
二二、函数(五)
1、static和inline
1)静态变量
利用static可以声明一个静态变量,static变量如果没有指定初始化的值,那么会初始化为0,无论有没有指定初始值,都只会初始化一次,静态变量的值不会因函数大括号结束而消失。语法如下
//static语法
static 类型 变量名称;
//示例
static int a;
//count变量在函数Add()第一次调用的时候会初始化为0,当第二次Add()调用时,则不再初始化count变量
int Add(int a,int b)
{
static int count; //第二次Add()调用时,则count为1
count++;
。。。
}
2)内联函数
可以使用inline声明一个内联函数,内联函数将会建议编译器把这个函数处理成内联代码以提升性能,但始终是建议,具体编译器是否采纳,由编译器决定。
//声明一个内联函数
inline int Add(int a,int b)
{
return a+b;
}
2、从编译器的角度理解定义和声明
1)编译器编译代码的顺序
计算机并不能看懂C/C++语言,计算机的世界里只有二进制,因此,我们每一次编程,每一句代码,编译器都会编译成计算机能够读懂的二进制代码(机器语言),我们的代码是一篇写满了命令的文章,而编译器则是一个合格的翻译官,负责把我们的文章翻译给计算机听,计算机是一个合格的士兵,它从不质疑你的命令,你让它做什么它就做什么,就算你的命令是错的!
而编译器这个翻译官在读我们的文章的时候,它是从第一行,第一个字开始读的。因此可以先对函数声明,再对函数进行定义。
#include <iostream>
int main()
{
ave(1, 2);
}
int ave(int a, int b)
{ //大括号中的内容为函数的定义
return (a + b) / 2;
}
2)函数的声明
以上的代码没有任何语法错误,但是不能编译,因为编译器读取到函数ave()的时候,它并不知道ave是什么,编译器即不知道ave需要什么样参数,也不知道ave函数返回什么样的值,因为ave不是C/C++编译器提供的函数!对于编译器来说,它此时不需要知道ave具体是什么功能,但是它需要知道ave函数返回的是什么类型的值,需要什么样的参数!
因此在一个函数使用之前,至少应该告诉编译器这个函数的基本信息,那就是这个函数的参数和返回值,这种告诉,就叫做函数的声明,就拿本例来说,函数的声明为int ave(int a,int b);
对于编译器来说,它此时并不需要知道参数的名字,只需要知道这个函数返回的是int类型的值,要求的是两个int类型的参数,因此声明也可以写为这样int ave(int,int);
综上所述,声明是人和编译器的事,声明并不需要翻译成计算机语言告诉计算机。但是函数的定义和计算机有关
//函数的声明
#include <iostream>
int ave(int a, int b); //函数的声明
int ave(int,int); //声明时,可以只说明参数类型即可,也可以多次声明
int main()
{
ave(1, 2);
}
int ave(int a, int b)
{ //大括号中的内容为函数的定义,函数的定义只能有一次
return (a + b) / 2;
}
3)函数的定义和声明
不管我们和编译器谈的如何愉快,你给定的什么样子的函数声明,但是最终,还是要通过编译器告诉计算机这个函数的具体实现过程,这个实现过程的告诉,就是函数的定义。
函数的声明可以有多次,但是函数的定义只能有一次。
4)深入理解函数的定义和声明
声明的本质是与编译器的对话,单纯的声明并不存在内存的分配,只是给编译器一个大体的感念,既然是对话,我们可以多次对话,所以对于同一个事物,我们可以多次声明。
而定义的本质是通过编译器与计算机的对话,这就涉及到内存的分配和访问,因此同一个事物,不管声明多少次,但是只能有一次定义。
变量同样适用这个规则,我们可以通过关键字extern声明一个变量,而把这个变量的声明和定义分开。
写函数的声明的时候,没有写extern关键字,是因为函数的声明本事就是extern的,因此不需要手动指出。
extern的作用也是告诉编译器,此处只是一个声明,你去别处找定义,因此extern是针对的全局变量,因为局部变量不存在去别处找定义的可能性。而函数的声明自带extern属性,因此函数本身也是全局的。
#include <iostream>
extern int all; //声明一个变量
int main()
{
std::cout << all << std::endl; //输出250
}
int all{ 250 }; //变量的定义
5)理解函数的定义

3、头文件和源文件
1)模块化的实现
在一个大型项目中,不可能把所有的源代码都写到一个源文件中,通过添加新的源文件,可以把一个工程分解为若干个模块。其中x.c为C语言的源文件,x.cpp为C++的源文件。不同的语言要使用不同的语法
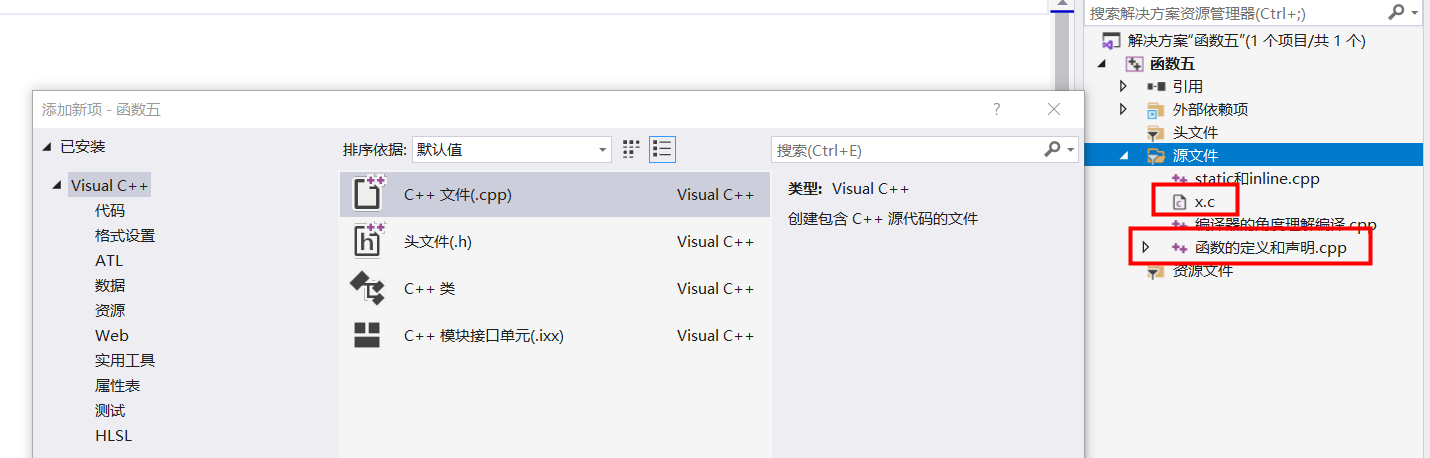
可以在一个cpp文件中写函数的定义,另一个cpp文件中写函数的声明来使用函数
//emah.cpp
int ave(int a, int b)
{
return (a + b) / 2;
}
int bigger(int a, int b)
{
return a > b ? a : b;
}
//主函数.cpp
#include <iostream>
int ave(int a, int b); //函数的声明
int bigger(int a, int b);
int main()
{
int c = ave(100, 200);
std::cout << c << std::endl;
int d = bigger(100, 200);
std::cout << d << std::endl;
}
2)头文件使用
可以在头文件中写入函数的声明,然后在主函数中直接调用头文件
//cmath.c
int ave(int a, int b);
int bigger(int a, int b);
//cmath.cpp
int ave(int a, int b)
{
return (a + b) / 2;
}
int bigger(int a, int b)
{
return a > b ? a : b;
}
//主函数.cpp
#include <iostream>
#include "cmath.h" //调用自定义头文件
int main()
{
int c = ave(100, 200);
std::cout << c << std::endl;
int d = bigger(100, 200);
std::cout << d << std::endl;
}
3)多个源码共用一个全局变量
在头文件中声明多个源文件中,要共用的变量。变量的定义可以放在任何源文件中,但不能放在头文件中,因为这样违背了一个事物只能定义一次的元组。如
extern int verId;
3)#pragman once
放在头文件中的第一行,可以防止头文件被多次调用
#pragman once
...
4)#define
#ifdef _H_
#define _H_
xxxxxxx
#endif
注:
①编译器不会编译头文件,先从编译器的源文件开始编译,将每个源文件编译为x.obj的目标文件
②一个工程中只能有一个同名函数(除了函数重载)
③静态函数只在该函数所在的源文件中有效,在其它源文件中无效。静态函数可以写在头文件中,这种情况,函数不在全局有效,所以静态函数可以多次使用。
④内联函数也可以写在头文件中,
⑤静态变量也在各自的源文件中有效,
⑥pragma once部分编译器支持,部分编译器不支持。pragma once下的内容只会被引用一次
⑦ifndef 检测有没有定义一个宏
4、extern
1)声明一个C语言风格的函数
//e.h
#pragma once
extern "C" int ave(int a,int b); //告诉编译器,该函数为C语言风格的函数
//e.c
int ave()
{
return 1;
}
//主函数.cpp
#include <iostream>
#include "e.h"
int main()
{
std::cout<<ave();
}
2)声明一群C风格的函数
//e.h
#pragma once
extern "C"
{
int ave();
int pve();
}
3)把头文件内的内容声明为C语言风格
extern "C"
{
#include "emath.h"
#include "pmath.h"
}
注:以上方式即为C++调用C语言代码的办法,但是C语言无法调用C++的代码
5)extern和_cplusplus
#ifdef __cplusplus //定义一个宏,表示在C++环境下
extern "C"
{
#endif
#include "emath.h"
#include "pmath.h"
#ifdef __cplusplus
}
#endif
5、C和C++源文件混用的问题及LNK4042问题
//math.cpp
int ave(int a,int b)
{
return (a+b)/2;
}
//math.c
int add(int a,int b)
{
return a + b;
}
//math.h
#pragma once
int ave(int a, int b);
extern "C" int add(int a,int b);
//主函数.cpp
#include <iostream>
#include "math.h"
int main()
{
std::cout<<ave(1,5)<<std::endl;
std::cout<<add(1,5)<<std::endl;
}
//程序执行会报错
综述:在一个项目中,如果存在一个x.c文件和x.cpp文件,则编译的时候只会生成一个x.obj文件
6、创建自己的sdk
将我们自定义的库制作成一个安装包,发布给别人使用,就是SDK(Softwore Development Kit)
1)编辑源文件和头文件
//源文件
#include "edoyun.h"
#define VERSION "1.0"
int ave(int a, int b)
{
return a * b / 2;
}
namespace edoyun
{
const char* GetVersion()
{
const char* str = VERSION;
return str;
}
}
//头文件
int ave(int a, int b);
namespace edoyun
{
const char* GetVersion();
}
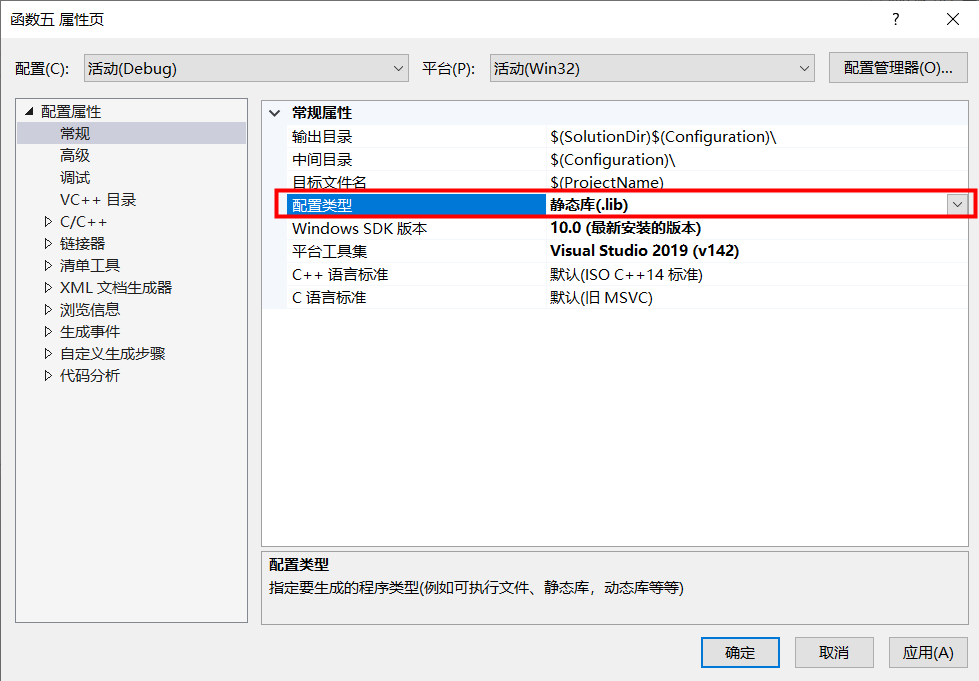
2)设置项目属性的配置类型为静态库(.lib)
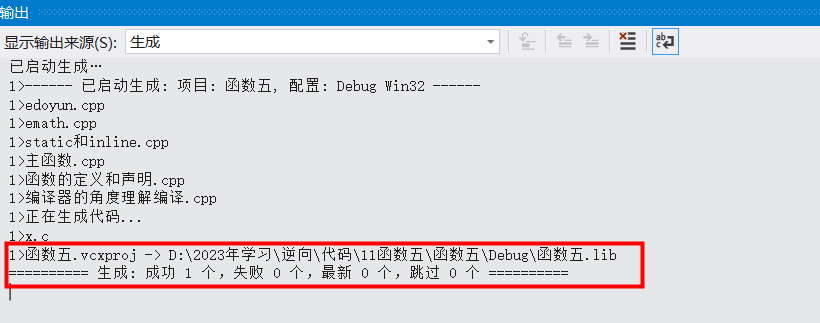
重新生成项目时,就会生成一个x.lib文件
3)将x.lib文件和x.h文件拷贝到一个文件夹中

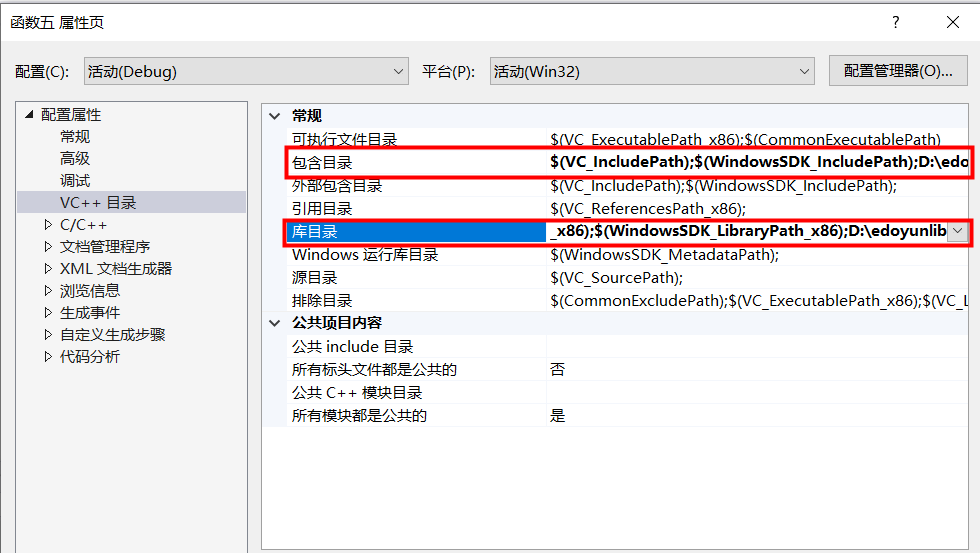
4)将库文件和头文件进行引用
在项目属性-VC++目录的包含目录和库目录中分别添加上述库文件和头文件所在的目录
5)使用库文件(法一)
#include <iostream>
#include <edoyun.h>
#pragma comment(lib,"edoyun.lib") //将库文件加入到项目中
int main()
{
std::cout << edoyun::GetVersion() << std::endl;
std::cout << ave(100, 200) << std::endl;
}
6)使用库文件(法二)
项目属性-链接器-输入-附加依赖性中,将lib进行添加,注意用分号隔开
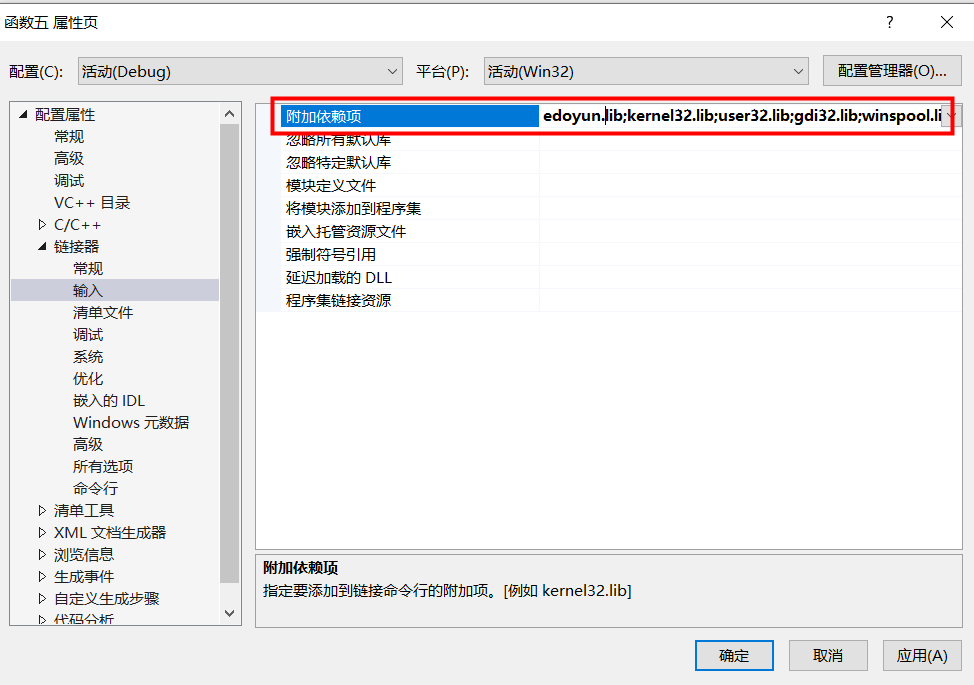
//此时即可以完整使用自定义的库文件
#include <iostream>
#include <edoyun.h>
int main()
{
std::cout << edoyun::GetVersion() << std::endl;
std::cout << ave(100, 200) << std::endl;
}
7、函数调用约定
函数调用约定时函数调用者与被调用者之间的一种协议,这个协议主要规定了以下两个内容:
①如何传递参数
②如何恢复栈平衡
//如下代码中main()函数调用了ave()函数
#include <iostream>
int ave(int a, int b)
{
return (a + b) / 2;
}
int main()
{
ave(100, 200);
}
//汇编代码
ave(100, 200);
00F71881 68 C8 00 00 00 push 0C8h //参数传递
00F71886 6A 64 push 64h
00F71888 E8 E9 F9 FF FF call ave (0F71276h)
00F7188D 83 C4 08 add esp,8 //恢复栈平衡
1)函数调用约定__cdecl
__cdecl参数入栈顺序为:从右到左,堆栈平衡为:谁调用谁平衡。正因为__cdecl这种堆栈平衡方式,能够支持不定量参数
#include <iostream>
int __cdecl ave(int a, int b) //先入栈b,再入栈a
{
return (a + b) / 2;
}
int main()
{
ave(100, 200);
}
//汇编
ave(100, 200);
00E21881 68 C8 00 00 00 push 0C8h
00E21886 6A 64 push 64h
00E21888 E8 E9 F9 FF FF call ave (0E21276h)
00E2188D 83 C4 08 add esp,8
2)函数调用约定__stdcall
__stdcall参数入栈顺序为:从右到左,堆栈平衡为:函数自己恢复栈平衡。Windows编程中WINAPI CALLBACK都是__stdcall的宏,生成的函数名会加下划线,后面跟@和参数尺寸
#include <iostream>
int __stdcall ave(int a, int b) //先入栈b,再入栈a
{
return (a + b) / 2;
}
int main()
{
ave(100, 200);
}
//汇编
ave(100, 200);
00EE1891 68 C8 00 00 00 push 0C8h
00EE1896 6A 64 push 64h
00EE1898 E8 33 FA FF FF call ave (0EE12D0h)
注:在x64架构下,默认使用的函数调用为_fastcall
3)函数调用约定__fastcall
第一个参数通过ecx传递,第二个参数通过edx传递,剩余参数入栈顺序:从右到左;堆栈平衡:函数自己恢复栈平衡。fastcall的函数执行速度比较快
#include <iostream>
int __fastcall ave(int a, int b) //先入栈b,再入栈a
{
return (a + b) / 2;
}
int main()
{
ave(100, 200);
}
//汇编
ave(100, 200);
00D31891 BA C8 00 00 00 mov edx,0C8h //优先通过寄存器传参,所以快
00D31896 B9 64 00 00 00 mov ecx,64h
00D3189B E8 90 F9 FF FF call ave (0D31230h)
4)其它调用约定
①__thiscall用作C++中类的访问
②naked call是一种不常用的调用约定,一般用于实模式驱动开发
8、递归函数
函数可以调用自己本身,这种函数称为递归函数,另外还存在一种情况,即函数A调用函数B,而函数B又调用函数A,这种函数称为互相递归函数。
int ave(int x)
{
if(x==1)return x;
return x*ave(x-1);
}
递归函数本质上更像一个循环,因此一定要为递归函数设计退出机制。并且递归函数往往效率上不如循环,并且还存在耗尽栈资源而奔溃的可能性,因为函数每次调用都传递参数,导致栈资源被耗尽,但是合理的使用递归函数能够提高代码的可阅读性。因此使用递归函数时需要权衡利弊

 浙公网安备 33010602011771号
浙公网安备 33010602011771号