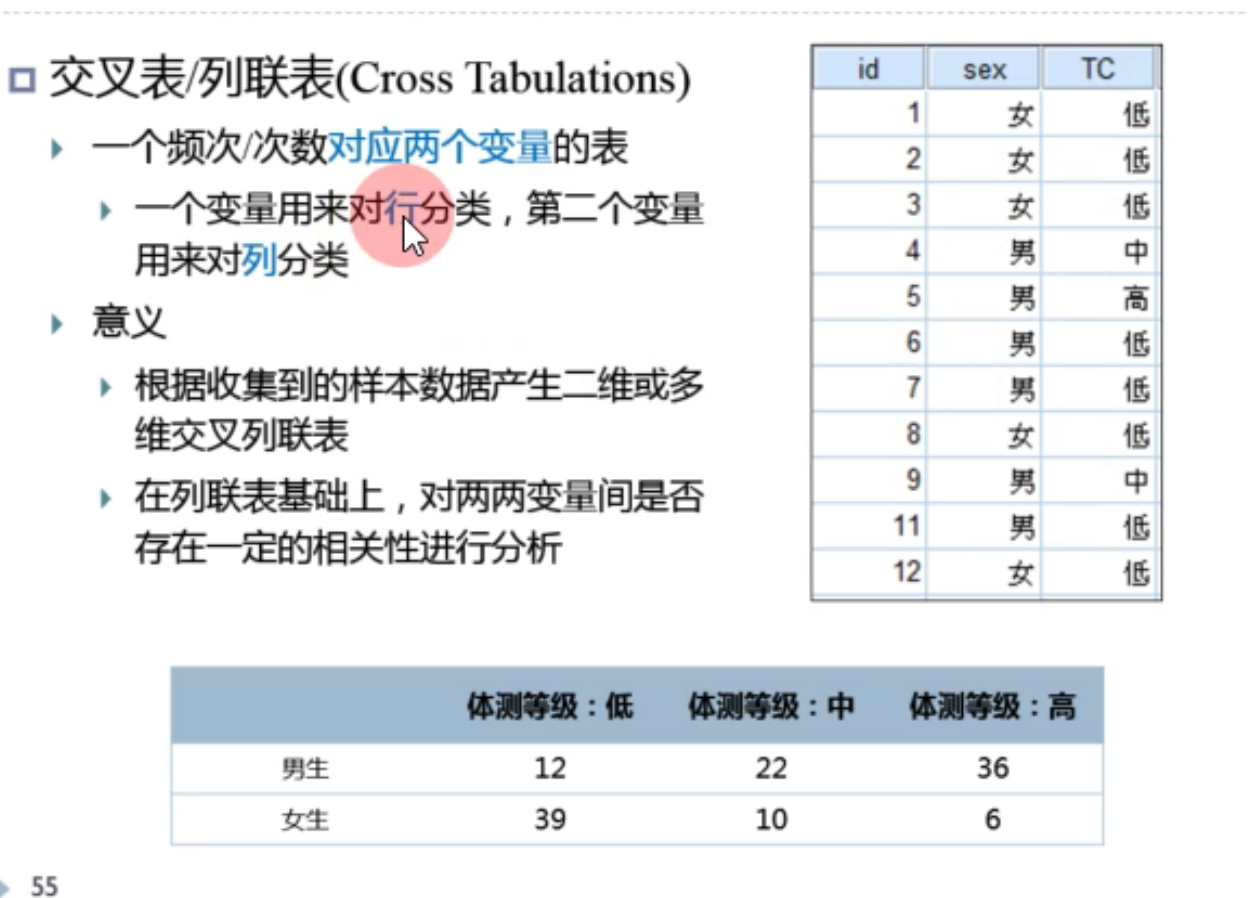
交叉表能统计出女低多少人,女中多少人...
分析-描述统计-交叉表:

通过散点图看看是不是线性关系:图形-旧对话框-散点
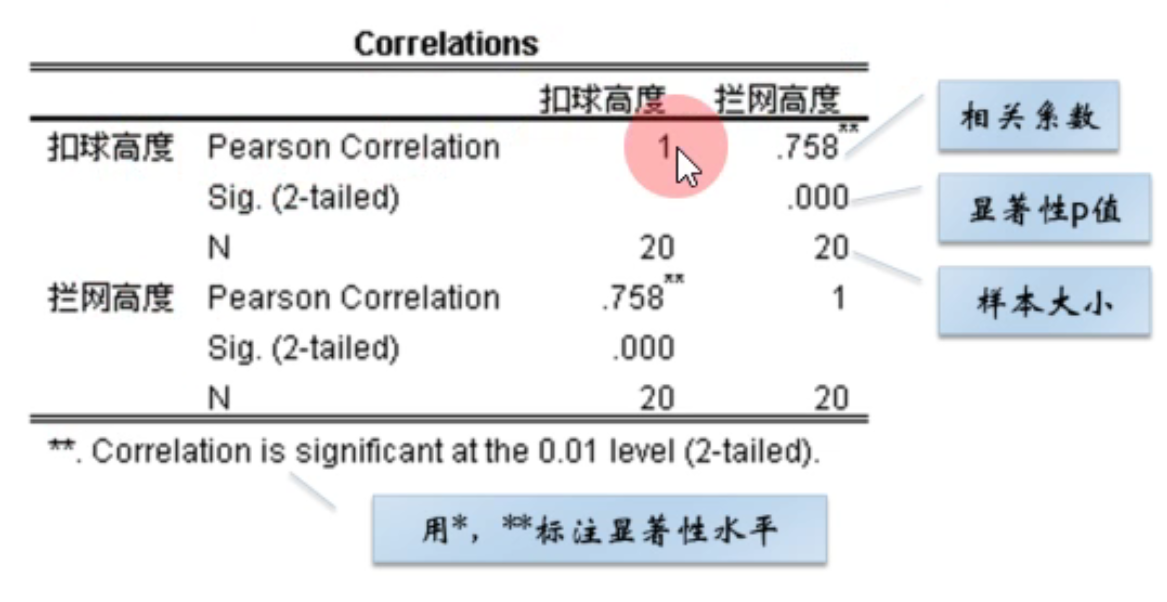
计算相关系数:分析-相关-双变量,选项里面还能呈现出描述性统计
一个星号显著,2个星号更更显著

下图的p(显著性值)越小越显著
P<0.05 相关系数 R=0.279:显著的不相关
P>0.05 相关系数R=0.799:相关但不显著,可能有偶然因素
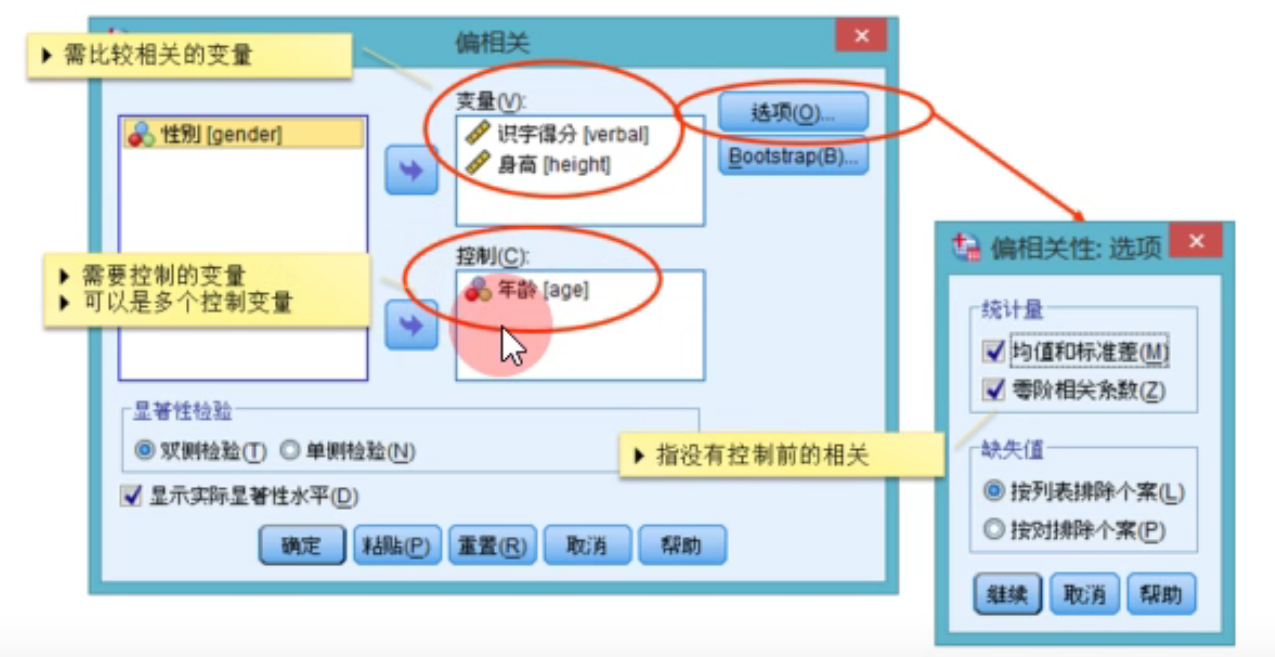
偏相关控制第三个变量:

偏相关系数是控制第三个变量的影响(如年龄),单独研究两个变量的相关系数 ,比相关系数更准确
分析-相关-偏相关:
上面是没有控制第三变量的相关系数,下面是控制了的偏相关系数

单样本t检验:一个样本和总体均值比较,看样本和总体均值是否有差异
分析-比较均值-单样本t检验,均值是总体的均值
如果sig<显著性水平,拒绝原假设,即样本和总体均值有差异
独立/相关样本t检验:比较2个独立/相关样本,看2个总体均值是否一致
分析-比较均值-独立样本t检验:
下面比较两个城市的通勤时间,样本1是a城市的通勤时间,样本2是b城市的通勤时间,现在把所有通勤时间放到一起了,第二列变量是对应的城市
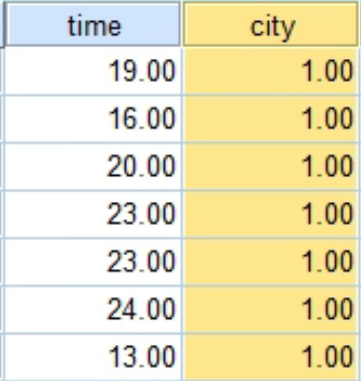

如果第一个sig>0.05,则说明2个总体方差相等(方差齐性),就看第一行;否则看第二行
是否拒绝看第二个sig(p值),若<0.05,则拒绝H0,认为有显著差异

相关样本 t 检验:
分析-比较均值-成对样本t检验,然后把两列变量(如吃饭前,吃饭后)放到成对变量里面,结果看最后的sig

 浙公网安备 33010602011771号
浙公网安备 33010602011771号