


实验班
1 . 由于不能FQ,先将DOWNLOAD_ROOT 上的数据下载到本地,然后传到云服务器上,该程序就直接从云服务器上获取文件到本地并且解压:
import os
import tarfile
from six.moves import urllib
HOUSING_PATH = "datasets/housing"
HOUSING_URL = "http://123.57.133.88/housing.tar"
def fetch_housing_data(housing_url=HOUSING_URL, housing_path=HOUSING_PATH):
if not os.path.isdir(housing_path): # os.path.isdir : 判断housing_path是否是一个目录
os.makedirs(housing_path) # 在D:\notebook下创建目录
tgz_path = os.path.join(housing_path, "housing.tgz") # 拼接路径
urllib.request.urlretrieve(housing_url, tgz_path) # 从housing_url下载数据到tgz_path
housing_tgz = tarfile.open(tgz_path) # 先打开文件
housing_tgz.extractall(path=housing_path) # 解压文件到housing_path得到 .csv
housing_tgz.close() # 关闭文件
fetch_housing_data()
2. 读取数据并查看数据特征,数据中的每行是一个街区,列对应属性
注意ocean_proximity属性指的是离海边的距离属于哪个等级:<1H OCEAN? INLAND ? NEAR OCEAN ? NEAR BAY ? ISLAND ?
import pandas as pd
import matplotlib.pyplot as plt
def load_housing_data(housing_path=HOUSING_PATH):
csv_path = os.path.join(housing_path, "housing.csv")
return pd.read_csv(csv_path) # 读取csv文件
housing = load_housing_data()
housing.head() # 查看前5行

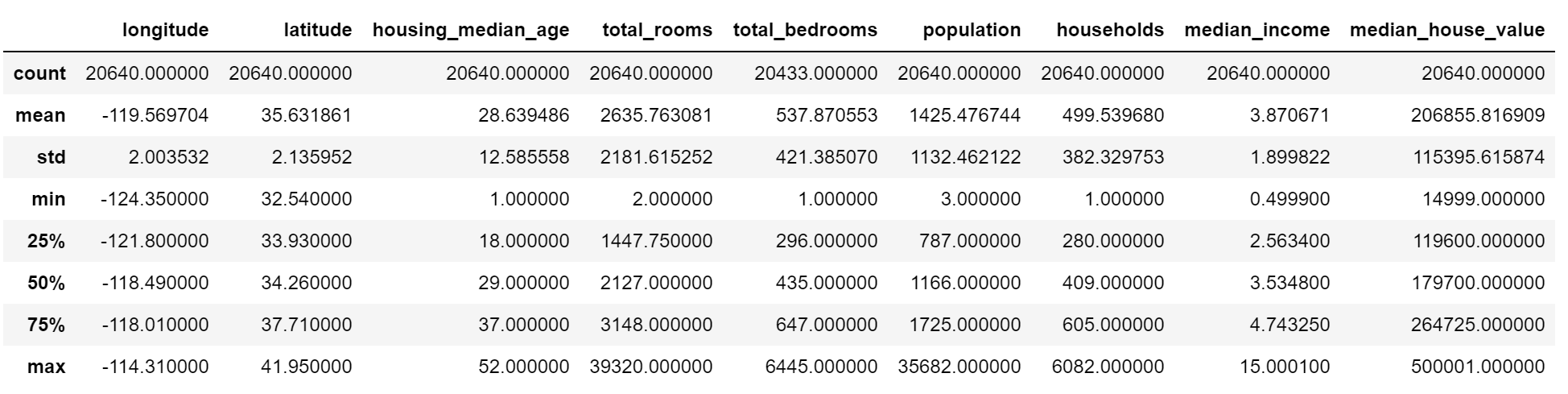
housing.describe()
count:统计longitude那一列有多少非空值,即有多少街区是有这个属性的
mean:longitude 的均值
25% : 有25%的房屋longitude是< -121.8的
zzz
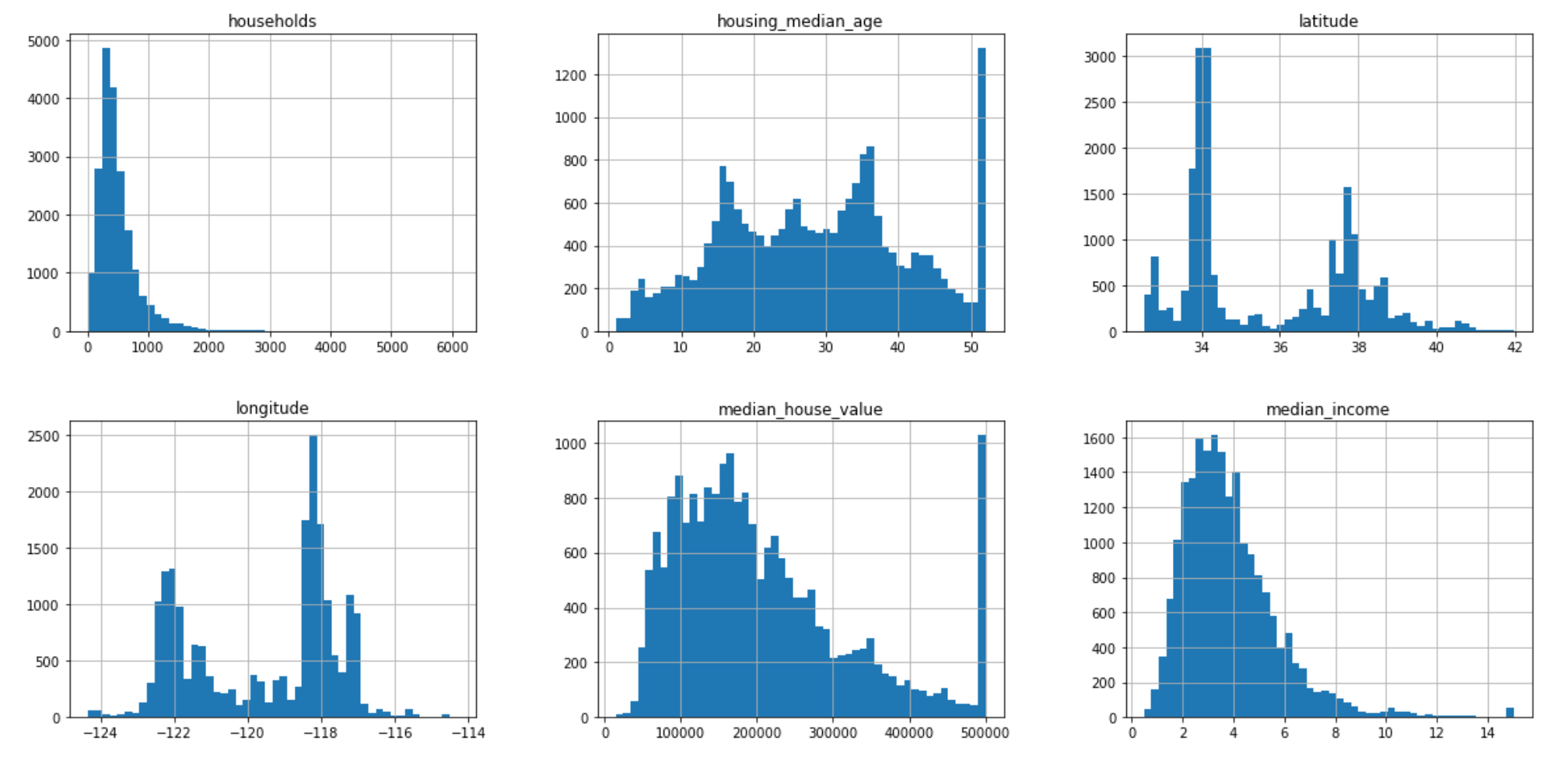
housing.hist(bins=50, figsize=(20,15))
plt.show()
根据每个属性画图:
见latitude,latitude=34的房屋有3000多个
创建测试集 test_set 和训练集 train_set ,该测试集一般占总数据的20%(提前抽离出一些新的数据用于测试)
为了使得每次运行,以前的测试集都不变,则将每个实例做哈希映射,若最后一个字节<=51则归入测试集 :
import hashlib
import numpy as np
def test_set_check(identifier, test_ratio, hash):
return hash(np.int64(identifier)).digest()[-1] < 256 * test_ratio
def split_train_test_by_id(data, test_ratio, id_column, hash=hashlib.md5):
ids = data[id_column]
in_test_set = ids.apply(lambda id_: test_set_check(id_, test_ratio, hash))
return data.loc[~in_test_set], data.loc[in_test_set]
housing_with_id = housing.reset_index() # 在原来的数据上加上一列index
train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "index")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号