


集成学习
集成学习:结合多个学习器
集成学习的学习器:基学习器
异质集成:基学习器使用的算法不同;同质:算法相同
决策树的非叶节点是判断条件,叶子结点是结果
SVM=支持向量机属于监督学习(数据带标签),用于二分类
泛化能力:适应新数据的能力
多样性:基学习器之间的差异性
理想的情况下,集成学习的基学习器相互独立相互补充
正则化:损失函数加正则项,为了防止过拟合
基学习器的多样性有正则化作用,避免过拟合
启发式算法是基于经验构造的算法,如蚁群算法,模拟退火,神经网络
度量多样性的方法:相关系数、Q 统计、Kappa统计、信息熵
弱学习机:预测能力仅仅强于随机猜测;强学习机预测能力高于弱学习机
根据个体学习器的不同,集成学习方法大致可分为两大类:
1.即个体学习器间存在强依赖关系,必须串行生成的序列化方法,如Boosting
2.个体学习器间不存在强依赖关系、可同时生成的并行化方法,如Bagging和“随机森林”。
Boosting有:AdaBoost(Adaptive Boosting)、GBM(Gradient Boosting Machine)、XGBoost
AdaBoost:
例子:
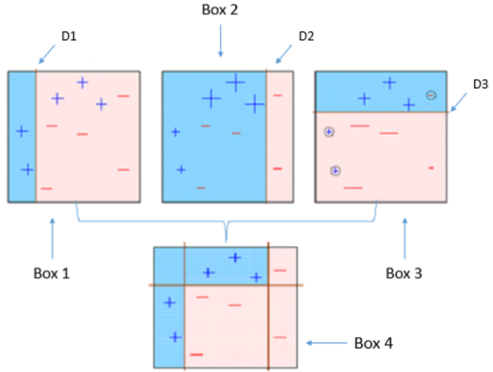
下面这张图对Ada-boost做了恰当的解释:
- Box 1: 你可以看到我们假设所有的数据点有相同的权重(正号、负号的大小都一样),并用一个决策树桩D1将它们分为两部分。我们可以看到这个决策树桩将其中的三个正号标记的数据点分类错误,因此我们将这三个点赋予更大的权重交由下一个预测树桩进行分类。
- Box 2: 在这里你可以看到三个未被正确分类的(+)号的点的权重变大。在这种情况下,第二个决策树桩D2试图将这三个错误的点准确的分类,但是这又引起新的分类错误,将三个(-)号标记的点识别错误,因此在下一次分类中,这三个(-)号标记的点被赋予更大的权重。
- Box 3: 在这里三个被错误分类的(-)号标记的点被赋予更大的权重,利用决策树桩D3进行新的分类,这时候又产生了新的分类错误,图中用小圆圈圈起来的一个负号点和两个正号点
- Box 4: 在这里,我们将D1、D2和D3三个决策器组合起来形成一个复杂的规则,你可以看到这个组合后的决策器比它们任何一个弱分类器表现的都足够好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号