第五章 物理内存管理
第五章 物理内存管理
操作系统除了担负管理页表映射的职责外,还担负着管理物理内存资源的职责。
一方面,操作系统需要具备以物理页为粒度进行物理内存分配的能力。
另一方面,操作系统需要具备分配小内存区域的能力。
物理内存总是有限的,通过换页机制将物理内存的数据暂时迁移到磁盘等次级存储上的方式释放物理内存,间接增大了可用的物理内存。
5.1 操作系统的职责:管理物理内存资源
5.1.1 评价维度
操作系统的物理内存分配设计有两个重要的评价维度:
-
物理内存分配要追求更高的内存资源利用率。
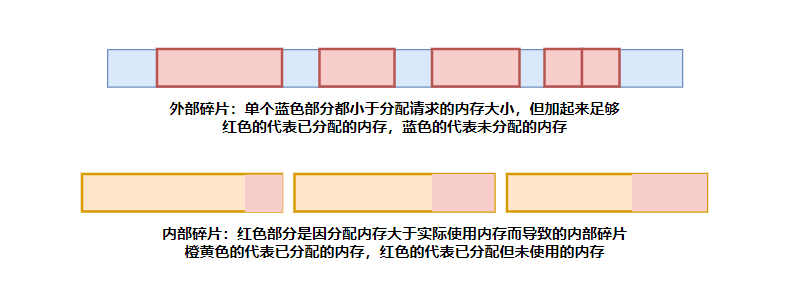
内存碎片:无法被利用的内存,直接导致内存资源利用率的下降。内存碎片又进一步被分为外部碎片和内部碎片。
外部碎片:外部碎片通常是在多次分配和回收内存之后产生,物理内存上空闲的部分处于离散分布的状态。
内部碎片:当分配的空间大于实际分配请求所需的空间时,就会造成部分内存的浪费。
-
物理内存分配器要追求更好的性能,尽可能降低分配延迟和节约 CPU 资源。
通过精密的算法细致地解决碎片问题固然能够有效提高内存资源利用率,但却带来高昂的性能开销
5.1.2 基于位图的连续物理页分配方法
操作系统可以通过如下方法实现物理页分配:
首先初始化一个位图(Bitmap),每一位对应一个物理页,若为 0 则表明相应的物理页空闲,反之则为已分配;在分配时查找位图,找到为 0 的位,分配相应的物理页,并且把该位设置为 1。
一种简单的连续物理页分配
// 共有 N 个 4K 物理页,位图中每一位对应一个页
bit bitmap[N];
void init_allocator(void) {
int i;
for (i = 0; i < N; i++) {
bitmap[i] = 0;
}
}
// 分配 n 个连续的物理页
u64 alloc_pages(u64 n) {
int i, j, find;
for (i = 0; i < N; i++) {
find = 1;
for (j = 0; j < n; j++) {
if (bitmap[i+j] != 0) {
find = 0;
break;
}
}
if (find) {
// 将找到的连续的物理页对应的位图设置为 1
for (j = i; j < i+n; j++) {
bitmap[j] = 1;
}
return FREE_MEM_START + i * 4K;
}
}
// 分配失败
return NULL;
}
// 释放 n 个连续的物理页
void free_pages(u64 n, u64 addr) {
int i, page_idx;
// 计算待释放的起始页索引
page_idx = (addr - FREE_MEM_START)/4K;
for (i = 0; i < n; i++) {
bitmap[page_idx + i] = 0;
}
}
这种简单的分配器在两个维度上均存在不足
- 分配时要查询整个位图,分配速度慢。
- 容易导致外部碎片问题。
5.1.3 伙伴系统原理
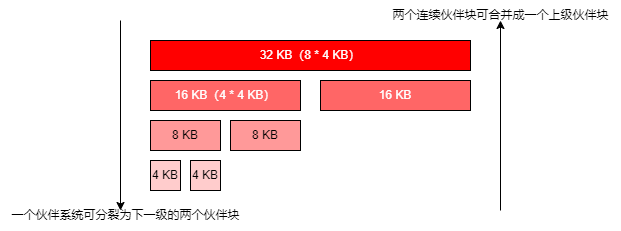
伙伴系统被广泛的用于分配连续的物理内存页,基本思想是将物理内存划分成连续的块,以块为单位进行物理内存的分配,不同块的大小可以不同,每个块都有一个或多个连续的物理页组成,物理页的数量必须是2的n次幂(可能是为了更好的找到伙伴快进行合并)
伙伴系统的基本思想:
当一个请求需要分配 m 个物理页时,伙伴系统寻找一个大小合适的块,该块包含 \(2^n\) 个物理页。且满足2^n-1 < m <= 2^n。在处理分配请求过程中,大的块可以分裂成两半,这两个块互为伙伴。分裂得到的块可以继续分裂,直到得到一个大小合适的块。在一个块被释放时,分配器会找到其伙伴块,若伙伴块也处于空闲的状态,则将两个伙伴块进行合并,形成更大的块,然后继续向上尝试合并。能够很好的缓解外部碎片问题。
通常使用空闲数组链表去实现伙伴系统,全局有一个有序数组,数组的每一项指向的是一条空闲链表,每条链表将其对应大小的空闲块连接起来(一条链表中的空闲块大小相同)。
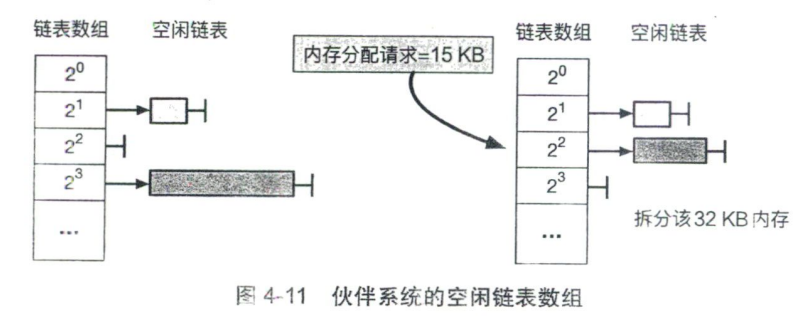
在图中要分配一个 15KB 的空间,需要 4 个(4*4KB = 16KB)个物理页,也就是图中数组索引为 2 对应的链表,发现是空,就在索引为 3 的数组中找到空闲区间,进行分裂,分裂为两个 16KB 的块,其中一个用于满足内存分配请求,另外一个连接到索引为 2 的链表中。
寻找伙伴系统比较有效一个重要原因:确定一个伙伴块非常简单。互为伙伴的两个快的物理地址仅仅有一位不同,且该位由块大小决定块 A(0~8 KB)和块 B(8 KB~16 KB)互为伙伴块,物理地址分别为 0x0,0x2000,仅由第 13位不同,而块大小是 8 KB(2^13)。
5.1.4 案例分析:ChCore 中伙伴系统的实现
查看《操作系统:原理与实现》书籍
5.1.5 SLAB 分配器的设计
引入 SLAB 分配器的原因:
伙伴系统最小的分配块的大小是 4 KB,在大多数情况下,内核需要分配的内存大小通常是几十字节或几百个字节,远远小于一个物理页的大小。仅仅使用伙伴系统进行内存的分配,会出现严重的内部碎片问题,从而导致内存资源的利用率降低。所以,研究人员就引入了另外一套内存分配气质用于分配小内存,也就是SLAB机制。
SLAN 分配器的发展:
Solaris 2.4 操作系统设计并实现了 SLAB 分配器,但是维护了太多的队列、实现日趋复杂、存储开销也由于复杂的设计而增大。于是,在 SLAB 的基础上设计了 SLUB 分配器。SLUB 能够在降低复杂度的同时提供与 SLAB 相当甚至更好的性能。SLOB 分配器主要为了满足内存资源稀缺场景的需求,具有较小的存储开销,但在碎片问题的处理方面比不上 SLAB 和 SLUB。
SLUB 分配器的设计思路:
SLUB 分配器主要数据结构示意图
SLUB 是为了满足操作系统频繁的分配小内存的需求,依赖于伙伴系统进行物理页的分配。简单来讲,就是将伙伴系统分配的大块内存进一步细分成小块内存进行管理。
SLUB 分配器只分配固定大小的内存块,块大小通常是 2^n 个字节(一般来说,3 <= n < 12)。对于每一种块大小,SLUB 分配器都会使用独立的内存资源池进行分配。
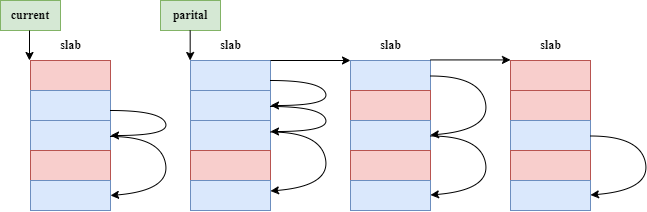
SLUB 分配器向伙伴系统申请一定大小的物理内存块(一个或多个连续物理页)作为内存资源池。将获得的物理内存块作为一个 slab。slab 会被划分成等长的小块内存,其内部空闲的小块内存会被组织成空闲链表的形式。一个内存资源池通常还有 current 和 parital 两个重要指针。current 指针仅指向一个 slab ,所有的分配请求都将从该指针指向的 slab 中获得空闲内存块。partial 指针指向由所有拥有空闲块的 slab 组成的链表。
当 SLUB 分配器接收到一个分配请求时,它首先定位到能满足请求大小且大小最接近的内存资源池,然后从 current 指针指向的 slab 中拿出一个空闲块返回即可。如果 current 指针指向的 slab 在取出一个空闲块后,该 slab 不再拥有空闲块,即全部分配完,则从 partial 指针指向的链表中取出一个 slab 交给 current 指针。如果 partial 指针指向的链表为空,那么 SLUB 分配器就会向伙伴系统申请分配新的物理内存作为新的 slab。
当 SLUB 分配器接收到一个释放请求时,它将被释放的块放入相应 slab 的空闲链表中。如果该 slab 原本已经没有空闲块,即全部分配完,则将其重新移动到 partial 指针指向的链表中;如果该 slab 变为所有内存块都是空闲的,即原来仅分配出去一块,那么可以将其释放,还给伙伴系统。至于如何找到释放块所属于的 slab,则可以通过在slab 头部加人元数据并且使得 slab 头部具有对齐属性等方式来实现。
5.1.6 常用的空闲链表
除了上述伙伴系统和 SLAB 分配器外,还有其他基于不同空闲链表的内存分配方法。这些方法不仅可以用在内核态,也可以用在用户态的内存分配器中,比如堆分配器。
空闲链表的内存分配在用户态分配器中常被用到。
内存分配器中常用的三种空闲链表:
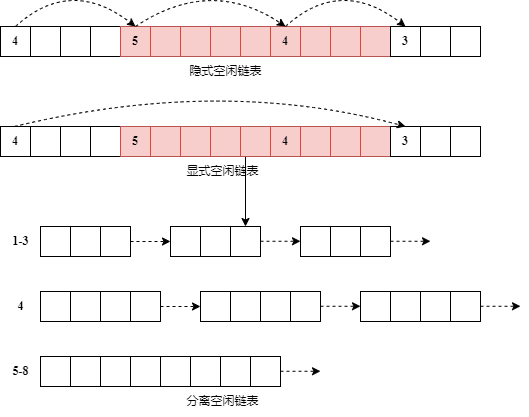
-
隐式空闲链表
如图所示,链表中的每个元素代表了一块内存区域,空闲(白色)和非空闲(彩色)的内存块混杂在同一条链表里。每个内存块头部存储了关于该块是否空闲、块大小信息,通过块大小可以找到下一个块的位置。在分配的时候,在链表中依次查询,直到找到合适的大小,如果分配之后的内存块还有余量,则将剩下的余量作为新的内存块加入链表中。在释放内存块时,会检查前后的内存块是否空闲,如果空闲则合并。
-
显示空闲链表
显示链表仅仅将空闲内存块通过链表链接起来。每个内存块头部除了存放块大小、维护两个指针(prev 和 next)分别指向前后空闲块。分配空间的过程和隐式空闲链表相似。显示链表在分配速度上更具有优势,因为分配时间与空闲块的数量成正比,隐士链表则与所有快成正比
-
分离空闲链表
在显示链表的基础上构建的,通过维护多条显示链表,每条链表服务固定范围大小的分配请求。相比于普通的显示空闲链表,能够获得更好的性能,分配空闲块所需要的时间会更小,多条链表可以更好的支持并发操作。
5.2 操作系统如何获得更多物理内存资源
5.2.1 换页机制
被分配使用的虚拟页在页表中一定有相应的物理页映射吗?
并不是
场景1:操作系统应该如何使用虚拟内存抽象使得只有4GB内存的电脑能够同时运行两个总共需要5 GB内存的空间?
场景2:开发人员预先不知道程序占用多少内存空间,于是向操作系统申请了足够大的虚拟内存,大部分的虚拟页最终都不会被用到。操作系统应该如何利用虚拟内存抽象做到根据实际使用情况分配珍贵的物理内存资源?
换页机制是为满足上述场景所涉及的,该机制基本思想是当物理内存容量不够时,操作系统应该把若干物理页的内容写到类似于磁盘这种容量更大且更加便宜的存储设备中,然后就可以回收这些物理内存并继续使用了。
操作系统需要将物理页上的内容写入磁盘上的一个位置,并在页表中将相应的映射删除,同时记录该物理页被换到了磁盘上的那个位置,以上过程称为物理页的换出。
当应用程序访问被换出到磁盘上的物理页对应的虚拟地址时,会发生缺页异常,缺页异常函数判断该虚拟地址属于合法的虚拟地址范围,且对应的物理页被换出。因此,会分配一个空闲的物理页,将之前换出到磁盘上的内容重新写入到空闲物理页中,并在页表中添加相应的映射。这个过程称为换入。
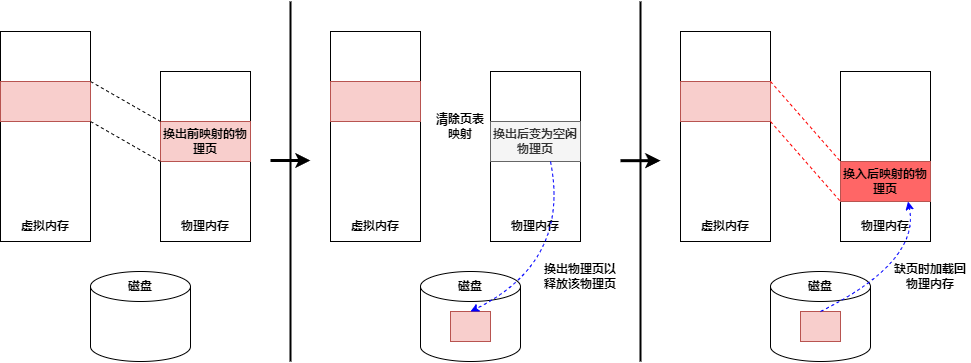
利用换页机制,操作系统可以将物理内存中放不下的内容存放到磁盘中,等到需要的时候再放回物理内存中,从而能在不修改应用进程的前提下提供超出物理内存实际容量的内存空间。
操作系统是用完所有物理页后才进行换页吗?
这样的策略在理论上是可以的,但是在内存资源紧张时,可能导致许多物理页分配操作都需要先进行换页,从而造成分配时延高的问题。
操作系统设置三个阈值:高水位线(High Watermark)、低水位线(Low Watermark)、最小水位线(Min Watermark)。
当空闲物理页小于低水位线时,则择机进行换页操作,目标是把空闲物理页数量恢复到高水位线;当空闲物理页数量低于最小水位线时,则立即进行换页操作,且是批量操作。
换页机制使得操作系统能够获取更多的物理内存资源,是否牺牲了什么作为代价?
换页之后,应用进程再次访问该页时会发生缺页异常,需要将物理页内容从磁盘中加载到内存中。磁盘操作是耗时的,应用进程的执行时间就会增加,往往意味着应用性能的下降。
有什么方法能减少因换页机制带来的性能损失吗?
可以使用预取机制。可以利用时空局部性来改善该问题。在缺页处理函数中采用预取机制,发生缺页异常时,将临近的虚拟页也进行映射,从而减少缺页异常的次数。
由于延迟映射同样会引起缺页异常,操作系统如何判断页表中没有映射是由于按需页面分配导致的还是换页导致的呢?
操作系统需要标记进程中那些虚拟页被换出以及换出的位置,若未被标记则说明尚未为该虚拟页分配物理页。一种高效的实现方法是:在页表项中做标记。
5.2.2 页替换策略
当需要进行换页时,操作系统将根据页替换策略选择一个或一些污了页换出到磁盘以便让出空间。
页替换策略是依据硬件提供的页访问信息,猜测那些页应该被换出,从而最小化缺页异常的发生次数以提升性能。
MIN 策略/OPT 策略
在选择换出页时,优先选择未来不会再访问的页,或者最长时间不会再访问的页。
是理论上最优的页替换策略,但在实际场景中很难被实现。
它经常作为一个标准,来衡量其他的页替换策略的效果。
FIFO 策略
最简单的页替换策略之一。
优先选择最先换入的页进行替换。
操作系统维护一个队列用于记录换入内存的物理页号,每换入一个物理页就将其页号加入到队列尾部。队列头部就是最先换入的内存页了。当需要换出时,总是选择队列头部的物理页。
Second Chance 策略
是FIFO 策略的一种改进版本。
同样需要一个队列来记录换入的物理页号,此外,还有为每一个物理页号维护一个访问标志位。
如果访问的页号已经在队列中了,则置上其访问标志位。
在要换出页时,查看队列头部的页,标志位有两种情况
- 如果它的访问标志位没有被置上,则换出该页号对应的内存页。
- 如果它的访问标志位被置上了,则将该页号移动到队列尾部,重新判断队列头部的页。
一般来说 Second Chance 策略是要优于 FIFO 策略的,当队列中所有的访问标志位都被置上时,就会退化为 FIFO 策略了。
LRU 策略
在选择被换出的页时,优先考虑,最久没有被访问的页。
该策略出发点:过去数条指令频繁访问的页很可能在后续的数条指令中也被频繁访问。
实现方法:操作系统维护一个链表,按照内存页的访问顺序,插入到链表中;每次访问后,操作系统将刚刚访问的内存页号移动到链表尾部,每次选择换出位于链表首端的页。
MRU 策略
该策略和 LRU 策略刚好相反,在替换内存页时,优先换出最近被访问的内存页
随机替换策略
操作系统会任意挑选一个物理页面进行换出,该策略的好处在于不需要维护页面的访问信息,不过相比于 LRU 等策略一般会引发更多的缺页。
5.2.3 页表项中的访问位与页替换的实现
对于大多数页替换策略而言,操作系统都需要获得物理页是否被访问的信息,通常的实现是根据硬件自动设置的页表项中的访问位(比如 Access Flag 和 Dirty State)来判断物理页是否被访问过。由于硬件是在地址翻译的过程中设置页表项中的访问位,所以操作系统需要维护物理页和页表项之间的关系,才能够通过页表项获取物理页是否被访问过的信息。
反向映射机制
Linux 操作系统通过反向映射(Reverse Mapping)机制记录物理页对应页表项。
5.2.4 工作集模型
在选择和实现页替换策略时,操作系统的原则时以最小的开销达到尽可能接近 MIN 替换策略的效果。
如果选择的页替换策略和实际的工作负载不相匹配,那么就有可能产生颠簸现象。
颠簸现象:大部分的 CPU 的时间都被用来处理缺页异常以及等待缓慢的磁盘操作,而仅剩小部分的时间用于完成真正有意义的工作。
工作集模型能够有效的避免颠簸现象的发生。
工作集模型:一个应用程序在时刻 t 的工作集 W 为它在时间区间 [t-x, t] 使用的内存页集合,也被视为它在未来(下一段x时间内)会访问的内存页集合。
如何高效的追踪工作集?
工作集时钟算法:操作系统设置一个定时器,每经过固定的时间间隔,一个设置好的工作集追踪函数就会被调用。
该追踪函数为每个内存页维护两个状态:上次使用时间和访问位均被初始化为 0。每次被调用,该函数都会检查每个内存页的状态。
- 如果访问位是 1,则说明在此次时间间隔内该页被访问过,于是该函数会把当前系统时间赋值给该内存页的上次使用时间。该方法的前提是 CPU 硬件会在程序访问某个页的时候自动地将对应的访问位设置成 1。
- 如果访问位是0,则说明在此次时间间隔内该页没有被访问,于是该函数会计算该页的年龄(当前系统时间-该页的上次使用时间)。若该页的年龄超过预设的时间间隔 x,则它不再属于工作集。检查完一个页的状态之后,工作集追踪函数将其访问位设置为0。
5.2.5 利用虚拟内存抽象节约物理内存资源
内存去重
操作系统定期的在内存中扫描具有相同内容的物理页,并且找到映射到这些物理页的虚拟页;然后只保留其中一个物理页,并将具有相同内容的其他虚拟页都用写时拷贝的方式映射到这个物理页,然后释放其他物理页以供将来使用。
Linux 操作系统就实现了该功能,成为 KSM(Kernel Same-page Merging)。内存去重会对应用进程访存时延造成影响,当应用程序写一个被去重的内存页时,既会触发缺页异常,又会导致内存拷贝,从而可能造成性能下降。
内存去重的安全问题
一种简单的攻击是:攻击者可以在内存中通过穷举的方式不断构造数据,然后等待操作系统去重,再通过访问时延是否变长来窃取数据。比如假设攻击者知道某个进程在内存中保存了一个变量 secret,但不知道这个变量的值。于是攻击者首先构造一个除了变量secret外其他都一样的内存页,然后不断改变该变量的值,并记录访问该变量的时间,若时延突然变长,说明这个页发生了去重,即表示猜对了 secret 的值。
防御方法:操作系统仅在同一用户的应用进程内存之间进行内存区重,从而使得攻击者无法猜测到别的用户应用进程中的数据。
内存压缩
当物理内存不充足时,操作系统会选择一些“最近不太会使用”的内存页,压缩其中的数据,从而释放更多空闲内存。当应用程序访问被压缩的数据时,操作系统将其解压即可,所有操作都在内存中完成。相比于换出内存数据到磁盘中,速度更快。
Linux 系统支持的 zswap 机制采用了内存压缩。
5.3 性能导向的内存分配机制
5.3.1 物理内存与 CPU 缓存
相比于 CPU 执行的速度,内存访问速度是非常缓慢的:一条算术运算指令可能只需要一个或几个时钟周期即可完成,而一次内存访问则可能需要花费上百个时钟周期。如果每条内存读写指令都需要通过总线访问物理内存,那么 CPU 与物理内存之间的数据搬运可能成为显著的性能瓶颈。
为了降低访存的开销,现代 CPU 内部通常包含 CPU 缓存,用于存放一部分物理内存中的数据。
访问 CPU 缓存一般最快只需要几个时钟周期 。
缓存结构
CPU 缓存中包含若干条缓存行和每条缓存行相应的状态信息。后者包括:一个有效位用于表示该缓存行是否有效,一个标记地址标识给缓存行对应的物理地址,以及一些其他信息。
CPU 是如何在 CPU 缓存中查找数据的呢?
CPU 通过 MMU 翻译后的物理地址查找缓存,物理地址在逻辑上分为 Tag、Set(也称为 Index)以及 Offset 三段。
组(Set)与路(Way)是 CPU 缓存的经典概念。
物理地址的 Set 段能表示的最大数目称为组。
每组中支持的最大缓存行数目(最多的 Tag 数)称为路。
在 Set 相同的情况下,缓存最多支持 4 个不同的 Tag,也就是 4 路,该 CPU 缓存被称为 4 路组相联。
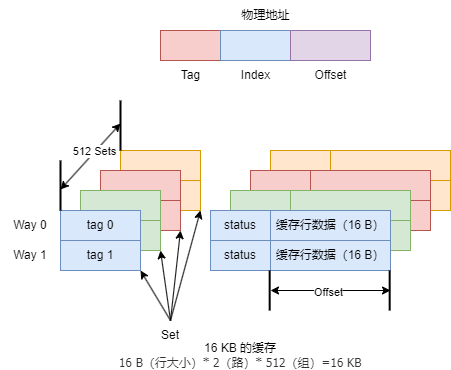
缓存寻址
以 Cortex-A57 CPU 的 L1 数据缓存为例,介绍 CPU 缓存查找的一般过程。CPU 缓存相关的参数:
- 物理地址长度 44 位。
- 缓存大小为 32 KB,缓存行大小为 64 字节。
- 256 组,2 路组相联缓存。
\(64 * 2 * 256 = 32768\)。32768 B = 32 KB
假设要读取以物理地址 0x2FBBC030 开始的 4 个字节的物理内存数据。
0010 1111 1011 1011 1100 0000 0011 0000
Offset 的值:11 0000 = 0x30
Set 的值:00 0000 00 = 0x0
Tag 的值:00 1011 1110 1110 1111 = 0xBEEF
根据 Set 定位到 Set = 0 的两个缓存行,对比 Tag 并且检查 Valid 是否为 1(表示该缓存行有效),即可进一步根据 Offset 进行访问。
CPU 缓存行何时写回物理内存?
- 存在专门的硬件指令负责写回某缓存行
- 若某组中的缓存行状态都为有效状态且被修改过,而 CPU 需要在该组中加载新的缓存行进行读写,此时 CPU 会首先选择该组中已有的某缓存行写回物理内存(空出一个缓存行)
5.3.2 物理内存分配与 CPU 缓存
相比于物理内存,CPU 缓存要小得多。
操作系统可以根据 CPU 缓存的特点,优化为应用分配物理页的策略,从而更好的利用缓存以提升应用性能。
操作系统开发者提出了一种称为缓存着色的内存染色机制。
该机制的基本思想:把能够被存放到缓存中不同位置(不造成缓存冲突)的物理页标记上不同的颜色,在为连续内存页分配物理页面的时候,优先选择不同颜色的物理页面进行分配。
5.3.3 多核与内存分配
多核 CPU 包含多个核心,不同的应用可以在不同核心上同时运行,由于应用进程可能在不同 CPU 核心上同时发起需要在操作系统中分配内存的系统调用,操作系统可能会在不同 CPU 核心上同时调用 SLAB 内存分配接口。
为了防止重复分配同一块内存,一种可行的方式是只允许一个 CPU 核心调用 SLAB 内存分配接,在分配完成后才允许下一个 CPU 核心发起调用请求(每个 CPU 核心先获取一把锁才能进行内存分配,分配完成后释放锁,而锁的持有者至多只有一个 CPU 核心)。该方式会导致性能下降的问题:当多个 CPU 核心同时需要调用内存分配接口时,实际上每次只有 CPU 核心在执行分配操作,而其余 CPU 核心都需要等待它分配结束,多核 CPU 的优势就没有体现。
为了满足操作系统在多个 CPU 核心上同时进行内存分配的需求,操作系统开发人员提出了一种为每个 CPU 核心建立内存分配器的设计。
5.3.4 CPU 缓存的硬件划分
在多核 CPU 中,CPU 缓存通常分成多级,每个 CPU 核心拥有私有的 CPU 缓存(例如,L1,L2 缓存),而所有的 CPU 核心会共享最末级 CPU 缓存。
不同的应用进程会竞争最末级的 CPU 缓存,有可能由于互相影响导致应用进程产生性能抖动。
近年来硬件厂商也开始通过相关硬件特性使得操作系统能够更加灵活的分配 CPU 缓存资源。
Intel CAT
Inte 缓存分配技术允许操作系统设置应用程序所能使用的最末级缓存的大小和区域,从而实现最末级缓存资源在不同应用程序间的隔离。
CAT 提供若干个服务类(Class of Service, CLOS)并允许通过设置寄存器的方式把应用程序划分到某个 CLOS。每个 CLOS 有一个容量位掩码(Capacity Bitmask, CBM),标记着该 CLOS 能够使用的最末级缓存资源。
不同的 CLOS 对应的缓存资源既可以是完全隔离的,也可以是部分重合的。
ARMv8 MPAM
MPAM(Memory System Resource Partitioning and Monitoring, MPAM)支持配置多个分区 ID(Partition ID, PARTID),并可限制每个 PARTID 能够使用的缓存资源。操作系统可以把应用进程划分到某个 PARTID,从而限制该应用进程能够使用的缓存资源。
MPAM 支持两种缓存划分方案
- 缓存局部划分:同样使用位图按比例划分属于不同 PARTID 的可用缓存资源。
- 缓存最大容量划分:通过配置 MPAMCFG_CMAX 寄存器的值来设定一个 PARTID 能够使用的最大缓存资源比例。
如图所示:
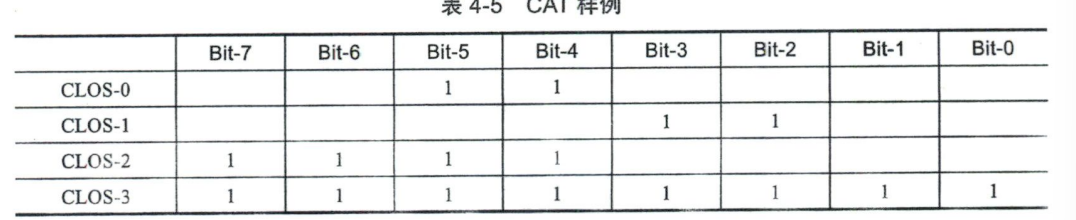
CLOS-0 和 CLOS-1 只能使用 25% 的最末级 CPU 缓存资源,且 CLOS-0 和 CLOS-1 之间的最末级 CPU 缓存资源是相互隔离的。CLOS-2 能使用 50%,CLOS-3能够使用100%
5.3.5 非一致内存访问
随着单处理器中核心数量的增多以及多处理器系统的出现,单一的内存控制器逐渐成为性能的瓶颈。因此,多核及多处理器系统将多个内存控制器分布在不同的核心或处理器上。
每个处理器被分配一个单独的内存分配器,每个核心可以通过本地的内存控制器快速访问本地内存,也可以通过远端的内存控制器访问远端内存。但访问远端内存的时延将远高于访问本地内存的时延。
这种由于本地和远端内存而导致访存时延不同的架构被称为非一致内存访问(Non-Uniform Memory Access, NUMA)。
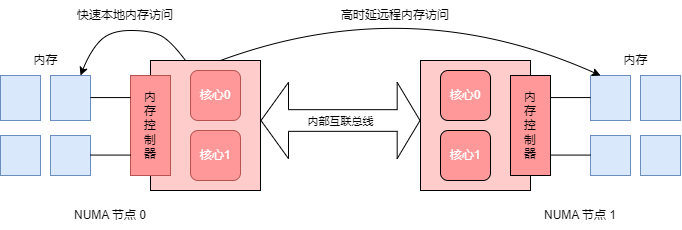
如上图所示,一个节点中的任意核心能够快速的访问本节点的本地内存。一旦其需要访问远端其他节点的内存,则需要通过互联总线与远端节点通信。
NUMA 架构有多种组成方式,一个 NUMA 节点可以是一个物理处理器,也可以是处理其中的一部分核心。
5.3.6 NUMA 架构与内存分配
在 NUMA 架构下,尽可能使得应用进程中的访存操作均是访问本地内存,避免因频繁的远程内存访问而造成严重的性能问题。
现代操作系统一般采用两种策略来进行优化。
- 操作系统可以为上层应用提供 NUMA 感知的内存分配接口,让上层应用显式的分配内存所在位置。
- 对于没有显示使用这些接口的应用,操作系统需要根据当前线程运行的节点,尽可能将内存分配在本地节点,从而避免远程内存访问。
在 Linux 中,针对 NUMA 提供了三种内存分配模式:
- 绑定模式:从指定的 NUMA 节点上分配内存。
- 优先模式:从指定的 NUMA 节点上分配内存失败时,尝试从指定节点最近的节点上分配内存
- 交错模式:从应用给定的节点中以页尾粒度交错的分配内存。
默认选用优先模式。
Linux 提供了libnuma 库,numa_alloc_onnode 接口在指定的 NUMA 节点上分配固定大小的内存,numa_alloc_local 用于本地节点分配内存,numa_alloc_interleaved 用于使用交错模式分配内存。以上接口分配的内存均需使用 numa_free 接口进行释放。
如下代码所示:用不同的方式分配处理器中的内存。
#define _GNU_SOURCE
#include <stdio.h>
#include <sched.h>
#include <numa.h>
int main() {
int cpu = sched_getcpu();
int node = numa_node_of_cpu(cpu);
printf("cpu node: %d and numa node %d\n", cpu, node);
int *memo_0 = numa_alloc_onnode(sizeof(int), node);
int *memo_1 = numa_alloc_local(sizeof(int));
int *memo_2 = numa_alloc_interleaved(sizeof(int));
*memo_0 = 0, *memo_1 = 1, *memo_2 = 2;
numa_free(memo_0, sizeof(int));
numa_free(memo_1, sizeof(int));
numa_free(memo_2, sizeof(int));
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号