
量化
股市开始交易:开盘;
建仓:进入市场;
平仓:退出市场
外汇(交易)市场:forex,市场中有2种头寸=开盘,分为商业净头寸(包括央行的外汇储备、企业的进出口贸易、个人留学旅游等进行的外汇交易)和非商业净头寸(投机和套利)
如果人民币值钱了,则能把人民币兑换更多的外币
如果一段时间中国没有印钱,而经济又发展了,那么人民币就值钱了
黄金:黄金多了,它就不值钱了;钱多了,金就值钱了
套现:指利用不同市场中同一种产品价格之间的差别获利
大多数股票的面值均为每股一元;发行价格就是买股票的价格
每股净资产 =(总资产-总负债)/ 总股数,它越高,表示股东拥有的每股资产价值越多
股票按照业绩分类:蓝筹股(资本雄厚、信誉优良的公司的股票,如中石油、中石化)、绩优股(业绩优良的公司股票,如茅台)、ST股(特别处理股票,连续2年亏损或者每股净资产低于股票面值)
股票按照上市地区分类:
涨跌幅10%:一天的价格变动不能超过10%
T+1:T是交割日,今天买了,明天才能卖
T+3:当天买入的股票,3天后才能卖,比如第一天买入股票100股,第二天又买入100股,虽然已经有200股股票,但到三天后只能卖出100股,第四天才能卖出所有股票.

证监会:决定公司能否上市,若上市了不符合规定,还能撤下来;
证券中介机构:只有在证券交易所里面有席位才能去买股票,证券中介机构是有席位的,买不了席位的股民只能通过证券中介机构的席位才能买到股票
交易所:每个板有对应的大盘,即指数,能反应该板块所有股票的综合表现,在上证则为沪指

市值 = 发行股票的总价值 = 每股市场价格 * 总股数,小公司一般小市值
没人买了就跌,有人买就涨
竞价:买方和卖方进行对接
开盘集合竞价:系统以成交量最大为原则将一定数量的买方和卖方撮合,然后确定开盘价
连续竞价时间内很快就能完成交易
收盘集合竞价:.....确定收盘价
股票交易时间:

K线可以观察每日价格变动,每个柱子代表该日的价格,柱子分为阳线(涨了,即低开高走:开盘价<收盘价)和阴线:
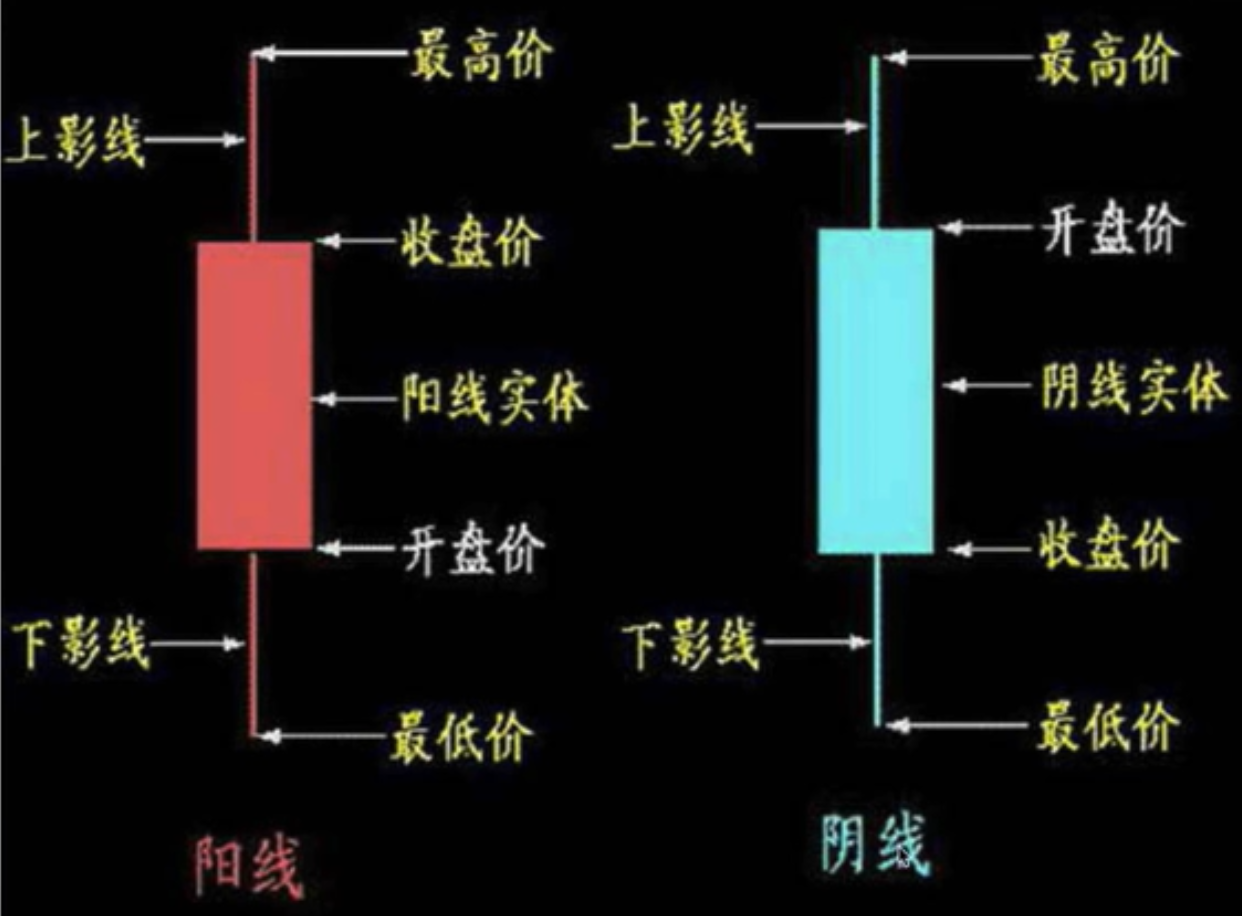
5日均线:取前5日的价格做平均值,所连成的线
基本面分析和技术分析:

回测:用历史的数据来测试策略
ipython
ipython中 ,查找含有pp的命令:a.*pp*?
查看a的信息:a?
快捷键:

!后面表示是一条命令
运行文件:%run a.py
%paste:粘贴代码并执行它
random.randint(参数1,参数2):参数1<=函数返回参数1和参数2之间的任意整数<=参数2
range(10) :产生10个数, [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
range(1, 11) : [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
列表解析第一个是函数表达式,它作用于后面的每个元素上:
例1:a=[x for x in range(101) if x%2==0]
等价于<=>
a=[] for i in range(101): if i%2==0: a.append(i)例2:
L = [ i**2 for i in range(1,11)] print L [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
创建100个从1-10000的随机数: li=[random.randint(1,10000) for i in range(100)]
sort排序后会作用到自己,计算排序时间:%timeit li.sort();
开启调整,如果接下来的命令出错,就进入到调试模式,用exit退出:%pdb on
关闭调试:%pdb off
执行1+1后,执行_则输出上面计算的结果2
可以输入首字母再按上下键来获得历史命令
把结尾的目录赋值给a:%bookmark a ~
列出所有保存过的目录:%bookmark -l
删除保存下来的a:%bookmark -d a
删除所有保存的:%bookmark -r
numpy:
list a为每件商品的单价,list b为对应商品的件数,根据他俩求商品总价:
将两个list转成ndarray格式,然后对应元素相乘,最后求总和:( np.array(list a) * np.array(list b) ).sum()
.dtype:ndarray数据类型
数组总的元素个数:.size
数组维度:.shape
下面三维数组维度是2页2行3列(2,2,3)

转置:a.T
有多少维:a.ndim
[2]*3 = [2,2,2]
np.zeros(10):10个0,且数据类型为float64
np.zeros(10,dtype='int'):10个0,且数据类型为int
np.ones(10):10个1
创建有5个位置的空数组,里面的数是其他程序留给内存的:np.empty(5)
np.arange(10):产生10个数,从0到9
x=np.arange(2,9):2-8
x**2:是里面的每一个数做平方
np.arange(2,10,3):3是步长,[2,5,8],步长还能是小数
np.linspace(0,100,101):起始值是0,结束值是100,包括结束值的,给区间切割101份,这样就是0,1,2...,100,也是101个数
np.eye(10):10*10的单位矩阵
将1维数组转换成3*5矩阵:.reshape((3,5))
a[0,0]:取第0行第0列
a[:4]:取前4个元素,索引为0,1,2,3
a[4:]:索引从4开始(包括)到结尾
b=list(range(10)):b是list类型
数组的切片内容更改后,影响原数组,除非切片.copy(),但是列表的切片并不影响
把数组a里面>5的元素取出来:a[a>5]
取>5且是偶数,或用 | :a[ (a>5) & (a%2==0) ]
取出ndarray中第0和第2号索引位置的元素:a[[0,2]]
假定取 [6,8;16,18]:

则:
a[ [1,3],:] 是取出第一和第三行,再取出第一和第三列 [ :, [1,3] ]

每个元素取绝对值:np.abs(a)
每个取根号:np.sqrt(a)
向零取整:np.trunc(a)
四舍五入与正负无关:np.round(a)
向下取整:np.floor(a)
向上取整:np.ceil(a)
将每个元素的整数和小数分开,变成2个元素: np.modf(a)
不是数,如负数开根号: nan :float("nan")
无穷大:float("inf")
np.isnan(a):a中不是nan的都是false,否则是true;np.isinf 同理
将数组a和数组b的每一个元素对应相比较,保留大的:np.maximum(a,b),类似np.minimum(a,b)
数组每个元素加起来:a.sum()
平均:a.mean()
方差=每个数据与平均值差的平方的和再除以元素个数:a.var()
标准差=方差开根号:a.std()
若是服从正态分布的数据,则抽出一堆数据后,均值+标准差表示数据的68.27%大约都分布在在这个区间
a.argmax():最大值索引;a.argmin():最小值索引
random.random():返回 [ 0,1 )
random.choice( [1,2,3] ):从给定数组中随便取一个值出来
random.shuffle(a):随机打乱数组a
random.randint(0,10,(2,3)):生成2*3的矩阵,每个元素都是随机数;类似random.choice( [1,2,3] ,10)
np.random.uniform(0, 2,10):生成10个随机数,每个数在 [0,2] 内
pandas:
Series对象:

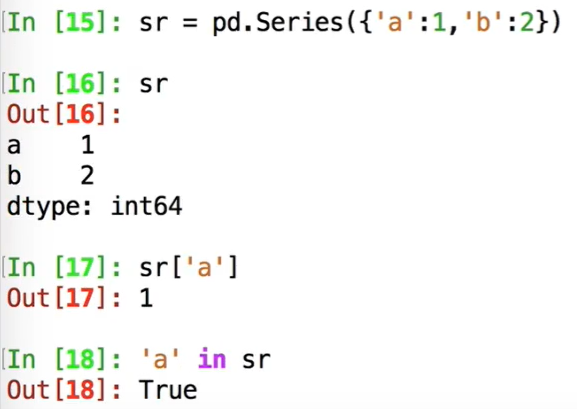
a=pd.Series([11,12,13],index=["a","b","c"])
访问:a[0] 或者 a["b"]
字典:
获得索引和值:

切片:

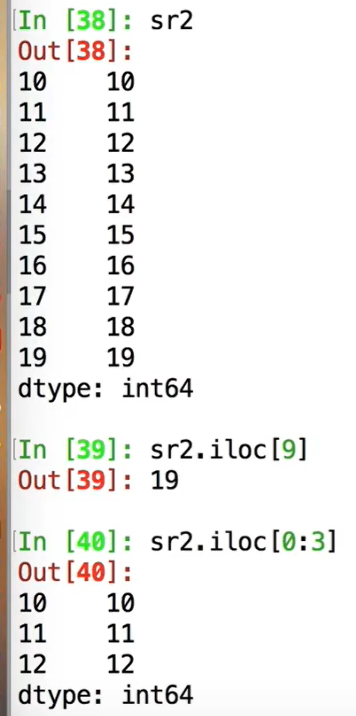
为防止歧义:loc 明确表明使用的是key,iloc表示索引: sr.loc[]
按照标签对应相加:

此处的NaN表示数据缺失值
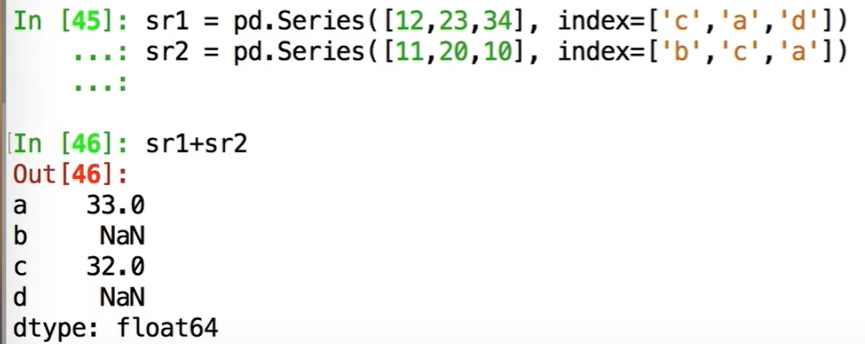
使用add则缺失的值默认为0:
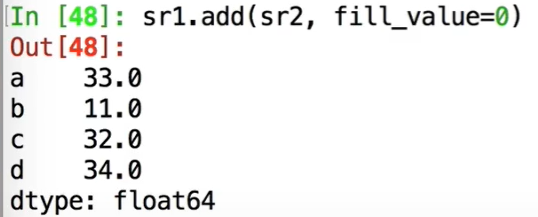
处理缺失值(识别NaN)isNull和notnull:

dropna删掉所有缺失值:

sr.fillna(0):将所有nan替换成0,注意这些函数都不是修改自身,若改动自身则再赋值
DataFrame
一列是一个类型,它的切片是包含首尾的
DataFrame的创建、索引命名:


返回dataframe索引和值:

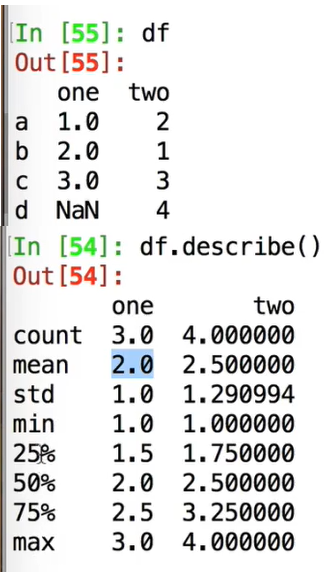
describe()分别统计每一列的信息:
count:该列非NaN的个数
25%:排序好后,第25%的数
50%:中间的数
用loc获取某个位置的值:

取某一列df["one"],取2列df[["one","two"]],取出第a行:df.loc["a"],取出第0行:df.iloc[0], 取出第one列,再取出第0行df['one'][0],取出第one列的倒数2个数df['one'][-2:],如果不想要前面的索引,则最后.values
对齐相加,NaN相加还是NaN:

df.dropna():若有1行里有NaN,则整行删掉
df.dropna(how='all'):只有一行里面全是NaN才删掉该行
df.dropna(axis=1):删除含有NaN的列
df.mean()默认是按照列求平均数,除非指定axis;.sum()类似,只有此处DataFrame默认是按照列进行的,其他函数都是默认按行
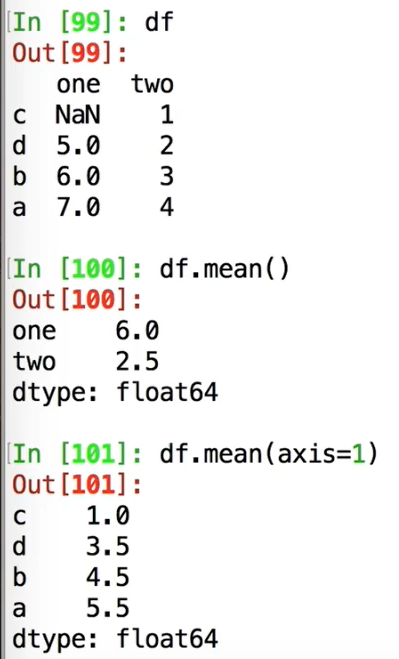
sort_values用by指定按照什么来排序,ascending是降序,不管升降,有NaN的行都排在最后面:

按照行索引排序:
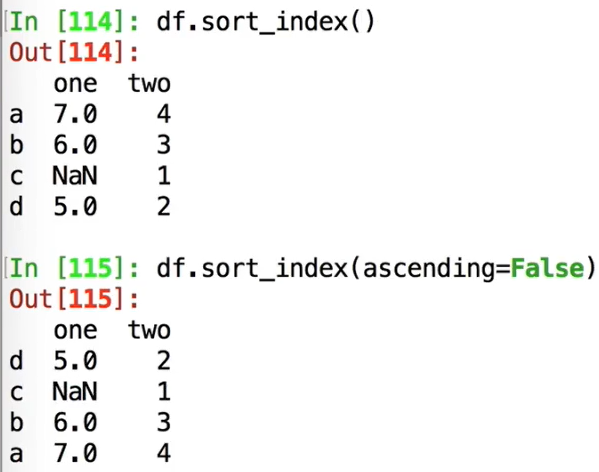
按照列索引降序排序:

dateutil格式化时间:


pd.to_datetime批量转换日期:

pd.date_range生成指定时间范围内的时间,以及指定天数来生成时间:
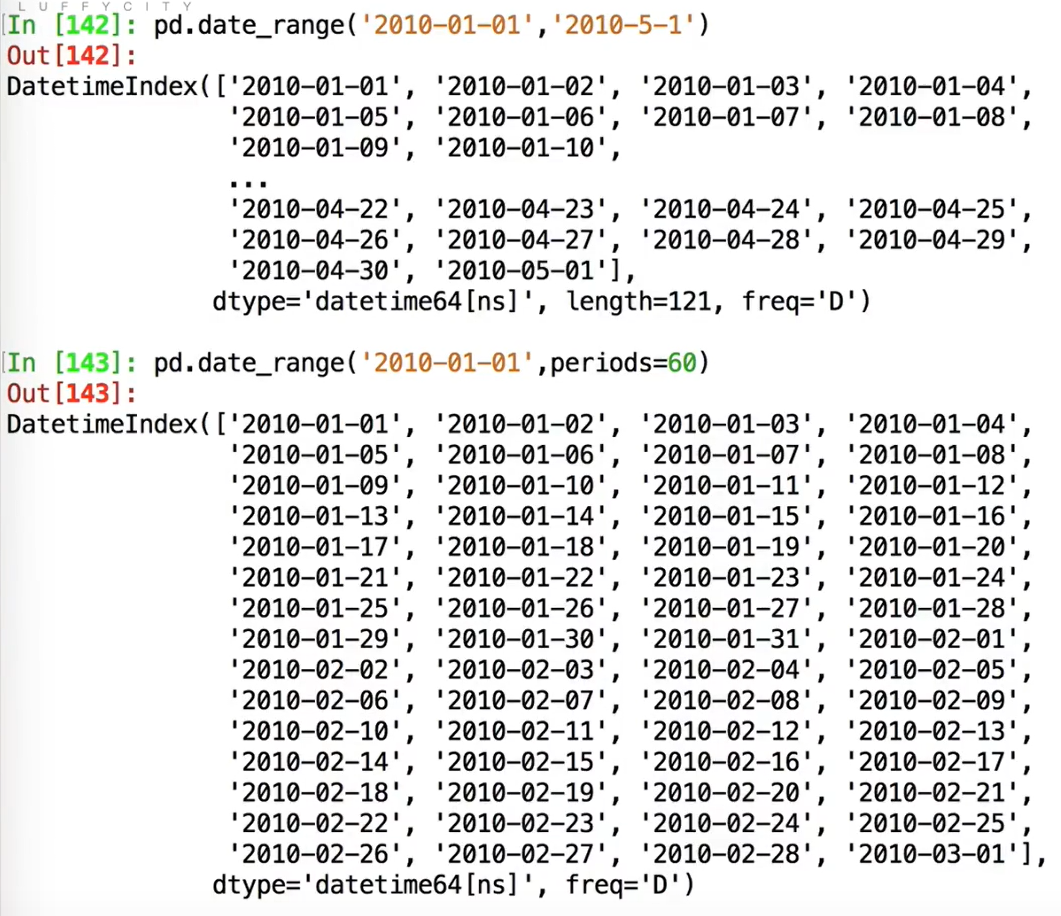
若指定freq='H',按照小时列出;freq='W':按照周日输出;frep='W-MON':按照周一输出;freq='B':按照工作日周一-周五输出
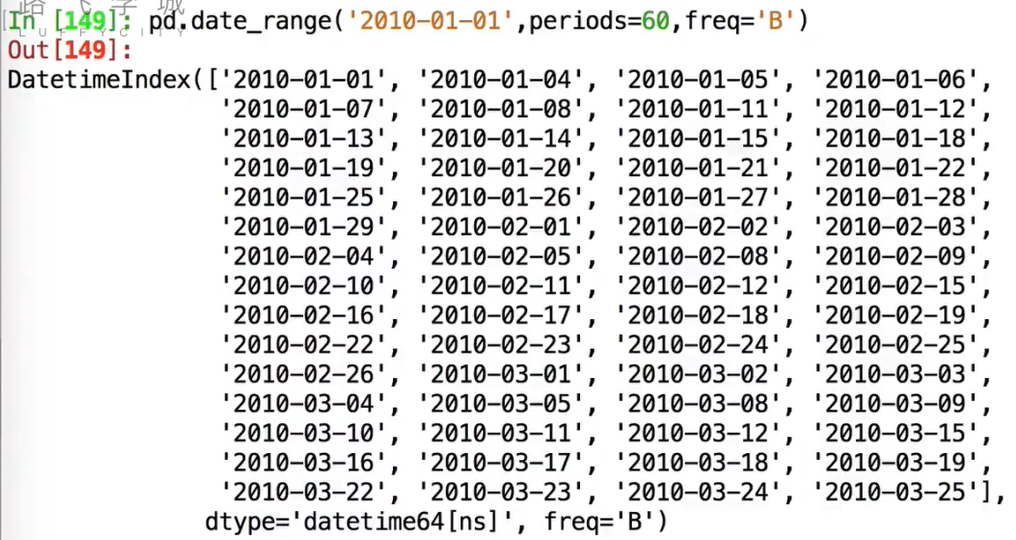
还能:
![]()
dateTimeindex可以拿来做series和dataframe的索引:
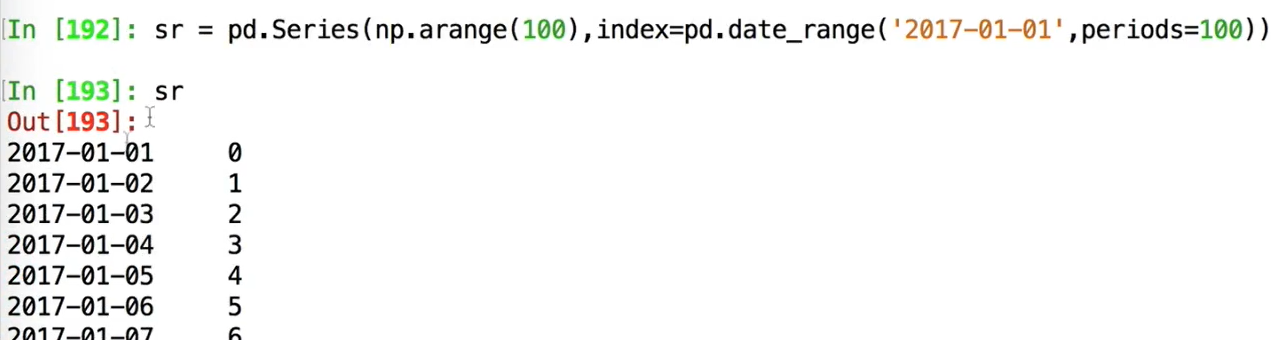
仅仅选取3月的数据:sr['2017-03'];
取出一段时间的:sr['2017':'2018-03']
按每周列,把每周内的数据加起来 sr.resample['W'].sum(),左列的日期是一周开始的日子
按照每月:

取平均:sr.resample['W'].mean()
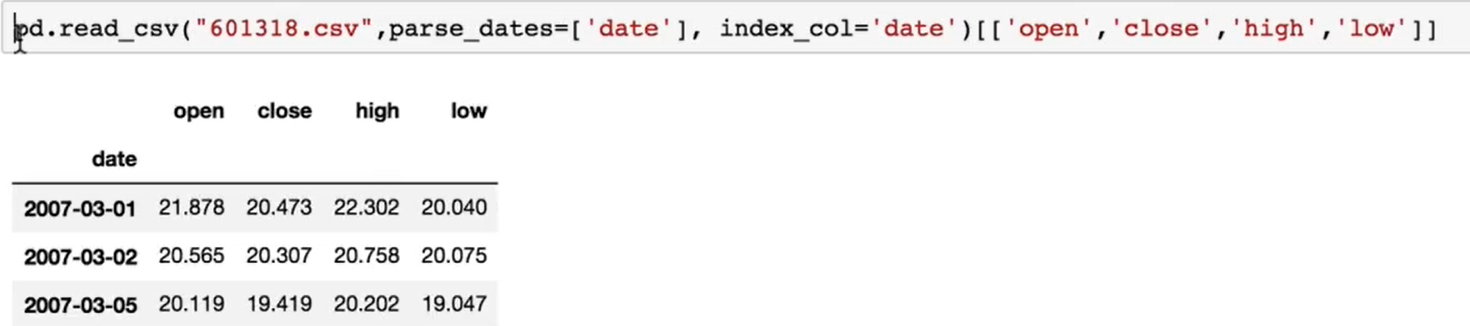
读csv文件:pd.read_csv('aaa.csv')
以第0列作为索引(把第0列放到开头一列):

以日期作为索引:

parse_dates把日期列定为时间对象,这样索引就是DateTimeindex了:

指定文件无列名:

指定列名:

把原数据中的所有none字符串替换为NaN:

读取excel文件:pd.read_excel('a.xlsx')
将dataFrame写入到文件中:to_csv
header=False:列名不写了
index=Flase:索引列不写了
na_rep='null':把df中的NaN替换为null
columns指定写入哪些列
df.to_csv('a.csv',header=False,index=False,na_rep='ASD',columns=['tow'])
转成html和json:

matplotlib
一般:import matplotlib.pyplot as plt
pl.plot:画折现图,第三个参数是描的点
o:是点
o-:线

只要不调用show,就会累积的画图

调用legend时,需要plot里面有label参数,才能分开显示

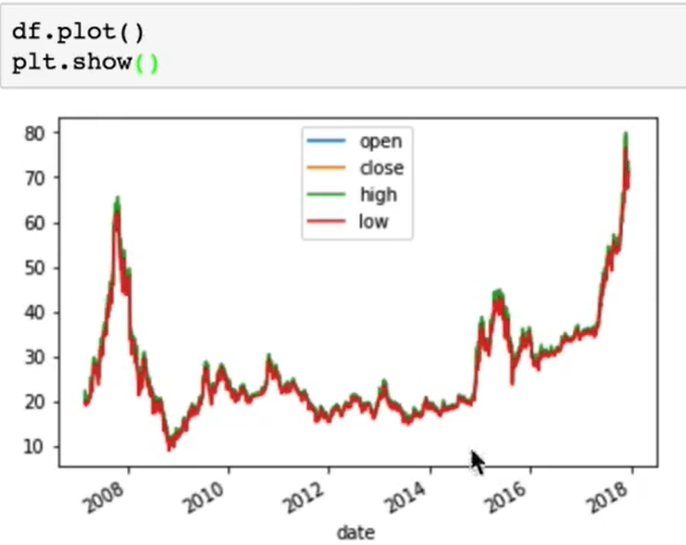
画出csv来:
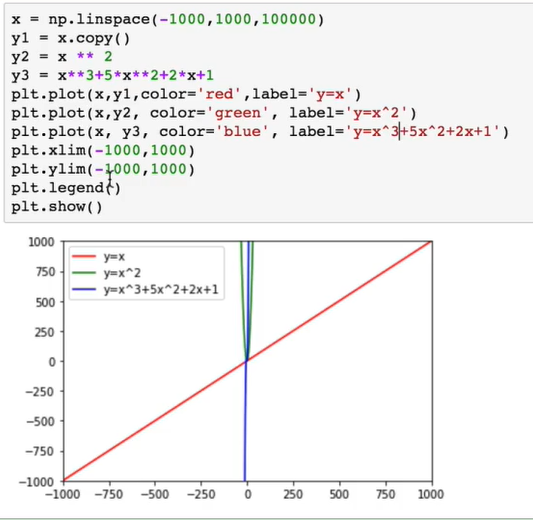
画数学函数:

画子图:

bar第一个参数是横坐标,第二个参数是高度,width控制柱子宽度
xticks:在哪些刻度上写标签
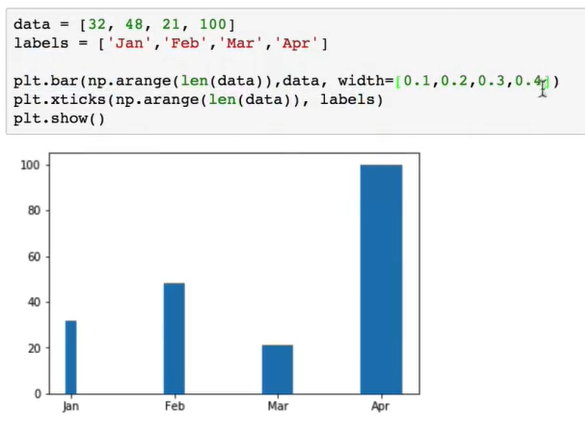
柄图:
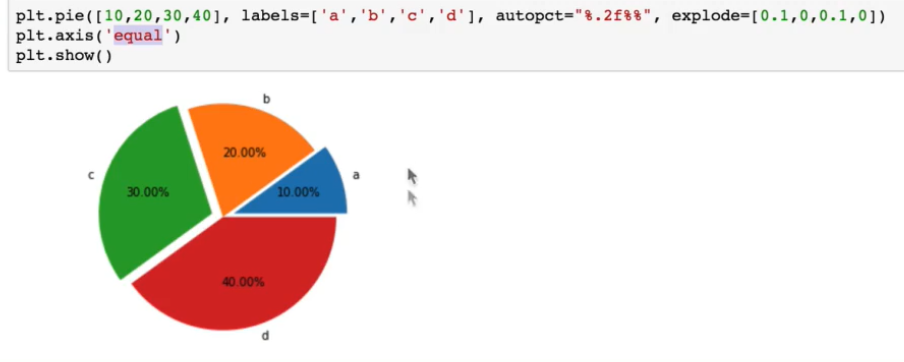
%.2f%%:f是转为附点数,.2是小数点后保留2位,最后的%%加到后面,explode是分离扇形
axis是把扇形画正
先把日期转换为python时间:
import matplotlib.finance as fin
ochl是open、close...的简称,按照顺序传进去

fig.show()
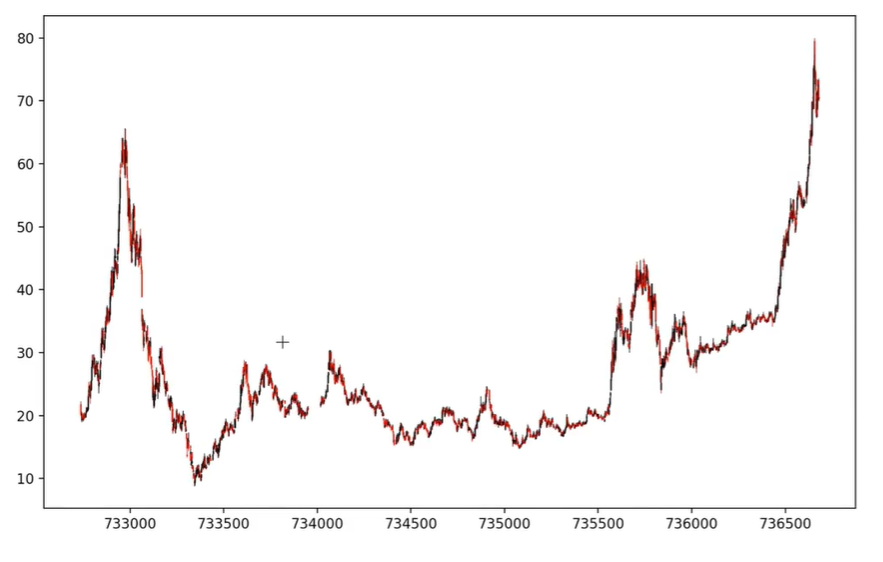
为了加快速度。可以使用切片:
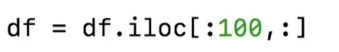
tushare 获取股票数据
import tushare as ts
输入的是证券代码:ts.get_k_data('601318')
ktype能画出日k线、周k线(开盘价是一周第一天的开盘价,收盘价是一周最后一天的收盘价)、月k线
还制定起始时间:
ts.get_k_data('601318',start='1988-01-01')
df["close"].shift(1):将dataframe的close一列向下挪动一行,-1是向上挪动
量化:
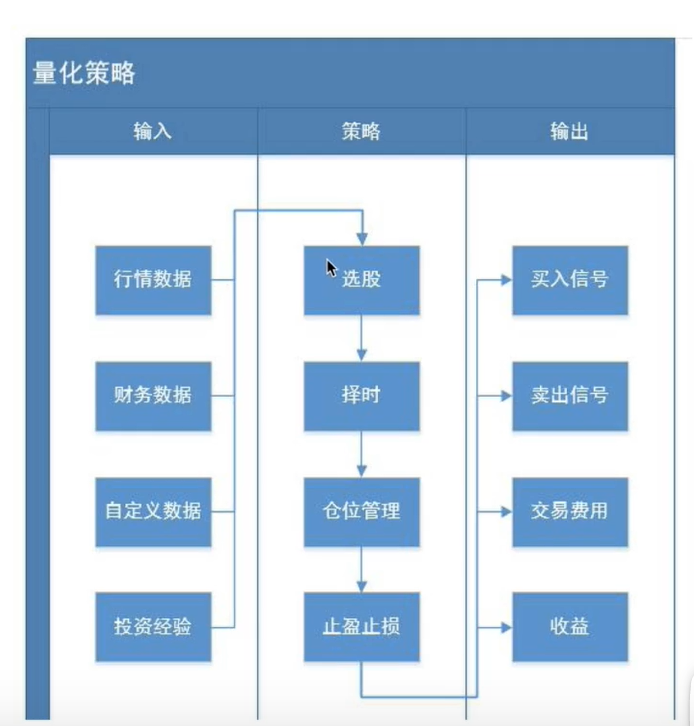
作业1:
买卖股票按照开盘价计算

答案在:homework1
MA5:5日均线;MA10:10日均线,5日和10日的叫日均线,30和60日的叫季均线,120天和240天的叫年均线,时间短的叫短期均线,时间长的叫长期均线
双均线策略:金叉:短期均线上穿长期均线的那个交叉点,之后股票可能大涨,则买入股票;死叉:....下穿.....,之后股票可能跌,则卖了
作业2:
提示:
for i in range(a,len(l)) :索引从 a 到 l 的结尾(包括)
if不需要括号,且用and
.index得到的是时间戳,to_pydatetime()能将时间戳进行转换
Series的索引若是时间,则sort_index()升序排列
每100股100股的买,一手买100股
最后的钱要加上还没卖完的股票的价值

答案在:homework2
作业3:
提示:
不持仓:表示没有该股票
在joinquant中
红线是基准线(第一天拿所有的钱平均买该大盘里面的300成分股,然后也不卖,之后的涨跌情况),蓝线是自己写的策略线,纵坐标是获益百分比,0表示没有获益没有亏损
策略收益和基准收益是到截止日期时,获益的情况 =(最后的钱-开始的钱)/ 开始的钱,年化收益就是一年的获益率,胜率是赚的交易次数 / 总的交易次数,盈亏比=赚的钱 / 亏损的钱,最大回撤:可能面临的最大亏损,从任一高点到其后续最低点的下跌幅度的最大值,对应的回撤区间就是最大亏损幅度区间
保存什么东西就放到g的属性中;.XSHG是该股票在上海上市
get_index_stocks('000002.XSHG')能获取旗下所有成分股的代号
set_option('use_real_price',True):使用真实价格成交
买股票要佣金(给券商,让他帮我买),卖股票交佣金和印花税(给国家的)
针对的是股票type='stock',买股票不需要印花税open_tax=0,只需要付佣金万分之三open_commission=0.0003,卖需要千分之一印花税close_tax=0.001+佣金万分之三,每笔交易如果佣金低于5块则按照5块钱算:
set_order_cost(OrderCost(open_tax=0, close_tax=0.001, open_commission=0.0003, close_commission=0.0003, close_today_commission=0, min_commission=5), type='stock')
今日涨停价一般等于昨日收盘价*1.1,跌停价=昨日收盘*0.9
每个工作日(如果下拉框选择是每天)会自动调用handle_data
get_current_data()['601318.xshg']返回该股票数据,是一个字典:

get_current_data()['601318.xshg'].day_open:去当日的股票池里找到该股票601318.xshg,然后返回该股票当日开盘价
attribute_history('601318.XSHG',5):返回该股票当日前5天(不包括当日)的历史数据
order('601318.XSHG',100):当日买100份股
买股票必须以100股的倍数,卖没事
order_value('601318.XSHG',1000):当日用1000块买这个股票,能买多少买多少,但是100的倍数
order_target('601318.XSHG',200):买到200股,若第二个参数=0,则表示全部卖出
order_target_value(‘代码’,1000):买股票买到值1000块为止
position对象中的avg_cost表示买该股票1份平均花了多少钱,total_amount是总仓位,即买了该股票总共多少股,仓位就是多少股
点击回测会显示更多详细信息

答案:
## 初始化函数,设定要操作的股票、基准等等 def initialize(context): set_benchmark('000300.XSHG') g.security = get_index_stocks("000300.XSHG") set_option('use_real_price', True) set_order_cost(OrderCost(open_tax=0, close_tax=0.001, open_commission=0.0003, close_commission=0.0003, close_today_commission=0, min_commission=5), type='stock') def handle_data(context,data): buy=[] # 先卖股票 for stock in g.security: p = get_current_data()[stock].day_open histp = context.portfolio.positions[stock].avg_cost amount = context.portfolio.positions[stock].total_amount if p>=histp*1.25 and amount>0: order_target(stock,0) if p<=histp*0.9 and amount>0: order_target(stock,0) if p<10 and amount==0: buy.append(stock) dividemoney = context.portfolio.available_cash / len(buy) for stock in buy: order_value(stock,dividemoney)
双均线属于择时
双均线作业:
record能多画几个图

## 初始化函数,设定要操作的股票、基准等等 def initialize(context): set_benchmark('000300.XSHG') g.security = ["601318.XSHG"] set_option('use_real_price', True) set_order_cost(OrderCost(open_tax=0, close_tax=0.001, open_commission=0.0003, close_commission=0.0003, close_today_commission=0, min_commission=5), type='stock') g.p1=5 g.p2=10 def handle_data(context,data): df = attribute_history('000300.XSHG',g.p2) ma5 = df['close'][-5:].mean() ma10 = df['close'].mean() for stock in g.security: if ma5 < ma10 and stock in context.portfolio.positions: order_target(stock,0) if ma5 > ma10 and stock not in context.portfolio.positions: order_value(stock,context.portfolio.available_cash*0.8) record(ma5=ma5,ma10=ma10)
因子选股策略
因子:选股的标准、如增长率、市值、市盈率、ROE(净资产收益率)
调仓:调整一下股票的种类和数目
以小市值策略为例:每个月调仓,使得所持有的股票一直是市值最小的那几份
a = query(valuation).filter(valuation.code.in_(g.security):由于valuation里面有市值数据,就到valuation表中查询包含有g.security里面股票的sql,g.security保存了一堆股票代码
get_fundamentals(a):获取上面这些股票的财务数据,包括市值股票代码code、市值market_cap等
run_monthly(handle,1):每月的第一个工作日运行handle函数
:n 是前n个
为了不要索引,最后.values:
## 初始化函数,设定要操作的股票、基准等等 def initialize(context): set_benchmark('000002.XSHG') set_option('use_real_price', True) set_order_cost(OrderCost(open_tax=0, close_tax=0.001, open_commission=0.0003, close_commission=0.0003, close_today_commission=0, min_commission=5), type='stock') g.security = get_index_stocks('000002.XSHG') g.sql = query(valuation).filter(valuation.code.in_(g.security)) g.num = 20 run_monthly(handle,1) def handle(context): tobuy = get_fundamentals(g.sql)[["code","market_cap"]].sort("market_cap")["code"][:g.num].values for stock in context.portfolio.positions: if stock not in tobuy: order_target(stock,0) newbuy = [stock for stock in tobuy if stock not in context.portfolio.positions] if len(newbuy)>0: divide = context.portfolio.available_cash / len(newbuy) for stock in newbuy: order_value(stock,divide)
标准化能去掉量纲:

假定选2个因子为:roe,市值,想要高的roe,低的市值,要将2者用min-max标准化,然后用roe-市值得到一个综合因子,用该综合因子筛选。
roe在indicator表中
## 初始化函数,设定要操作的股票、基准等等 def initialize(context): set_benchmark('000002.XSHG') set_option('use_real_price', True) set_order_cost(OrderCost(open_tax=0, close_tax=0.001, open_commission=0.0003, close_commission=0.0003, close_today_commission=0, min_commission=5), type='stock') g.security = get_index_stocks('000002.XSHG') g.sql = query(valuation,indicator).filter(valuation.code.in_(g.security)) g.num = 20 run_monthly(handle,1) def handle(context): l = get_fundamentals(g.sql)[["code","market_cap","roe"]] l["market_cap"] = (l["market_cap"]-l["market_cap"].min())/(l["market_cap"].max()-l["market_cap"].min()) l["roe"] = (l["roe"]-l["roe"].min())/(l["roe"].max()-l["roe"].min()) l["score"] = l["roe"]-l["market_cap"] tobuy =l.sort("score")["code"][-g.num:].values for stock in context.portfolio.positions: if stock not in tobuy: order_target(stock,0) newbuy = [stock for stock in tobuy if stock not in context.portfolio.positions] if len(newbuy)>0: divide = context.portfolio.available_cash / len(newbuy) for stock in newbuy: order_value(stock,divide)
均值回归理论:
当价格下跌离开均线到一定程度(偏离程度)时,它可能就会上涨,此时买;当上涨超过均值一定程度时,他可能会跌,此时卖
可定义偏离程度= (MA-P) / MA,除法能去量纲
series对象.nlargest(3):按照第二列,选择里面最大的3行
此处用该理论来选股:

def initialize(context): set_benchmark('000002.XSHG') set_option('use_real_price', True) set_order_cost(OrderCost(open_tax=0, close_tax=0.001, open_commission=0.0003, close_commission=0.0003, close_today_commission=0, min_commission=5), type='stock') g.security = get_index_stocks('000002.XSHG') g.sql = query(valuation,indicator).filter(valuation.code.in_(g.security)) g.num = 10 g.ma = 30 run_monthly(handle,1) def handle(context): tobuy = pd.Series(index=g.security) for stock in tobuy.index: p = get_current_data()[stock].day_open ma = attribute_history(stock,g.ma)['close'].mean() tobuy[stock] = (ma-p)/ma tobuy = tobuy.nlargest(g.num).index.values for stock in context.portfolio.positions: if stock not in tobuy: order_target(stock,0) newbuy = [stock for stock in tobuy if stock not in context.portfolio.positions] if len(newbuy)>0: divide = context.portfolio.available_cash / len(newbuy) for stock in newbuy: order_value(stock,divide)
或者:
def initialize(context): set_benchmark('000002.XSHG') set_option('use_real_price', True) set_order_cost(OrderCost(open_tax=0, close_tax=0.001, open_commission=0.0003, close_commission=0.0003, close_today_commission=0, min_commission=5), type='stock') g.security = get_index_stocks('000002.XSHG') g.sql = query(valuation,indicator).filter(valuation.code.in_(g.security)) g.num = 10 g.ma = 30 run_monthly(handle,1) def handle(context): tobuy = pd.Series() for stock in g.security: p = get_current_data()[stock].day_open ma = attribute_history(stock,g.ma)['close'].mean() tobuy[stock] = (ma-p)/ma tobuy = tobuy.nlargest(g.num).index.values for stock in context.portfolio.positions: if stock not in tobuy: order_target(stock,0) newbuy = [stock for stock in tobuy if stock not in context.portfolio.positions] if len(newbuy)>0: divide = context.portfolio.available_cash / len(newbuy) for stock in newbuy: order_value(stock,divide)
布林带策略可用于择时:
有3条线,上面是压力线,中间是均线,下面是支撑线,可定义:中间线=20日均线,上线=20日均线+N*SD,SD是标准差,下线= 20日均线-N*SD
当价格超过压力线,则清仓,当价格低于支撑线,则全仓买入
def initialize(context): set_benchmark('600036.XSHG') set_option('use_real_price', True) set_order_cost(OrderCost(open_tax=0, close_tax=0.001, open_commission=0.0003, close_commission=0.0003, close_today_commission=0, min_commission=5), type='stock') g.security = '600036.XSHG' g.n = 2 g.m = 30 def handle_data(context,data): p = get_current_data()[g.security].day_open sr = attribute_history(g.security,g.m)['close'] ma = sr.mean() up = ma + g.n*sr.std() down = ma - g.n*sr.std() if p > up and g.security in context.portfolio.positions: order_target(g.security,0) if p < down and g.security not in context.portfolio.positions: order_value(g.security,context.portfolio.available_cash)
PEG策略选股:
若股票定价合理,则市盈率PE=收益增长率G
市盈率PE=股价P / 每股收益EPS
EPS=总利润 / 总股数
股价 =市值/总股数
所以 市盈率PE = 市值 / 总利润,越被低估,股价越可能涨,则买入

peg越低则买入,且要求分子分母都是正的,负的不行,因为说明在赔钱
思路是:计算所有股票的PEG指标,买入最小的N支股票
市盈率PE在valuation表里面叫pe_ratio,G在indicator里面叫inc_net_profit_year_on_year
筛选df:df[ (条件1) & (条件2) ]
前3个 :3
后三个 -3:
## 初始化函数,设定要操作的股票、基准等等 def initialize(context): set_benchmark('000300.XSHG') set_option('use_real_price', True) set_order_cost(OrderCost(open_tax=0, close_tax=0.001, open_commission=0.0003, close_commission=0.0003, close_today_commission=0, min_commission=5), type='stock') g.security = get_index_stocks('000300.XSHG') g.sql = query(valuation,indicator).filter(valuation.code.in_(g.security)) g.num = 20 run_monthly(handle,1) def handle(context): l = get_fundamentals(g.sql)[["code","pe_ratio","inc_net_profit_year_on_year"]] l = l[ (l['pe_ratio'] > 0) & (l['inc_net_profit_year_on_year']>0) ] l['peg'] = l['pe_ratio'] / l['inc_net_profit_year_on_year'] / 100 tobuy = l.sort('peg')['code'][:g.num].values for stock in context.portfolio.positions: if stock not in tobuy: order_target(stock,0) newbuy = [stock for stock in tobuy if stock not in context.portfolio.positions] if len(newbuy)>0: divide = context.portfolio.available_cash / len(newbuy) for stock in newbuy: order_value(stock,divide)
动量策略和反转策略是相反的:
采用它选股

取出一堆股票的前30天的close列的数据,转置后索引是股票代码,列是时间:
history(30,field = "close",security_list=list(stocks)).T
ascending=False是降序,选最大的收益率是动量策略,最小的反转,此时让ascending=True
## 初始化函数,设定要操作的股票、基准等等 def initialize(context): set_benchmark('000300.XSHG') set_option('use_real_price', True) set_order_cost(OrderCost(open_tax=0, close_tax=0.001, open_commission=0.0003, close_commission=0.0003, close_today_commission=0, min_commission=5), type='stock') g.security = get_index_stocks('000300.XSHG') g.sql = query(valuation,indicator).filter(valuation.code.in_(g.security)) g.num = 10 run_monthly(handle,1) def handle(context): l = history(30,field='close',security_list = g.security).T l['ret'] = (l.iloc[:,-1]-l.iloc[:,0])/l.iloc[:,0] tobuy = l.sort('ret',ascending=False).index[:g.num] for stock in context.portfolio.positions: if stock not in tobuy: order_target(stock,0) newbuy = [stock for stock in tobuy if stock not in context.portfolio.positions] if len(newbuy)>0: divide = context.portfolio.available_cash / len(newbuy) for stock in newbuy: order_value(stock,divide)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号