


hadoop1
hadoop包括:

文件切割后的块里面有偏移量,第3块的偏移量是第1块和第二块的大小合,也等于前一块的偏移量+前一块大小,节点就是服务器。副本数不能太少,否则这几个副本所在的节点资源都用完的话,就不能再有程序访问节点了;只能读

服务器就是台式机,下图有2个机架,每个机架有3个服务器(节点),灰色是副本,dn:datanode,一个文件块至少有3个副本(它们id都一样),就至少要放到3个dn上
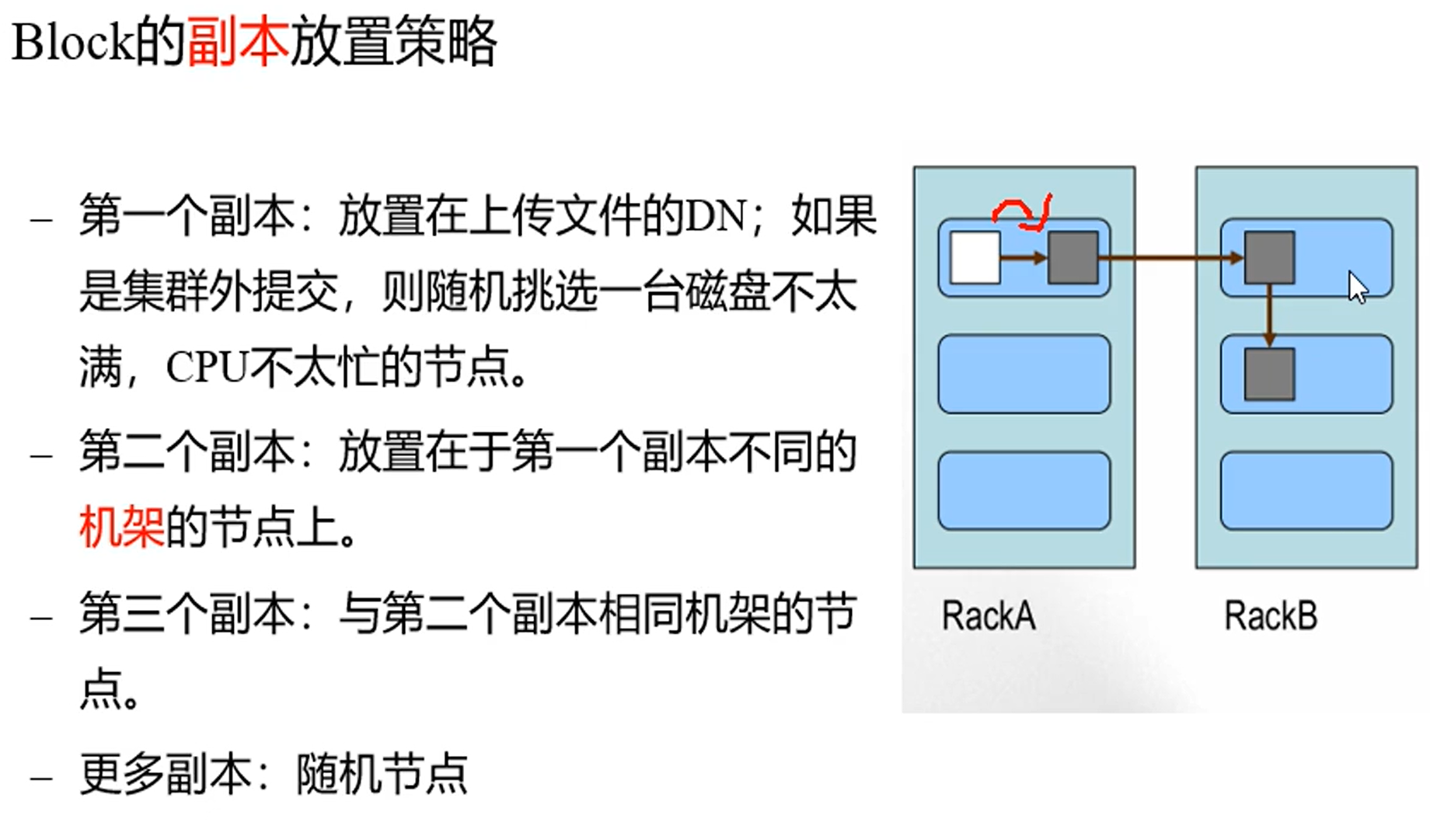
文件包括元数据和数据本身,元数据放到namenode里面,数据放到datanode里面,hsdfclient如果想要存取数据,首先要去namenode里面知道元数据信息,再自己去datanode拿数据。
元数据存在内存,隔一段时间会持久化,fsimage就是元数据到磁盘后的文件(隔一段时间更新),edis保存对元数据的操作(实时更新),snn根据nn的edis去更新nn上的fsimage(合并edis)

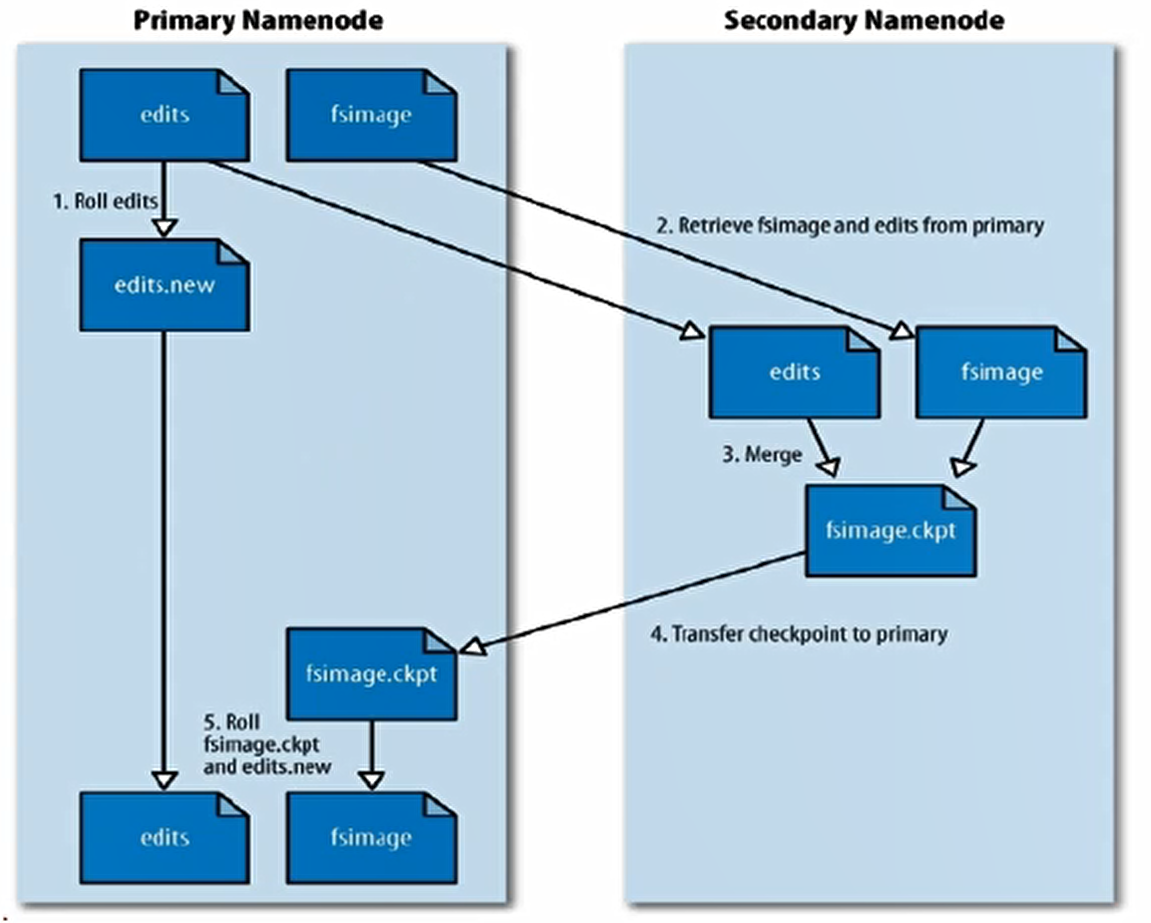
配置如下:其中node2部署了snn和dn,nn和snn都要大量io,不应当放到一个node上;node01运行一个命令启动集群后,需要ssh配置好才能自动启动node3的集群,通过一个机器控制其他机器;

步骤:
配置ip:vi /etc/sysconfig/network-scripts/ifcfg-ens32
重启网络:systemctl restart network
配置好jdk后,永久设置主机名:hostnamectl set-hostname 新主机名(把/etc/hostname文件旧的主机名删除,替换为新的主机名),ip与主机名的映射:vi /etc/hosts

重启网络:systemctl restart network
对node01拍个快照,然后克隆node02,node03,node04,再配置下ip和主机名
node01创建秘钥,此时会生成文件.ssh:ssh-keygen
把公钥拷贝到node01,node02,node03,node04:ssh-copy-id -i ./.ssh/id_rsa.pub root@node01;...2;..3;...4
然后测试登录所有机器:ssh root@node01;ssh root@node02;...
node01中把hadoop3.1.0.tar.gz(这是已经编译好的,无需编译源码)上传,然后tar -xvf had..
将一个没什么用的目录删掉,方便后面复制:rm -rf hadoop-3.1.0/share/doc/
修改:vi etc/hadoop/hadoop-env.sh,(环境变量在/etc/profile)末尾加(gg:光标首行;G:光标末尾):
export JAVA_HOME=/usr/java/jdk1.8.0_161
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
上面表示由root用户来操作namenode,dn,snn节点
配置nn:vi etc/hadoop/core-site.xml:
fs.defaultFS表示namenode,即nn在node01上,hadoop.tmp.dir表示把元数据和数据块放到/home/hadoop_data
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9820</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop_data</value>
</property>
</configuration>
告诉它snn在node02上:vi etc/hadoop/hdfs-site.xml:
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node02:9868</value>
</property>
</configuration>
配置dn在node02.node03,node04:vi etc/hadoop/workers
node02
node03
node04
将hadoop目录拷贝到node02,node03,node04的家目录上:
scp -r hadoop-3.1.0 root@node02:~
scp -r hadoop-3.1.0 root@node03:~
scp -r hadoop-3.1.0 root@node04:~
第一次安装要格式化来创建一个空白的fsimage(他在/home/hadoop_data/dfs/name/current/,.md5是验证文件):
hadoop-3.1.0/bin/hdfs namenode -format
启动hadoop: cd hadoop-3.1.0/sbin ./start-dfs.sh
用jps显示各个node上当前所有java进程
关闭4个node的防火墙和自启动:
systemctl stop firewalld.service
systemctl disable firewalld.service
访问namenode的http监控页面:http://192.168.154.101:9870/
配置windows下的C:\Windows\System32\drivers\etc\hosts:
192.168.154.101 node01
192.168.154.102 node02
192.168.154.103 node03
192.168.154.104 node04
上面不是高可用的,因为node01可能死掉,高可用HA(可靠的)的hdfs集群中,有多个nn,这几个nn除了状态都一样,没有snn,nn有2个状态active和standby,只有一个nn处于active状态,还有:

active的nn把产生的edis保存到所有的 jn 上,处于standby的nn把jn上的新增的edis定时同步下来(时间很快,相当于实时同步),每个zkfc对应一个nn
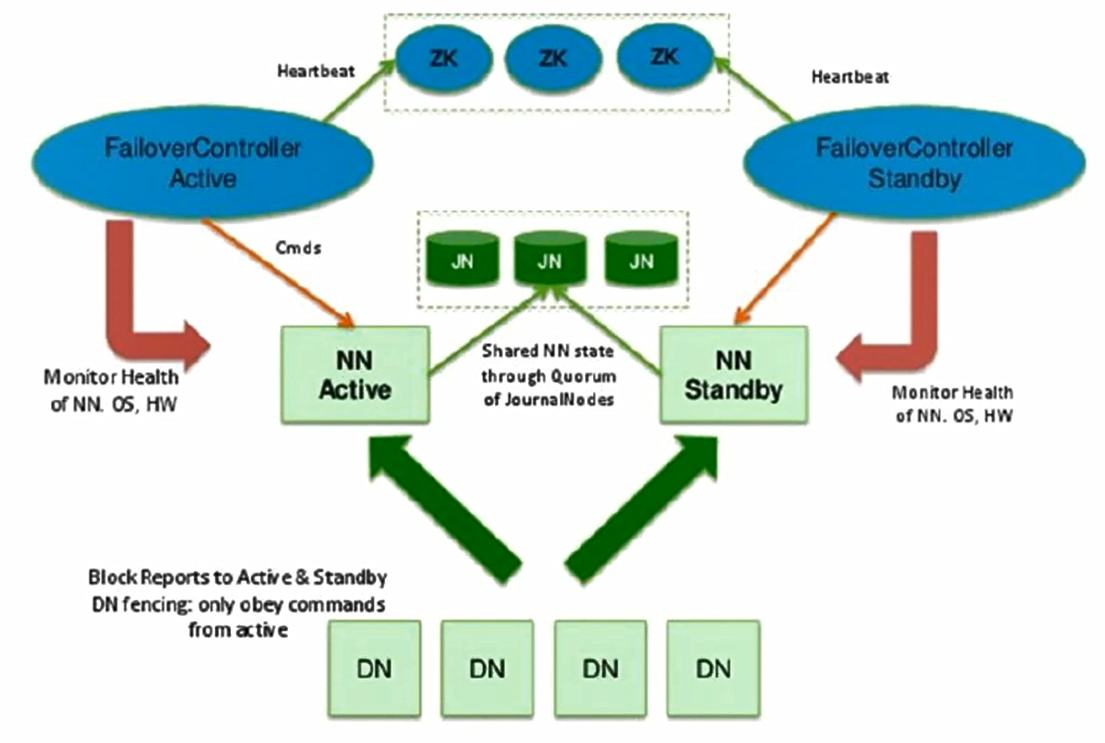
dn将block的位置数据汇报给所有的nn,zkfc监控到处于active的nn有问题,则通知zookeeper,zookeeper选择一个standby状态的nn,通知对应的zkfc,zkfc让该nn变为active:
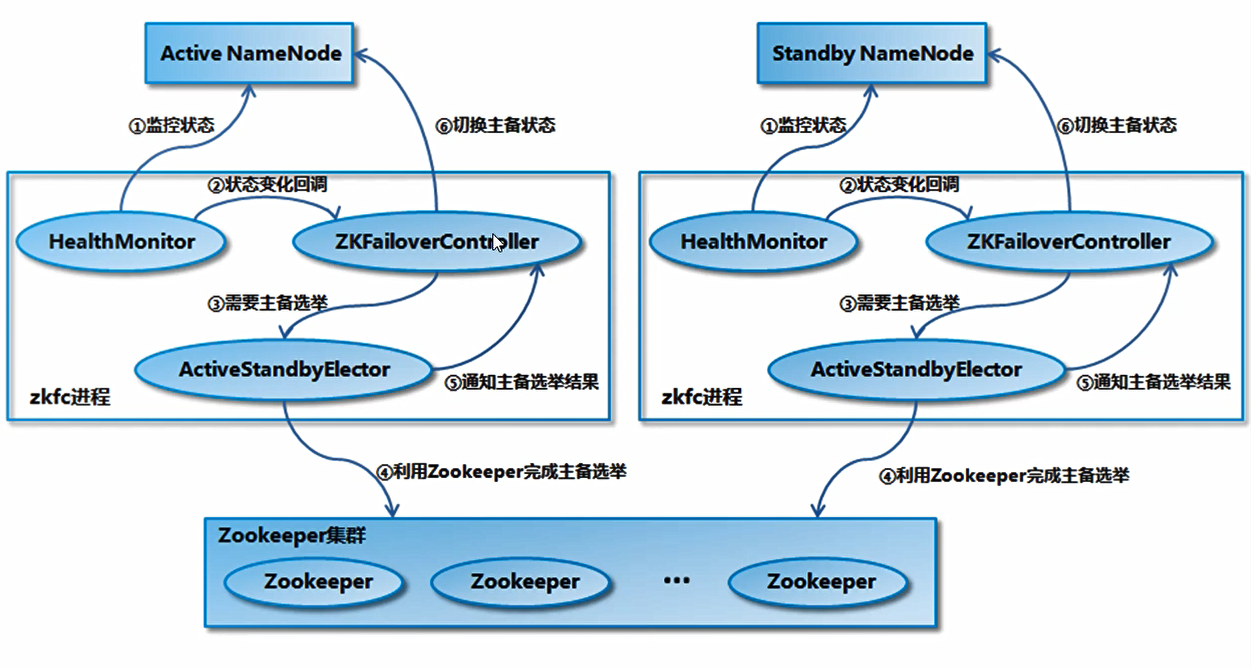
nn的fsimage都是相同的原因:一个nn初始化创建一个fsimage后,接下来拷贝到其他的nn上 ,一个standby的nn拿到 jn 上的edis来更新了fsimage后拷贝到其他所有的nn上
如果本机的dn挂了,可启动它:bin/hdfs --daemon start datanode
node01上传zookeeper,然后tar -xvf ...;
配置zookeeper数据存放位置,3个zookeeper放到node01,node02,node03,2888是zookeeper接收其他zookeeper的数据端口,3888是发送
vi zookeeper-3.4.6/conf/zoo.cfg
tickTime=2000
clientPort=2181
initLimit=5
syncLimit=2
dataDir=/home/zookeeper
server.1=node01:2888:3888
server.2=node02:2888:3888
server.3=node03:2888:3888
创建服务编号,在node01,node02,3上同时输入:mkdir /home/zookeeper
node01:echo 1 > /home/zookeeper/myid
node02:echo 2 > /home/zookeeper/myid
node03:echo 3 > /home/zookeeper/myid
将zookeeper拷贝到node02,3:
scp -r zookeeper-3.4.6 root@node02:~
scp -r zookeeper-3.4.6 root@node03:~
三台机器同时启动zookeeper:
zookeeper-3.4.6/bin/zkServer.sh start
jps看一下zookeeper有么有启动(QuorumPeerMain)
结构:
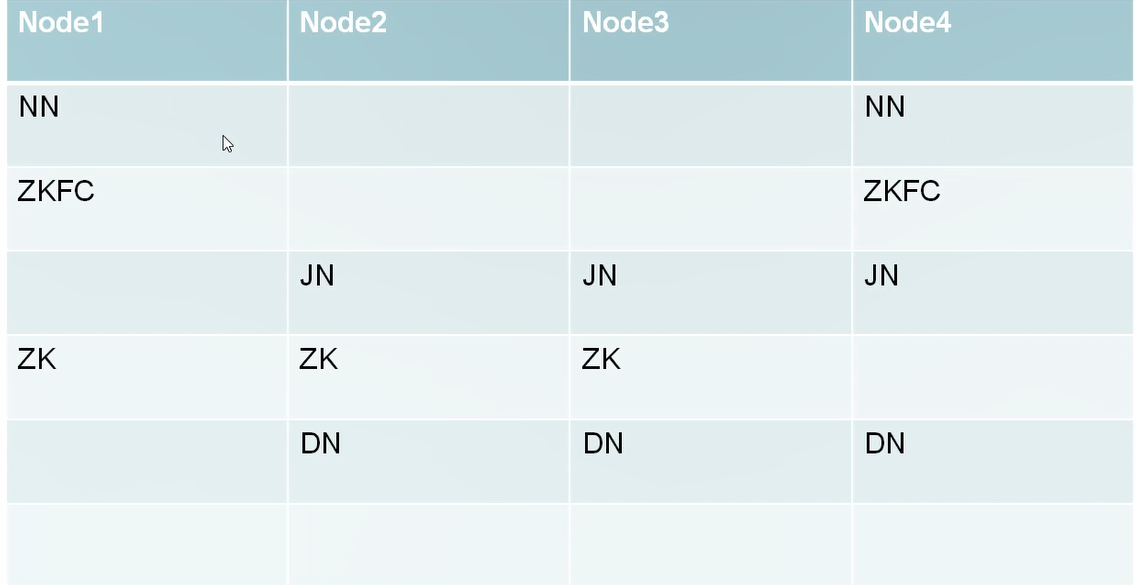
node01上配置其他节点的权限,注释掉snn,再加zkfc和jn:
vi hadoop-3.1.0/etc/hadoop/hadoop-env.sh
#export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_ZKFC_USER=root
export HDFS_JOURNALNODE_USER=root
配置浏览器权限为root方便浏览器操作,bjsxt是集群的名字,不是单个节点的名字:vi hadoop-3.1.0/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bjsxt</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop_data</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- HDFS连接zookeeper集群的地址和端口 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>node01:2181,node02:2181,node03:2181</value>
</property>
</configuration>
node04需要有秘钥:ssh-keygen
node01配置:vi hadoop-3.1.0/etc/hadoop/hdfs-site.xml
<configuration>
<!-- 定义hdfs集群ID号方便别人访问 -->
<property>
<name>dfs.nameservices</name>
<value>bjsxt</value>
</property>
<!-- 定义hdfs集群中namenode的ID号 -->
<property>
<name>dfs.ha.namenodes.bjsxt</name>
<value>nn1,nn2</value>
</property>
<!-- 定义namenode的主机名和RPC协议的端口 -->
<property>
<name>dfs.namenode.rpc-address.bjsxt.nn1</name>
<value>node01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.bjsxt.nn2</name>
<value>node04:8020</value>
</property>
<!-- 定义namenode的主机名和HTTP协议的端口 -->
<property>
<name>dfs.namenode.http-address.bjsxt.nn1</name>
<value>node01:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.bjsxt.nn2</name>
<value>node04:9870</value>
</property>
<!-- 定义共享edits的URL,jn -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node02:8485;node03:8485;node04:8485/laoxiao</value>
</property>
<!-- 定义HDFS的客户端连接HDFS集群时返回active namenode地址 -->
<property>
<name>dfs.client.failover.proxy.provider.bjsxt</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- HDFS集群中两个namenode切换状态时的隔离方法,通过隔离方法,当一个nn切换到active后,将另一个处于active的nn强制状态转换为standby -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- HDFS集群中两个namenode切换状态时的隔离方法的密钥 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- journalnode集群中用于保存edits文件的目录 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/journalnode/data</value>
</property>
<!-- HA的HDFS集群自动切换namenode的开关,改为true就能自动切换了-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
拷贝到node02,node03,node04:
scp hadoop-3.1.0/etc/hadoop/* root@node02:~/hadoop-3.1.0/etc/hadoop/
scp hadoop-3.1.0/etc/hadoop/* root@node03:~/hadoop-3.1.0/etc/hadoop/
scp hadoop-3.1.0/etc/hadoop/* root@node04:~/hadoop-3.1.0/etc/hadoop/
由于之前有了非HA的元数据,此时把集群变成HA的
node01配置一个变量:vi /etc/profile
export HADOOP_HOME=/root/hadoop-3.1.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
重新加载一下:source /etc/profile
启动集群的所有 jn:hadoop-daemons.sh start journalnode
jps看一下node02,3,4有没有启动
再看看有没有报错:tail -100 hadoop-3.1.0/logs/hadoop-root-journalnode-node04.log
共享namenode的edis到 jn 上,node01:
hdfs namenode -initializeSharedEdits
去node02,3,4看有没有edis:cd /opt/journalnode/data/laoxiao/current/
由于node01已经初始化,则node01上启动namenode:
hdfs --daemon start namenode
node04上执行命令拷贝node01的元数据:
cd hadoop-3.1.0/bin/
./hdfs namenode -bootstrapStandby
停止集群:stop-dfs.sh

 浙公网安备 33010602011771号
浙公网安备 33010602011771号