
① 不支持key为null
一、ConcurrentHashMap1.7
1、背景
传统HashTable保证线程安全,是采用synchronized锁将整个HashTable中的数组锁住,在多个线程中只允许一个线程访问Put或者Get,效率非常低,但是能够保证线程安全问题。
JDK官方不推荐在多线程的情况下使用HashTable或者HashMap,建议使用ConcurrentHashMap分段HashMap,能保证效率和安全性。
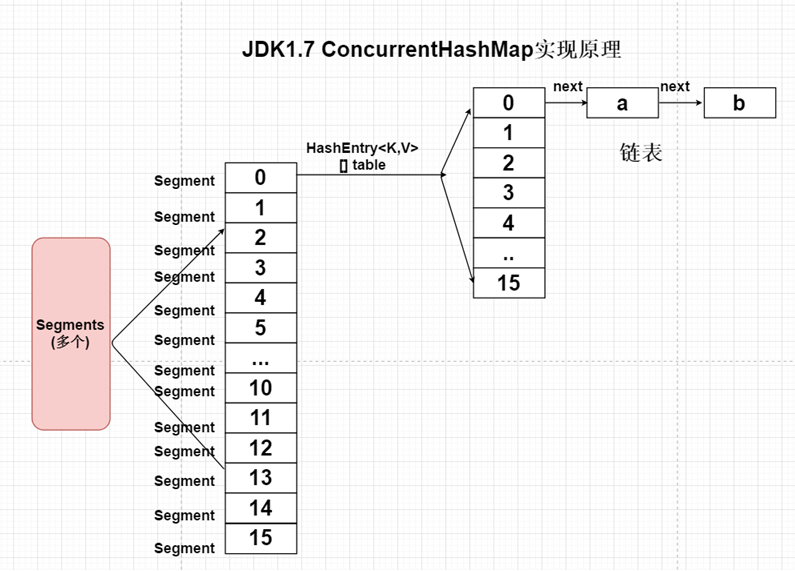
2、ConcurrentHashMap1.7架构
基于Segment分段锁设计,lock+cas保证node节点线程安全问题。
ConcurrentHashMap1.7将一个大的HashMap集合拆分成n多个不同的小的HashTable(Segment),默认的情况下是分成16个不同的Segment。每个Segment中都有自己独立的HashEntry<K,V>[] table.
第一次计算存放在哪个Segment对象中,第二次计算Segment对象中哪个HashEntry<K,V>[] table下标位置。
扩容:支持多个Segment同时扩容。
3、核心参数
##1.无参构造函数分析: initialCapacity ---16 loadFactor HashEntry<K,V>[] table; 加载因子0.75 concurrencyLevel 并发级别 默认是16 ##2. 并发级别是能够大于2的16次方 if (concurrencyLevel > MAX_SEGMENTS) concurrencyLevel = MAX_SEGMENTS; ##3.sshift 左移位的次数 ssize 作用:记录segment数组大小 int sshift = 0; int ssize = 1; while (ssize < concurrencyLevel) { ++sshift; ssize <<= 1; } ##4. segmentShift segmentMask:ssize - 1 做与运算的时候能够将key均匀存放; this.segmentShift = 32 - sshift; this.segmentMask = ssize - 1; ##5. 初始化Segment0 赋值为下标0的位置 Segment<K,V> s0 = new Segment<K,V>(loadFactor, (int)(cap * loadFactor), (HashEntry<K,V>[])new HashEntry[cap]); ##6.采用CAS修改复制给Segment数组 UNSAFE.putOrderedObject(ss, SBASE, s0); // or
4、Put方法
Put方法底层的实现 简单分析 Segment<K,V> s; if (value == null) throw new NullPointerException(); ###计算key存放那个Segment数组下标位置; int hash = hash(key); int j = (hash >>> segmentShift28) & segmentMask15; //保留最高4位与15做与运算 ###使用cas 获取Segment[10]对象 如果没有获取到的情况下,则创建一个新的segment对象 if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck (segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment s = ensureSegment(j); ### 使用lock锁对put方法保证线程安全问题 return s.put(key, hash, value, false); 0000 0000 00000 0000 0000 0000 0000 0011 0000 0000 00000 0000 0000 0000 0000 0011
6、深度分析
Segment<K,V> ensureSegment(int k) private Segment<K,V> ensureSegment(int k) { final Segment<K,V>[] ss = this.segments; long u = (k << SSHIFT) + SBASE; // raw offset Segment<K,V> seg; ### 使用UNSAFE强制从主内存中获取 Segment对象,如果没有获取到的情况=null if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) { ## 使用原型模式 将下标为0的Segment设定参数信息 赋值到新的Segment对象中 Segment<K,V> proto = ss[0]; // use segment 0 as prototype int cap = proto.table.length; float lf = proto.loadFactor; int threshold = (int)(cap * lf); HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap]; #### 使用UNSAFE强制从主内存中获取 Segment对象,如果没有获取到的情况=null if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) { // recheck ###创建一个新的Segment对象 Segment<K,V> s = new Segment<K,V>(lf, threshold, tab); while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) { ###使用CAS做修改 if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s)) break; } } } return seg; } final V put(K key, int hash, V value, boolean onlyIfAbsent) { ###尝试获取锁,如果获取到的情况下则自旋 HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value); V oldValue; try { HashEntry<K,V>[] tab = table; ###计算该key存放的index下标位置 int index = (tab.length - 1) & hash; HashEntry<K,V> first = entryAt(tab, index); for (HashEntry<K,V> e = first;;) { if (e != null) { K k; ###查找链表如果链表中存在该key的则修改 if ((k = e.key) == key || (e.hash == hash && key.equals(k))) { oldValue = e.value; if (!onlyIfAbsent) { e.value = value; ++modCount; } break; } e = e.next; } else { if (node != null) node.setNext(first); else ###创建一个新的node结点 头插入法 node = new HashEntry<K,V>(hash, key, value, first); int c = count + 1; ###如果达到阈值提前扩容 if (c > threshold && tab.length < MAXIMUM_CAPACITY) rehash(node); else setEntryAt(tab, index, node); ++modCount; count = c; oldValue = null; break; } } } finally { ###释放锁 unlock(); } return oldValue; }
二、ConcurrentHashMap1.8
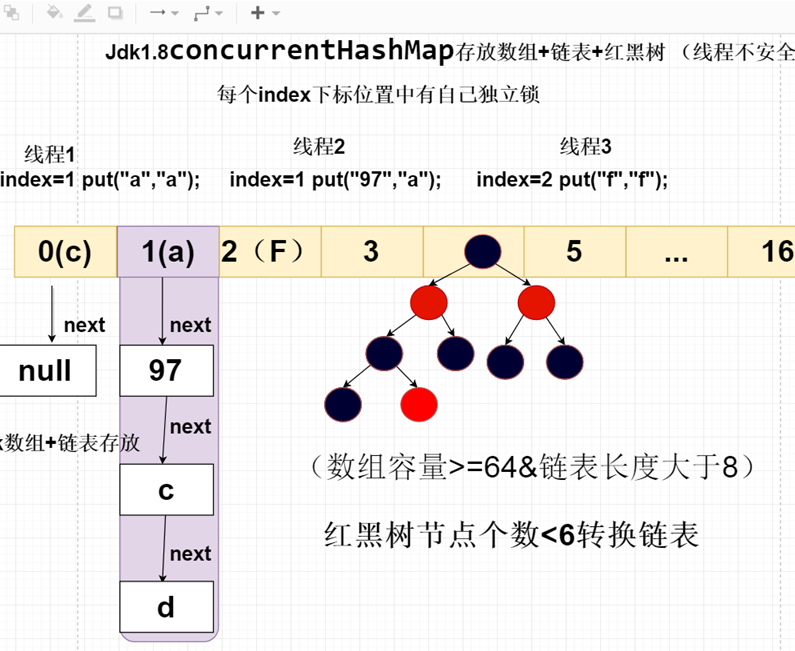
1、介绍
ConcurrentHashMap1.8取消segment分段设计,采用对CAS + synchronized保证node节点,并发线程安全问题,将锁的粒度拆分到每个index
下标位置,实现的效率与ConcurrentHashMap1.7相同。
锁的竞争:多个线程同时put key的时候,多个key都落在同一个index node节点时,需要做所得竞争
2、源码分析
1)构造函数为空,说明是懒加载;
2)不支持key为null(put方法中)
3)binCount 记录链表长度,如果大于8的情况下,则链表转红黑树。
4)在全局共享变量中加上volatile关键字,及时读取最新主内存数据,保证线程可见性(为第6点准备)。
5)sizeCtl 默认为0,用来控制table的初始化和扩容操作,具体应用在后续会体现出来。-1 代表一个线程正在进行table初始化扩容,-2 代表两个线程正在进行table初始化扩容(为第6点准备)。
6)ConcurrentHashMap1.8 ,每个线程做put操作初始化时,发现sizeCtl <0会进行自旋状态,非常消耗cpu,导致cpu飙升。当一个线程获取到锁至给table初始化的整个阶段,其他线程都一直在做自旋,直到判断table不为null才退出,如果占用资源的线程在给table赋值之前断电,其他线程一直自旋。
7)初始化默认长度16
8)sc 提前扩容的元素数量 sc = n - (n>>>2);
9)CAS使用:多个线程同时赋值修改没有冲突的index位置元素时使用CAS(对比第11点)
如果CAS修改成功,则直接退出自旋,否在继续自旋。
10)并发扩容时做辅助扩容,非常厉害

11)Synchronized使用 :多个线程同时赋值修改index位置冲突元素时使用Synchronized锁(对比第9点)
12)对该节点的链表进行扫描并判断,如果key相等则修改,不等则找到最后一个元素,插到其后面。
13)addCount 提前扩容;对size做++.CounterCells。记录每个线程size++的次数。
14)如何统计size
ConcurrentHashMap1.7 每个segment有独立统计size值,可以通过累加每个segment中的size。
ConcurrentHashMap1.8,每个线程中有增加元素时,会该线程随机数与length-1取余,得出在CounterCells数组(多线程可见)中index下标位置,对其下标元素+1,最后对所有下标元素值累加得出size。当线程随机数取余产生index冲突,且多线程对该index操作时,使用cas进行操作。
源码:
private final void addCount(long x, int check) { // as 表示 LongAdder.cells // b 表示 LongAdder.base // s 表示当前map.table中元素的数量 CounterCell[] as; long b, s; //条件一:true-> 表示cells 已经初始化了,当前线程应该去使用hash寻址找到合适的cell 去累加数据 // false-> 表示当前线程应该将数据累加到base //条件二:false-> 表示写base成功,数据累加到base 中了,当前竞争不强烈,不需要创建cells // true-> 表示写base失败,与其它线程在base上发生竞争,当前线程应该去尝试创建cells /** * LongAdder 中的cekks数组,当baseCount 发生竞争后,会创建cells数组 * 线程会通过计算hash值 取道自己的cell,将增量累加到指定cell中 * 总数 = sum(cells) + baseCount * * private transient volatile CounterCell[] counterCells; */ if ((as = counterCells) != null || !U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) { //有几种情况进入到if中 // 1. true-> 表示cells 已经初始化了,当前线程应该去使用hash寻址找到合适的cell 去累加数据 // 2. true-> 表示写base失败,与其它线程在base上发生竞争,当前线程应该去尝试创建cells //a 表示当前线程hash寻址命中的cell CounterCell a; //v 表示当前线程写cell 时的期望值 long v; //m 表示当前cells 数组的长度 int m; //true-> 未竞争 false->发生竞争 boolean uncontended = true; //条件一:as == null || (m = as.length - 1) < 0 // 表示写base竞争失败,然后进入if块,需要调用fullAddCount进行扩容 或者重试 LongAdder.longAccumulate //条件二:(a = as[ThreadLocalRandom.getProbe() & m]) == null // 前置条件:cells已经初始化了, // true-> 表示当前线程命中的cell表格是个空,需要当前线程进入fullAddCount方法去初始化 cells,放入当前位置 //条件三:!(uncontended = U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x)) // false->取反得到false,表示当前线程使用cas方式更新当前命中的cell成功 // true-> 取反得到true,表示当前线程使用cas方式更新命中的cell失败,需要进入fullAddCount 进行重试或者扩容cells if (as == null || (m = as.length - 1) < 0 || //getProbe() 获取当前线程的hash值 (a = as[ThreadLocalRandom.getProbe() & m]) == null || !(uncontended = U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) { // 和LongAdder的 longAccumulate一样 fullAddCount(x, uncontended); //考虑到fullAddCount 里面的事情太多,就让当前线程不参与到扩容相关的逻辑了 return; } // check是 是否扩容的主要标识 // putVal方法中调用addCount时, 里面传进来的binCount = check // binCount >= 1 当前命中的桶位的链表的长度,是1时也可能代表key相同,发生冲突 // binCount == 0 当前命中的桶位是null,直接将节点放到桐中 // binCount == 2 桶位下已经树化 // remove() 方法中调用addCount时, 里面传进来的 check=-1 if (check <= 1) return; // 获取当前散列表的元素个数,期望值 s = sumCount(); } // 表示一定是一个put 操作调用的addCount (只有添加元素时才会扩容) if (check >= 0) { // tab 代表 map.table // nt 代表 map.nextTable /** * 扩容过程中,会将扩容中的新table 赋值给 nextTable 保持引用,扩容结束之后,这里会被设置为Null * private transient volatile Node<K, V>[] nextTable; */ // n 代表table 数组的长度 // sc 代表sizeCtl 的临时值 Node<K,V>[] tab, nt; int n, sc; /** sizeCtl < 0 * X 1. -1 表示当前table正在初始化(有线程在创建table数组),当前线程需要自旋等待.. * 可能 2. 表示当前mao正在进行扩容 高16位表示:扩容的标识戳 低16位表示:(1 + nThread) 当前参与并发扩容的线程数量 * * sizeCtl = 0 * X 表示创建table数组时,使用 DEFAULT_CAPACITY 为大小 * * sizeCtl > 0 * X 1.如果table 未初始化,表示初始化大小 * 可能 2.如果已经初始化,表示下次扩容时的 触发条件(阈值) */ // 自旋 // 条件一:s >= (long)(sc = sizeCtl) // true:1.当前sizeCtl 为一个负数,表示正在扩容中。 // 2.当前sizeCtl 是一个正数,表示扩容阈值 // false: 表示当前table 尚未达到扩容条件 // 条件二; (tab = table) != null 恒成立 // 条件三: (n = tab.length) < MAXIMUM_CAPACITY // 当前table长度小于最大值限制,则可以进行扩容 while (s >= (long)(sc = sizeCtl) && (tab = table) != null && (n = tab.length) < MAXIMUM_CAPACITY) { //当前扩容标识戳,之前讲过 //16 -> 32 标识戳:32768 int rs = resizeStamp(n); // 条件成立:当前table正在扩容 // 当前线程理论上应该协助table 完成扩容 if (sc < 0) { // 条件一:(sc >>> RESIZE_STAMP_SHIFT) != rs // true-> 说明当前线程获取到的扩容唯一标识戳 非 本次扩容 // false-> 说明当前线程获取到的扩容唯一标识戳 是 本次扩容 // 条件二:jdk1.8中有bug_jira:其实想表达的是:sc == (rs << 16) + 1 // true-> 表示扩容完毕,当前线程不需要再参与进来了 // false-> 扩容还在进行时,当前线程可以参与进来 // 条件三:jdk1.8中有bug_jira:应该是:sc == rs << 16 + MAX_RESIZERS // true-> 表示当前参与并发扩容的线程达到最大值 65535 - 1 // false-> 表示当前线程可以参与进来 // 条件四:(nt = nextTable) == null // true-> 表示本次扩容结束 // false-> 扩容正在进行 if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 || sc == rs + MAX_RESIZERS || (nt = nextTable) == null || transferIndex <= 0) break; // 前置条件:当前table 正在执行扩容中,当前线程有机会参与扩容 // 条件成立:说明当前线程成功参与到扩容任务中,并且将sc低16位加1,表示多了一个线程参与工作 // 条件失败:说明参与工作的线程比较多,cas修改失败,下次自旋 大概率还会来到这里 // 条件失败:1.当前很多线程都在此处尝试修改sizeCtl,有其它一个线程修成功,导致你的sc期望值与内存中的值不一致,修改失败 // 2.transfer 任务内部的线程也修改了sizeCtl if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) // 协助扩容线程,持有nextTable 参数 //在transfer 方法中,需要做一些扩容准备工作 transfer(tab, nt); } //RESIZE_STAMP_SHIFT = 16 // 1000 0000 0001 1011 0000 0000 0000 0000 + 2 // => 1000 0000 0001 1011 0000 0000 0000 0010 // 条件成立:说明当前线程是触发扩容的第一个线程,在transfer 方法中,需要做一些扩容准备工作 else if (U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2)) // 触发扩容条件的线程,不持有nextTable 参数 transfer(tab, null); // 再次获取当前散列表的元素个数,期望值,再次自旋 s = sumCount(); } } }
//求sum的一个方法,不是准确值,是期望值,因为其它线程可能还在写数据
//把cells求和,再加上base就是总和sum。
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
3、面试题:
1)ConcurrentHashMap1.8为什么要去除Segments分段锁?
① ConcurrentHashMap1.7需要计算两次index值;ConcurrentHashMap1.8只需要计算一次index值。
② ConcurrentHashMap1.7中Segments分段锁效率真的不高,所以只需对node节点上锁就行
2)为什么ConcurrentHashMap1.8使用Synchronized锁而不是用Lock锁?
① Lock锁不带自旋功能
② Synchronized锁自带自旋功能,且有锁的升级过程
3)ConcurrentHashMap1.8如何基于node节点实现锁机制?
index没有发生冲突使用cas,发生冲突则使用Synchronized锁。
4)区别?
① 数据结构:1.7数组+Segments分段锁+HashEntry链表;1.8数组+链表+红黑树(直接使用node存储数据)
② 锁的实现:1.7Lock锁+CAS + UNSAFE;1.8index没有发生冲突使用cas,发生冲突则使用Synchronized锁。
③ 扩容实现:1.7支持多个Segment同时扩容;1.8支持并发扩容。
16、JDK7的ConcurrentHashMap实现原理
ConcurrentHashMap将一个大的HashMap集合拆分成n多个不同的小的HashTable(Segment),默认的情况下是分成16个不同的Segment。每个Segment中都有自己独立的HashEntry<K,V>[] table(table数组)
17、ConcurrentHashMap为什么在构造函数初始化s0?
为了方便后期其他key落到不同segment中时,能够知道创建segment对象的加载因子、初始化容量大小为多少。
ConcurrentHashMap 底层是如何实现?
1.传统方式 使用 HashTable 保证线程问题,是采用synchronized 锁将整个HashTable 中的数组锁住, 在多个线程中只允许一个线程访问 Put 或者 Get,效率非常低,但是能够保证线程安全问题。 2.多线程的情况下 JDK 官方推荐使用 ConcurrentHashMap ConcurrentHashMap 1.7 采用分段锁设计 底层实现原理:数组+Segments 分段锁+HashEntry 链表实现 大致原理就是将一个大的 HashMap 分成 n 多个不同的小的HashTable 不同的 key 计算 index 如果没有发生冲突 则存放到不同的小的HashTable 中,从而可以实现多线程,同时做 put 操作,但是如果多个线程同时put 操作key 发生了 index 冲突落到同一个小的 HashTable 中还是会发生竞争锁。3.ConcurrentHashMap 1.7 采用 Lock 锁+CAS 乐观锁+UNSAFE 类里面有实现类似于 synchronized 锁的升级过程。 4.ConcurrentHashMap 1.8 版本 put 操作 取消 segment 分段设计直接使用Node数组来保存数据 index 没有发生冲突使用 cas 锁

 浙公网安备 33010602011771号
浙公网安备 33010602011771号