Python网络爬虫——腾讯招聘数据 可视化
一. 选题的背景
Python网络爬虫课程设计选择《腾讯招聘数据》这个选题,旨在通过对大规模真实数据的分析和挖掘,达到以下预期目标:
①社会层面:通过对腾讯招聘数据的分析,可以了解当前市场上的就业趋势和职业需求,对于企业招聘和个人求职都具有重要的参考价值。
②经济层面:可以了解不同行业、不同职位的薪资待遇和就业机会,对于企业招聘和个人求职都具有指导作用。
③技术层面:可以让学生掌握Python网络爬虫技术和数据分析技能,提高数据处理和分析的能力,为学生未来从事数据分析、数据挖掘等领域的工作打下坚实的基础。
④数据来源:腾讯是中国最大的互联网公司之一,其招聘数据具有很高的可信度和代表性,可以为学生提供真实的数据挖掘案例,从而提高学生的数据分析和挖掘能力。
二.主题式网络爬虫设计方案
1.主题式网络爬虫名称
腾讯招聘数据
2.主题式网络爬虫爬取的内容与数据特征分析
爬取岗位地址和岗位属性百分比分布、岗位数量和岗位属性数量、岗位名称、岗位职责、岗位地址和招聘数据。
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
(1)设计方案概述:
要爬取腾讯招聘信息,使用Python编写一个网络爬虫程序。
(2)实现思路如下:
①首先,我们需要确定要爬取的网站页面,例如腾讯招聘的页面链接为:https://careers.tencent.com/search.html。
②发送HTTP请求获取页面内容,可以使用Python的requests库实现。
③解析页面内容,获取招聘信息。可以使用Python的BeautifulSoup库或者正则表达式进行解析。
④将获取到的招聘信息存储到本地或者数据库中。
(3)技术难点:
①反爬虫机制:腾讯招聘网站可能会设置反爬虫机制,例如限制IP访问频率、使用验证码等。我们需要在爬虫程序中添加一些策略,避免被网站封禁。
②动态页面:腾讯招聘网站的页面是动态生成的,需要使用浏览器渲染引擎来解析页面。可以使用Python的Selenium库模拟浏览器操作,获取动态页面内容。
③数据存储:获取到的招聘信息需要进行存储,可以选择将数据存储到本地文件或者数据库中。需要考虑数据存储格式、存储路径等问题。
三、主题页面的结构特征分析
1.主题页面的结构与特征分析
目标内容界面:

2.Htmls 页面解析
四、网络爬虫程序设计
1.数据爬取与采集
以下为爬取过程代码
def save_excel(self, data_dict): ''' 保存数据 ''' with open(r'./{}.csv'.format('招聘数据'), 'a+', newline='', encoding='gbk') as file_csv: csv_writer = csv.writer(file_csv, delimiter=',') csv_writer.writerow(data_dict['岗位详情']) print(r'***正在保存: 招聘数据:{}'.format(data_dict['岗位详情'][0])) def show_image(self):
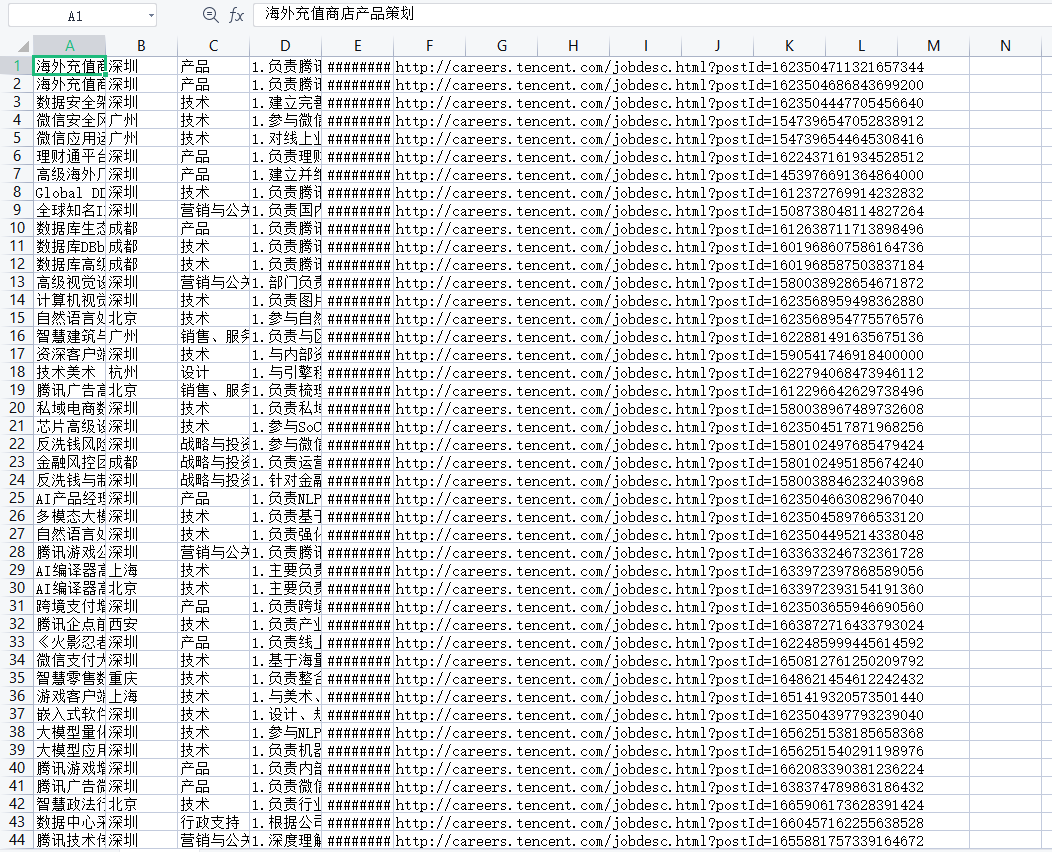
现在我们获得了csv其中csv如下图所示
2.防止反爬虫
USER_AGENT_LIST = [ 'Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.90 Safari/537.36', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3451.0 Safari/537.36', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:57.0) Gecko/20100101 Firefox/57.0', 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1500.71 Safari/537.36', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.2999.0 Safari/537.36', 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.70 Safari/537.36', 'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.4; en-US; rv:1.9.2.2) Gecko/20100316 Firefox/3.6.2', 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.155 Safari/537.36 OPR/31.0.1889.174', 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.1.4322; MS-RTC LM 8; InfoPath.2; Tablet PC 2.0)', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36 OPR/55.0.2994.61', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.814.0 Safari/535.1', 'Mozilla/5.0 (Macintosh; U; PPC Mac OS X; ja-jp) AppleWebKit/418.9.1 (KHTML, like Gecko) Safari/419.3', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.134 Safari/537.36', 'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; Trident/6.0; Touch; MASMJS)', 'Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.21 (KHTML, like Gecko) Chrome/19.0.1041.0 Safari/535.21', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', 'Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.90 Safari/537.36', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3451.0 Safari/537.36', ]
3.开始访问生成分析图
import jieba from collections import Counter from wordcloud import WordCloud from PIL import Image import numpy as np from matplotlib import pyplot as plt import random, csv, requests, time, re from matplotlib.font_manager import FontProperties class TXSpider(object): def __init__(self): self.big_str = '' # 起始的请求地址 self.start_url = 'https://careers.tencent.com/tencentcareer/api/post/Query' # 起始的翻页页码 self.start_page = 1 # 翻页条件 self.is_running = True # 准备工作地点大列表 self.addr_list = [] # 准备岗位种类大列表 self.category_list = [] def parse_start_url(self): # 条件循环模拟翻页 while self.is_running: # 构造请求参数 params = { # 捕捉当前时间戳 'timestamp': str(int(time.time() * 1000)), 'countryId': '', 'cityId': '', 'bgIds': '', 'productId': '', 'categoryId': '', 'parentCategoryId': '', 'attrId': '', 'keyword': '', 'pageIndex': str(self.start_page), 'pageSize': '10', 'language': 'zh-cn', 'area': 'cn' } headers = {'user-agent': random.choice(USER_AGENT_LIST)} response = requests.get(url=self.start_url, headers=headers, params=params).json() """调用解析响应方法""" self.parse_response_json(response) """翻页递增""" self.start_page += 1 """翻页终止条件""" if self.start_page == 20: self.is_running = False """翻页完成,开始生成分析图""" self.crate_img_four_func()
 文本分析:jieba 分词
文本分析:jieba 分词
4.数据分析与可视化
生成饼图和函数分析
def crate_img_four_func(self): # 统计数量 data = {} # 大字典 addr_dict = {} # 工作地址字典 cate_dict = {} # 工作属性子弹 for k_addr, v_cate in zip(self.addr_list, self.category_list): if k_addr in data: # 大字典统计工作地址数据 data[k_addr] = data[k_addr] + 1 # 地址字典统计数据 addr_dict[k_addr] = addr_dict[k_addr] + 1 else: data[k_addr] = 1 addr_dict[k_addr] = 1 if v_cate in data: # 大字典统计工作属性数据 data[v_cate] = data[v_cate] + 1 # 工作属性字典统计数据 cate_dict[v_cate] = data[v_cate] + 1 else: data[v_cate] = 1 cate_dict[v_cate] = 1 """工作地址饼图""" addr_dict_key = [k for k in addr_dict.keys()] addr_dict_value = [v for v in addr_dict.values()] plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] plt.rcParams['axes.unicode_minus'] = False plt.pie(addr_dict_value, labels=addr_dict_key, autopct='%1.1f%%') plt.title(f'岗位地址和岗位属性百分比分布') plt.savefig(f'岗位地址和岗位属性百分比分布-饼图') plt.show()
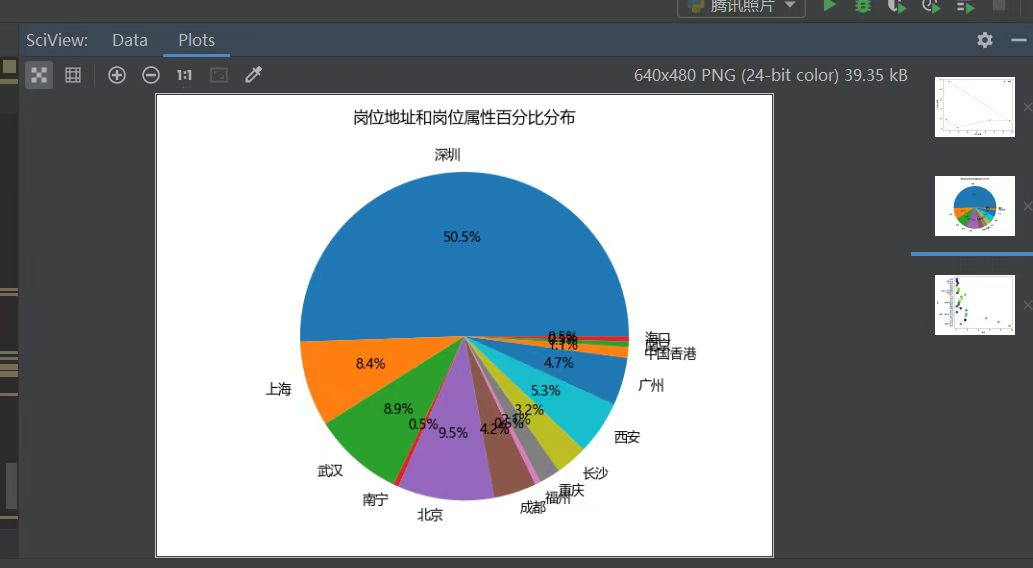
生成柱状图和散点图
'''根据岗位地址和岗位属性二者数量生成柱状图''' import matplotlib;matplotlib.use('TkAgg') plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False zhfont1 = matplotlib.font_manager.FontProperties(fname='C:\Windows\Fonts\simsun.ttc') name_list = [name for name in data.keys()] num_list = [value for value in data.values()] width = 0.5 # 柱子的宽度 index = np.arange(len(name_list)) plt.bar(index, num_list, width, color='steelblue', tick_label=name_list, label='岗位数量') plt.legend(['分解能耗', '真实能耗'], prop=zhfont1, labelspacing=1) for a, b in zip(index, num_list): # 柱子上的数字显示 plt.text(a, b, '%.2f' % b, ha='center', va='bottom', fontsize=7) plt.xticks(rotation=270) plt.title('岗位数量和岗位属性数量柱状图') plt.ylabel('次') plt.legend() plt.savefig(f'岗位数量和岗位属性数量柱状图-柱状图', bbox_inches='tight') plt.show()
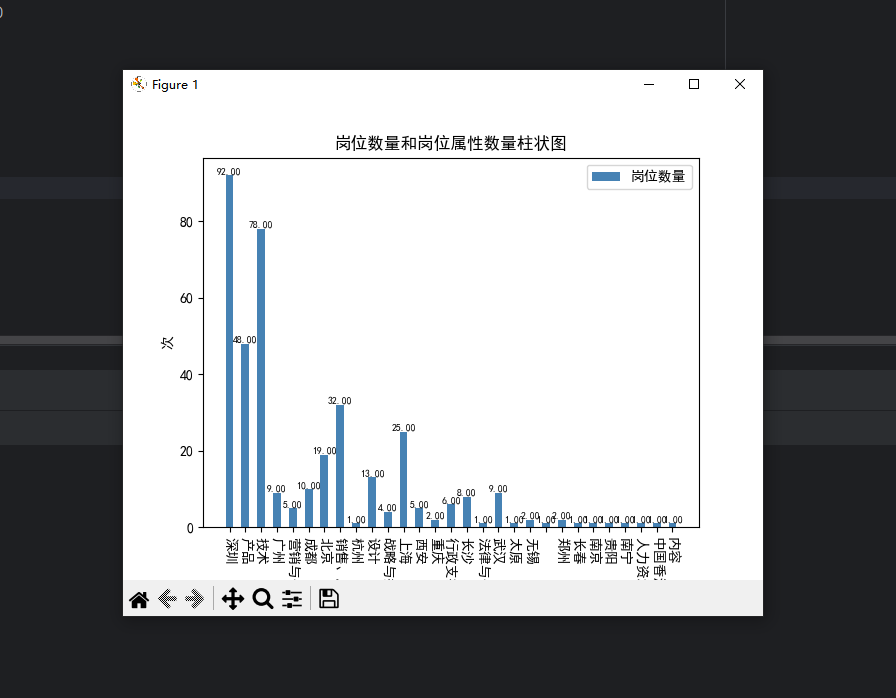
5.生成词云图可视化处理
def show_image(self): ''' 词云图 ''' # 进行jieba分词, 数据存到 source_list中 source_list = list(jieba.cut(self.big_str)) # 去除空格 source_list = [i for i in source_list if i != ' '] # 读取停用词文本 stop_words = [] with open('stopw.txt', 'r', encoding='utf-8') as f: for line in f: stop_words.append(line.strip().lower()) # 去除停用词 result_words = [] for word in source_list: if word != '\n': if word.lower() not in stop_words: if word not in stop_words: result_words.append(word) # 统计词频 word_count = Counter(result_words) top_words = word_count.most_common(20) # print('=============前20的词================') # for k, v in top_words: # print(k, v) # 绘制词云图 # A、添加背景图片 mask_pic = np.array(Image.open('背景.png')) # B、设置词云图样式 wd = WordCloud( font_path="msyh.ttc", # msyh.ttc background_color="white", scale=4, mask=mask_pic, max_words=100, ) # 添加数据 wd.generate_from_frequencies(dict(word_count)) wd.to_file('词云图.png') print('词云图创建完成')
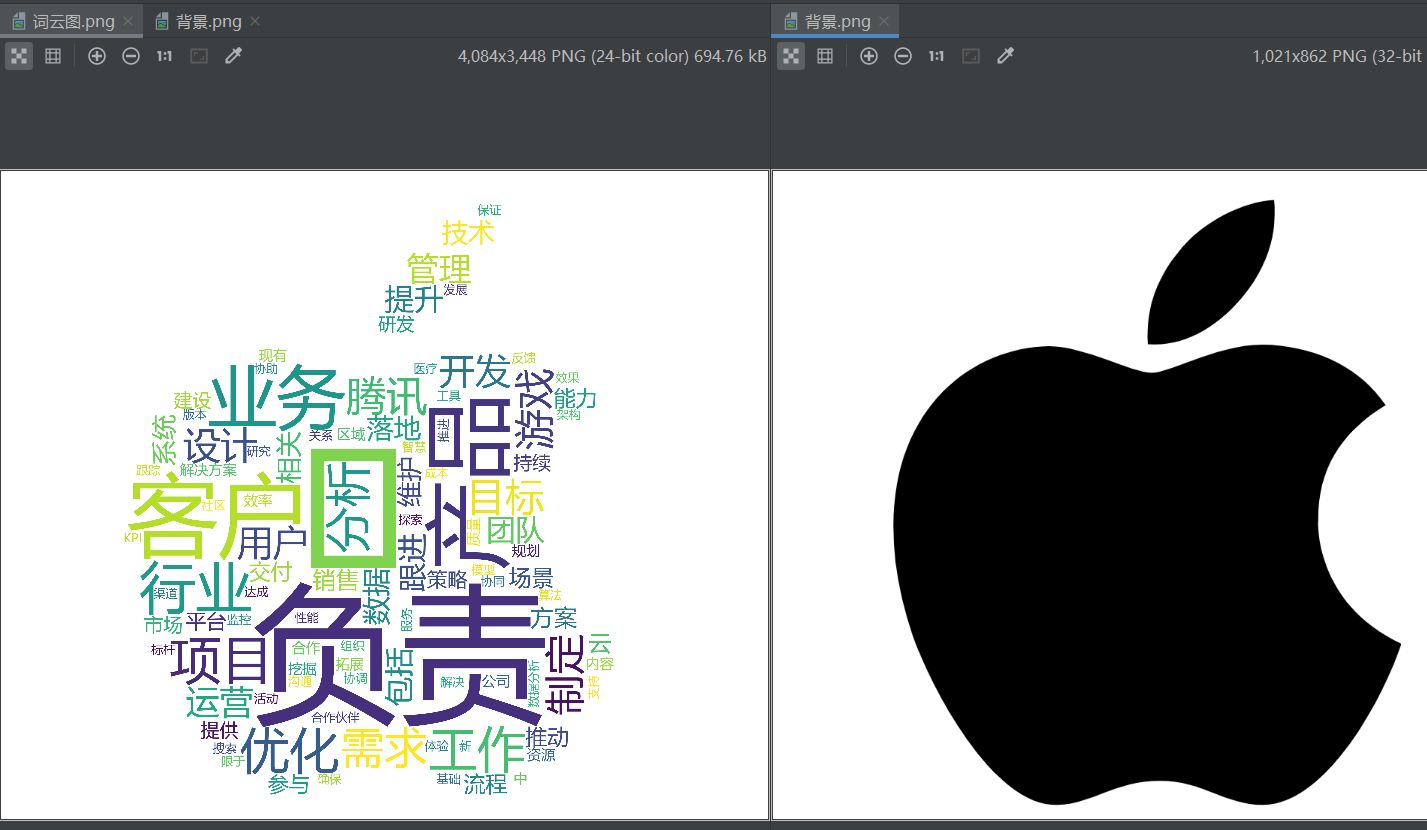
6.将以上各部分的代码汇总,附上完整程序代码
USER_AGENT_LIST = [ 'Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.90 Safari/537.36', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3451.0 Safari/537.36', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:57.0) Gecko/20100101 Firefox/57.0', 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1500.71 Safari/537.36', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.2999.0 Safari/537.36', 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.70 Safari/537.36', 'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.4; en-US; rv:1.9.2.2) Gecko/20100316 Firefox/3.6.2', 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.155 Safari/537.36 OPR/31.0.1889.174', 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.1.4322; MS-RTC LM 8; InfoPath.2; Tablet PC 2.0)', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36 OPR/55.0.2994.61', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.814.0 Safari/535.1', 'Mozilla/5.0 (Macintosh; U; PPC Mac OS X; ja-jp) AppleWebKit/418.9.1 (KHTML, like Gecko) Safari/419.3', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.134 Safari/537.36', 'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; Trident/6.0; Touch; MASMJS)', 'Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.21 (KHTML, like Gecko) Chrome/19.0.1041.0 Safari/535.21', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', 'Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.90 Safari/537.36', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3451.0 Safari/537.36', ] import jieba from collections import Counter from wordcloud import WordCloud from PIL import Image import numpy as np from matplotlib import pyplot as plt import random, csv, requests, time, re from matplotlib.font_manager import FontProperties class TXSpider(object): def __init__(self): self.big_str = '' # 起始的请求地址 self.start_url = 'https://careers.tencent.com/tencentcareer/api/post/Query' # 起始的翻页页码 self.start_page = 1 # 翻页条件 self.is_running = True # 准备工作地点大列表 self.addr_list = [] # 准备岗位种类大列表 self.category_list = [] def parse_start_url(self): # 条件循环模拟翻页 while self.is_running: # 构造请求参数 params = { # 捕捉当前时间戳 'timestamp': str(int(time.time() * 1000)), 'countryId': '', 'cityId': '', 'bgIds': '', 'productId': '', 'categoryId': '', 'parentCategoryId': '', 'attrId': '', 'keyword': '', 'pageIndex': str(self.start_page), 'pageSize': '10', 'language': 'zh-cn', 'area': 'cn' } headers = {'user-agent': random.choice(USER_AGENT_LIST)} response = requests.get(url=self.start_url, headers=headers, params=params).json() """调用解析响应方法""" self.parse_response_json(response) """翻页递增""" self.start_page += 1 """翻页终止条件""" if self.start_page == 20: self.is_running = False """翻页完成,开始生成分析图""" self.crate_img_four_func() def crate_img_four_func(self): # 统计数量 data = {} # 大字典 addr_dict = {} # 工作地址字典 cate_dict = {} # 工作属性子弹 for k_addr, v_cate in zip(self.addr_list, self.category_list): if k_addr in data: # 大字典统计工作地址数据 data[k_addr] = data[k_addr] + 1 # 地址字典统计数据 addr_dict[k_addr] = addr_dict[k_addr] + 1 else: data[k_addr] = 1 addr_dict[k_addr] = 1 if v_cate in data: # 大字典统计工作属性数据 data[v_cate] = data[v_cate] + 1 # 工作属性字典统计数据 cate_dict[v_cate] = data[v_cate] + 1 else: data[v_cate] = 1 cate_dict[v_cate] = 1 """工作地址饼图""" addr_dict_key = [k for k in addr_dict.keys()] addr_dict_value = [v for v in addr_dict.values()] plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] plt.rcParams['axes.unicode_minus'] = False plt.pie(addr_dict_value, labels=addr_dict_key, autopct='%1.1f%%') plt.title(f'岗位地址和岗位属性百分比分布') plt.savefig(f'岗位地址和岗位属性百分比分布-饼图') plt.show() '''根据岗位地址和岗位属性二者数量生成柱状图''' import matplotlib;matplotlib.use('TkAgg') plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False zhfont1 = matplotlib.font_manager.FontProperties(fname='C:\Windows\Fonts\simsun.ttc') name_list = [name for name in data.keys()] num_list = [value for value in data.values()] width = 0.5 # 柱子的宽度 index = np.arange(len(name_list)) plt.bar(index, num_list, width, color='steelblue', tick_label=name_list, label='岗位数量') plt.legend(['分解能耗', '真实能耗'], prop=zhfont1, labelspacing=1) for a, b in zip(index, num_list): # 柱子上的数字显示 plt.text(a, b, '%.2f' % b, ha='center', va='bottom', fontsize=7) plt.xticks(rotation=270) plt.title('岗位数量和岗位属性数量柱状图') plt.ylabel('次') plt.legend() plt.savefig(f'岗位数量和岗位属性数量柱状图-柱状图', bbox_inches='tight') plt.show() def parse_response_json(self, response): # 获取岗位信息大列表 json_data = response['Data']['Posts'] # 判断结果是否有数据 if json_data is None: # 没有数据,设置循环条件为False self.is_running = False # 反之,开始提取数据 else: # 循环遍历,取出列表中的每一个岗位字典 # 通过key取value值的方法进行采集数据 for data in json_data: # 工作地点 LocationName = data['LocationName'] # 往地址大列表中添加数据 self.addr_list.append(LocationName) # 工作属性 CategoryName = data['CategoryName'] # 往工作属性大列表中添加数据 self.category_list.append(CategoryName) # 岗位名称 RecruitPostName = data['RecruitPostName'] # 岗位职责 Responsibility = data['Responsibility'] Responsibility = re.sub(r'\n|\t| |\u2022|\xa0', '', Responsibility) self.big_str += Responsibility # 发布时间 LastUpdateTime = data['LastUpdateTime'] # 岗位地址 PostURL = data['PostURL'] # 构造保存excel所需要的格式字典 data_dict = { '岗位详情': [RecruitPostName, LocationName, CategoryName, Responsibility, LastUpdateTime, PostURL] } self.save_excel(data_dict) def save_excel(self, data_dict): ''' 保存数据 ''' with open(r'./{}.csv'.format('招聘数据'), 'a+', newline='', encoding='gbk') as file_csv: csv_writer = csv.writer(file_csv, delimiter=',') csv_writer.writerow(data_dict['岗位详情']) print(r'***正在保存: 招聘数据:{}'.format(data_dict['岗位详情'][0])) def show_image(self): ''' 词云图 ''' # 进行jieba分词, 数据存到 source_list中 source_list = list(jieba.cut(self.big_str)) # 去除空格 source_list = [i for i in source_list if i != ' '] # 读取停用词文本 stop_words = [] with open('stopw.txt', 'r', encoding='utf-8') as f: for line in f: stop_words.append(line.strip().lower()) # 去除停用词 result_words = [] for word in source_list: if word != '\n': if word.lower() not in stop_words: if word not in stop_words: result_words.append(word) # 统计词频 word_count = Counter(result_words) top_words = word_count.most_common(20) # print('=============前20的词================') # for k, v in top_words: # print(k, v) # 绘制词云图 # A、添加背景图片 mask_pic = np.array(Image.open('背景.png')) # B、设置词云图样式 wd = WordCloud( font_path="msyh.ttc", # msyh.ttc background_color="white", scale=4, mask=mask_pic, max_words=100, ) # 添加数据 wd.generate_from_frequencies(dict(word_count)) wd.to_file('词云图.png') print('词云图创建完成') def run(self): ''' 逻辑控制部分 ''' self.parse_start_url() self.show_image() if __name__ == '__main__': t = TXSpider() t.run()
五、总结
1.结论:
①招聘信息的数量和类型:分析不同时间段和不同职位类型的招聘信息数量,了解腾讯公司的招聘需求和趋势。
②薪资水平:对不同职位类型的薪资水平进行分析,了解腾讯公司不同职位的薪资水平和差异。
③岗位要求:分析不同职位类型的招聘要求,如学历、工作经验、技能等,了解腾讯公司不同职位的要求和趋势。
④招聘部门:不同部门的招聘信息数量和类型,了解腾讯公司不同部门的招聘需求和趋势。
⑤地域分布:不同地区的招聘信息数量和类型,了解腾讯公司在不同地区的招聘需求和趋势。
⑥技能要求:不同职位类型的技能要求,了解腾讯公司对于不同职位的技能要求和趋势。
⑦招聘渠道:不同招聘渠道的招聘信息数量和类型,了解腾讯公司在不同招聘渠道的招聘需求和趋势。
达到了预期的目标了。
2.收获:
①熟练掌握Python网络爬虫的基本原理和技能。
②学会如何使用Python爬虫库(如BeautifulSoup、Scrapy等)来爬取网页数据。
③熟悉如何处理和清洗爬取到的数据,以便后续的数据分析和可视化。
④学会如何将爬取到的数据存储到数据库中,以便后续的数据处理和分析。
⑤了解如何使用Python的数据分析和可视化库(如Pandas、Matplotlib、Seaborn等)来分析和可视化数据。
⑥加深对数据分析和可视化的理解,了解如何从数据中发现规律和趋势。
3.改进建议:
①提高代码的可读性和可维护性,注重代码的规范和风格。
②考虑如何提高爬虫的效率和稳定性,避免被反爬虫机制拦截。
③在数据分析和可视化方面,可以考虑使用更多的图表类型和数据分析方法,以便更全面地了解数据。
④考虑如何将数据分析和可视化的结果呈现给用户,以便用户更好地理解数据。可以考虑使用交互式可视化工具,如Bokeh、Plotly等。
⑤在爬取数据时,要遵守网站的爬虫规则和法律法规,避免侵犯他人权益。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号