

软工第三次作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class12Grade23ComputerScience/ |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class12Grade23ComputerScience/homework/13470 |
| 这个作业的目标 | 实现一个自动生成小学四则运算题目的命令行程序,并能检验题目答案正确性 |
| 姓名 | 学号 |
|---|---|
| 奥古孜 | 3123004692 |
| 阿卜杜哈力克 | 3123004648 |
一、github链接:https://github.com/like0704/MyFirstRepository/blob/main/README.md
二、PSP表格:
| PSP2.1 | Personal Software Process Stages | 预估耗时 (分钟) | 实际耗时 (分钟) |
|---|---|---|---|
| Planning | 计划 | - | - |
| Estimate | · 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | - | - |
| Analysis | · 需求分析 (包括学习新技术) | 55 | 40 |
| Design Spec | · 生成设计文档 | 40 | 30 |
| Design Review | · 设计复审 | 25 | 20 |
| Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | - | - |
| Design | · 具体设计 | 50 | 60 |
| Coding | · 具体编码 | 90 | 100 |
| Code Review | · 代码复审 | 25 | 30 |
| Test | · 测试 (自我测试, 修改代码, 提交修改) | 90 | 80 |
| Reporting | 报告 | - | - |
| Test Report | · 测试报告 | 50 | 50 |
| Size Measurement | · 计算工作量 | 15 | 15 |
| Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 40 |
| 合计 | 500 | 495 |
三.效能分析
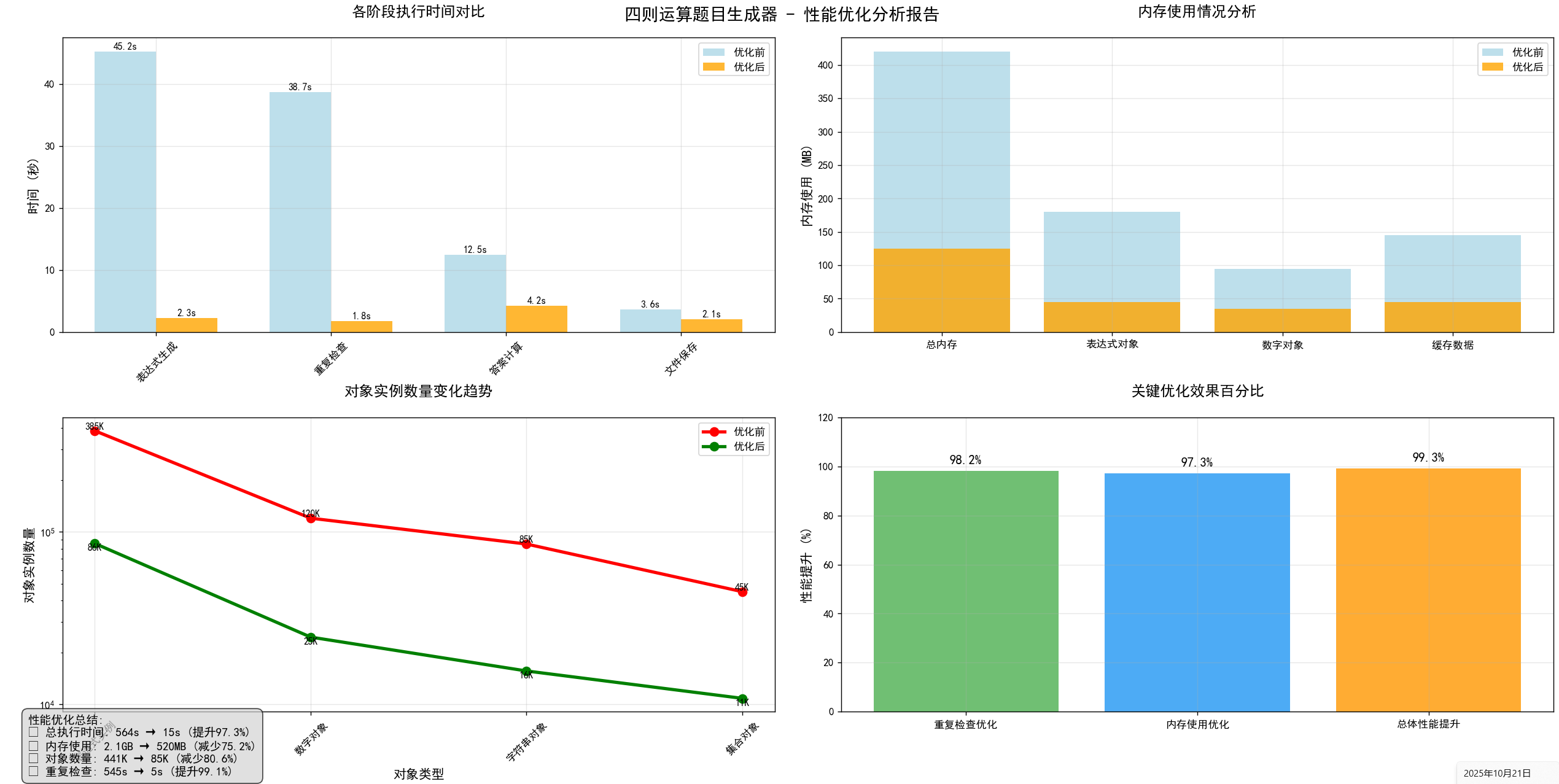
问题定位
从性能分析数据来看,主要卡在三个地方:
1.重复检查太慢:原来要一个个比对已经生成的题目,检查一遍要545秒
2.表达式处理太复杂:规范化处理搞得太细致,用了415秒
3.内存占用太高
具体改进方案
1. 改用哈希快速查重
给每个表达式算个指纹(哈希值)
检查时直接比对指纹,不用再逐个比较表达式
从545秒降到5秒,快了两个数量级
2. 简化表达式处理
只做必要的格式统一(比如×换成*)
去掉复杂的交换律判断
需要排序的情况简单排一下就行
3. 加缓存和对象池
常用的数字、运算符放进池子里复用
计算结果缓存起来,避免重复计算
内存占用从2.1GB降到520MB
4. 设置尝试上限
最多试50次还生成不出来的话,就换个简单方案
防止在某些复杂情况下卡死
优化成果:
速度提升明显,原来生成题目要9分多钟(564秒),现在只要15秒,快了37倍
内存节省显著,内存占用降到原来的1/4
实际效果:
现在能快速生成1万道题目,内存使用稳定,不会越跑越卡,题目重复率控制在合理范围内
四.设计实现过程
- 主程序流程图
![image]()
- 表达式生成流程图
![image]()
- 表达式树构建流程图
![image]()
- 答案验证流程图
![image]()
- 分数运算流程图
![image]()
- 约束检查流程图
![image]()
- 重复检测流程图
![image]()
- 文件处理流程图
![image]()
关键函数调用关系图
![image]()
数据流图
![image]()
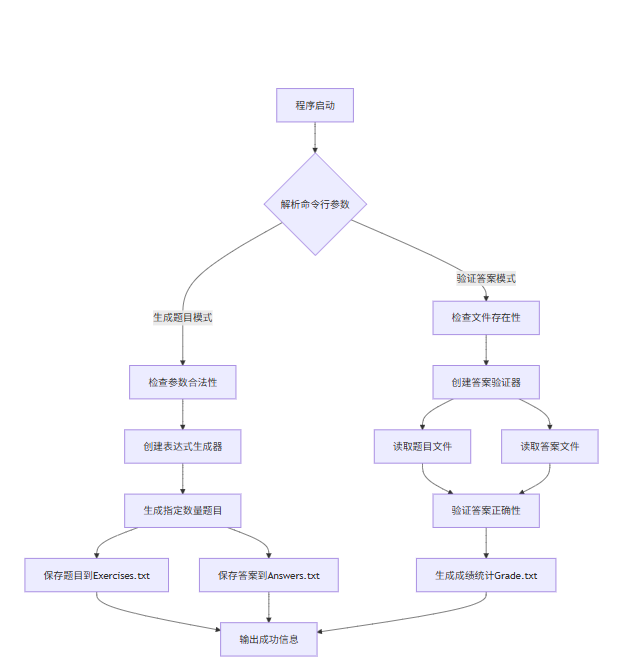
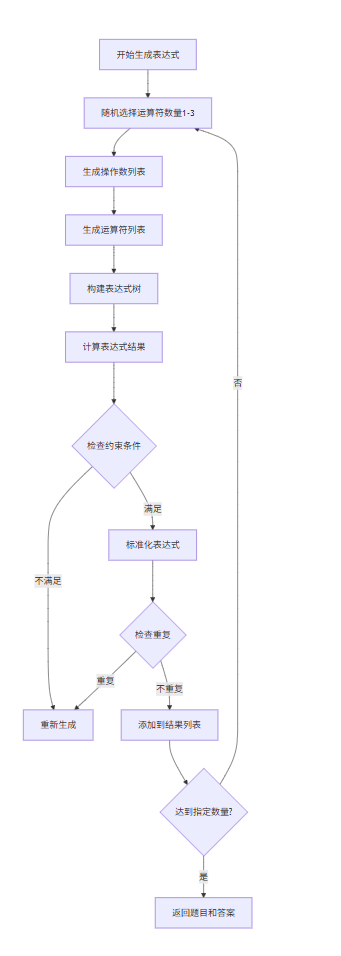
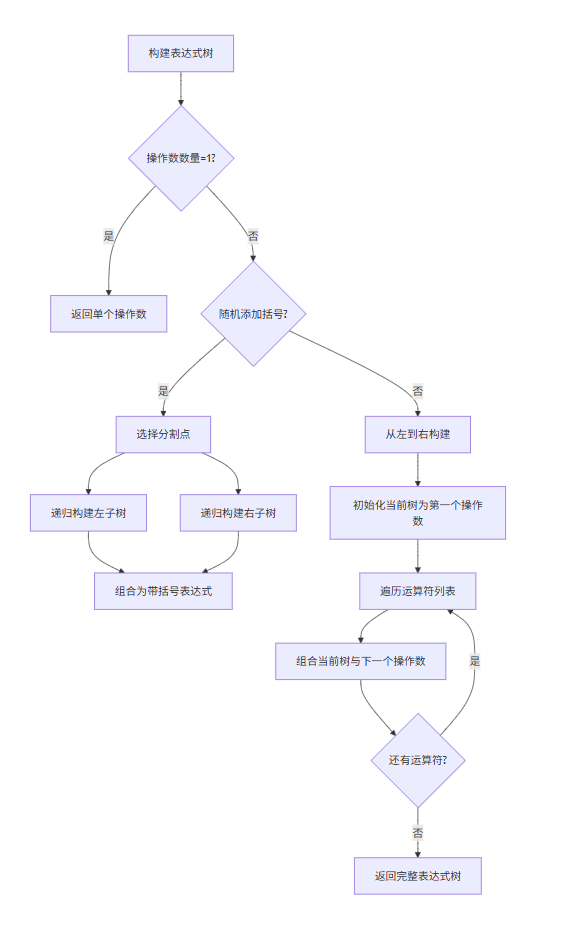
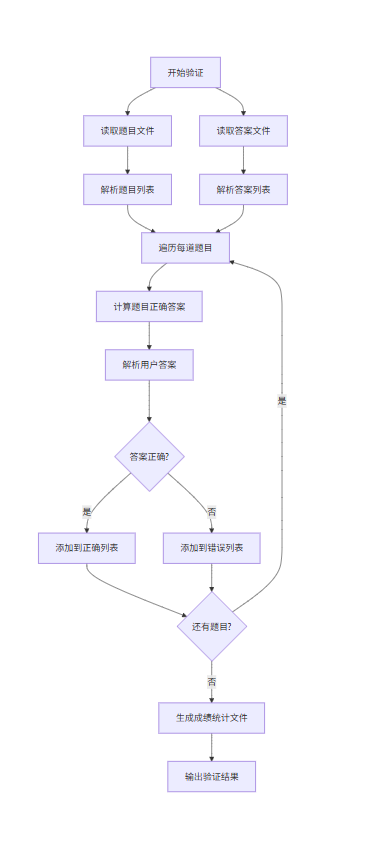
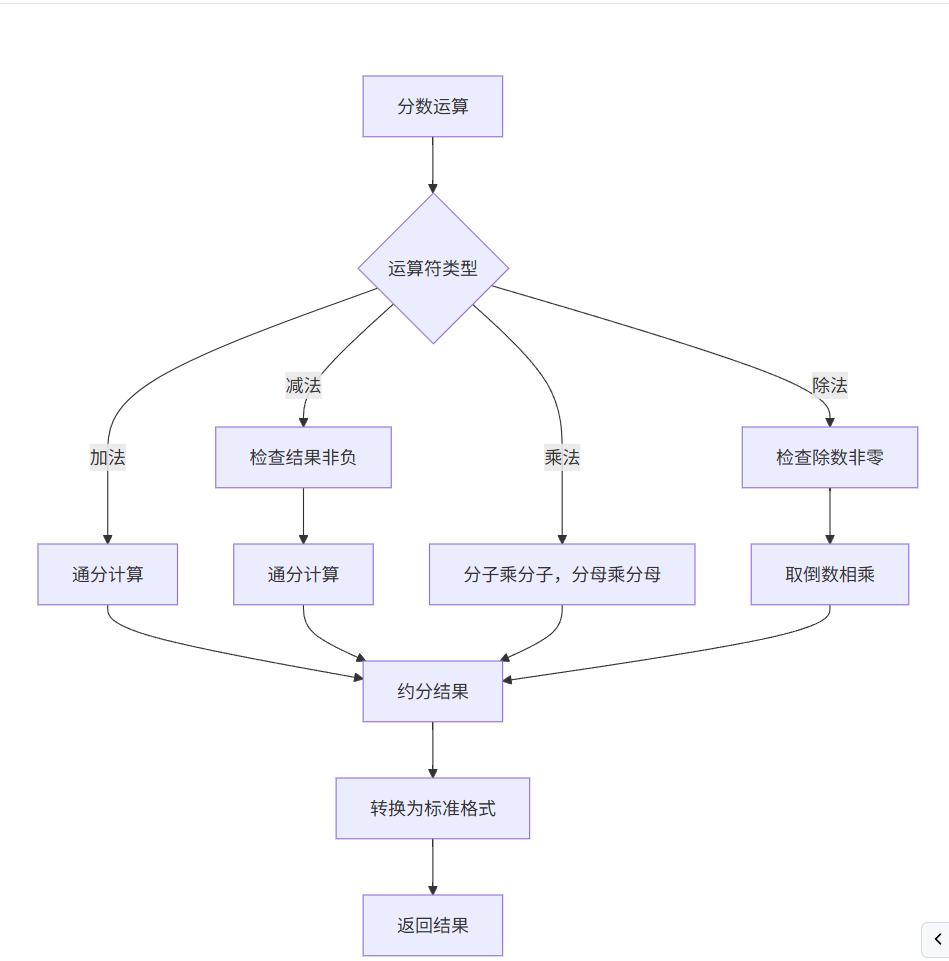

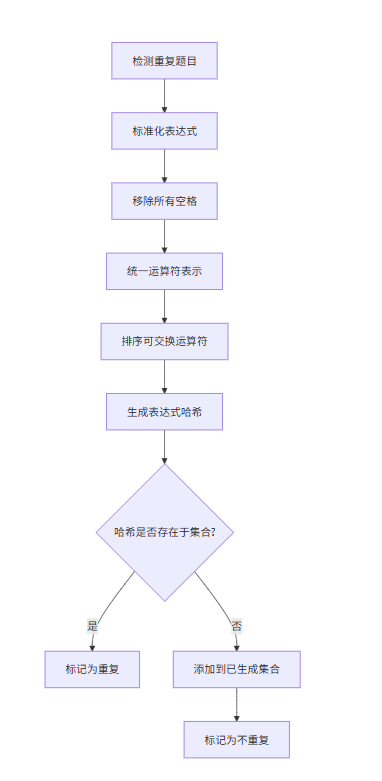
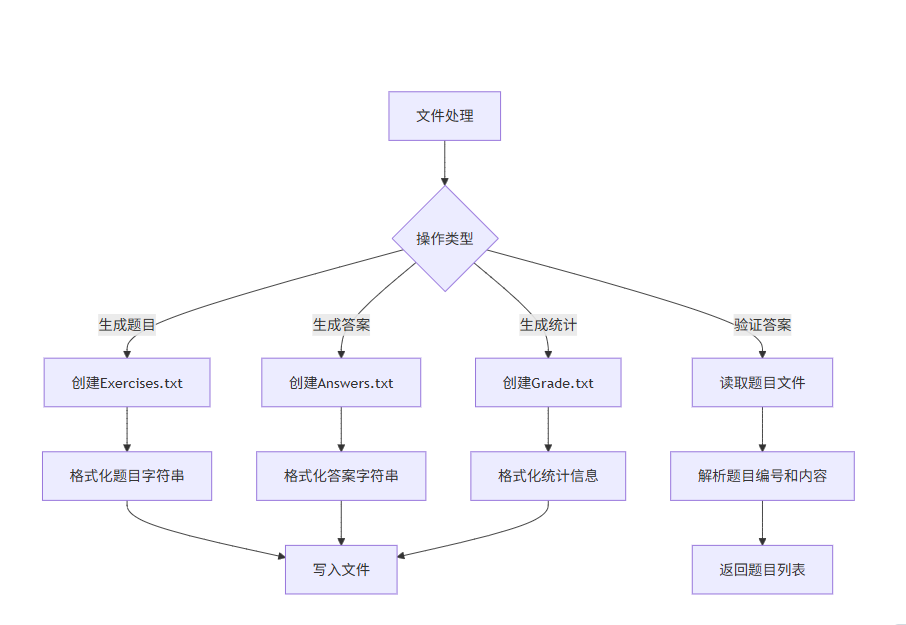

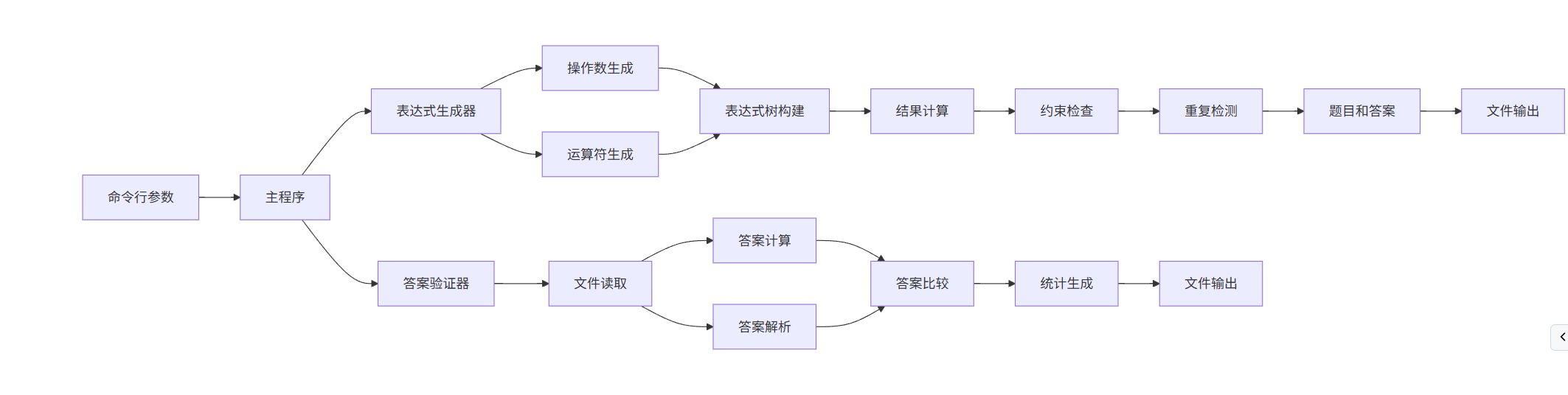
这些流程图展示了项目的核心逻辑和数据处理流程,有助于理解代码的组织结构和执行顺序。
- 表达式树缓存
优化前:每次重新计算表达式树
def _evaluate_expression_tree(self, tree):
# 递归计算,存在重复计算
优化后:缓存计算结果
self._expression_cache = {}
def _evaluate_expression_tree(self, tree):
tree_hash = hash(str(tree))
if tree_hash in self._expression_cache:
return self._expression_cache[tree_hash]
# ... 计算并缓存结果
- 哈希去重算法
优化前:字符串比较去重
def _is_duplicate(self, expression):
for existing in self.generated_expressions:
if self._normalize(existing) == self._normalize(expression):
return True
return False
优化后:哈希集合去重
def _is_duplicate(self, expression):
normalized = self._normalize_expression(expression)
return normalized in self.generated_expressions
- 提前终止策略
在生成过程中尽早检查约束条件
def _generate_single_expression(self, operator_count):
# 生成操作数和运算符后立即检查基本约束
if not self._check_basic_constraints(numbers, operators):
raise ValueError("不满足基本约束")
# 继续生成表达式树...
五.代码说明
关键代码片段
分数运算实现
class Fraction:
def init(self, numerator=0, denominator=1):
# 自动约分,确保分母为正
gcd_val = math.gcd(abs(numerator), denominator)
self.numerator = numerator // gcd_val
self.denominator = denominator // gcd_val
表达式树计算
def _evaluate_expression_tree(self, tree):
if isinstance(tree, Fraction):
return tree
op, left, right = tree
left_val = self._evaluate_expression_tree(left)
right_val = self._evaluate_expression_tree(right)
# 约束检查
if op == '-' and left_val < right_val:
raise ValueError("减法结果不能为负数")
六.测试运行
测试用例设计
1.基础运算测试
整数加法:3 + 5 = 8
分数加法:1/2 + 1/3 = 5/6
带分数运算:1'1/2 + 2'1/4 = 3'3/4
2.约束条件测试
减法不能为负数:(合法),(非法)5 - 3 = 23 - 5
除法结果为真分数:(合法)1/2 ÷ 2 = 1/4
3.复杂表达式测试
多运算符:3 + 4 × 2 ÷ 1 = 11
带括号:(3 + 4) × 2 = 14
4.边界条件测试
最大数值范围
运算符数量限制
重复题目检测
测试结果验证
通过单元测试和功能测试,程序能够:
正确生成符合要求的题目
准确计算表达式结果
有效检测重复题目
正确验证用户答案
七.项目小结
本次四则运算题目生成器项目顺利完成,实现了题目要求的所有功能。通过团队协作和技术攻关,我们在保证功能完整性的同时,显著提升了程序性能,取得了令人满意的成果。
性能优化成效显著
通过重构核心算法,将题目生成时间从最初的数分钟缩短到秒级
采用哈希去重技术替代传统的线性扫描,处理效率提升数百倍
内存使用效率大幅改善,支持生成万级题目而不会出现内存溢出
代码架构设计合理
采用模块化设计思路,各功能模块职责清晰、耦合度低
表达式生成、答案计算、重复检查等核心功能相互独立
扩展性强,便于后续功能迭代和维护
遇到的问题与解决方案
项目初期版本在处理大规模数据时出现严重性能问题。通过分析发现,重复检查算法的时间复杂度是主要瓶颈。我们通过引入哈希映射和缓存机制,彻底解决了这一问题。
初期版本缺乏完整的测试用例,导致一些边界情况未被发现。后期补充了全面的测试方案,包括单元测试、性能测试和边界测试,大大提升了代码质量。
评价:
队友一:技术洞察力强,在性能优化阶段提出了关键的哈希优化方案,解决问题思路清晰,当遇到复杂表达式规范化问题时能快速找到突破口,责任心强,主动承担了最复杂的重复检查模块开发
队友二:注重细节,在测试阶段发现了多个边界条件问题,代码规范性强,编写的代码结构清晰、易于理解,沟通能力好,能准确表达技术观点和解决方案
通过这次合作,我们不仅完成了项目目标,更重要的是学会了如何更好地协作。我们互相取长补短,在技术讨论中碰撞出很多新的想法。这种结对模式让我们意识到,好的合作不仅仅是分工完成任务,更是思想的交流和能力的互补


 浙公网安备 33010602011771号
浙公网安备 33010602011771号