
20242321汤泽鹏 2024-2025-2 《Python程序设计》实验四报告
20242321 2024-2025-2 《Python程序设计》实验四报告
课程:《Python程序设计》
班级:2423
姓名:汤泽鹏
学号:20242321
实验教师:王志强
实验日期:2025年5月14日
必修/选修:公选课
零、引言
计算机里都是从零开始计数的,我也从零开始写。首先谈谈我的实验动机吧,事情是这样的,这学期开始的时候我加了太多比赛报名群,结果把时间弄混了,导致有的比赛错过了报名时间。于是我想到了爬取这些比赛的名称、时间、报名网址,并每天早上9:00自动运行脚本发送邮件到我的邮箱里。另外:本实验报告非常非常详细地讲了如何爬取一个网站,可以举一反三用到别的网站上,如豆瓣、铁路12306,牛客网等等。我简单爬了一下学校的oj平台,发现需要通过API才能获取数据,难度有点高,还有就是风险有点高,可能被封号甚至被认为Ddos攻击把服务器搞崩了,那就真的G了,基于”所见即所得“的爬虫准则,我放弃了爬取oj平台。
一、实验内容
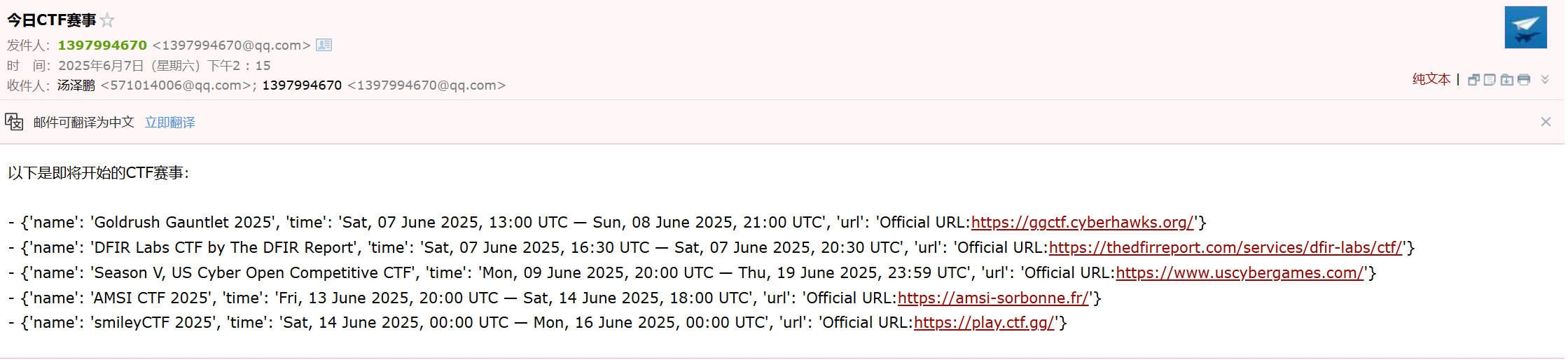
- 爬虫爬取CTFtime:爬取CTFtime上比赛的名称、时间、报名网址,并每天早上9:00自动运行脚本发送邮件到我的邮箱里。
- 在华为云服务器上运行脚本
二、实验演示
不多说了,先上演示结果,源码在文末(源码隐藏了邮箱授权码,所以无法直接复制使用):
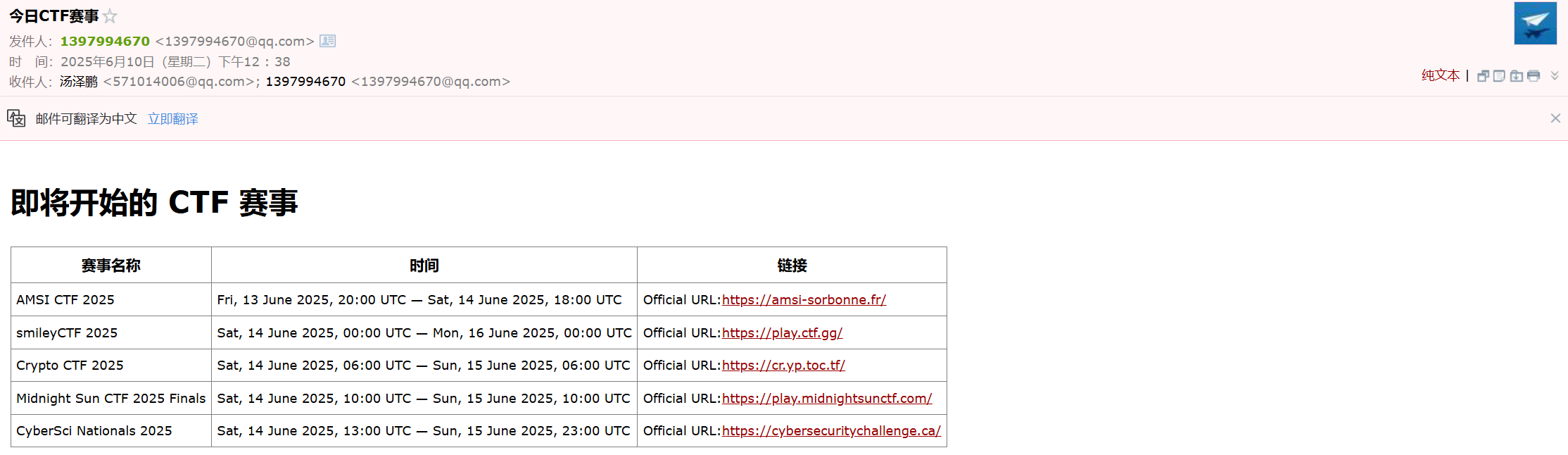
https://www.bilibili.com/video/BV1LXTrzCE5e/
https://www.bilibili.com/video/BV1LXTrzCEEd/
https://www.bilibili.com/video/BV1s5TkzbESJ/
华为云上跑的测试邮件:
但是源代码跑了很久很久,实在录不下来视频
三、实验过程
1.实验分析
本实验分为三步走战略:
- 利用python编写爬虫爬取CTFtime上比赛的名称、时间、报名网址等信息
- 将所获取的信息通过邮件发送
- 通过windows任务计划程序每天早上9:00自动运行脚本
- 创建华为云服务器,并运行python脚本
2.实验设计
-
分析CTFtime的网页内容,寻找规律
-
通过requests库来发送HTTP请求获取网页内容
-
通过BeautifulSoup来解析HTML/XML的文档
-
通过fake_useragent库来绕过反爬
-
解析出需要的信息(名称、时间、报名网址)
-
通过字典进行存储每组比赛信息
-
用HTML模板设计美化邮件
-
通过smtplib进行邮件发送
-
通过windows任务程序添加每日任务,自动运行脚本
3.非常非常的详细实验过程
(1)爬取信息
为了爬取CTFtime上的信息,我们首先需要分析CTFtime网页组成
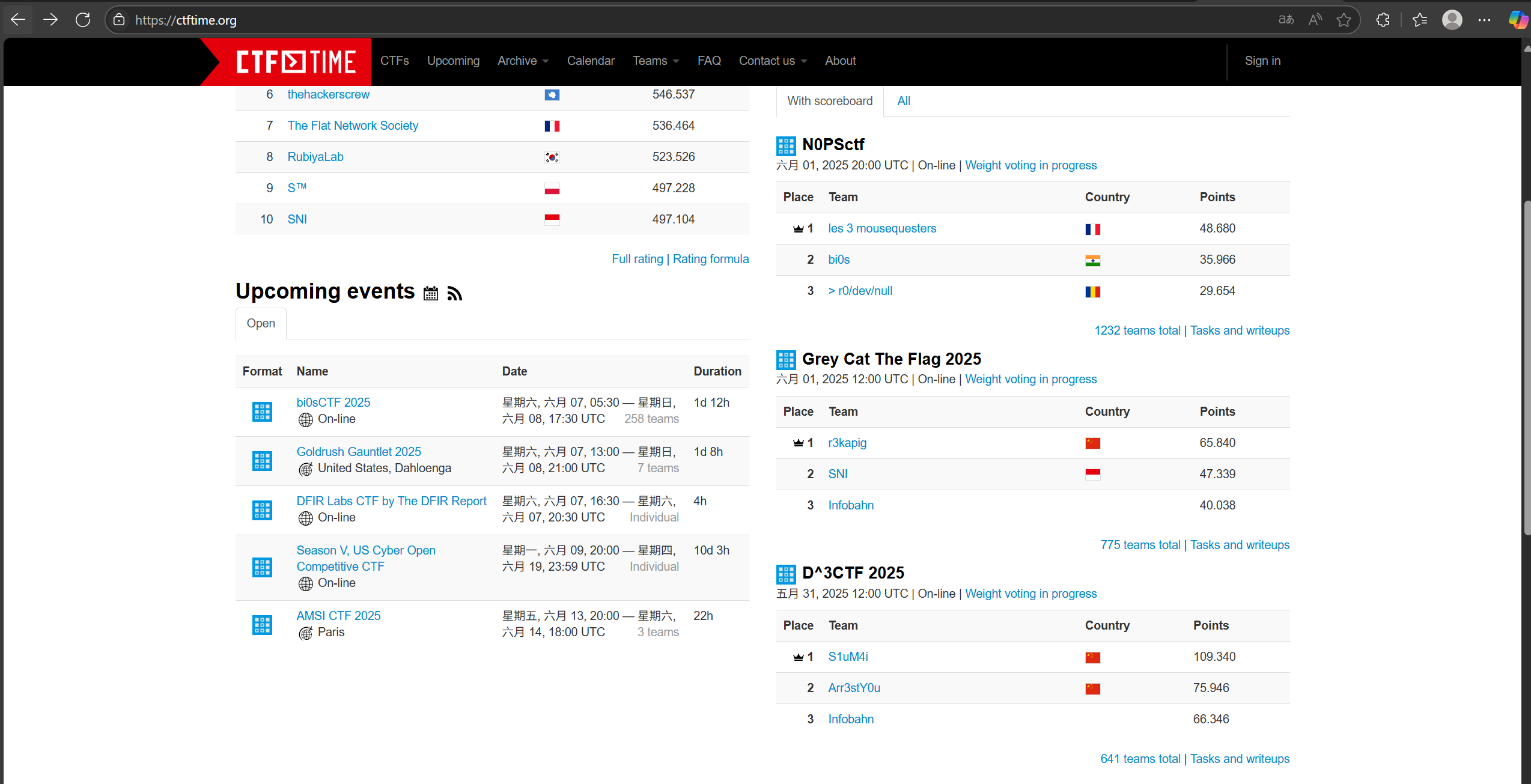
在主页上发现,有比赛的名称、时间,但是没有网址,点进任意一个比赛,发现报名网址。通过分析发现,我所要找的是形如”https://ctftime.org/event/XXXX“这样的网址,也就是说需要找到”XXXX“这四位数字
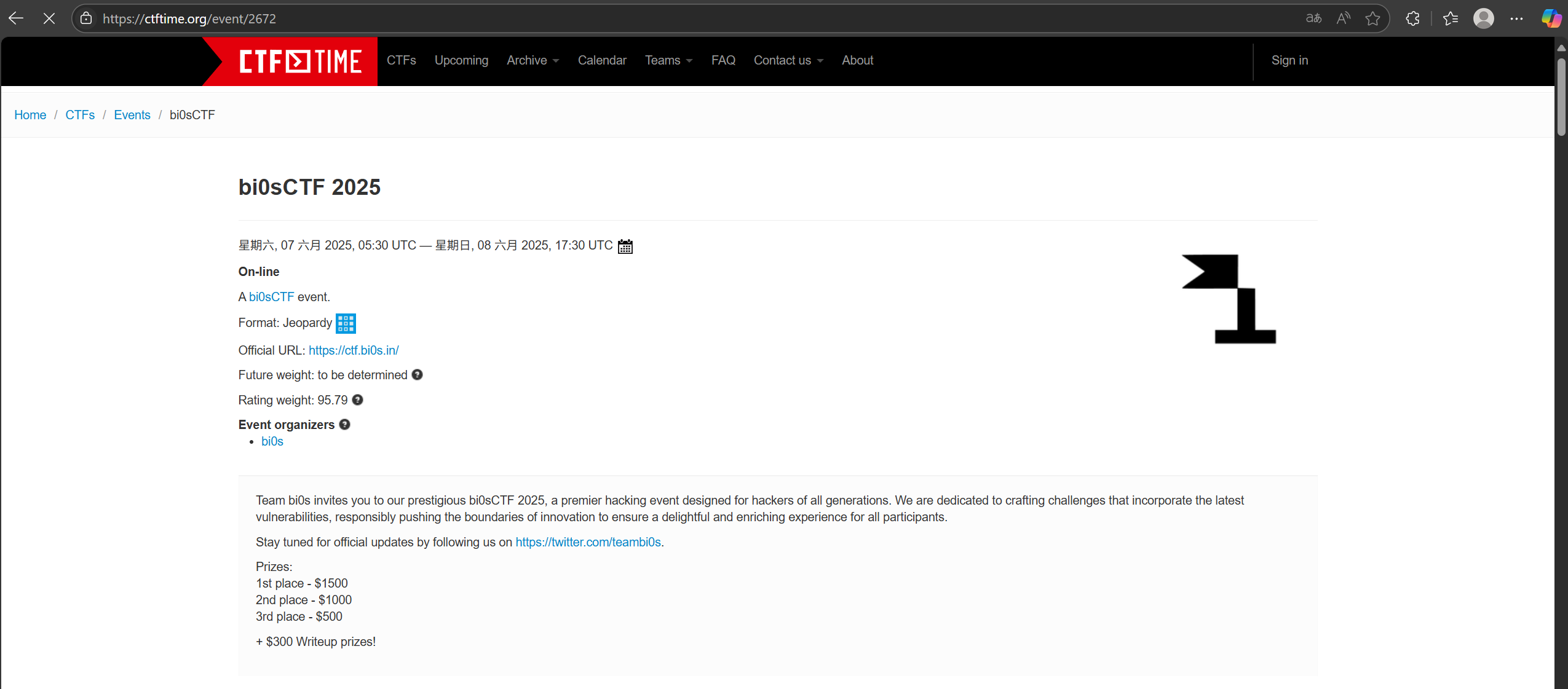
那么现在的目标就是找到XXXX与”https://ctftime.org/event/”拼凑起来形成一个url,然后进入新的url中进行爬取
按F12查看网页信息,发现当选中class_='table table-striped upcoming-events'时,目标就能全部被选中
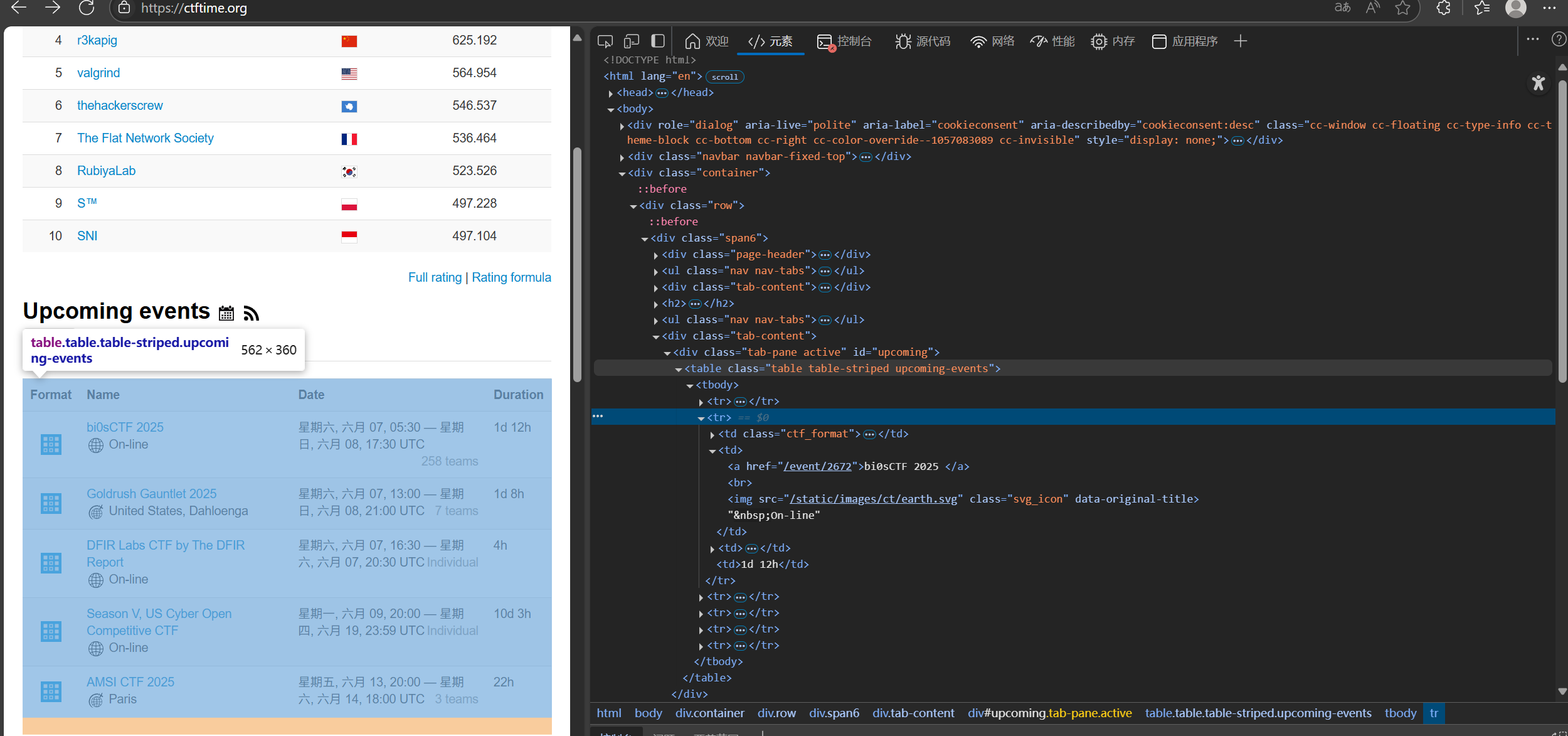
于是使用下面的代码来初步获取信息
def get_ctftime_upcoming(url):
url_event = "https://ctftime.org/event/" #每个赛事的网址都是url_event+xxxx
#下面寻找xxxx
ua = UserAgent()
headers = {
'User-Agent': ua.random # 每次随机生成一个合法的 User-Agent
}
r = requests.get(url, headers=headers)
bs_url = BeautifulSoup(r.content, 'html.parser') #听说lxml更快?
ctf_come = bs_url.find_all('table', class_='table table-striped upcoming-events') #因为在网页中选中class_='table table-striped upcoming-events'是赛事区域
#接下来寻找每个event后面的4位数字
#调试以后发现数字在<a标签后面
#print(ctf_come)
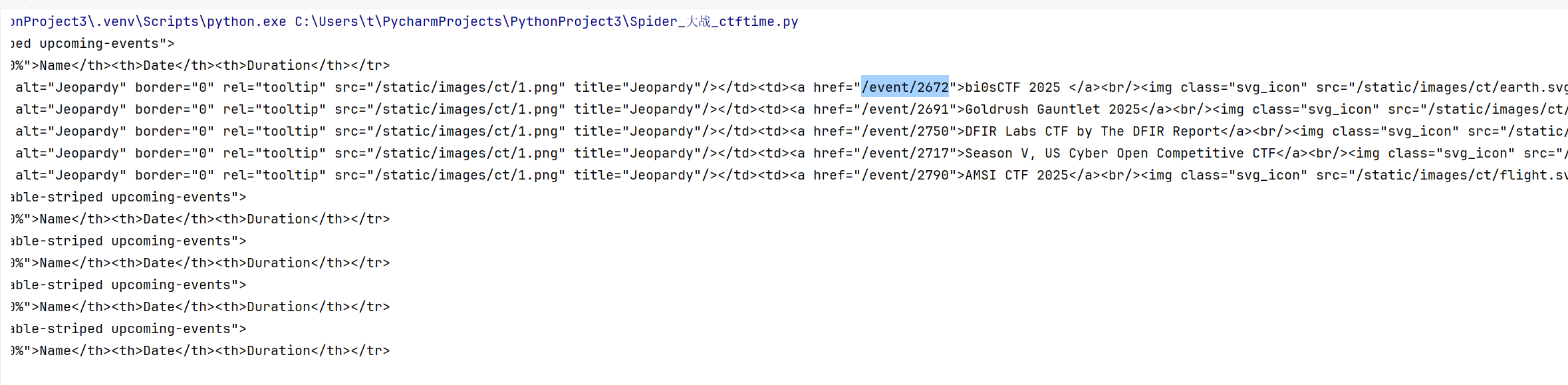
可以发现我们所需要的数字,需要进一步缩小范围,注意看四位数字在a的标签下,利用find_all可以找到,后面就是提取一下字符串中的id就行了,利用下面这段程序进一步提取
for table_come in ctf_come:
for a_come in table_come.find_all('a'):
#print(a_come)
href = a_come.get('href')
if href and href.startswith('/event'):
event_id = href.split('/')[-1]
if event_id.isdigit():
print(event_id)

这样就干净多了,接下来,将url_event = "https://ctftime.org/event/"与event_id拼起来:new_url = url_event + event_id
然后调用三个方法,get_name(),get_time,get_url():
def get_name(url):
ua = UserAgent()
headers = {
'User-Agent': ua.random # 每次随机生成一个合法的 User-Agent
}
r = requests.get(url, headers=headers)
bs_url = BeautifulSoup(r.content, 'html.parser') # 听说lxml更快?
name = bs_url.find_all('h2')
#print(name)#,结果是[<h2>Cyshock - The Awakening</h2>]
#这里需要提取名字
for h2_name in name:
final_name = h2_name.get_text(strip=True)
# print(final_name)
return final_name
def get_time(url):
ua = UserAgent()
headers = {
'User-Agent': ua.random
}
r = requests.get(url, headers=headers)
bs_url = BeautifulSoup(r.content, 'html.parser')
time = bs_url.find('div',class_ = 'span10')
p_time = time.find('p')
final_time = p_time.get_text(separator=' ', strip=True)
return final_time
def get_url(url):
ua = UserAgent()
headers = {
'User-Agent': ua.random
}
r = requests.get(url, headers=headers)
bs_url = BeautifulSoup(r.content, 'html.parser')
url = bs_url.find('div',class_ = 'span10')
for p_url in bs_url.find_all('p'):
# print(p_url)
text = p_url.get_text(strip=True)
#print(text)
if text.startswith('Official URL:'):
# print(text)
return text
这里简单介绍一下提取name吧,剩下两个思路都是一样的,在h2标签下可以发现比赛名
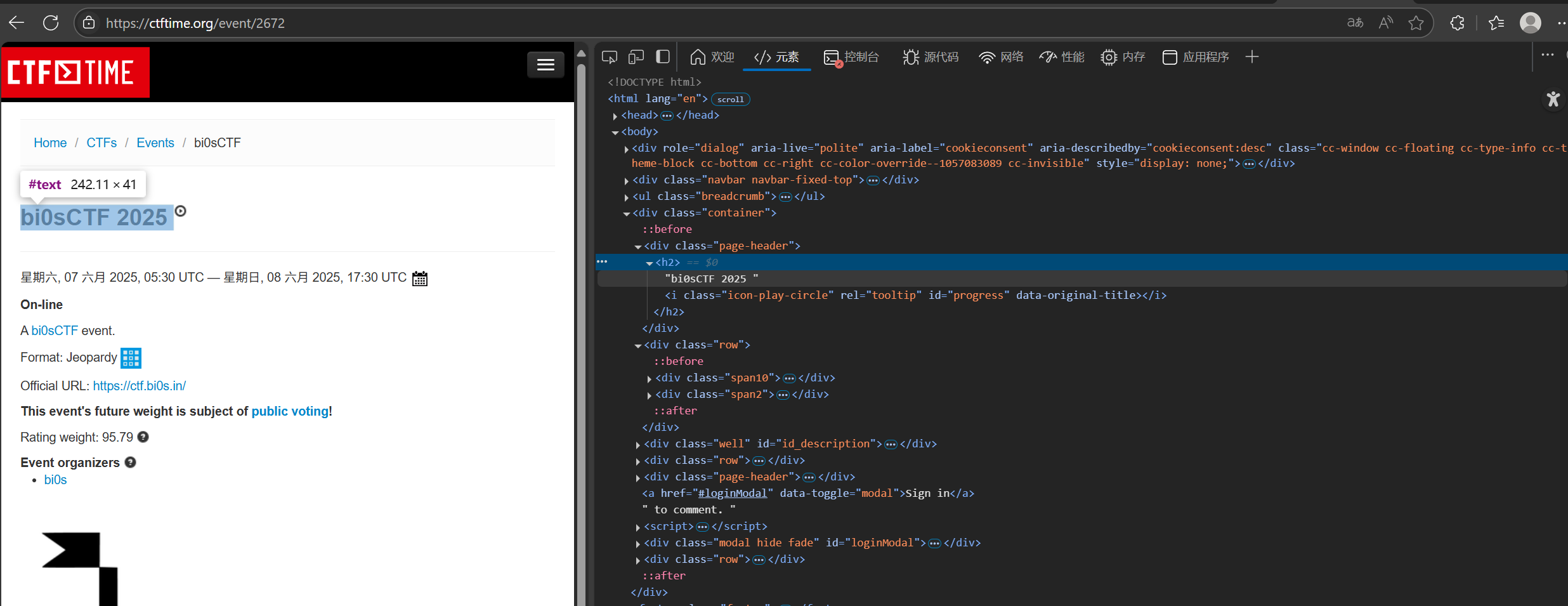
#这里需要提取名字
for h2_name in name:
final_name = h2_name.get_text(strip=True)
# print(final_name)
return final_name
通过上面的代码进行提取,结果如下:

时间和报名网址不再赘述
最后提取到的比赛信息如下,(这里bi0sCTF已经不见了,因为网站更新信息了,不是我做错了!!!):

(2)发送邮件
我们可以将获取到的信息用列表存起来,每一个元素又是一个字典,对应name、time、url,接下来解决如何通过邮件发送这个列表信息
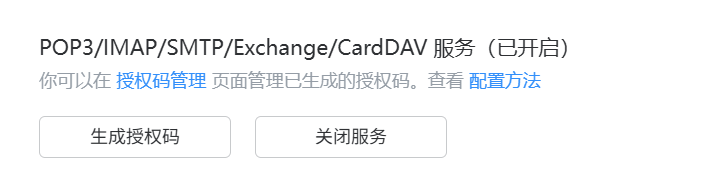
通过查询博文,我选择利用python的smtplib来发送邮件,首先在QQ邮箱中开启SMTP协议,进入设置->账户与安全->开启POP3/SMTP服务->生成授权码:
将信息通过邮件形式发送,可以以文本形式发送,也可以以html形式发送,但是文本形式真的太不雅观了,所以我选择html形式:
先构建html内容,从博文中扒下模板,替换为自己的内容即可:
# 构建 HTML 表格行
table_rows = ""
for event in events:
table_rows += f"""
<tr>
<td>{event['name']}</td>
<td>{event['time']}</td>
<td>{event['url']}</td>
</tr>
"""
# 构建完整 HTML 内容
html_template = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>CTF 赛事通知</title>
</head>
<body>
<h1>即将开始的 CTF 赛事</h1>
<table border="1" cellspacing="0" cellpadding="5" style="border-collapse: collapse;">
<thead>
<tr>
<th>赛事名称</th>
<th>时间</th>
<th>链接</th>
</tr>
</thead>
<tbody>
{table_rows}
</tbody>
</table>
</body>
</html>
"""
html_content = html_template.format(table_rows=table_rows)
重点是接下来如何传输
首先进行邮件服务器配置,设置smtp服务器地址,发送方的邮箱账号,以及发送方的授权码
mail_host = "smtp.qq.com" #smtp服务器地址
mail_sender = "" #发送方的qq邮箱
mail_pwd = "" #发送方的授权码
然后建立SMTP连接,连接邮箱对象,登陆邮箱
smtp = smtplib.SMTP_SSL(mail_host, 465,local_hostname='localhost')
smtp.login(mail_sender, mail_pwd)
之后构建邮箱内容:
msg = MIMEMultipart()
msg.attach(MIMEText(html_content, "html", "utf-8"))
msg["Subject"] = "今日CTF赛事"
msg["From"] = mail_sender
receivers = ["", ""] #前面是接收方qq邮箱,后面是发送方qq邮箱
msg["To"] = ";".join(receivers)
最后发送邮件:
smtp.sendmail(mail_sender, receivers, msg.as_string())
smtp.quit()
print("邮件发送成功")
(3)利用windows任务程序来自动运行脚本
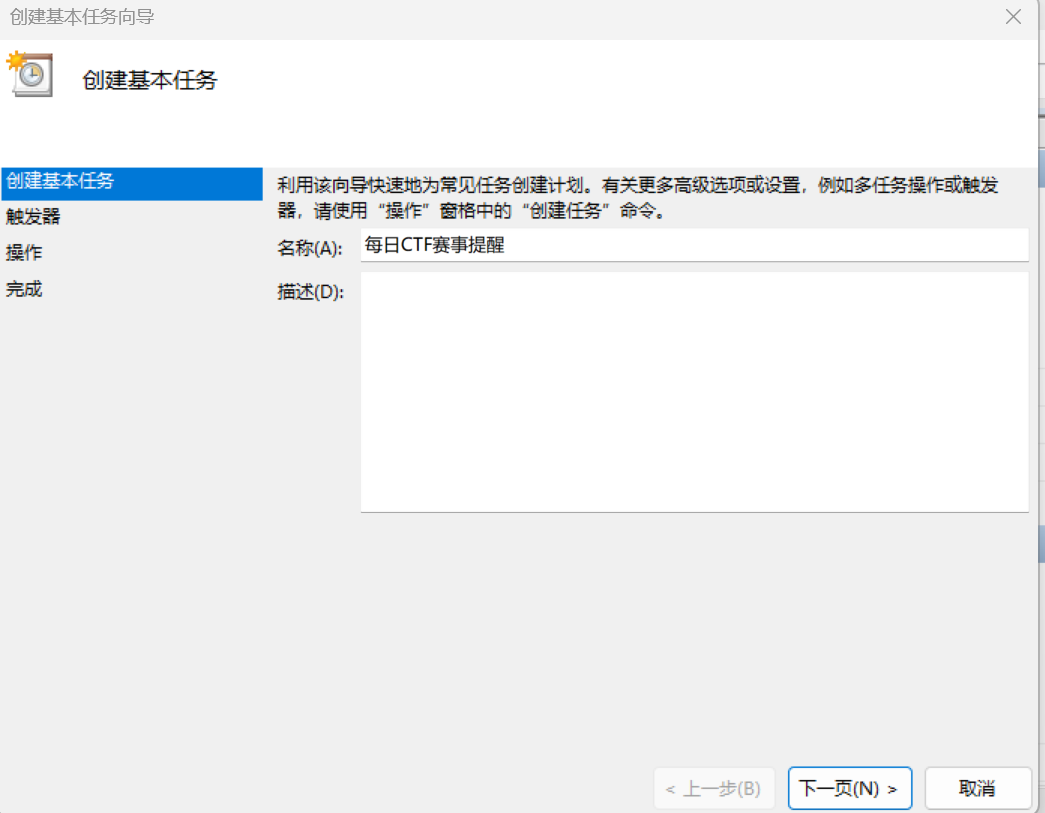
任务栏里搜任务计划程序,点击创建基本任务,输入任务名,比如叫”每日CTF赛事提醒“
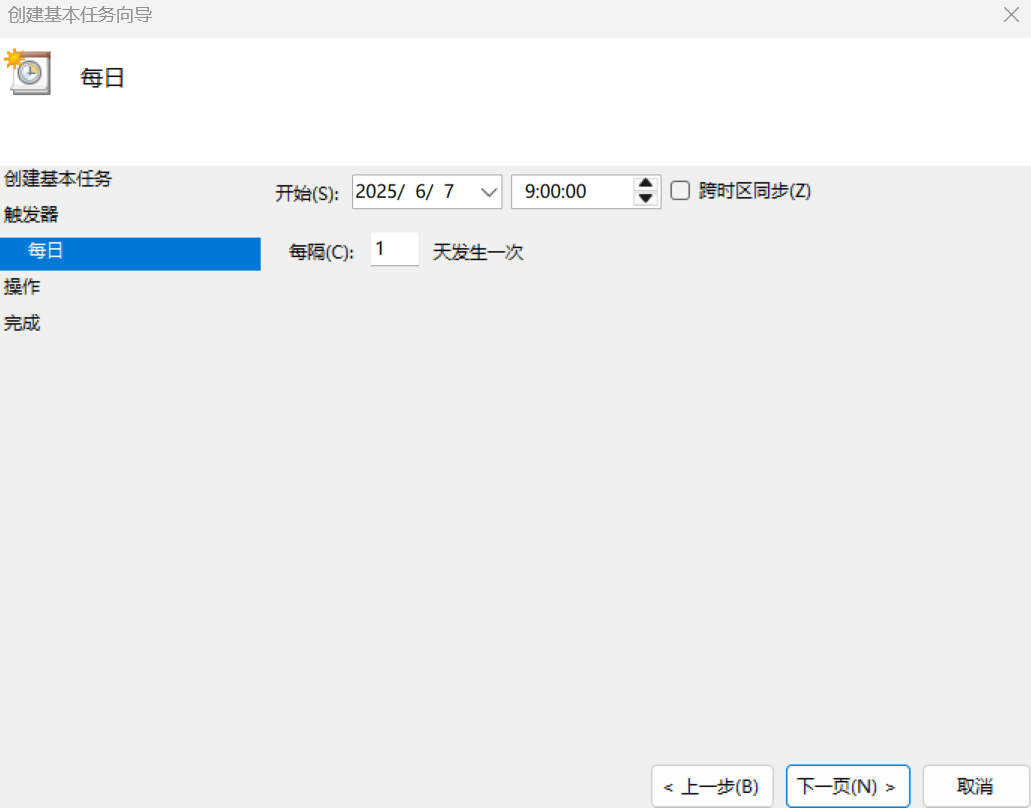
然后选择时间,并点击启动程序:
点击下一步,程序或脚本那里填python解释器的地址,添加参数那里填脚本的地址:
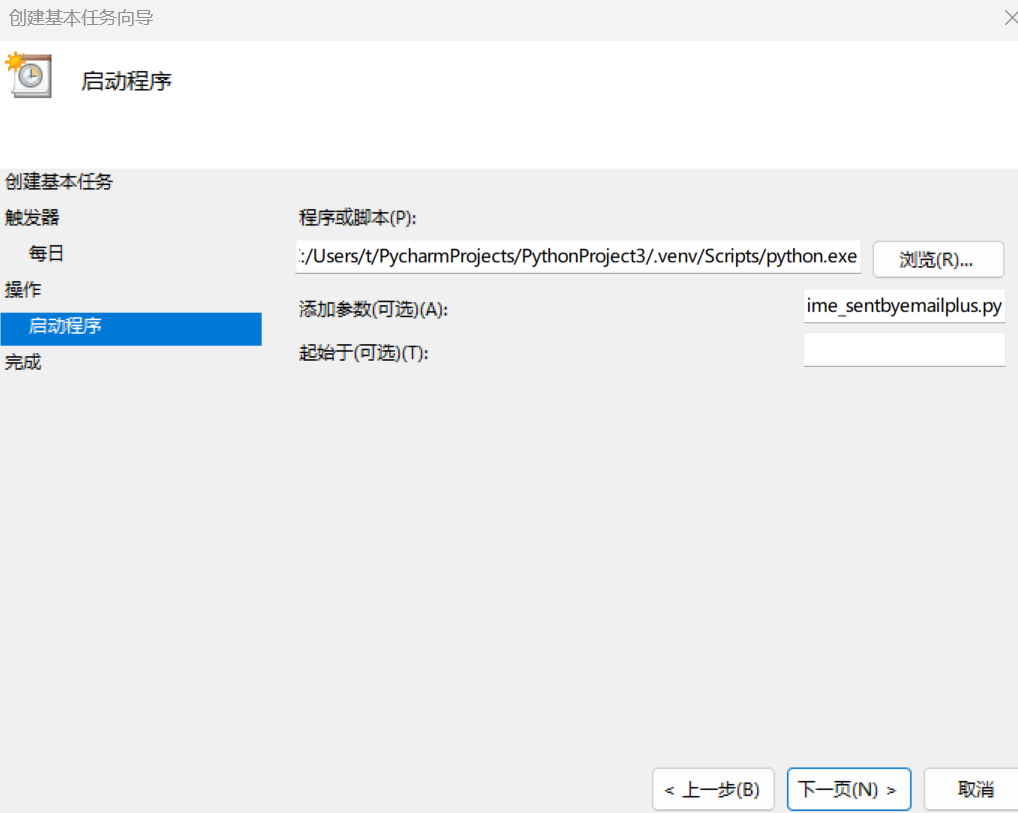
最后因为时间原因,无法演示9:00发送了,我试了一下是能正常使用的:

(4)创建华为云服务器,并运行脚本
这里我查了博客,又借助ai辅助操作,创建服务器就略过了,买高性能的服务器就可以了
然后在powershell上上传代码
'''scp 位置/CTFtime_sentbyemailplus.py root@ip:~
'''

这里我先是测试了一段邮件发送的代码,发现能够成功运行
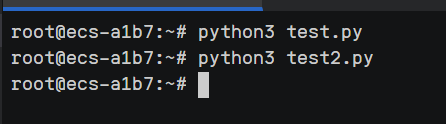

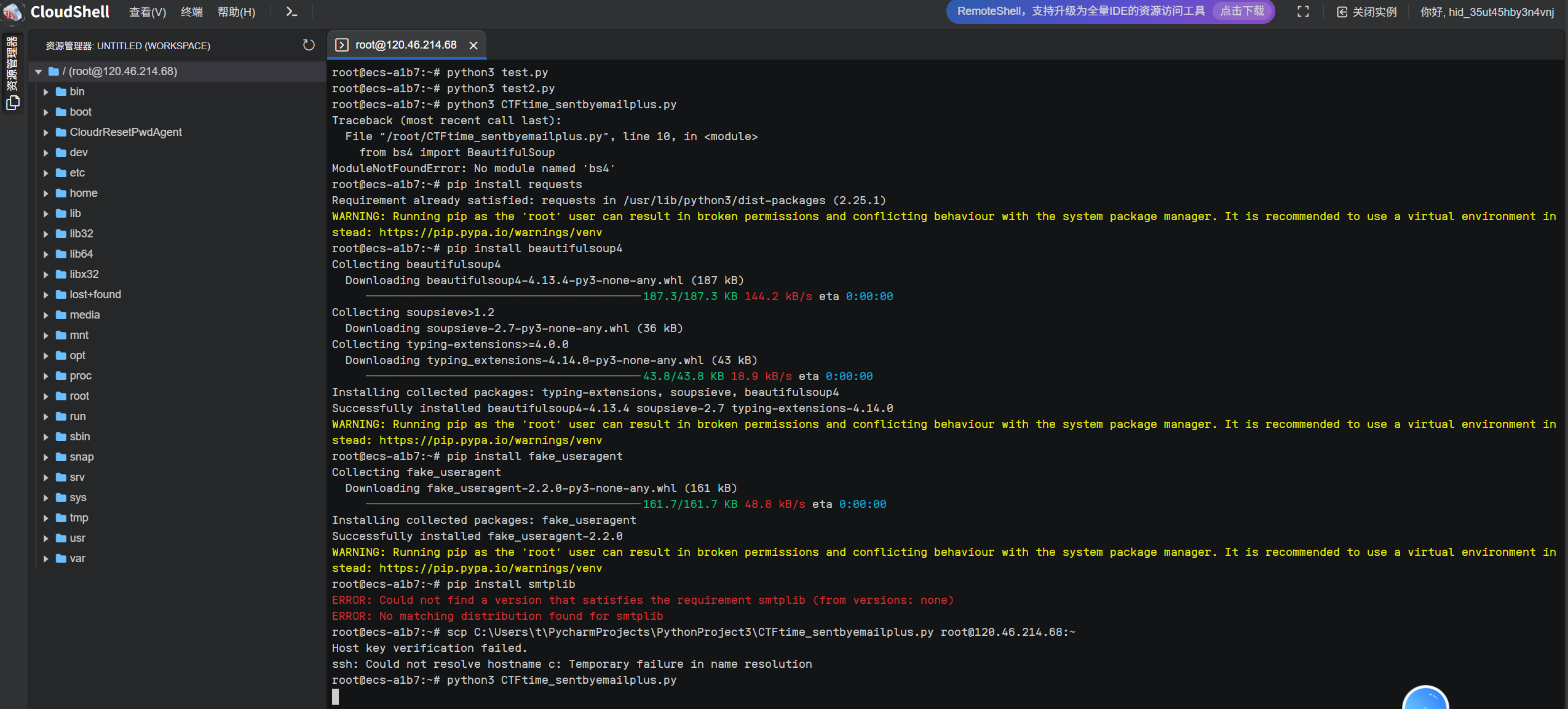
于是就可以运行最终代码了,先安装必须库
然后运行,因为时长有点长,就不放出来了
四、源码
挂Gitee上了:爬虫爬取CTFtime赛事信息,并且每日9:00自动运行脚本发送邮件信息 · bc010b2 · 走于暗巷/pythonhomework - Gitee.com
这里再粘贴一下吧:
CTFtime_sentbyemailplus.py
作者:20242321汤泽鹏
地点:电科院
时间:4 a.m
代理地址:Los Angels
import requests
import re
import smtplib
from email.mime.text import MIMEText
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
from email.mime.multipart import MIMEMultipart
def get_ctftime_upcoming(url):
url_event = "https://ctftime.org/event/" #每个赛事的网址都是url_event+xxxx
#下面寻找xxxx
ua = UserAgent()
headers = {
'User-Agent': ua.random # 每次随机生成一个合法的 User-Agent
}
r = requests.get(url, headers=headers)
bs_url = BeautifulSoup(r.content, 'html.parser') #听说lxml更快?
ctf_come = bs_url.find_all('table', class_='table table-striped upcoming-events') #因为在网页中选中class_='table table-striped upcoming-events'是赛事区域
#接下来寻找每个event后面的4位数字
#调试以后发现数字在<a标签后面
#print(ctf_come)
events = []
for table_come in ctf_come:
for a_come in table_come.find_all('a'):
#print(a_come)
href = a_come.get('href')
if href and href.startswith('/event'):
event_id = href.split('/')[-1]
if event_id.isdigit():
#print(event_id)
new_url = url_event + event_id
# print(get_name(new_url)+" | "+get_time(new_url)+" | "+get_url(new_url))
# print(get_name(new_url) + " | " + get_time(new_url))
events.append({
'name':get_name(new_url),
'time':get_time(new_url),
'url':get_url(new_url),
})
# for i in events:
# print(i)
return events
def get_name(url):
ua = UserAgent()
headers = {
'User-Agent': ua.random # 每次随机生成一个合法的 User-Agent
}
r = requests.get(url, headers=headers)
bs_url = BeautifulSoup(r.content, 'html.parser') # 听说lxml更快?
name = bs_url.find_all('h2')
#print(name)#,结果是[
Cyshock - The Awakening
]#这里需要提取名字
for h2_name in name:
final_name = h2_name.get_text(strip=True)
# print(final_name)
return final_name
def get_time(url):
ua = UserAgent()
headers = {
'User-Agent': ua.random
}
r = requests.get(url, headers=headers)
bs_url = BeautifulSoup(r.content, 'html.parser')
time = bs_url.find('div',class_ = 'span10')
p_time = time.find('p')
final_time = p_time.get_text(separator=' ', strip=True)
return final_time
def get_url(url):
ua = UserAgent()
headers = {
'User-Agent': ua.random
}
r = requests.get(url, headers=headers)
bs_url = BeautifulSoup(r.content, 'html.parser')
url = bs_url.find('div',class_ = 'span10')
for p_url in bs_url.find_all('p'):
# print(p_url)
text = p_url.get_text(strip=True)
#print(text)
if text.startswith('Official URL:'):
# print(text)
return text
def send_mail_upcoming():
# 获取赛事数据
url = "https://ctftime.org/"
events = get_ctftime_upcoming(url)
# 构建 HTML 表格行
table_rows = ""
for event in events:
table_rows += f"""
{event['name']}
{event['time']}
{event['url']}
"""
# 构建完整 HTML 内容
html_template = """
即将开始的 CTF 赛事
{table_rows}
| 赛事名称 | 时间 | 链接 |
|---|
"""
html_content = html_template.format(table_rows=table_rows)
# 发送邮件
mail_host = "smtp.qq.com"
mail_sender = "1397994670@qq.com"
mail_pwd = ""
smtp = smtplib.SMTP_SSL(mail_host, 465, local_hostname='localhost')
smtp.login(mail_sender, mail_pwd)
msg = MIMEMultipart()
msg.attach(MIMEText(html_content, "html", "utf-8"))
msg["Subject"] = "今日CTF赛事"
msg["From"] = mail_sender
receivers = ["571014006@qq.com", "1397994670@qq.com"]
msg["To"] = ";".join(receivers)
smtp.sendmail(mail_sender, receivers, msg.as_string())
smtp.quit()
print("邮件发送成功")
url="https://ctftime.org/"
get_ctftime_upcoming(url)
get_name(url)
get_time(url)
get_official_url(url)
get_url(url)
send_mail_upcoming()
get_ctftime_running(url)
五、遇到的问题及解决过程
1.爬虫应该怎么爬,强哥上课讲了爬虫的基本思路,但是具体该爬什么需要我们自己界定,以下是我对爬虫的理解:
爬虫爬的网页可以分为静态网页和动态网页,简单来说就是爬下来的和看到的一样就是静态网页,动态网页比较复杂。首先观察网址特征,找规律,一般都是固定的url前缀加上XXXX,我们要找的就是XXXX;然后就是按F12,根据鼠标的移动找到你想爬取的信息的位置,然后看相应的标签,大大缩小范围后根据实际情况截取关键信息。这样数据就爬下来了,当然这也是最简单的情况,后续我将学习更高级的爬虫姿势,毕竟爬虫还是太有用了。
关于爬静态网页,这个博文讲的不错:python爬虫思路——静态网站_爬虫静态网站-CSDN博客

2.程序如何运行,因为我的程序需要每天早上9:00自动运行,我先是看了这篇博文:Python 定时发送邮件-CSDN博客

但是我发现这个根本行不通,因为我需要一直运行程序,于是我又问了DeepSeek解决方法,我选择了windows程序管理这个方法,参考了这篇博文:给windows设置定时任务并运行py脚本_windows定时运行py程序-CSDN博客
3.同一段python代码,两周前能用,两周后就不能用了。
我真的是服了,我运行代码的时候报错信息是:邮件发送失败: 'ascii' codec can't encode characters in position 5-9: ordinal not in range(128),我问了通义千问、DeepSeek,Kimi、chatgpt,都让我添加Header处理,统一‘utf-8’处理,反正问题指向都是非ASCII码编码问题,最后我问了3遍DeepSeek,它在最后结尾提了一句授权码过期的问题!!!然后就能跑了。。。
4.其实也不止这些问题,在构建每一个方法时,我都花了些时间的,用了很多的注释和debug,真的是不容易。每次按下运行,我都期待着print”发送成功“。
5.最后在华为云上跑的时候,虽然上学期做过相关的华为云实验,但是我甚至忘了怎么创建云服务器。查了下博客,又问了ai,还好我的代码不涉及图像的相关处理,能够在华为云上顺利进行,就是速度太慢了,要不是有测试邮件,我都怀疑我的代码是不是不能跑。
六、实验总结
这次实验确实不容易,但是也挺有趣的,做爬虫的过程就像是破案的过程,需要一步一步找到自己想要的信息的位置,然后抽丝剥茧获取目标。
爬虫的功能也很强大,理论上能够获取任何信息,但是作为遵纪守法的好公民,我们只爬能爬的信息!绝不说出是强哥教的爬虫。。
这次实验查了很多博文,问了许多AI,大大提高了我的效率,当然总体框架还是我自己搭的。
七、课程总结
1.总结
第一学期就抢python课,我单纯是带着学习技术的目的来的,因为打CTF会用到很多脚本,有些脚本我都看不懂,同时我认为越早学,用到的地方越多。
强哥的讲课的风格真的很吸引人,幽默风趣但又认真严谨,从上课开始的学习通抽象手势签到,到每一章节都有一个主题将内容串联起来,深入浅出讲清pyhon。我印象最深的是老师经常提问什么是面向对象的语言,至今每次吃盖浇饭的时候我都会回味一遍。
感谢强哥,从print”人生苦短,我用python“,到socket通信、爬虫应用,让我获得了远超课时数的价值,激发了我课下去探索、debug的激情。
2.小建议
希望强哥能多抽问,学习通抽不到我,最后一节课我数据被限速了还抢不过别人。其他没什么了,下次还选。

八、参考资料_特别鸣谢强哥!
Python爬虫系列(一)——手把手教你写Python爬虫_python写爬虫-CSDN博客
python爬虫思路——静态网站_爬虫静态网站-CSDN博客
Python 邮件发送_python 网易 smtp port-CSDN博客
给windows设置定时任务并运行py脚本_windows定时运行py程序-CSDN博客
[博客园Markdown语法代码块折叠 - OSCHINA - 中文开源技术交流社区](https://my.oschina.net/rainfate/blog/10105451#:~:text=博客Markdown语法代码块默认不折叠,如果代码块过长很影响读者体验,可以使用自带博客园样式进行折叠。 语法如下: 请注意:在要折叠的代码内容前后各插入一行空格 ,标题<%2Fsummary> %2F%2FYour Code <%2Fdetails>)
https://docs.pingcode.com/baike/911566

 浙公网安备 33010602011771号
浙公网安备 33010602011771号