基于机器学习和深度学习的模糊测试技术
第3.4 本文总结一下近期两篇:
基于机器学习的模糊测试研究综述
一.机器学习---
一个经典的模糊测试程序工作流程包括输入预处理、测试用例生成、种子筛选与调度、测试执行、目标状态监测和结果分析等环节。
所以机器学习主要是通过对数据的训练,帮助在测试用例生成的数据,避免盲目编译,产出高质量的样例。
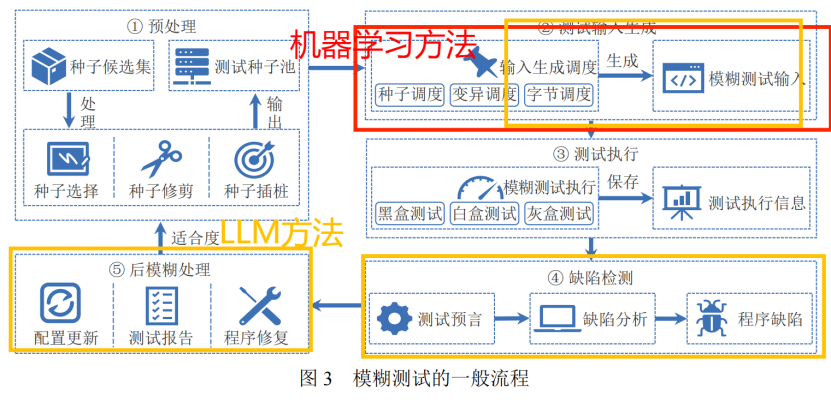
还是这个图,第二章机器学习怎么协助测试用例,就是讲了 测试用例里面的:生成→变异→调度/筛选→其它增值,这几个都在测试用例的过程里面,生成这个模块,会包括文件解析软件,编码解析工具,网络解析协议这些测试用例生成,而在变异中会有方向地推动变异,还会帮助我们在种子调度等更方便。
可以看出机器学习方法只针对测试输入生成这一步。
未来期望在于:拓宽领域,更深层次,提升效率,集思广益。
二.面向深度学习系统的模糊测试技术
因为这些都发生在测试输入生成阶段,本文的种子选择,种子变异,是通过深度学习的方法,迭代多次生成的。
|
阶段 |
目的 |
运行次数 |
|
预处理(数据准备) |
把“原始业务数据”变成干净、可用、格式正确的初始文件,让后面任何测试都能直接读 |
1次 |
|
种子选择 & 变异(测试输入生成) |
在已预处理好的种子池里,挑、改、造出能触发新覆盖或缺陷的新输入 |
每轮迭代都执行(成千上万次) |
覆盖分析就是在模糊测试输入以后,用深度学习模型来看下还有哪些缺陷没有覆盖到,覆盖是我们的手段。
把变异输入喂给 DNN → 顺手读出内部各层/神经元/区间的激活值 → 用结构性指标检查有没有新的“区域”被点亮 → 如果有,就认为这次变异“拓宽了探索边界”,把它留种继续变异。
不断重复这个过程,就能把模型内部状态空间尽可能撑大,从而提高碰到缺陷的概率;
但覆盖分析本身并不会告诉你“这就是缺陷”,它只负责给出“还有没有没走过的角落”这一导航信号。
用深度学习并不是为了“像神经网络一样一步步覆盖”这个形式感,而是因为它同时提供了两样别的系统没有的东西,正好解决传统 fuzz 的盲区:
- 免费、细粒度的“内部地图”
前向传播一次就能拿到每一层、每一段、每一个神经元的激活值,不需要插桩、不需要重写代码,就能实时知道“哪片区域还是黑的”——这是结构性覆盖能成立的前提。
- 可导出的“方向箭头”
因为网络可微,可以把“点亮黑区”或“放大预测误差”直接写成损失函数,用梯度反向推回输入空间,自动生成能命中这些区域的变异样本——这是梯度类变异(DeepXplore、DLFuzz 等)能高效运转的根因。
总结:
“本文用深度学习来助攻模糊测试:在测试用例生成阶段利用模型信息做种子调度与变异调度,生成新样本;执行后读取内部激活做覆盖分析,把触发新覆盖或缺陷的样本回投队列,循环迭代直至覆盖或缺陷目标达成。”
两者对比一下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号