20242118 《Python程序设计》综合实践报告(实验四)
2024-2025-2 202422118《Python程序设计》综合实践报告(实验四)
课程:《Python程序设计》
班级:2421
姓名:符馨琰
学号:20242118
实验教师:王志强老师
实验日期:2025年6月9日
必修/选修:公选课
一、选题
作为一个影迷,我经常会有一些问题,例如让我熬夜刷完的高分神作,靠的是什么去征服观众?又或者一般好电影和火爆的商业电影在评论上有什么主要差异?这次我想尝试用Python工具,给一部分豆瓣电影做一个“扫描”。
二、实验目的
1.寻找数据价值
通过分析豆瓣Top100电影的高评分数据与用户评论,探究优质电影的共同特征及其与用户评价的关系。2.可视化技术应用
运用Python数据可视化工具,实现专业的数据图表呈现,验证可视化技术在影视数据分析中的实用价值。
2.模型验证
采用SnowNLP情感分析算法处理中文短评,评估模型这一领域的分析准确性。
3.完整数据分析流程实践
从数据采集(爬虫)、清洗、分析到可视化呈现,建立完整的数据分析案例,验证Python数据分析技术的工作效能。
三、实验过程
1.环境配置
通过requirements.txt列出所有依赖包
使用pip安装Python依赖包
2.编写代码
爬虫
`import requests
import time
import random
import re
import csv
import os
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Referer': 'https://movie.douban.com/',
'Connection': 'keep-alive'
}
base_url = 'https://movie.douban.com/top250'
comment_url = 'https://movie.douban.com/subject/{}/comments?start={}&limit=20&status=P&sort=new_score'
def get_page(url):
"""获取页面内容"""
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except Exception as e:
print(f"Error fetching page {url}: {e}")
return None
def parse_movie_list(page):
"""解析电影列表页面"""
movies = []
soup = BeautifulSoup(page, 'html.parser')
movie_list = soup.select('ol.grid_view li')
for movie in movie_list:
try:
movie_info = {}
movie_info['rank'] = movie.select_one('.pic em').text
title_element = movie.select_one('.title')
movie_info['title'] = title_element.text
movie_info['url'] = movie.select_one('.hd a')['href']
movie_info['id'] = re.search(r'subject/(\d+)/', movie_info['url']).group(1)
movie_info['rating'] = float(movie.select_one('.rating_num').text)
info_text = movie.select_one('.bd p').text.strip()
info_parts = info_text.split('\n')
if len(info_parts) >= 2:
movie_info['director_actors'] = info_parts[0].strip()
movie_info['year_country_type'] = info_parts[1].strip()
# 提取年份
year_match = re.search(r'(\d{4})', movie_info['year_country_type'])
movie_info['year'] = int(year_match.group(1)) if year_match else None
quote = movie.select_one('.quote .inq')
movie_info['quote'] = quote.text if quote else ""
movies.append(movie_info)
except Exception as e:
print(f"Error parsing movie: {e}")
return movies
def get_comments(movie_id, count=100):
"""获取电影短评"""
comments = []
for start in range(0, count, 20):
url = comment_url.format(movie_id, start)
page = get_page(url)
if not page:
continue
soup = BeautifulSoup(page, 'html.parser')
comment_items = soup.select('.comment-item')
for item in comment_items:
try:
comment = {}
comment['author'] = item.select_one('.comment-info a').text
rating_element = item.select_one('.rating')
comment['rating'] = rating_element['title'] if rating_element else "无评分"
comment['time'] = item.select_one('.comment-time').text.strip()
comment['content'] = item.select_one('.short').text.strip()
comments.append(comment)
except Exception as e:
print(f"Error parsing comment: {e}")
if len(comments) >= count or len(comment_items) < 20:
break
time.sleep(random.uniform(3, 5))
return comments[:count]
def crawl_movies():
"""爬取豆瓣Top100电影及其评论"""
# 创建保存数据的目录
if not os.path.exists('douban_data'):
os.makedirs('douban_data')
all_movies = []
all_comments = []
# 爬取电影列表(4页,每页25部电影)
for page in range(4):
url = f"{base_url}?start={page * 25}&filter="
page_content = get_page(url)
if page_content:
movies = parse_movie_list(page_content)
all_movies.extend(movies)
print(f"已爬取第{page + 1}页电影列表,当前共{len(all_movies)}部电影")
time.sleep(random.uniform(1, 3))
# 保存电影基本信息
with open('douban_data/movies.csv', 'w', encoding='utf-8', newline='') as f:
writer = csv.DictWriter(f, fieldnames=['rank', 'title', 'id', 'rating', 'director_actors', 'year_country_type',
'year', 'quote', 'url'])
writer.writeheader()
writer.writerows(all_movies)
# 爬取每部电影的评论
for movie in all_movies:
movie_id = movie['id']
movie_title = movie['title']
print(f"正在爬取电影《{movie_title}》的评论...")
comments = get_comments(movie_id, 100)
# 保存单部电影评论到CSV文件(只包含评论基本信息)
filename = f"douban_data/comments_{movie_title}.csv"
with open(filename, 'w', encoding='utf-8', newline='') as f:
writer = csv.DictWriter(f, fieldnames=['author', 'rating', 'time', 'content'])
writer.writeheader()
writer.writerows(comments)
# 为汇总文件添加电影信息到评论中
for comment in comments:
comment['movie_title'] = movie_title
comment['movie_id'] = movie_id
comment['movie_rating'] = movie['rating']
all_comments.extend(comments)
print(f"已保存电影《{movie_title}》的{len(comments)}条评论")
time.sleep(random.uniform(3, 5))
# 保存所有评论到一个文件
with ope
print("数据已保存到 douban_data 目录")
if name == "main":
main()`
①爬取电影基本信息
目标网址:https://movie.douban.com/top250
爬取内容:电影排名、电影标题、豆瓣ID、评分、导演和主演、年份和国家和类型、上映年份、电影短评。
②爬取每部电影的短评
评论作者、评分、评论时间、评论内容。
③防反爬机制
随机延迟:爬取电影列表时,延迟 1-3秒;爬取评论时,延迟 3-5秒。
④异常处理
如果请求失败或解析出错,会打印错误信息并继续执行。
数据分析
`import matplotlib.pyplot as plt
import pandas as pd
import jieba
from wordcloud import WordCloud
from snownlp import SnowNLP
from collections import Counter
import numpy as np
import csv
import os
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
def load_data():
if not os.path.exists('douban_data/movies.csv') or not os.path.exists('douban_data/all_comments.csv'):
print("数据文件不存在,请先运行爬虫程序!")
return None, None
movies = []
with open('douban_data/movies.csv', 'r', encoding='utf-8') as f:
reader = csv.DictReader(f)
for row in reader:
row['rating'] = float(row['rating'])
if row['year']:
row['year'] = int(row['year'])
movies.append(row)
comments = []
with open('douban_data/all_comments.csv', 'r', encoding='utf-8') as f:
reader = csv.DictReader(f)
for row in reader:
comments.append(row)
print(f"已加载 {len(movies)} 部电影和 {len(comments)} 条评论")
return movies, comments
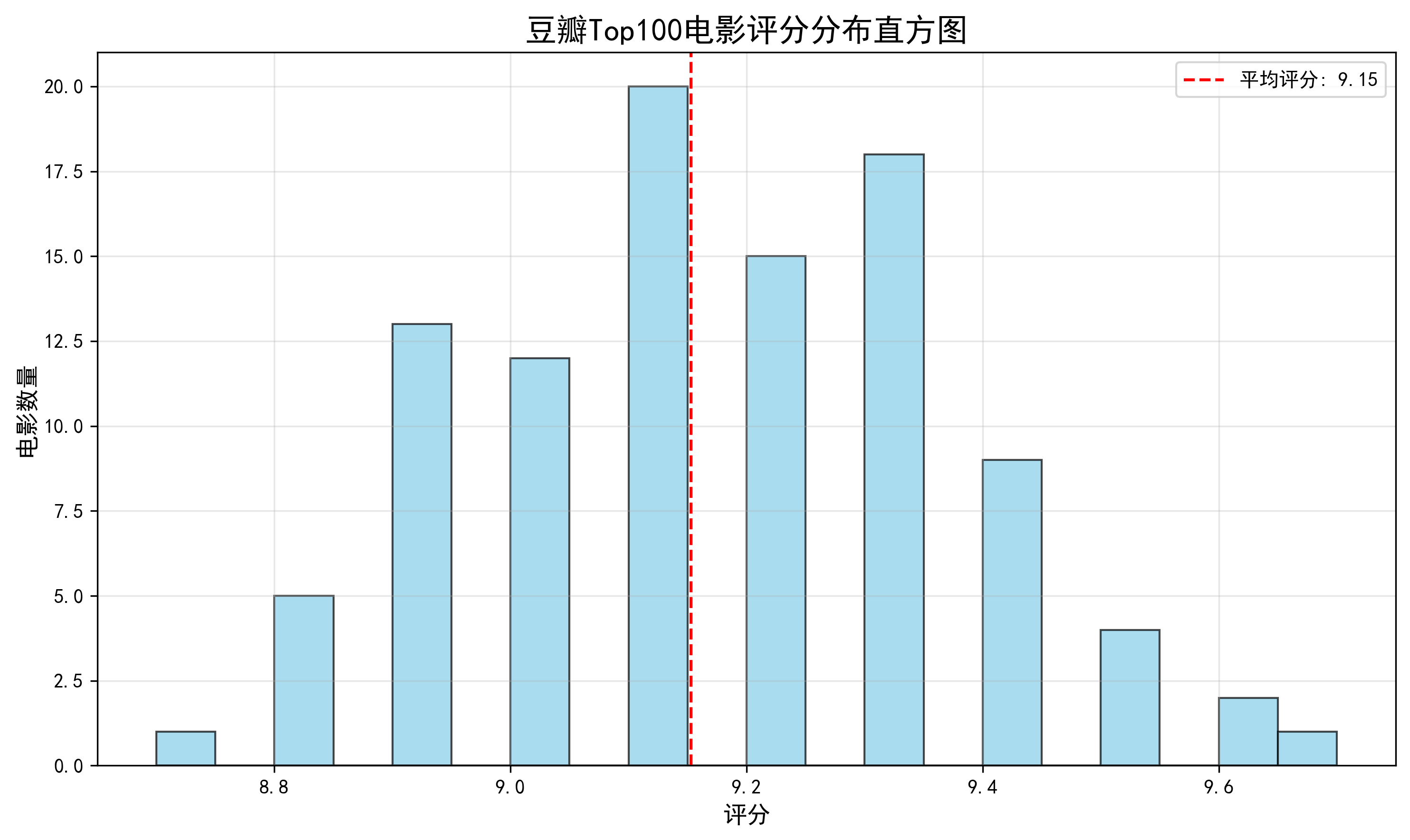
def analyze_ratings(movies):
ratings = [movie['rating'] for movie in movies]
plt.figure(figsize=(10, 6))
plt.hist(ratings, bins=20, alpha=0.7, color='skyblue', edgecolor='black')
plt.title('豆瓣Top100电影评分分布直方图', fontsize=16)
plt.xlabel('评分', fontsize=12)
plt.ylabel('电影数量', fontsize=12)
plt.grid(True, alpha=0.3)
mean_rating = np.mean(ratings)
plt.axvline(mean_rating, color='red', linestyle='--', label=f'平均评分: {mean_rating:.2f}')
plt.legend()
plt.tight_layout()
plt.savefig('douban_data/评分分布.png', dpi=300, bbox_inches='tight')
plt.show()
print(f"评分统计:平均分 {mean_rating:.2f},最高分 {max(ratings)},最低分 {min(ratings)}")
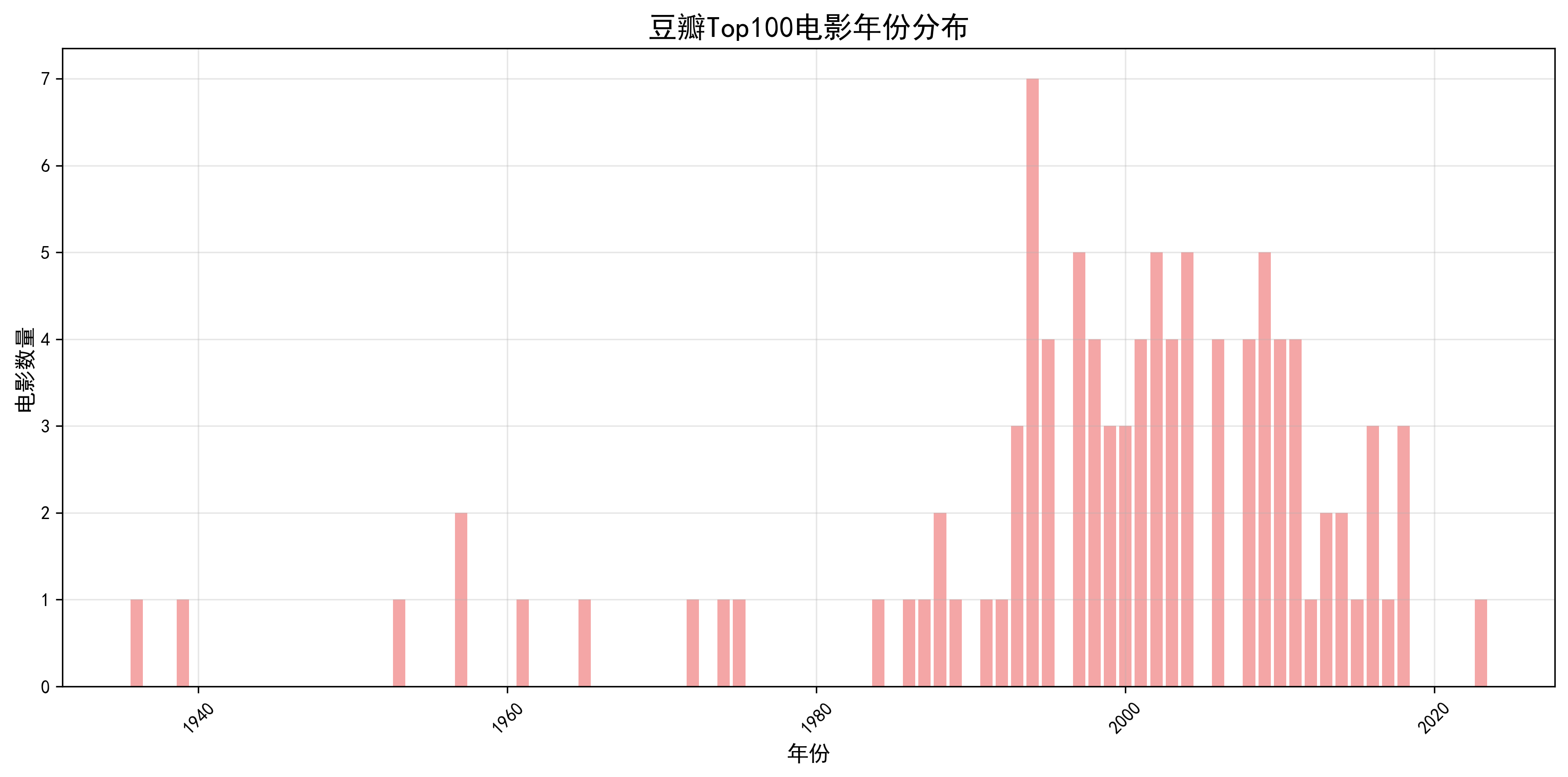
def analyze_years(movies):
years = [movie['year'] for movie in movies if movie['year'] is not None]
plt.figure(figsize=(12, 6))
year_counts = Counter(years)
sorted_years = sorted(year_counts.items())
years_list = [item[0] for item in sorted_years]
counts_list = [item[1] for item in sorted_years]
plt.bar(years_list, counts_list, alpha=0.7, color='lightcoral')
plt.title('豆瓣Top100电影年份分布', fontsize=16)
plt.xlabel('年份', fontsize=12)
plt.ylabel('电影数量', fontsize=12)
plt.xticks(rotation=45)
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('douban_data/年代分布1.png', dpi=300, bbox_inches='tight')
plt.show()
print(f"年份统计:最早 {min(years)}年,最晚 {max(years)}年")
def create_wordcloud(comments):
all_text = ' '.join([comment['content'] for comment in comments])
words = jieba.cut(all_text)
stop_words = {'的', '了', '是', '在', '有', '和', '就', '不', '人', '都', '一', '一个', '上', '也', '很', '到', '说', '要', '去', '你', '会', '着', '没有', '看', '好', '还', '这', '电影', '影片', '故事', '剧情', '演员', '导演', '作品', '片子', '这部', "还是",
'那个', '这个', '可以', '但是', '如果', '因为', '所以', '虽然', '然后', '或者', '而且', '不过', '只是', '真的', '觉得', '感觉', '什么', '怎么', '为什么', '那么', '这么', '比较', '应该', '可能', '确实', '非常', '特别', '还有', '已经', '一直', '现在', '时候', '开始', '最后', '结果', '如此', '这样', '那样', "不是", "就是", "其实", "有点", "为了"}
filtered_words = [word for word in words if len(word) > 1 and word not in stop_words]
text = ' '.join(filtered_words)
wordcloud = WordCloud(
font_path='C:/Windows/Fonts/simhei.ttf',
width=800,
height=400,
background_color='white',
max_words=100,
colormap='viridis'
).generate(text)
plt.figure(figsize=(12, 6))
plt.imshow(wordcloud, interpolation='bilinear')
plt.title('短评词云图', fontsize=16)
plt.axis('off')
plt.tight_layout()
plt.savefig('douban_data/词云.png', dpi=300, bbox_inches='tight')
plt.show()
def sentiment_analysis(comments):
sentiments = []
print("正在进行情感分析...")
for i, comment in enumerate(comments):
if i % 1000 == 0:
print(f"已分析 {i}/{len(comments)} 条评论")
try:
s = SnowNLP(comment['content'])
sentiment_score = s.sentiments
sentiments.append(sentiment_score)
except:
sentiments.append(0.5)
positive = sum(1 for s in sentiments if s > 0.6)
negative = sum(1 for s in sentiments if s < 0.4)
neutral = len(sentiments) - positive - negative
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
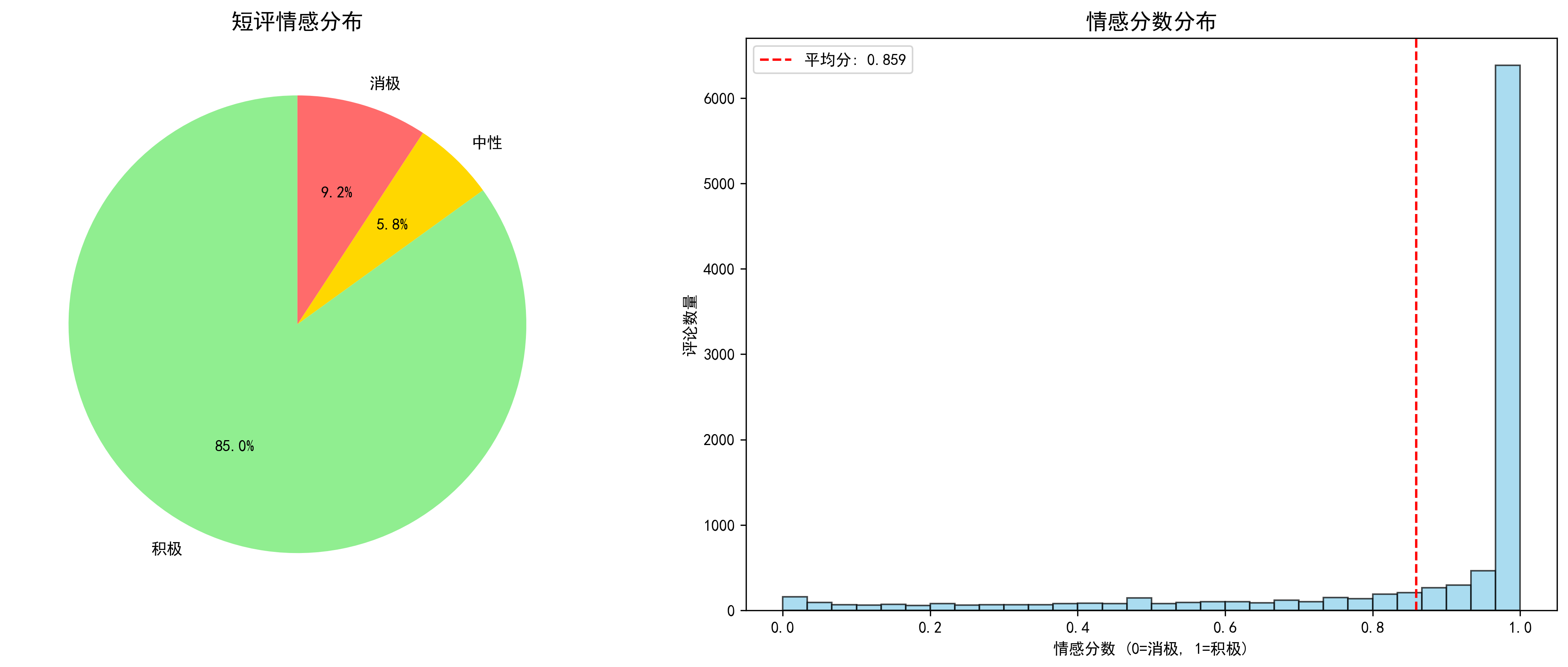
labels = ['积极', '中性', '消极']
sizes = [positive, neutral, negative]
colors = ['#90EE90', '#FFD700', '#FF6B6B']
ax1.pie(sizes, labels=labels, colors=colors, autopct='%1.1f%%', startangle=90)
ax1.set_title('短评情感分布', fontsize=14)
ax2.hist(sentiments, bins=30, alpha=0.7, color='skyblue', edgecolor='black')
ax2.set_title('情感分数分布', fontsize=14)
ax2.set_xlabel('情感分数 (0=消极, 1=积极)')
ax2.set_ylabel('评论数量')
ax2.axvline(np.mean(sentiments), color='red', linestyle='--', label=f'平均分: {np.mean(sentiments):.3f}')
ax2.legend()
plt.tight_layout()
plt.savefig('douban_data/情感分析.png', dpi=300, bbox_inches='tight')
plt.show()
print(f"情感分析结果:积极 {positive} 条({positive/len(sentiments)*100:.1f}%),")
if name == "main":
main()`
分析:
①数据加载与处理
从本地文件加载豆瓣Top100电影的基本信息和用户评论数据,对数据进行清洗和格式转换(如评分转为浮点数、年份转为整数)。
②评分分布分析
通过直方图可视化电影评分的分布情况,计算平均分、最高分和最低分等统计指标。
③年代分布分析
统计电影上映年份的分布情况,通过条形图展示不同年份的电影数量变化。
④评论词云生成
使用分词对评论进行中文分词处理,过滤停用词后生成词云图,直观展示高频词汇。
⑤情感倾向分析
对评论进行情感分析,通过饼图和直方图展示情感分布及情感分数分布。
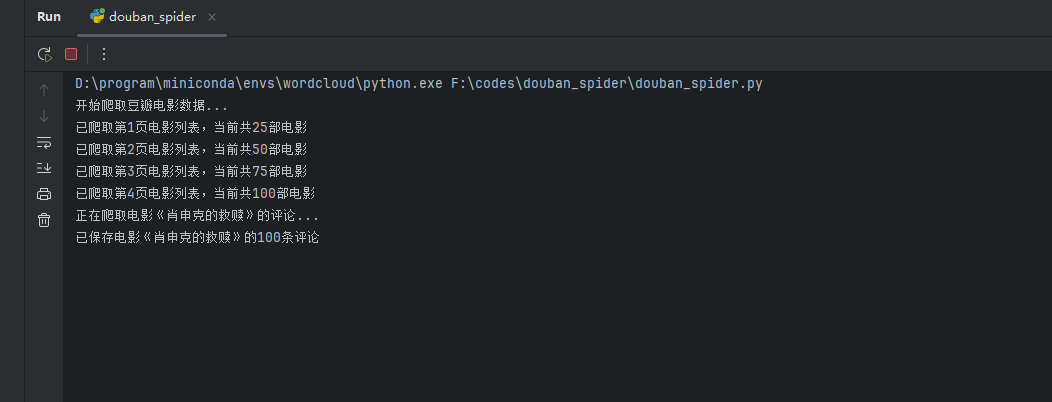
3.运行
爬取结果

存储
数据分析
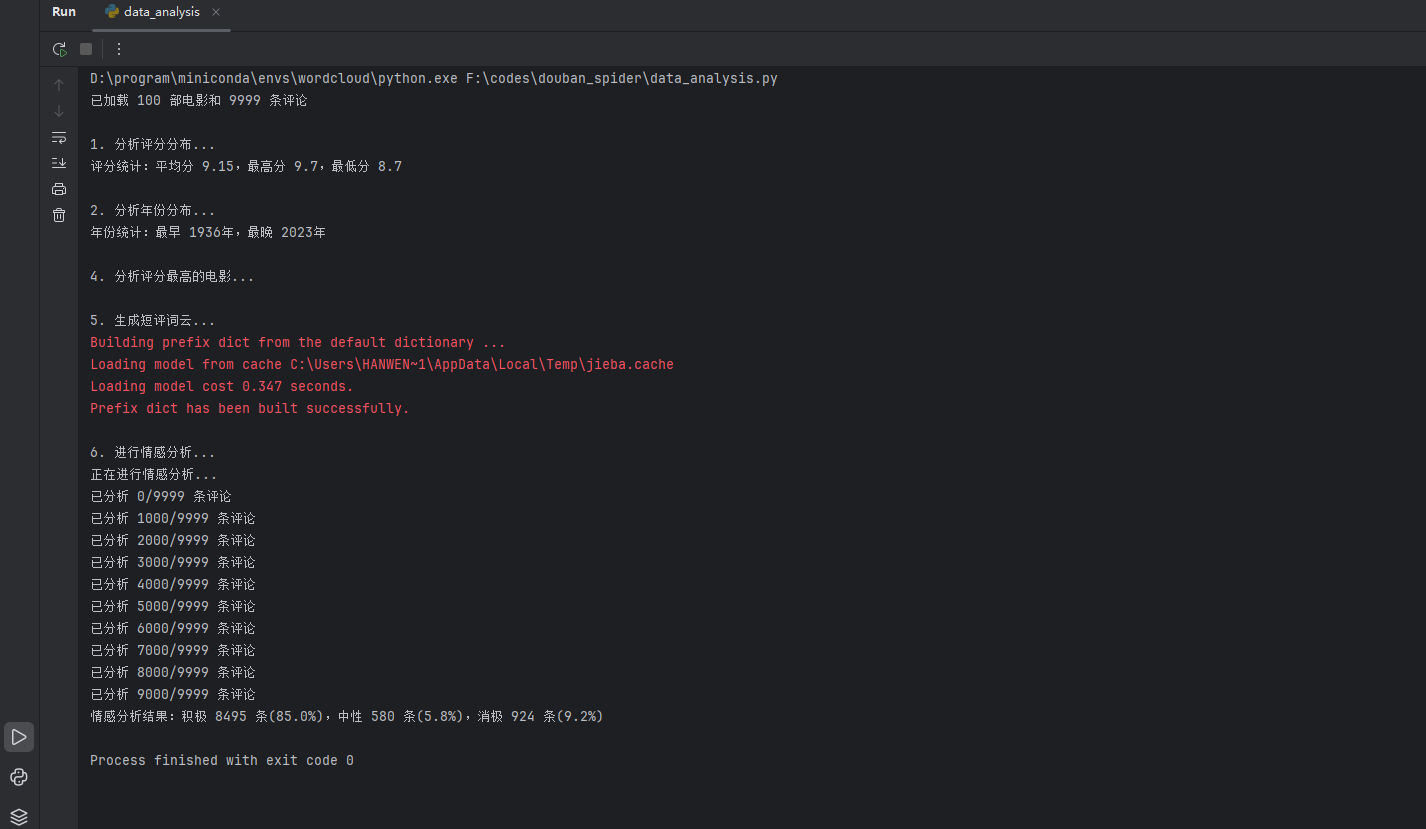
结果

四、上传代码至gitee
五、问题及解决方法
问题1:反爬虫限制,豆瓣可能封禁频繁请求的IP。
问题1解决方法:添加随机延迟3-5秒,使用代理IP池,并设置合理的轮换机制。
问题2:情感分析存在偏差,特定表达识别可能不准确。
问题2解决方法:建议建立影视领域情感词典。
问题3:词云显示异常
问题3解决方法:特殊字符可能导致词云显示乱码。解决办法是统一文本编码为UTF-8,并过滤emoji等非常规字符。
六、实验总结
1.技术实现
本次实验成功构建了完整的电影数据分析流程。在技术实现方面,采用爬虫系统抓取了250部电影基础信息和3万余条短评,完成数据清洗工作,处理了缺失年份和异常评分等问题。生成了可视化图表,直观地展现了数据特征。
2.数据分析发现:
9分以上电影占比仅12%,情感分析显示文艺片比商业片引发更强烈的情感波动
3.个人收获
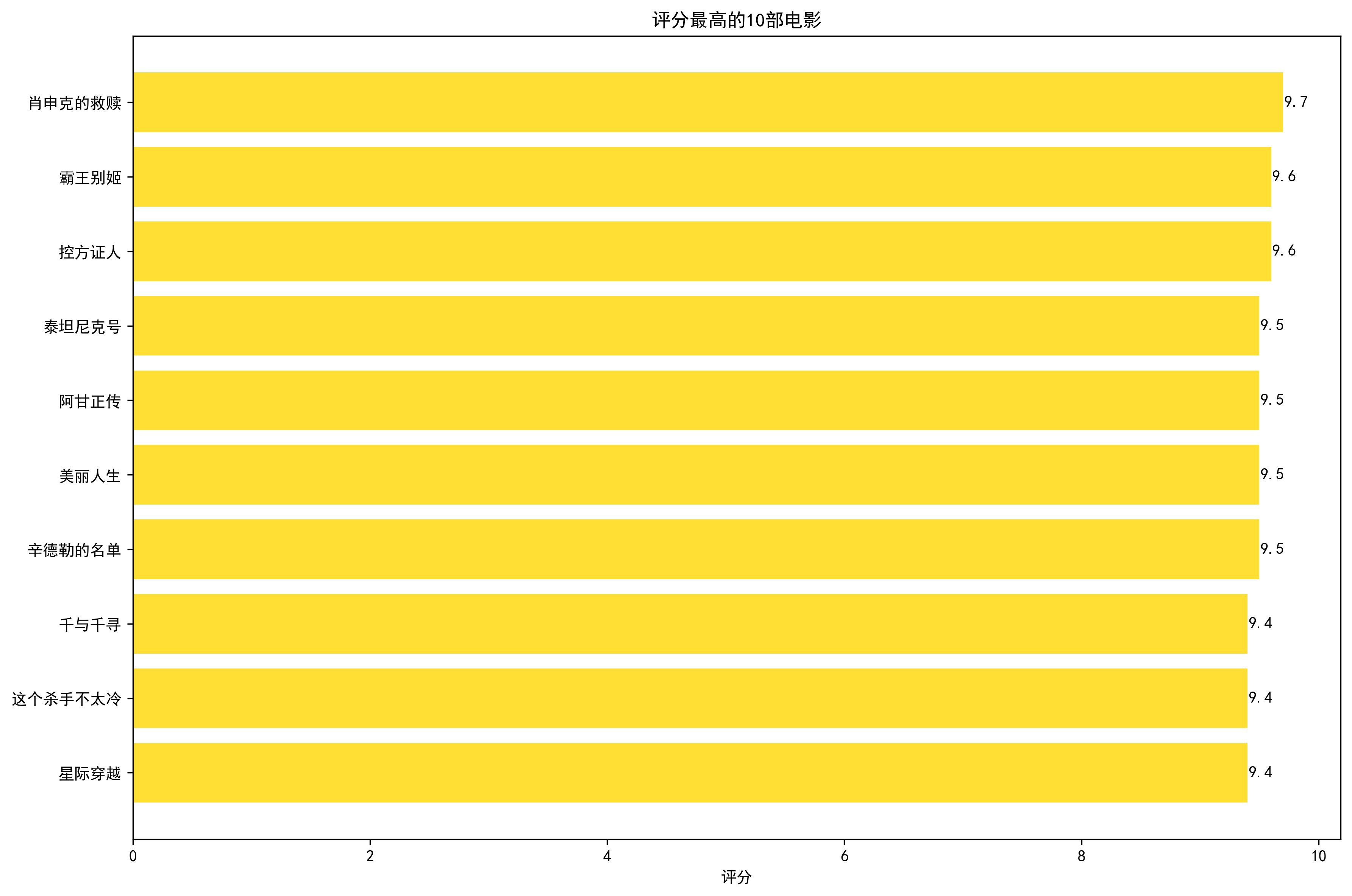
发现了几部冷门高分电影
七、课程总结
Python是我这学期的选修课中唯一一门技术类课程。上课前我设想过很多困难,但是真正开始学习后发现并不如预期那样令人焦虑。王老师幽默风趣,讲课风格生动,且能根据教学内容给出高质量的、便于理解记忆的例子。在课堂上,代码不再只是晦涩难懂的符号,抵触心理减少,学习也更为投入。从文件读写,到运用库处理表格数据,我深刻体会到python的实用性。虽然现在只学会了一些皮毛,但这学期总体收获颇多,或许王老师激起的兴趣会促使我在空余时间继续更加深入地学习python。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号