基于大语言模型的模糊测试研究综述
摘要:
模糊测试是一种自动化的软件测试方法,通过向目标软件系统输入大量自动生成的测试数据,以发现系统潜在的安全漏洞、软件缺陷或异常行为。然而,传统模糊测试技术受限于自动化程度低、测试效率低、代码覆盖率低等因素,无法应对现代的大型软件系统。近年来,大语言模型的迅猛发展不仅为自然语言处理领域带来重大突破,也为模糊测试领域带来了新的自动化方案。因此,为了更好地提升模糊测试技术的效果,现有的工作提出了多种结合大语言模型的模糊测试方法,涵盖了测试输入生成、缺陷检测、后模糊处理等模块。但是现有工作缺乏对基于大语言模型的模糊测试技术的系统性调研和梳理讨论,为了填补上述综述方面的空白,对现有的基于大语言模型的模糊测试技术的研究发展现状进行全面的分析和总结。主要内容包括:(1) 概述模糊测试的整体流程和模糊测试研究中常用的大语言模型相关技术;
(2) 讨论大模型时代之前的基于深度学习的模糊测试方法的局限性;
(3) 分析大语言模型在模糊测试方法中不同环节的应用方式;
(4) 探讨大语言模型技术在模糊测试中的主要挑战和今后可能的发展方向。
关键词:大语言模型;模糊测试;测试输入生成;缺陷检测;后模糊处理
本文就从上述四个主要内容展开
一. 引言在讲,“将 LLM 应用于模糊测试领域有利于提升模糊测试自动化水平, 分析被测试软件的潜在漏洞, 从而实现对系统 缺陷的高效检测”就是传统模糊测试自动化、效率、覆盖率都不足,而大语言模型带来新自动化契机。
二. 流程
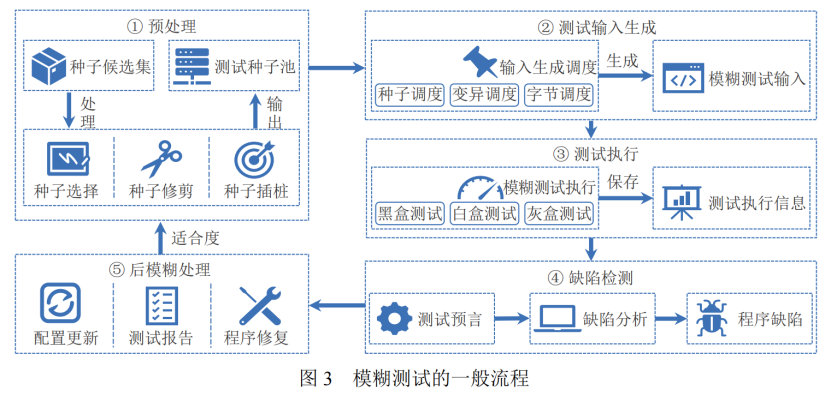
基于 LLM 的模糊测试常用技术:
先表明一点,我们是用 LLM 来帮助模糊测试——让大语言模型当“外挂插件”,替传统 fuzzing 在输入生成、缺陷检测、后处理等环节做得更智能、更自动化。
1. 微调 : 就是用现成的模型,微微改动,通过我们现成的一些训练数据,教给模型怎么去大范围生成我们模糊测试需要的数据
微调比较简单,而且LLM必须开源
2. 提示工程 : 就是通过提示LLM,不断训练,帮助我们进行模糊测试
有零样本,少样本,思维链,自动提示等方法
3. 传统方法融合:LLM 负责“想出点子”,传统算法负责“验点子、导航下一步”,两者互补,弥补纯模型生成带来的语法错、语义错、覆盖差等问题。
三.大模型时代前的基于深度学习的模糊测试
就是在LLM之前人们是怎么折腾深度学习来帮助模糊测试的四 主题:基于 LLM 的模糊测试
1.与传统方法的融合:
单一 LLM 在模糊测试中存在显著局限:生成的测试输入易出现语法 / 语义错误、对代码结构理解不足、种子选择缺乏针对性、生成用例存在大量冗余。
将 LLM 与传统模糊测试的成熟算法(反馈验证、程序分析、变异算子、统计分析)融合,可互补短板,显著提升测试输入的有效性、覆盖率与效率。
- 反馈验证:
通过编译 / 执行验证生成的测试输入,将错误信息闭环反馈给 LLM / 提示生成器,迭代优化生成结果,解决 LLM 生成输入的语法错误与执行无效问题。
- 程序分析:
利用传统程序分析技术(静态 / 动态分析)提取代码的结构、语义与上下文信息,输入给 LLM,弥补其对代码结构理解不足的缺陷,让生成的测试输入更贴合目标程序的实际逻辑。
- 变异算子:
融合传统模糊测试的变异策略(如 AFL 的位翻转、字节替换、块移动等),结合 LLM 的生成能力,扩充种子程序的数量与多样性,同时利用覆盖率反馈引导变异方向,提升测试覆盖率与漏洞发现概率。
- 统计分析······
LLM 驱动缺陷检测
1.测试断言生成
这个在缺陷检测部分,测试预言就是一把事先立好的判断标准,跟跑完的结果进行对比。判断这趟有没有Bug
2.缺陷分析
- 基于微调方法:教他看代码找漏洞
- 基于提示工程:基于提示工程的缺陷检测 = 把“去找漏洞”的指令 + 必要的上下文/例子一次性写进 prompt,扔给大模型 → 它当场返回漏洞信息,完事即走,模型权重不留痕迹,下次换代码再换新 prompt。Prompt就是临时指令包
LLM 驱动后模糊处理
4.1 微调(输入生成)
教材 = “怎么造输入”
种子、断言、历史触发片段 → 模型学会写测试用例
4.2 微调(缺陷检测)
教材 = “怎么看漏洞”
CVE 漏洞代码 + 描述/标签 → 模型学会当审计员
4.3 微调(程序修复)
教材 = “怎么改对代码”
{缺陷代码, 正确补丁} 对子 → 模型学会写补丁
测试不是循环的,也就是说,微调只发生一次,三条是平行的
后面两个方法也是一个道理
研究主要在LLM 驱动的测试输入生成。而缺陷检测和后模糊处理比较少。
灰盒测试比较多,其余比较少
然后在这些方法中仍有很多不足,
总结了最后四个研究方向:
1. 可以拓宽一下编程语言和编程软件,测试对象 测试对象是:
 2. 当前LLM主要应用在测试输入,缺陷检查和后模糊处理。预处理和测试执行还未涉及
2. 当前LLM主要应用在测试输入,缺陷检查和后模糊处理。预处理和测试执行还未涉及
3. 在当前调研的文献中, 我们注意到各种研究尚未提出一套统一且可靠的测试基准. 在实验评估中, 由于缺乏专门针对基于 LLM 的模糊测试的实验基准, 研究工作通常采用相应领域或编程语言的评估基准。
而且还容易泄露问题。
4. 怎么提升 LLM 测试领域性能,还是在微调上 一是构建高质量的微调数据集, 二是设计更符合现有 LLM 架构的微调方法.
总之主要就是讲了微调,提示工程,传统算法融合在不同情况的应用,具体操作还要看LLM的不同。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号