Hive
Hive
什么是Hive?
1、由Facebook开源用于解决海量结构化日志的数据统计
2、Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射成一张表,并提供类SQL查询功能
3、构建在Hadoop之上的数据仓库:使用HQL作为查询接口,使用HDFS存储,使用MapReduce计算 (Hadoop是一个由Apache基金会所开发的分布式系统基础架构)
4、本质是:将HQL转化为成MapReduce程序
5、灵活性和扩展性比较好:支持UDF,自定义存储格式等
6、Hive中的表是纯逻辑表,就只是表的定义等,即表的元数据。本质就是Hadoop的目录/文件,达到了元数据与数据存储分离的目的, Hive本身不存储数据,它完全依赖HDFS和MapReduce。
7、Hive的内容是读多写少,不支持对数据的更新
8、Hive中没有定义专门的数据格式,由用户指定,需要指定三个属性:1. 列分隔符 2. 行分隔符 3. 读取文件数据的方法
HQL和SQL的区别?
查询方式和面向的对象不同
HQL(Hibernate Query Language)和SQL(Structured Query Language)的主要区别在于它们的查询方式和面向的对象不同。
1、查询方式:
HQL是面向对象查询,它使用类名和对象属性进行查询,而SQL是面向数据库表查询,使用表名和字段进行查询。这意味着HQL的查询语句更接近于面向对象的编程方式,而SQL则更直接地操作数据库表结构。
2、面向的对象:
HQL关注的是对象及其属性,而SQL关注的是存储在表中的数据及其行和列的修改。HQL通过类及其属性来操作数据,并最终映射到数据库中的表结构,而SQL直接操作数据库表和字段。
3、语法结构:
HQL的语法结构为select from 类名 类对象 where 对象的属性,而SQL的语法结构为 select from 表名 where 表中字段。HQL的查询语句在Hibernate、Hive中使用,而SQL是关系型数据库的标准查询语言。
4、功能和特性:
HQL提供了更丰富和灵活的查询特性,包括支持多态、继承、关联等概念,使得SQL具有了面向对象的特性。HQL的查询结果不是纯数据,而是可以通过编程方式修改的对象组合,甚至返回子对象作为查询结果的一部分。HQL还包含分页、动态分析等概念,这些是SQL开发人员可能不熟悉的。
5、使用场景:
在Hibernate这样的数据库持久化框架中,HQL是推荐的查询方式,因为它提供了更加面向对象的封装。尽管HQL在数据库通用,可以切换数据库方言,但SQL在不同数据库中的语法有些不同,因此HQL更加符合开发标准
Hive的优点及应用场景
操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)
避免了去写 MapReduce,减少开发人员的学习成本
统一的元数据管理,可与 impala/ spark等共享元数据
易扩展(HDFS+ MapReduce:可以扩展集群规模;支持自定义函数)
数据的离线处理;比如:日志分析,海量结构化数据离线分析
Hive的执行延迟比较高,因此hive常用于数据分析的,对实时性要求不高的场合
Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高
Hive 和 RDBMS(关系数据库管理系统)的对比
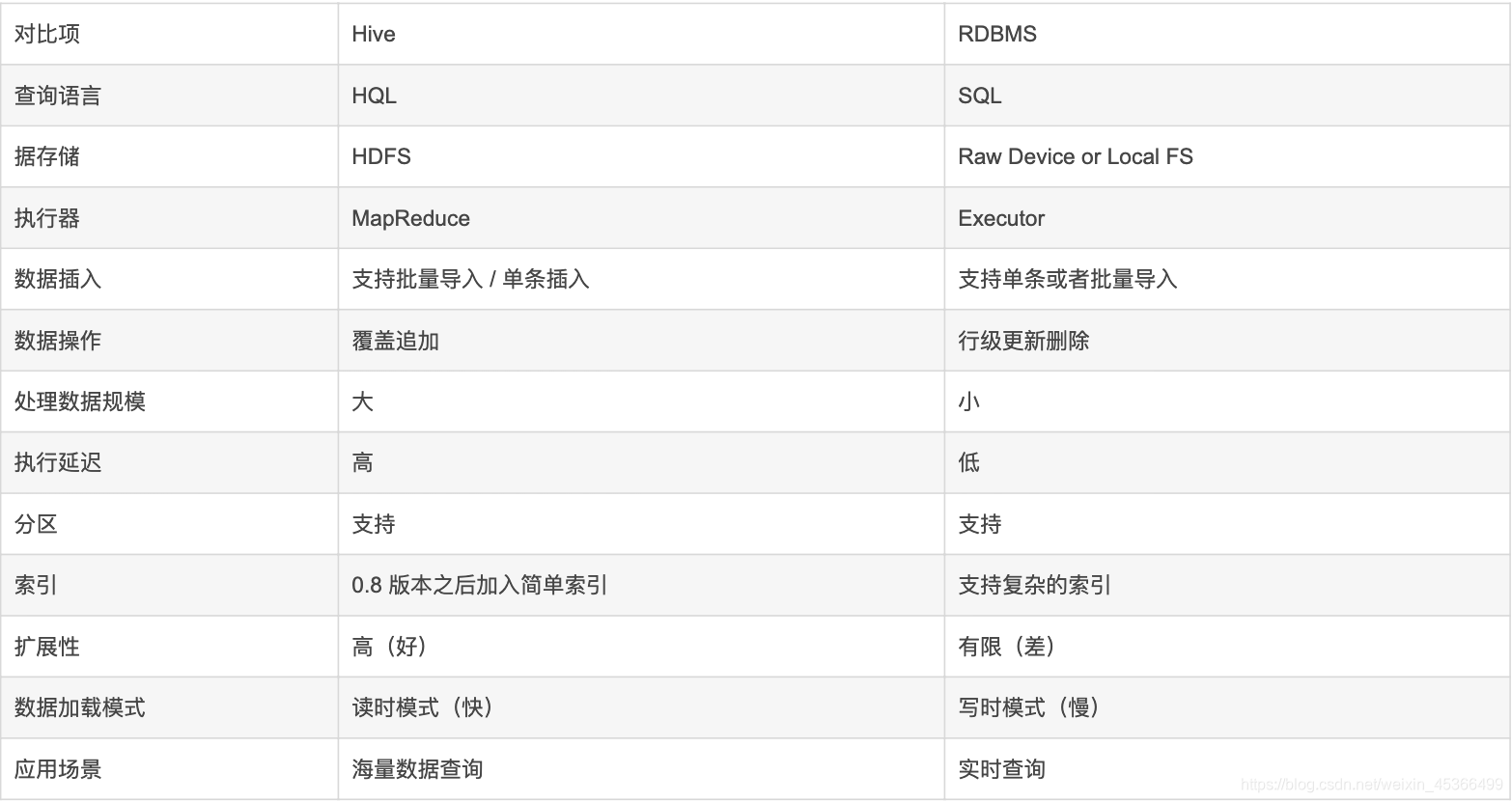
Hive 本质:Hive是一个数据仓库,适合用来做海量数据的离线分析
1.Hive处理的数据存储在HDFS
2.Hive分析数据底层的实现是MapReduce
3.执行程序运行在Yarn上
元数据存储:元数据是描述数据的数据,Hive 将元数据存储在关系型数据库中(MySql或者Derby)。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等,具体数据在HDFS。表的数据所在目录Metastore 默认存在自带的 Derby 数据库中。缺点就是不适合多用户操作,并且数据存储目录不固定。数据库跟着 Hive 走,极度不方便管理。解决方案:通常存我们自己创建的MySQL库(本地或远程),Hive 和 MySQL 之间通过 MetaStore 服务交互。
Hive的工作原理
流程大致步骤为:
-
1、用户提交查询等任务给Driver。
-
2、编译器获得该用户的任务Plan。
-
3、编译器Compiler根据用户任务去MetaStore中获取需要的Hive的元数据信息。
-
4、编译器Compiler得到元数据信息,对任务进行编译,先将HiveQL转换为抽象语法树,然后将抽象语法树转换成查询块,将查询块转化为逻辑的查询计划,重写逻辑查询计划,将逻辑计划转化为物理的计划(MapReduce), 最后选择最佳的策略。
-
5、将最终的计划提交给Driver。
-
6、Driver将计划Plan转交给ExecutionEngine去执行,获取元数据信息,提交给JobTracker或者SourceManager执行该任务,任务会直接读取HDFS中文件进行相应的操作。
-
7、获取执行的结果。
-
8、取得并返回执行结果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号