【pytest】case多执行慢?pytest-xdist分布式测试,了解一下
随着自动化项目开展逐步深入,case也会越写越多。那么随之而来的问题,就是case的运行时长越来越久了。
此问题属于必须解决的那种,本着拿来主义思想,有现成的绝不自己造(其实我也不费造),我们自然能搜索
到解决办法,而pytest-xdist就是其中之一,先附上地址。
pytest-xdist是一个pytest分布式测试插件,通过它的拓展,我们的pytest又有了新的能力:
- 并行运行测试:当你有多个cpu或主机,可以利用它们进行组合来运行测试。
- --looponfail:在子进程中重复运行测试。每次运行之后,pytest都会等待项目中的文件发生更改,然后重新运行之前失败的测试。
重复此操作,直到所有测试通过,然后再次执行完整运行。 - 多平台覆盖:可以指定不同的Python解释器或不同的平台,并在这些平台上并行运行测试。
上述3点是官方的一个介绍,后面2点暂时可以不用去关注它,最重要的是第一点,有了它就可以进行分布式的运行测试用例。
一、安装
- 安装很简单,pip命令:
pip install pytest-xdist - 如果你想看到可用的cpu数量,可以再装一个额外的插件psutil:
pip install pytest-xdist[psutil]
二、使用命令参数
要执行分布式运行,在运行命令后加参数即可。
pytest -n NUMCPUS,这里的NUMCPUS就是使用的cpu数量。pytest -n auto,如果传auto的话,它会自动检测系统的cpu数量,并且用来运行测试。
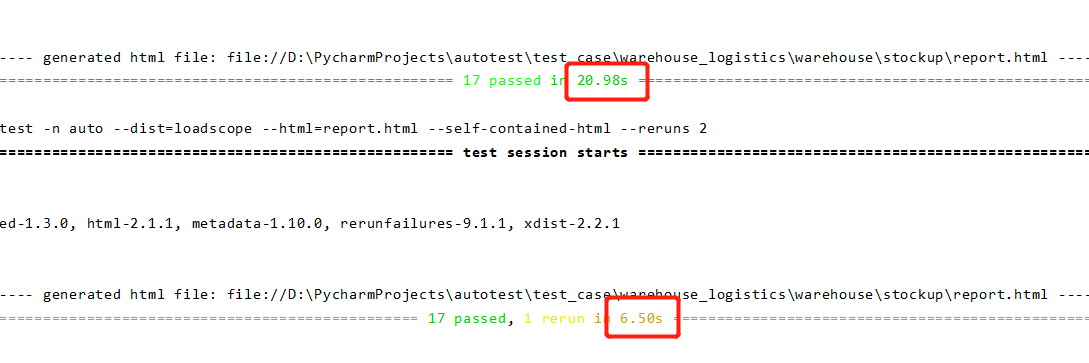
这是我使用下来的对比效果,在不用分布式的执行下,运行花费了20s,而利用分布式运行后只用了6.5s,提升效果
非常显著。目前我们的项目case有300多条,运行下来的时间在70s左右。
另外,对于自动化用例的运行,我们其实还要注意持续观察运行的结果,找出那些运行时间偏长的测试用例,然后分析问题,针对性的进行优化,
进一步的提高运行效率。
三、pytest-xdist运行顺序
在默认情况下,-n指令运行测试用例是随机的,不按某种顺序来运行。
这也是我写自动化用例所提倡的,那就是任何case都可以单独运行,随机运行,互不影响。这样的话,在使用分布式的时候,就不会有其他
case之间依赖不能运行的问题。
当然了,xdist也提供了2种顺序运行的模式:
--dist loadscope:可以按测试模块或测试类进行分组,可以让同组的case在同一个进程中运行。如果两者同时存在,那么类分组优先与模块分组。--dist loadfile:可以按文件分组,保证了同一个文件中的所有测试用例在同一个进程中运行。
如果觉得每次在命令行里带参数太麻烦了,也可以把参数加到到配置文件pytest.ini里:
[pytest]
addopts = -nauto --dist=loadfile
四、关于scope是session的fixture函数的处理
其实pytest-xdist的设计是能让每个运行进程执行自己集合下的所有测试用例。如果你的代码里有一个fixture函数scope='session',
那么,在不同进程中,这个fixture函数会被多次执行,这个动作就与scope='session'的作用产生了冲突。
虽然pytest-xdist没有内置的方法来使这样的fixture函数只执行一次,但可以通过使用锁文件来实现进程间通信。
这里官方提供了一段代码示例,大家可以了解一下:
import json
import pytest
from filelock import FileLock
@pytest.fixture(scope="session")
def session_data(tmp_path_factory, worker_id):
if worker_id == "master":
# not executing in with multiple workers, just produce the data and let
# pytest's fixture caching do its job
return produce_expensive_data()
# get the temp directory shared by all workers
root_tmp_dir = tmp_path_factory.getbasetemp().parent
fn = root_tmp_dir / "data.json"
with FileLock(str(fn) + ".lock"):
if fn.is_file():
data = json.loads(fn.read_text())
else:
data = produce_expensive_data()
fn.write_text(json.dumps(data))
return data
这里的filelock也是一个第三方库,它可以在Python中实现独立于平台的文件锁定,提供了一种简单的进程间通信方式。
代码想表达的意思大概是:
- 在第一次执行fixture函数的时候,产生的数据会存到FileLock的锁文件中
- 其他进程则会直接从文件中读取数据。
这个用法,暂时我还没有实践,但是给了我提示,我一直想优化一下我的数据库初始化,或许用这个方法可以试试,届时再分享。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号