


异常检测
原始模型前提
假设所有特征均服从正态分布:
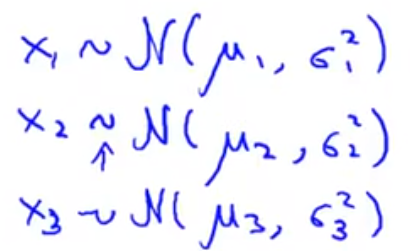
数据集划分
假定有1万个好引擎,20个坏引擎。训练集全部都是好引擎,以便训练出均值和方差。则按如下分类:

原始模型步骤
1.计算从j=1,2,3...,n的所有均值和方差:
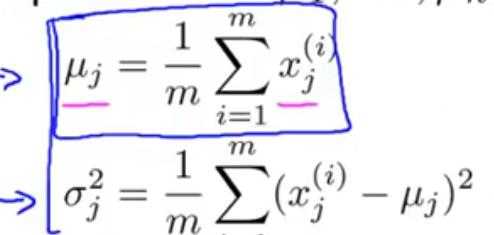
2.选定一个可疑点x,计算:
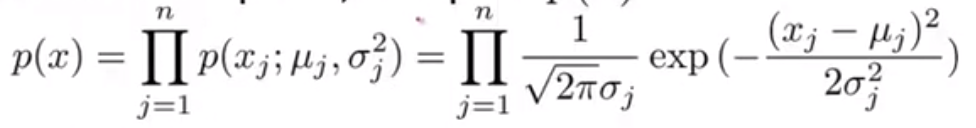
3.判定:

评价指标

参数的确定
为了确定ε的大小或者特征多少的确定,可以在交叉验证集上,试试哪个ε可以使得F值最大,就选择那个。
与监督学习的区别
数据集非常偏斜的情况下使用异常检测算法
若检测效果不好
假定一开始只用一个特征去检测,没有检测出来:
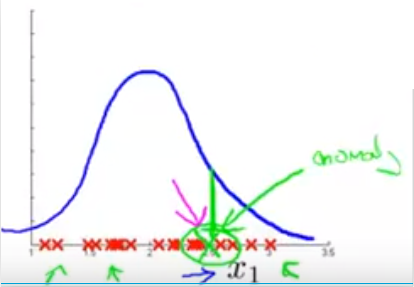
则可以多采用一个特征:
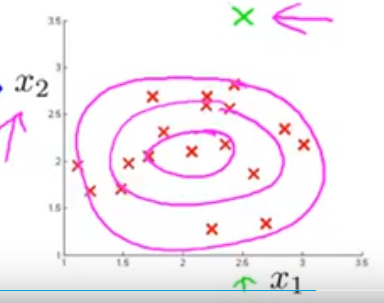
比如下图新增x5,x6特征:

多元高斯分布
不要为x1,x2单独建模,而是利用多元高斯分布建立一个统一的模型p,其中参数为:
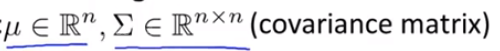
公式:

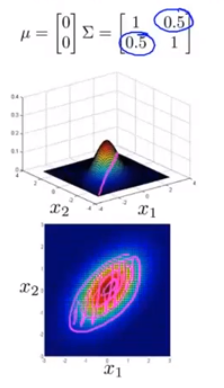
图像(假定三维):
多元高斯分布步骤
1.计算参数:

2.给定一个样本进行计算:
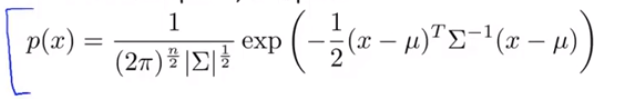
3.判定
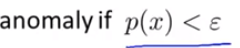
原始模型和多元高斯模型的比较
1.使用原始模型需要人为手动创建新特征,而高斯模型会自动步骤特征之间的关系。
2.当特征非常多的时候, 原始模型计算的成本更低
3.在使用高斯时,要求m远大于n。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号