ES分布式搜索引擎( elasticsearch)
ES分布式搜索引擎( elasticsearch)
什么是Elasticsearch?
一个开源的分布式搜索引擎,可以用来实现搜索、日志统计、分析、系统监控等功能,elasticsearch底层是基于lucene来实现的。
Elasticsearch是一个开源的分布式搜索和分析引擎,构建在Apache Lucene搜索引擎库之上,提供了一个分布式、多租户的全文搜索引擎,能够实时地存储、检索和分析大规模的数据。
Elasticsearch特点:
(1)分布式架构:Elasticsearch采用分布式架构
(2)实时搜索
(3)多租户支持:可以在同一个集群中为不同的应用或用户提供服务。
(4)文档存储:以文档为基本存储单元,每个文档都是一个JSON格式的数据对象。
(5)多种数据类型支持:包括文本、数字、地理位置。
(6)强大的查询语言:Elasticsearch提供了丰富的查询DSL,能够进行复杂的条件查询和聚合分析。
(7)高性能:能够处理大规模数据并提供低延迟的响应。
(8) 实时分析:除了搜索功能,还能够对数据进行实时的统计和分析。
Elasticsearch查询原理/步骤
查询原理主要是基于倒排索引、分词、查询解析和查询执行这几个基本步骤来实现的。
(1)、倒排索引
使用倒排索引来加快搜索速度。倒排索引是一种数据结构,它可以快速地定位到包含特定词条的文档。
(2)、分词
在索引文档时,Elasticsearch会对文本进行分词处理,将文本分割成词条。在用户执行查询时,查询字符串也会被进行同样的分词处理,以便匹配索引中的词条。
(3)、查询解析
(4)、查询执行
(5)、结果返回
什么是elastic stack(ELK)?
是以elasticsearch为核心的技术栈,包括beats、Logstash、kibana、elasticsearch
elasticsearch是elastic stack的核心,负责存储、搜索、分析数据。
kibana 数据可视化
elasticsearch 存储、计算、搜索数据
beats、Logstash 数据抓取
什么是Lucene?
是Apache的开源搜索引擎类库,提供了搜索引擎的核心API
Lucene是基于倒排索引来实现快速搜索的
倒排索引中有两个非常重要的概念:
-
文档(Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息
-
词条(Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条
创建倒排索引是对正向索引的一种特殊处理,流程如下:
-
将每一个文档的数据利用算法分词,得到一个个词条
-
创建表,每行数据包括词条、词条所在文档id、位置等信息
-
因为词条唯一性,可以给词条创建索引,例如hash表结构索引
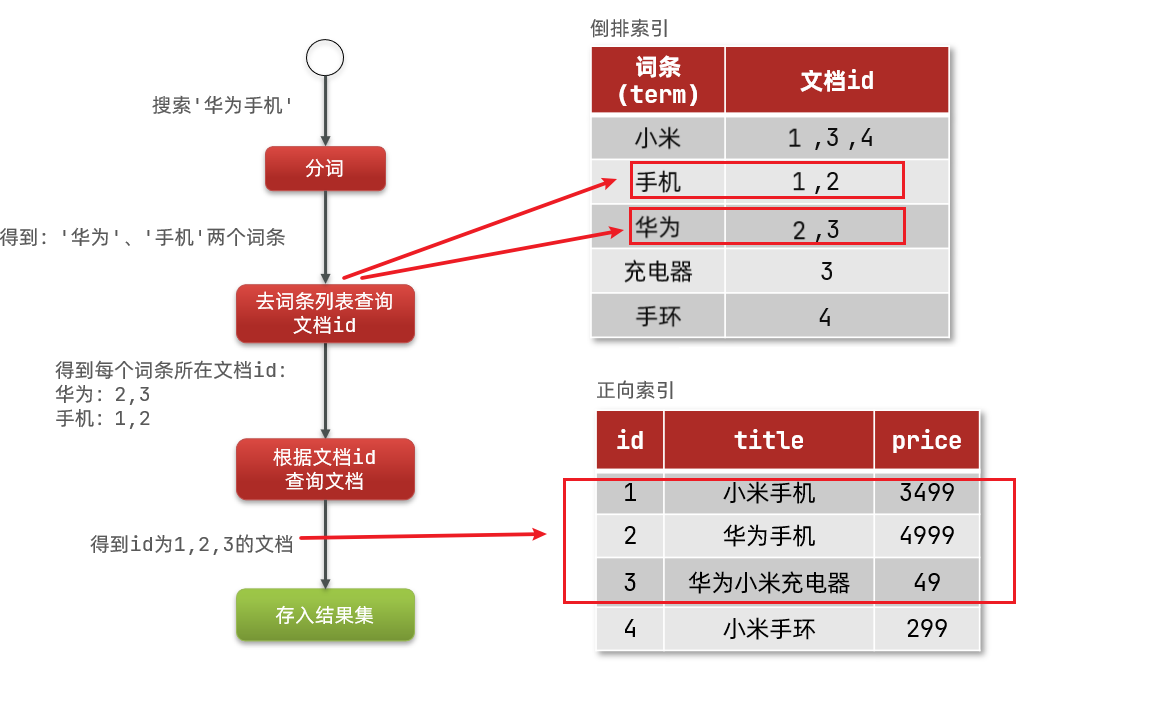
如图:

倒排索引的搜索流程如下(以搜索"华为手机"为例):
-
1)用户输入条件"华为手机"进行搜索。
-
2)对用户输入内容分词,得到词条:华为、手机。
-
3)拿着词条在倒排索引中查找,可以得到包含词条的文档id:1、2、3。
-
4)拿着文档id到正向索引中查找具体文档。
如图:
3 正向和倒排对比
概念区别:
正向索引是最传统的,根据id索引的方式。但根据词条查询时,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是根据文档找词条的过程。
而倒排索引则相反,是先找到用户要搜索的词条,根据词条得到保护词条的文档的id,然后根据id获取文档。是根据词条找文档的过程。
优缺点:
正向索引:
-
优点:
-
可以给多个字段创建索引
-
根据索引字段搜索、排序速度非常快
-
缺点:
-
根据非索引字段,或者索引字段中的部分词条查找时,只能全表扫描。
倒排索引:
-
优点:
-
根据词条搜索、模糊搜索时,速度非常快
-
缺点:
-
只能给词条创建索引,而不是字段
-
无法根据字段做排序
文档和字段
elasticsearch是面向文档(Document)存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化为json格式后存储在elasticsearch中:

而Json文档中往往包含很多的字段(Field),类似于mysql数据库中的列
mysql与elasticsearch对比
-
Mysql:擅长事务类型操作,可以确保数据的安全和一致性
-
Elasticsearch:擅长海量数据的搜索、分析、计算
|
MySQL
|
Elasticsearch
|
说明
|
|
Table
|
Index
|
索引(index),就是文档的集合,类似数据库的表(table)
|
|
Row
|
Document
|
文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式
|
|
Column
|
Field
|
字段(Field),就是JSON文档中的字段,类似数据库中的列(Column)
|
|
Schema
|
Mapping
|
Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema)
|
|
SQL
|
DSL
|
DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD
|
在企业中,往往是两者结合使用:
-
对安全性要求较高的写操作,使用mysql实现
-
对查询性能要求较高的搜索需求,使用elasticsearch实现
-
两者再基于某种方式,实现数据的同步,保证一致性
IK分词器
分词器的作用是什么?
-
创建倒排索引时对文档分词
-
用户搜索时,对输入的内容分词
IK分词器有几种模式?
-
ik_smart:智能切分,粗粒度
-
ik_max_word:最细切分,细粒度
IK分词器如何拓展词条?如何停用词条?
-
利用config目录的IkAnalyzer.cfg.xml文件添加拓展词典和停用词典
-
在词典中添加拓展词条或者停用词条

 浙公网安备 33010602011771号
浙公网安备 33010602011771号