Redis
一、Redis
redis是一个开源的、基于内存也可持久化的NoSql(非关系型)数据库,是key:value格式存储的。
-
常用NoSql数据库有:redis、 MongoDB、 HBase
-
redis特点:运行异常快redis最佳应用场景:数据变化快的场景。例如:股票价格、热点数据、实时通讯。
-
MongoDB特点:保留了SQL的一些特性(如查询,索引) MongoDB最佳应用场景:需要动态查询支持,需要使用索引,对大数据库有性能要求的场景。
-
HBase特点:HBase基于Hadoop提供了类似于Bigtable的能力,利用Hadoop的MapReduce来处理海量数据最佳应用场景:需要对大数据进行随机、实时访问的场景。例如: Facebook消息数据库(更多通用的用例即将出现)
-
Redis的value支持五种数据类型:
1. 字符串(string)
2. 列表(list)
3. 集合(set)
4. 有序集合(Zset)
5. 哈希(hash))
Redis 的应用场景包括:
“热点”数据,高频读、低频写
计数器、
排行榜、
消息队列系统、
社交网络和实时系统
Redis事务
MULTI、EXEC、DISCARD这三个指令构成了 redis 事务处理的基础:
MULTI:用来组装一个事务,从输入Multi命令开始,输入的命令都会依次进入命令队列中,但不会执行,直到输入Exec后,redis会将之前的命令依次执行。
EXEC:用来执行一个事务
DISCARD:用来取消一个事务
事务四大特性:原子性,持久性,隔离性,一致性
redis 只满足一致性和隔离性,不满足原子性(不支持回滚)和持久性
redis缓存穿透、缓存击穿和缓存雪崩
缓存穿透:大量恶意请求查询不存在的数据,从而绕过redis,直接攻击数据库
缓存击穿:指一个缓存失效的key,高并发情况下,大量的请求直接到数据库,可能会使数据库崩溃。
缓存击穿解决方法:
1、服务器启动时, 提前写入
2、规范key的命名, 通过中间件拦截
3、对某些高频访问的Key,设置合理的TTL或永不过期。(TTL(Time To Live)是指键值对的过期时间)
4、设置热点数据永不失效或者失效前主动更新。
5、使用分布式锁或者队列控制访问数据库的线程数量,避免大量并发请求打到数据库。
6、实现服务限流和熔断机制,防止因为某个服务不可用而影响整个系统。
7、使用布隆过滤器(将所有可能存在的数据哈希到一个足够大的bitmap中,对所有可能查询的参数以hash形式存储,在控制层先进行校验,不符合则丢弃,一个一定不存在的数据会被bitmap拦截掉从而避免了对底层存储系统的查询压力)。
缓存雪崩:指在同一时段大量的缓存失效,导致大量数据查询直接到数据库,可能会使数据库崩溃。
缓存雪崩解决方法:
1、设置合理的缓存失效时间,避免大量缓存同时失效。
2、实现缓存数据的分布式锁,确保同时只有一个客户端去数据库中查询数据,其他客户端等待。
3、利用Redis集群或者一致性哈希算法,分散key的分布,避免热点数据集中失效。
4、如果缓存数据设置了过期时间,可以在失效前主动更新缓存数据。
5、 服务限流和熔断
redis的两级缓存
Redis+Caffeine:配合本地缓存使用,例如Guava cache或Caffeine,使用本地缓存作为一级缓存,再加上redis远程缓存作为二级缓存的两级缓存架构。
使用两级缓存相比单纯使用远程缓存,具有什么优势?
1、本地缓存是基于本地环境的内存,访问速度非常快,对于一些变更频率低、实时性要求低的数据,可以放在本地缓存中,提升访问速度
2、使用本地缓存能够减少和Redis远程缓存间的数据交互,减少网络I/O开销,降低这一过程中在网络通信上的耗时
但是在设计中,还是要考虑一些问题的,例如数据一致性问题。首先,两级缓存与数据库的数据要保持一致,一旦数据发生了修改,在修改数据库的同时,本地缓存、远程缓存应该同步更新。
Redis持久化:
-
RDB快照 定期把内存数据完整保存到硬盘,像拍照一样,恢复快但有可能丢失最新数据
-
AOF日志 把每个写操作都记录下来,像记日记,数据更安全但恢复较慢,因为需要重新执行所有写操作
二、Redis集群的使用
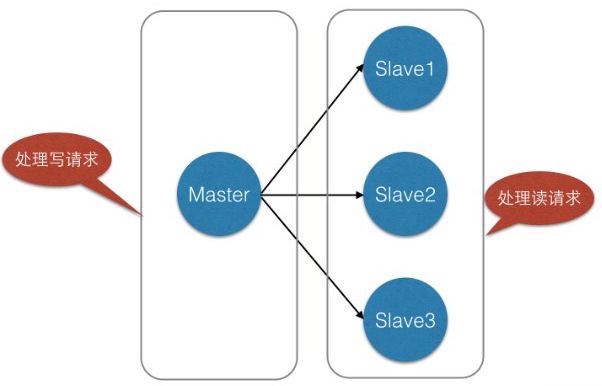
我们在使用Redis的时候,为了保证Redis的高可用,提高Redis的读写性能,最简单的方式我们会做主从复制,组成Master-Master或者Master-Slave的形式,或者搭建Redis集群,进行数据的读写分离,类似于数据库的主从复制和读写分离。如下所示:
同样类似于数据库,当单表数据大于500W的时候需要对其进行分库分表,当数据量很大的时候(标准可能不一样,要看Redis服务器容量)我们同样可以对Redis进行类似的操作,就是分库分表。
假设,我们有一个社交网站,需要使用Redis存储图片资源,存储的格式为键值对,key值为图片名称,value为该图片所在文件服务器的路径,我们需要根据文件名查找该文件所在文件服务器上的路径,数据量大概有2000W左右,按照我们约定的规则进行分库,规则就是随机分配,我们可以部署8台缓存服务器,每台服务器大概含有500W条数据,并且进行主从复制,示意图如下:
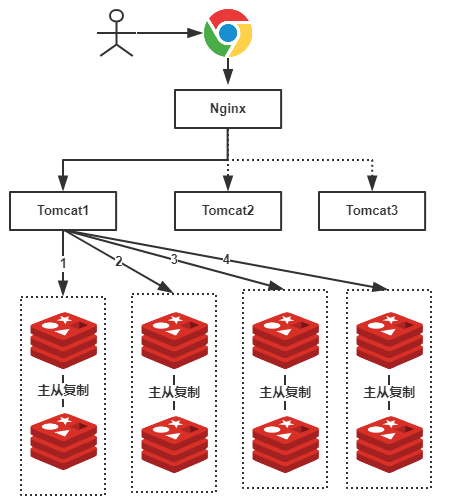
由于规则是随机的,所有我们的一条数据都有可能存储在任何一组Redis中,例如上图我们用户查找一张名称为”a.png”的图片,由于规则是随机的,我们不确定具体是在哪一个Redis服务器上的,因此我们需要进行1、2、3、4,4次查询才能够查询到(也就是遍历了所有的Redis服务器),这显然不是我们想要的结果,有了解过的小伙伴可能会想到,随机的规则不行,可以使用类似于数据库中的分库分表规则:按照Hash值、取模、按照类别、按照某一个字段值等等常见的规则就可以出来了!好,按照我们的主题,我们就使用Hash的方式。
二、为Redis集群使用Hash
一致性Hash算法也是使用取模的方法,只是,刚才描述的取模法是对服务器的数量进行取模,而一致性Hash算法是对2^32取模,什么意思呢?简单来说,一致性Hash算法将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-2^32-1(即哈希值是一个32位无符号整形),整个哈希环如下:
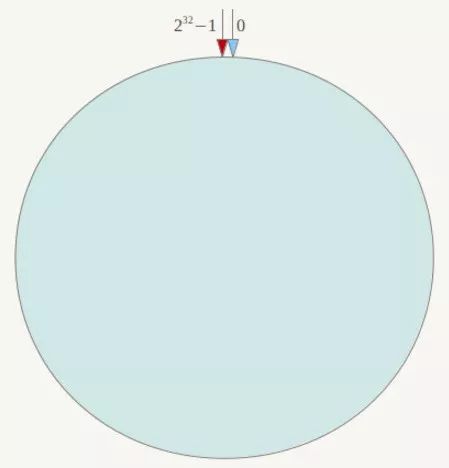
整个空间按顺时针方向组织,圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、5、6……直到2^32-1,也就是说0点左侧的第一个点代表2^32-1, 0和2^32-1在零点中方向重合,我们把这个由2^32个点组成的圆环称为Hash环。
下一步将各个服务器使用Hash进行一个哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置,这里假设将上文中四台服务器使用IP地址哈希后在环空间的位置如下:
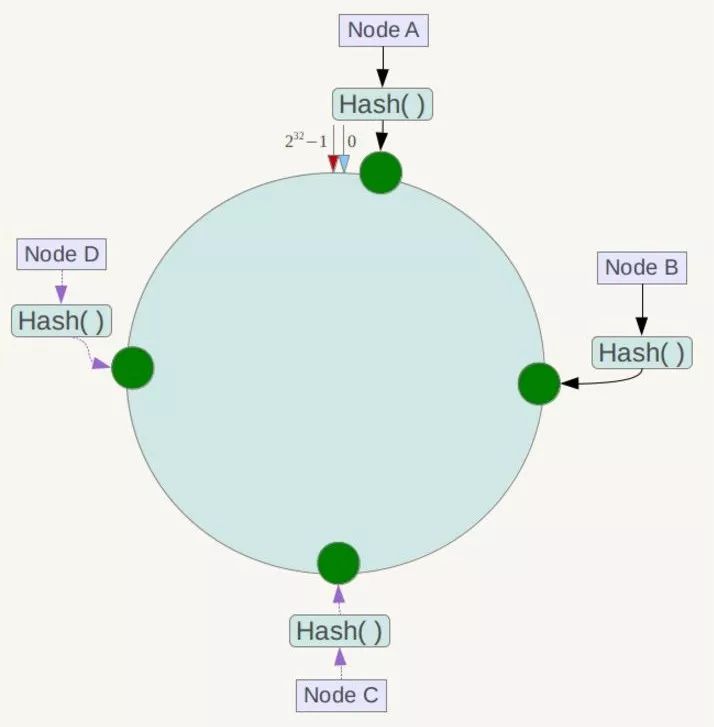
接下来使用如下算法定位数据访问到相应服务器:将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器!
例如我们有Object A、Object B、Object C、Object D四个数据对象,经过哈希计算后,在环空间上的位置如下:
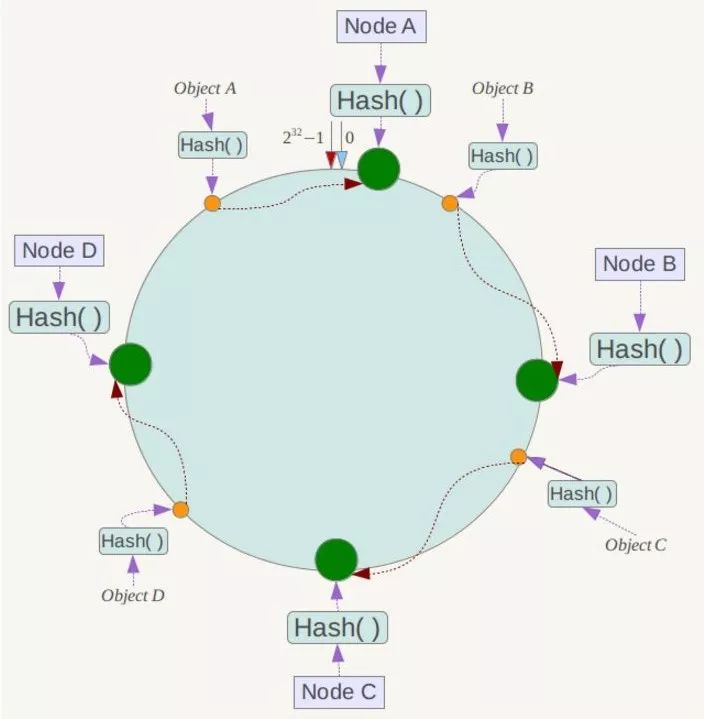
根据一致性Hash算法,数据A会被定为到Node A上,B被定为到Node B上,C被定为到Node C上,D被定为到Node D上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号