模糊测试技术综述
模糊测试学习第一篇
摘要:
模糊测试是一种安全测试技术,主要用于检测安全漏洞,近几年模糊测试技术经历了快速发展,因此有必要对相关成果进行总结和分析.通过搜集和分析网络与系统安全国际四大顶级安全会议(IEEES&P,USENIXSecurity,CCS,NDSS)中相关的文章,总结出模糊测试的基本工作流程,包括:预处理、输入数据构造、输入选择、评估、结果分析这5个环节,针对每个环节中面临的任务以及挑战,结合相应的研究成果进行分析和总结,其中重点分析以AmericanFuzzyLop工具及其改进成果为代表的,基于覆盖率引导的模糊测试方法.模糊测试技术在不同领域中使用时,面对着巨大的差异性,通过对相应文献进行整理和分析,总结出特定领域中使用模糊测试的独特需求以及相应的解决方法,重点关注物联网领域,以及内核安全领域.近些年反模糊测试技术以及机器学习技术的进步,给模糊测技术的发展带来了挑战和机遇,这些机遇和挑战为下一步的研究提供了方向参考.
关键词:
模糊测试;基本工作流程;物联网安全;内核安全;机器学习
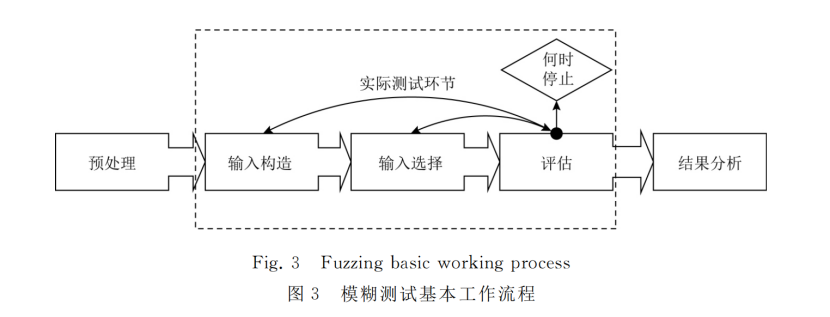
一.预处理
预处理里面主要有三个方法
1.插桩:插桩就是在不改变源代码的情况下,去影响编译器,让编译器给每一步做个记录,我们最后看到的是累加的记录
静态插桩需要依赖源码,在编译器内部视角,只是内存改了,在程序员视角,源码是不变的,这是在编译阶段就预备好的,而且必须知道源码
动态插桩不需要源码,在运行起来的时候,现场操作,但是这个开销比较大.
比如QEMU = 二进制翻译器 + 虚拟硬件把“目标 CPU 指令”一条条翻译成“主机 CPU 指令”,并在翻译时顺手插入我们想执行的“额外代码”(计数器、断点、日志),完成动态插桩。
2.符号执行
不给程序真数据,而是给它“代数符号”(x、y、z)当输入,让它一路把“走这条分支要满足什么方程”都记下来,最后交给数学求解器反推:
“到底什么数字能走到我想去的漏洞点?”
所以,静态一次画完全家的树,容易递归循环爆炸,动态稍微好一点,但是也会路径爆炸(剪枝等方法)
其中加速的方法:
- Pangolin:把以前算过的方程结果存起来,下次直接抄答案。
- Intriguer:只看“结构字段”级别,不求解整棵大树。
- ILF:让神经网络先学“大佬符号执行跑出的好样本”,再用模型猜怎么走更划算。
3.污点分析
先把所有“外来输入”涂上荧光粉(称为“污点”)。
程序运行时,荧光粉会随数据一起流动:复制、运算、传参……走到哪亮到哪。
我们只看“最终哪些指令/地址/寄存器发了光”,就能知道攻击者到底能影响哪些地方;如果某个发光点正好是:
- 跳转地址 → 可能控制流程
- 数组长度 → 可能溢出
- SQL/命令字符串 → 可能注入
|
维度 |
黑盒 |
灰盒 |
白盒 |
|
能看到啥 |
只读输入/输出,完全看不见内脏 |
看一点“X 光片”——覆盖率、边频 |
全开:源码、CFG、变量、断言 |
|
源码 |
不需要,有二进制就行 |
最好有源码;无源码也能用 QEMU/PT |
必须有完整源码 |
|
优缺点 |
上手快,门槛低;深度不足 |
性价比最高,平衡速度与穿透力 |
挖得最深,但资源/时间最贵 |
灰盒模糊测试总体上来看会更有优势,通过灵活的设计,灰盒模糊测试可以在检 测能力与资源消耗之间寻找一个合适的平衡点
二.输入构造
即获得输入数据,先得到一个数据S,然后对S进行不定次数的编译,得到新的数据I,此时S就是种子,I就是输入的数据。
- 种子获取是可以下载公用或自己获取准备的
- 种子筛选是在划分权重和优先级
- 种子突变
2中能量分配是随时间变化的策略,不是一次性打分,他可能随着时间次数等等会变动。
种子突变即在前面的基础上快速生成大量的数据,有六种

但是根据突变所依据的策略不同,我们将突变的方式划分为2种:黑盒突变(black-boxmutation)和导向型突变(guidedmutation)
- 黑盒突变不依赖任何信息,闷声利用上面的招数
- 引导性是需要各方面引导一下
可以分为程序状态导向型突变和性能导向型突变,前者主要在看这个程序存在的内部状态,比如位置,字段。后者是看对外部指标的提升的影响,比如覆盖率的提升等等进行
三.输入选择
是在实际输入之前,把无效的数据筛除然后提高效率
四.评估
1.覆盖率就是广度,看覆盖的对象
2.平均暴露时间 从 fuzz 启动到第一次触发指定漏洞的平均秒数
3.开销
4.四步实验法

五.结果分析
结果要手动去重,判断是否有意义的漏洞
最后
当前研究主要是物联网模糊测试和内核模糊测试,在不同领域有不同工具,包括反模糊测试,在机器学习中的应用结合

 浙公网安备 33010602011771号
浙公网安备 33010602011771号